
本指南将演示如何使用 Profiler 随附的工具跟踪 TensorFlow 模型的性能。您将学习如何了解您的模型在主机 (CPU)、设备 (GPU) 或主机与设备组合上的性能。
性能剖析有助于了解模型中各种 TensorFlow 运算的硬件资源消耗(时间和内存),并解决性能瓶颈,最终提高模型的执行速度。
本指南将指导您了解如何安装 Profiler、提供的各种工具、Profiler 收集性能数据的不同模式,以及一些用于优化模型性能的建议最佳做法。
如果要在 Cloud TPU 上剖析模型性能,请参阅 Cloud TPU 指南。
安装 Profiler 和 GPU 前提条件
使用 pip 为 TensorBoard 安装 Profiler 插件。请注意,Profiler 需要最新版本的 TensorFlow 和 TensorBoard (>=2.2)。
pip install -U tensorboard_plugin_profile
要在 GPU 上剖析,您必须:
满足 TensorFlow GPU 支持软件要求上列出的 NVIDIA® GPU 驱动程序和 CUDA® Toolkit 要求。
确保 NVIDIA® CUDA® Profiling Tools Interface (CUPTI) 位于以下路径下:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
如果 CUPTI 不在该路径下,请运行以下命令,在 $LD_LIBRARY_PATH 环境变量前面追加其安装目录:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
然后,重新运行上面的 ldconfig 命令,验证在该路径下可以找到 CUPTI 库。
解决权限问题
在 Docker 环境中或 Linux 上使用 CUDA® Toolkit 运行性能剖析时,您可能会遇到与 CUPTI 权限不足相关的问题 (CUPTI_ERROR_INSUFFICIENT_PRIVILEGES)。请参阅 NVIDIA 开发者文档,详细了解如何在 Linux 上解决这些问题。
要解决 Docker 环境中的 CUPTI 权限问题,请运行以下代码:
docker run option '--privileged=true'
Profiler 工具
从 TensorBoard 的 Profile 标签页中访问 Profiler,只有您捕获一些模型数据后,Profiler 才会出现。
注:Profiler 需要访问互联网才能加载 Google Chart 库。如果您在本地计算机上、在公司防火墙后或者数据中心中完全离线运行 TensorBoard,某些图表和表可能缺失。
Profiler 提供了多种工具来帮助您进行性能分析:
- 概览页面
- 输入流水线分析器
- TensorFlow Stats
- Trace Viewer
- GPU Kernel Stats
- 内存性能剖析工具
- Pod Viewer
概览页面
概览页面提供了您的模型在性能剖析运行期间表现的顶级视图。该页面会向您显示主机和所有设备的汇总概览信息,以及一些提升模型训练性能的建议。您还可以在 Host 下拉列表中选择各个主机。
概览页面包含以下信息:
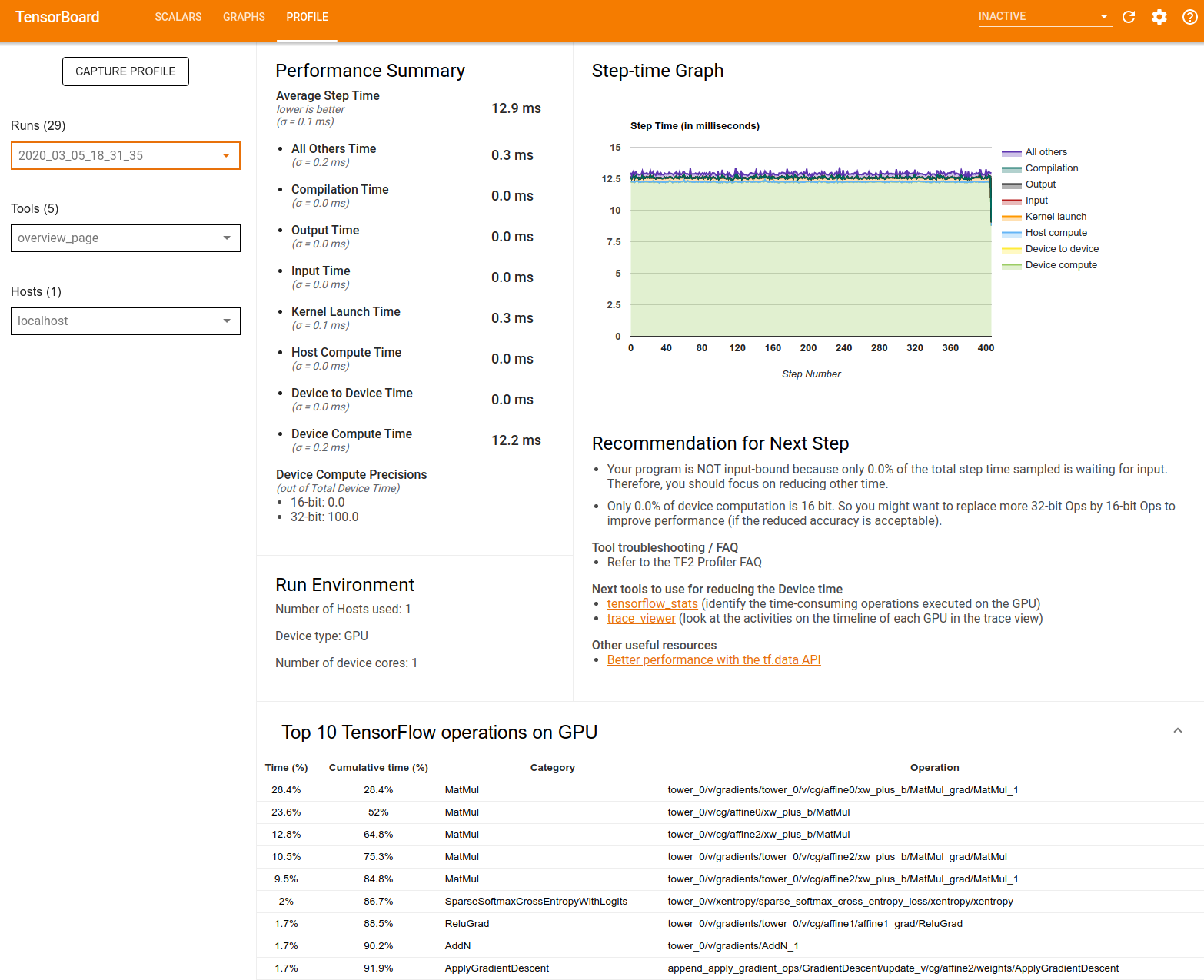
Performance Summary:显示模型性能的简略摘要。性能摘要包含两部分:
单步用时细分:按照消耗时间的项目将平均单步用时细分成多个类别:
- 编译:编译内核花费的时间。
- 输入:读取输入数据花费的时间。
- 输出:读取输出数据花费的时间。
- 内核启动:主机启动内核花费的时间
- 主机计算时间。
- 设备间通信时间。
- 设备端计算时间。
- 所有其他时间,包括 Python 开销。
设备计算精度 - 报告使用 16 位和 32 位计算的设备计算时间的百分比
Step-time Graph:显示所有采样步骤中的设备单步用时图(以毫秒为单位)。每个步骤分为多个类别(以不同颜色标识)。红色区域对应设备闲置等待主机的输入数据所需的单步用时部分。绿色区域显示设备的实际工作时长。
Top 10 TensorFlow operations on GPU:显示运行时间最长的设备端运算。
每行显示了运算的自用时间(以所有运算需要的时间百分比形式)、累计时间、类别和名称。
Run Environment:显示包括以下信息的模型运行环境的简略摘要:
- 使用的主机数。
- 设备类型 (GPU/TPU)。
- 设备核心的数量。
Recommendation for Next Step:在模型受输入约束时报告,并推荐您可以用于定位和解决模型性能瓶颈的工具。
输入流水线分析器
当 TensorFlow 程序从文件读取数据时,它会以流水线方式从 TensorFlow 计算图的顶部开始。读取过程分为多个串联的数据处理阶段,其中一个阶段的输出是下一个阶段的输入。这种数据读取系统称为输入流水线。
从文件读取记录的典型流水线包括以下阶段:
- 文件读取。
- 文件预处理(可选)。
- 文件从主机传输到设备。
低效的输入流水线会严重减缓应用速度。如果将很大一部分时间花在输入流水线上,应用会被视为受输入约束。使用从输入流水线分析器获得的分析数据可以了解输入流水线低效的地方。
输入流水线分析器可以立即告诉您程序是否受输入约束,并引导您执行设备端和主机端分析,这两种分析可以帮助您在输入流水线的任何阶段调试性能瓶颈。
请查阅输入流水线性能指导,了解优化数据输入流水线的推荐最佳做法。
输入流水线信息中心
要打开输入流水线分析器,请选择 Profile,然后在 Tools 下拉列表中选择 input_pipeline_analyzer。

信息中心包含三个版块:
- 摘要:汇总了整个输入流水线的相关信息,包含您的应用是否受输入约束,以及受输入约束时的约束程度等信息。
- 设备端分析:显示详细的设备端分析结果,包括设备单步用时,以及每一步中等待各个核心的输入数据所用的设备时间的范围。
- 主机端分析:显示详细的主机端分析,包括主机输入处理时间的明细。
输入流水线摘要
摘要通过显示等待主机输入所用的设备时间百分比来报告您的程序是否受输入约束。如果您使用的是已被检测的标准输入流水线,则该工具将报告占用大部分输入处理时间的环节。
设备端分析
设备端分析提供了设备与主机所用时间以及等待主机输入数据所用设备时间的信息。
- 单步用时与步数的关系图:显示所有采样步骤中的设备单步用时图(以毫秒为单位)。每个步骤分为多个类别(以不同颜色标识)。红色区域对应设备闲置等待主机的输入数据所需的单步用时部分。绿色区域显示设备的实际工作时长。
- 单步用时统计信息:报告设备单步用时的平均值、标准差和范围([最小值,最大值])
主机端分析
主机端分析将主机上的输入处理时间(tf.data API 运算所用的时间)细分为以下几类:
- Reading data from files on demand:在没有缓存、预提取和交错的情况下从文件读取数据所用的时间。
- Reading data from files in advance:读取文件所用的时间,包括缓存、预提取和交错。
- Data preprocessing:预处理运算所用的时间,例如图像解压缩。
- Enqueuing data to be transferred to device:向设备传输数据之前将数据加入馈入队列所用的时间。
展开 Input Op Statistics 可以看到各个输入运算及其按执行时间分类的统计信息。
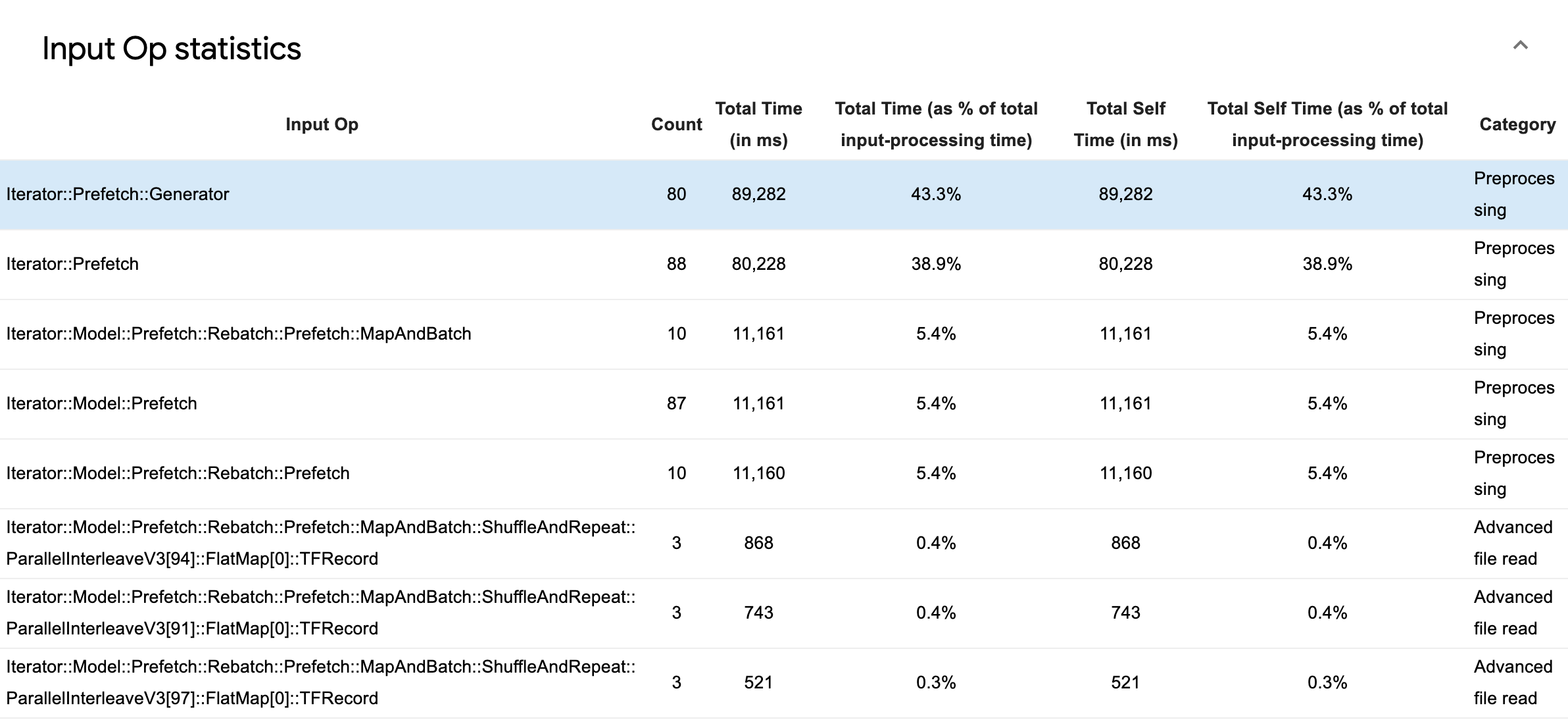
源数据表中的每个条目都包含以下信息:
- Input Op:显示输入运算的 TensorFlow 运算名称。
- Count:显示性能剖析期间运算执行的实例总数。
- Total Time (in ms):显示每个实例所用时间的累计和。
- Total Time %:显示在一个运算上花费的总时间占输入处理总时间的比例。
- Total Self Time (in ms) - 显示其中每个实例所用的自我时间的累计和。此处的自我时间是指在函数体内部所用的时间,不包括它调用的函数所用的时间。
- Total Self Time % - 显示在总自我时间占输入处理总时间的比例
- Category - 显示输入运算的处理类别。
TensorFlow Stats
TensorFlow Stats 工具可以显示性能剖析会话期间在主机或设备上执行的每个 TensorFlow 运算的性能。
该工具在两个窗格中显示性能信息:
上部窗格最多会显示四个饼图:
- 主机上每个运算自我执行时间的分布。
- 主机上每个运算自我执行时间的分布。
- 设备上每个运算自我执行时间的分布。
- 设备上每个运算自我执行时间的分布。
下部窗格显示了一个表,该表会报告 TensorFlow 运算的数据,其中每个运算占据一行,每种数据类型为一列(点击列标题可对列进行排序)。点击上部窗格右侧的 Export as CSV 按钮可将此表中的数据导出为 CSV 文件。
请注意:
如果任何运算有子运算:
- 运算的总“累计”时间不包括子运算所用的时间。
- 运算的总“自我”时间不包括子运算所用的时间。
如果某个运算在主机上执行:
- 此运算所占用设备上的总自我时间百分比将为 0。
- 直到并包括此运算的设备上总自用时间的累计百分比将为 0。
如果某个运算在设备上执行:
- 此运算所占用主机上的总自我时间百分比将为 0。
- 直到并包括此运算的主机上总自我时间的累计百分比将为 0。
您可以选择在饼图和表中包含或排除空闲时间。
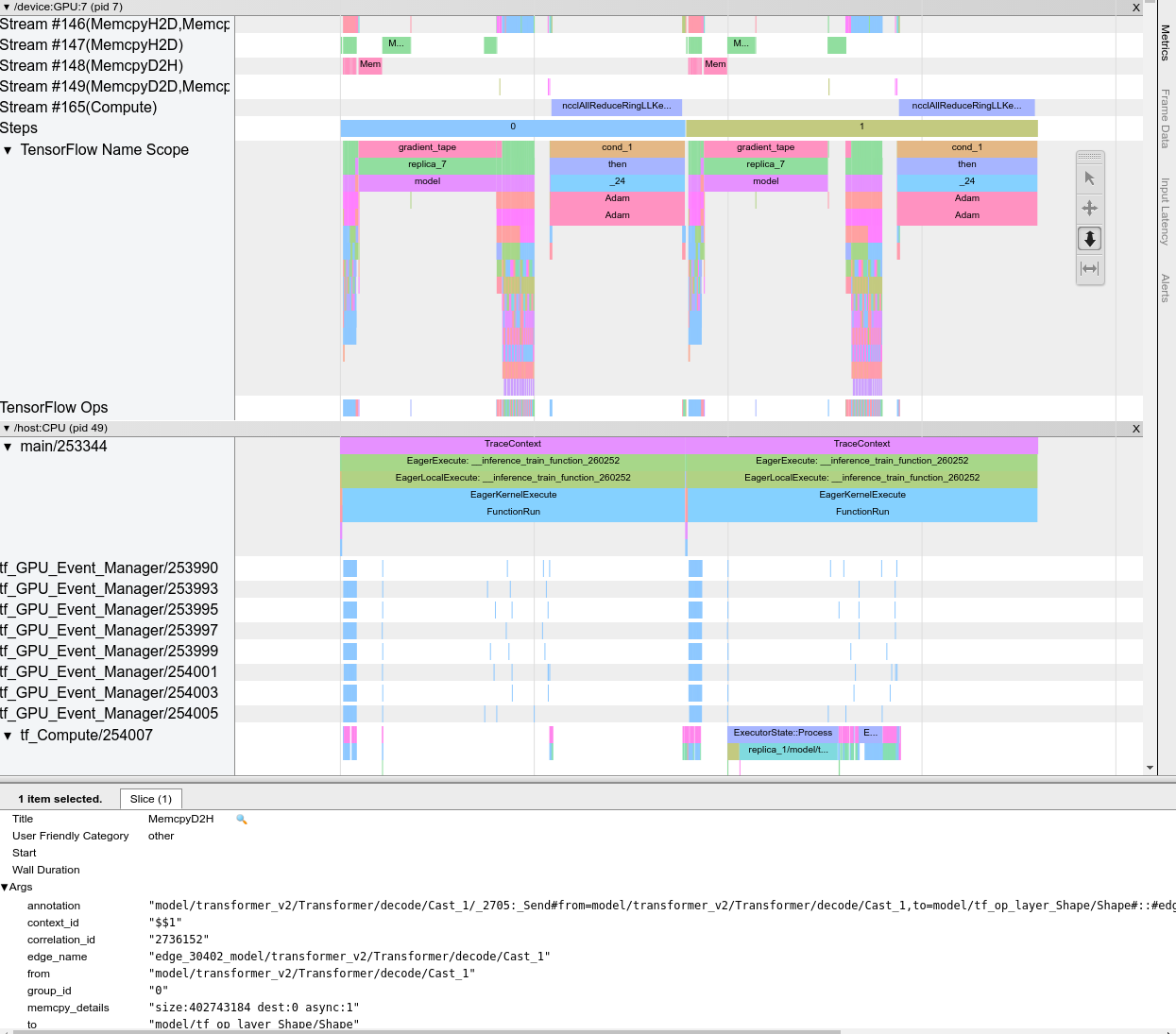
Trace Viewer
Trace Viewer 会显示一个包含以下信息的时间线:
- TensorFlow 模型所执行运算的持续时间
- 系统的哪个部分(主机还是设备)执行了运算。一般来说,主机会执行输入运算,预处理训练数据并将其传输到设备,而设备则执行实际模型训练
借助 Trace Viewer,您可以确定模型中的性能问题,然后采取措施解决这些问题。例如,您既可以从较高的层面确定是输入还是模型训练占用了大部分时间,又可以根据明细了解哪个运算占用了最长的执行时间。请注意,Trace Viewer 被限制为每个设备 100 万个事件。
Trace Viewer 界面
当您打开 Trace Viewer 时,它会显示您最近的运行:

此画面包含以下主要元素:
- Timeline 窗格:显示设备和主机在一段时间内执行的运算。
- Details 窗格:显示 Timeline 窗格中选择的运算的其他信息。
Timeline 窗格包含以下元素:
- 顶栏:包含各种辅助控件。
- 时间轴:显示相对于跟踪记录开始的时间。
- 板块和轨道标签:每个版块都包含多个轨道,并且左侧有一个三角形,点击该三角形可以展开和收起相应的版块。系统中的每个处理元素都有一个版块。
- 工具选择器:包含与 Trace Viewer 交互的各种工具,例如 Zoom、Pan、Select 和 Timing。使用 Timing 工具可以标记时间间隔。
- Events:显示运算的执行时间或者元事件(例如训练步骤)的持续时间。
版块和轨道
Trace Viewer 包含以下版块:
- 每个设备节点一个版块,使用设备芯片编号和芯片内的设备节点进行标记(例如,
/device:GPU:0 (pid 0))。每个节点版块都包含以下轨道:- Step:显示在设备上运行的训练步骤的持续时间
- TensorFlow Ops:显示在设备上执行的运算
- XLA Ops - 如果使用的编译器是 XLA,则显示在设备上运行的 XLA 运算(每个 TensorFlow 运算都会转换成一个或多个 XLA 运算。XLA 编译器可以将 XLA 运算转换成在设备上运行的代码)。
- 用于在主机的 CPU 上运行的线程的版块,标有 Host Threads。该版块为每个 CPU 线程包含一个轨道。请注意,您可以忽略显示的信息和版块标签。
事件
时间线内的事件以不同的颜色显示;颜色本身没有特定含义。
Trace Viewer 还可以显示您的 TensorFlow 程序中 Python 函数调用的跟踪记录。如果您使用 tf.profiler.experimental.start() API,可以在开始性能剖析时使用 ProfilerOptions 命名元组启用 Python 跟踪。或者,如果您使用采样模式进行性能剖析,可以使用 Capture Profile 对话框中的下拉选项选择跟踪级别。
GPU Kernel Stats
此工具可以显示性能统计信息以及每个 GPU 加速内核的源运算。
该工具在两个窗格中显示信息:
上部窗格显示了一个饼图,其中所示为经过的总时间最长的 CUDA 内核
下部窗格显示了一个表,其中包含每个内核-运算对的以下数据:
- 按内核-运算对分组,经过的总 GPU 持续时间的降序排名。
- 启动的内核的名称。
- 内核使用的 GPU 寄存器的数量。
- 使用的共享(静态 + 动态共享)内存的总大小(以字节为单位)。
- 以
blockDim.x, blockDim.y, blockDim.z形式表示的块尺寸。 - 以
gridDim.x, gridDim.y, gridDim.z形式表示的网格尺寸。 - 运算是否可以使用 Tensor Cores。
- 内核是否包含 Tensor Core 指令。
- 启动此内核的运算的名称。
- 此内核-运算对出现的次数。
- 经过的总 GPU 时间(以毫秒为单位)。
- 经过的平均 GPU 时间(以毫秒为单位)。
- 经过的最短 GPU 时间(以毫秒为单位)。
- 经过的最长 GPU 时间(以毫秒为单位)。
内存性能剖析工具
内存性能剖析工具可在性能剖析间隔期间监视设备的内存使用量。您可以使用此工具执行以下操作:
- 通过查明峰值内存使用量和为 TensorFlow 运算分配的相应内存来调试内存不足 (OOM) 问题。您还可以调试运行多租户推断时可能出现的 OOM 问题
- 调试内存碎片问题。
内存性能剖析工具在三个版块中显示数据:
- 内存性能剖析摘要
- 内存时间线图
- 内存明细表
内存性能剖析摘要
此版块显示 TensorFlow 程序的内存性能剖析的简明摘要,具体如下所示:
<img src="./images/tf_profiler/memory_profile_summary.png" width="400", height="450">
内存性能剖析摘要包含以下六个字段:
- Memory ID:列出所有可用设备内存系统的下拉列表。从下拉列表中选择要查看的内存系统。
- #Allocation:性能剖析间隔内进行的内存分配数。
- #Deallocation:性能剖析间隔中的内存释放数。
- Memory Capacity:您选择的内存系统的总容量(以 GiB 为单位)。
- Peak Heap Usage:自模型开始运行以来的峰值内存使用量(以 GiB 为单位)。
- Peak Memory Usage:性能剖析间隔中的峰值内存使用量(以 GiB 为单位)。此字段包含以下子字段:
- Timestamp:时间线图上出现峰值内存使用量的时间戳。
- Stack Reservation:堆栈上保留的内存量(以 GiB 为单位)。
- Heap Allocation:堆上分配的内存量(以 GiB 为单位)。
- Free Memory:可用内存量(以 GiB 为单位)。内存容量等于堆栈预留、堆分配和可用内存的总和。
- Fragmentation:碎片百分比(越低越好)。它的计算方式为
(1 - Size of the largest chunk of free memory / Total free memory)。
内存时间线图
此版块显示了内存使用量(以 GiB 为单位)以及碎片百分比与时间(以毫秒为单位)关系图。

X 轴表示性能剖析间隔的时间线(以毫秒为单位)。左侧的 Y 轴表示内存使用量(以 GiB 为单位),右侧的 Y 轴表示碎片百分比。在 X 轴上的每个时间点,总内存都分为三类:堆栈(红色)、堆(橙色)和可用(绿色)。将鼠标悬停在特定的时间戳上可以查看有关此时内存分配/释放事件的详细信息,具体如下所示:

弹出窗口显示以下信息:
- timestamp(ms):所选事件在时间线上的位置。
- event:事件的类型(分配或释放)。
- requested_size(GiBs):请求的内存量。对于释放事件,这将是负数。
- allocation_size(GiBs):实际分配的内存量。对于释放事件,这将是负数。
- tf_op:请求分配/释放的 TensorFlow 运算。
- step_id:发生此事件的训练步骤。
- region_type:使用此已分配内存的数据实体类型。可能的值包括临时变量的
temp、激活和梯度的output以及权重和常量的persist/dynamic。 - data_type:张量元素类型(例如,uint8 表示 8 位无符号整数)。
- tensor_shape:所分配/已释放张量的形状。
- memory_in_use(GiBs):此时间点正在使用的总内存。
内存明细表
此表显示了性能剖析间隔中处于峰值内存使用量时的有效内存分配。
每个 TensorFlow 运算对应一行,每行都包括以下列:
- Op Name:TensorFlow 运算的名称。
- Allocation Size (GiBs):分配给此运算的内存总量。
- Requested Size (GiBs):此运算请求的总内存量。
- Occurrences:此运算的分配数。
- Region type:使用此已分配内存的数据实体类型。可能的值包括临时变量的
temp、激活和梯度的output以及权重和常量的persist/dynamic。 - Data type:张量元素类型。
- Shape:已分配张量的形状。
注:您可以对表中的任何列进行排序,还可以按运算名称筛选行。
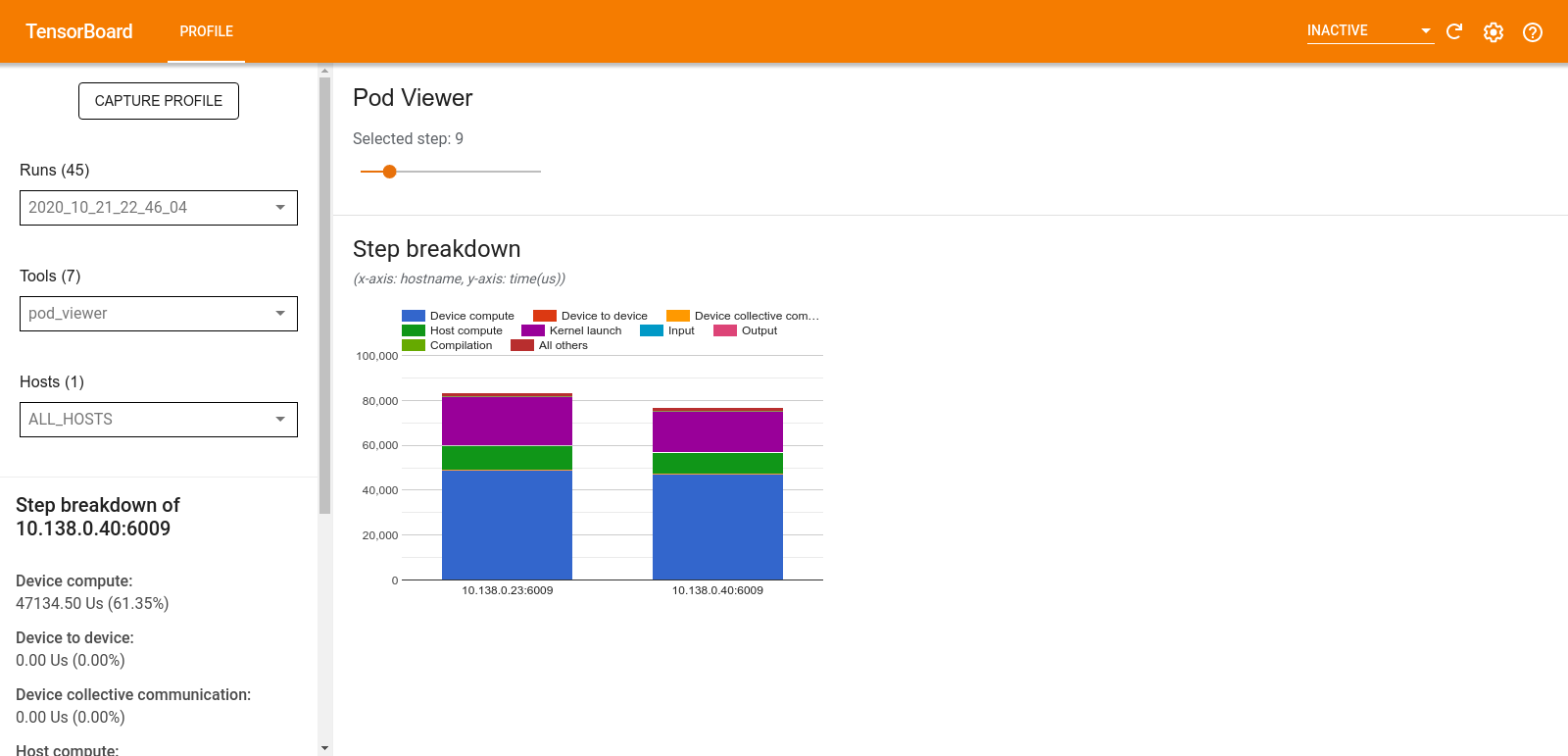
Pod Viewer
Pod Viewer 工具可以显示一个训练步骤在所有工作进程中的细分。

- 上部窗格具有用于选择步骤编号的滑块。
- 下部窗格显示堆叠的柱状图。这是细分的步骤-时间类别彼此叠加的高级视图。每个堆叠的柱状图代表一个唯一的工作进程。
- 当您将鼠标悬停在堆叠的柱状图上时,左侧的卡片会显示有关步骤细分的更多详细信息。
tf.data 瓶颈分析
警告:此工具是实验性的。如果分析结果看起来不正确,请提交 GitHub 议题。
tf.data 瓶颈分析会自动检测程序中 tf.data 输入流水线中的瓶颈,并提供有关如何解决它们的建议。它适用于使用 tf.data 的任何程序,无论采用哪个平台 (CPU/GPU/TPU)。分析和建议均基于这篇指南。
它通过按以下步骤操作来检测瓶颈:
- 找到最受输入约束的主机。
- 找到执行速度最慢的
tf.data输入流水线。 - 根据 Profiler 跟踪记录重新构造输入流水线计算图。
- 在输入流水线计算图中找到关键路径。
- 将关键路径上最慢的转换确定为瓶颈。
界面分为三个版块:Performance Analysis Summary、Summary of All Input Pipelines 和 Input Pipeline Graph。
Performance Analysis Summary

此版块提供了分析的摘要。它会报告在性能剖析中是否检测到较慢的 tf.data 输入流水线。此版块还会显示最受输入约束的主机及其最慢且具有最大延迟的输入流水线。最重要的是,它会识别输入流水线的哪一部分是瓶颈以及如何解决该瓶颈。瓶颈信息通过迭代器类型及其长名称提供。
如何读取 tf.data 迭代器的长名称
长名称的格式为 Iterator::<Dataset_1>::...::<Dataset_n>。在长名称中,<Dataset_n> 与迭代器类型匹配,长名称中的其他数据集表示下游转换。
例如,考虑以下输入流水线数据集:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
上面数据集中迭代器的长名称为:
| 迭代器类型 | 长名称 |
|---|---|
| 范围 | Iterator::Batch::Repeat::Map::Range |
| 映射 | Iterator::Batch::Repeat::Map |
| 重复 | Iterator::Batch::Repeat |
| 批次 | Iterator::Batch |
所有输入流水线的摘要

本部分提供了所有主机上的所有输入流水线的摘要。通常只有一个输入流水线。使用分配策略时,有一个主机输入流水线运行程序的 tf.data 代码,多个设备输入流水线从主机输入流水线中检索数据并将其传送到设备。
对于每个输入流水线,它显示其执行时间的统计信息。如果调用花费的时间超过 50μs,则算作缓慢。
输入流水线图

此版块显示了输入流水线计算图及执行时间信息。您可以使用“Host”和“Input Pipeline”选择要查看的主机和输入流水线。输入流水线的执行按执行时间降序排列,您可以使用 Rank 下拉菜单选择排序方式。
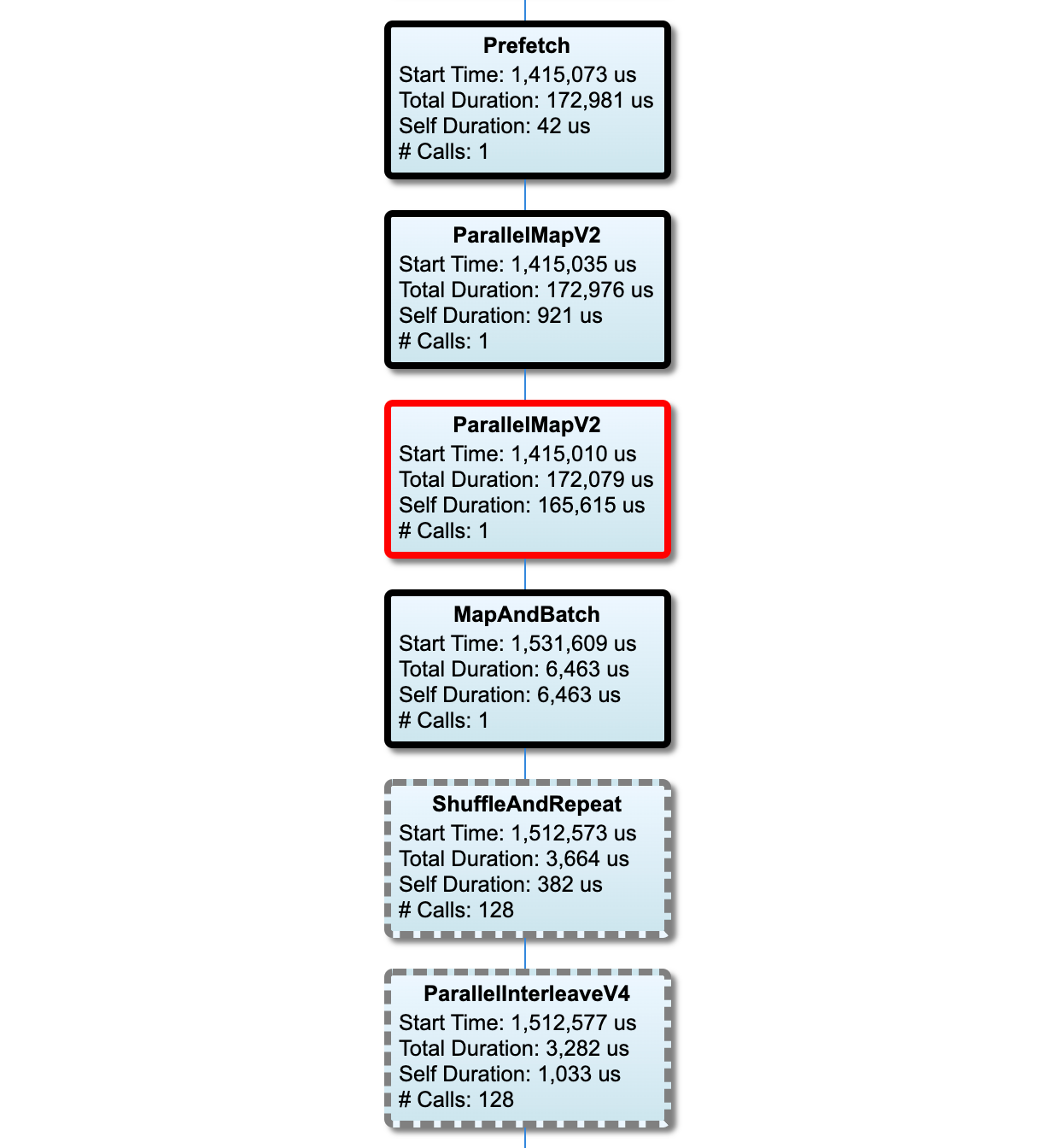
关键路径上的节点具有加粗轮廓。瓶颈节点(在关键路径上具有最长自用时间的节点)具有红色轮廓。其他非关键节点具有灰色虚线轮廓。
在每个节点中,Start Time 表示执行的开始时间。例如,如果输入流水线中存在 Batch 运算,则可以多次执行同一节点。如果多次执行,则为第一次执行的开始时间。
Total Duration 是执行的实际时间。如果多次执行,则为所有执行的实际时间之和。
Self Time 是不包含与其直接子节点的重叠时间的 Total Time。
“# Calls”是输入流水线的执行次数。
收集性能数据
TensorFlow Profiler 可以收集您的 TensorFlow 模型的主机活动和 GPU 跟踪记录。您可以将 Profiler 配置为通过编程模式或采样模式收集性能数据。
性能剖析 API
您可以使用以下 API 执行性能剖析。
使用 TensorBoard Keras 回调 (
tf.keras.callbacks.TensorBoard) 的编程模式# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])使用
tf.profilerFunction API 的编程模式tf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()使用上下文管理器的编程模式
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
注:过长时间地运行 Profiler 可能会导致其耗尽内存。建议每次剖析不超过 10 个步骤的性能。为了避免由初始化开销导致的不准确,请不要剖析前几个批次的性能。
采样模式:使用
tf.profiler.experimental.server.start()启动 gRPC 服务器并运行您的 TensorFlow 模型,执行按需性能剖析。在启动 gRPC 服务器并运行模型后,您可以通过 TensorBoard 性能剖析插件中的 Capture Profile 按钮捕获性能剖析文件。使用上文“安装 Profiler”部分中的脚本启动 TensorBoard 实例(如果尚未运行)。例如,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)剖析多个工作进程性能的示例:
# E.g. your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
<img src="./images/tf_profiler/capture_profile.png" width="400", height="450">
使用 Capture Profile 对话框指定以下信息:
- 以逗号分隔的性能剖析服务网址或 TPU 名称列表。
- 性能剖析持续时间
- 设备、主机和 Python 函数调用跟踪的级别
- 在首次不成功时,您希望 Profiler 重新尝试捕获性能剖析文件的次数
剖析自定义训练循环的性能
要剖析 TensorFlow 代码中自定义训练循环的性能,请使用tf.profiler.experimental.Trace API 对训练循环进行插桩,为 Profiler 标记步骤边界。
name 参数用作步骤名称的前缀,step_num 关键字参数追加到步骤名称中,_r 关键字参数使此跟踪事件可由 Profiler 作为步骤事件处理。
例如,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
这将启用 Profiler 的分步性能分析并使步骤事件显示在 Trace Viewer 中。
确保您将数据集迭代器包含在 tf.profiler.experimental.Trace 上下文中,以便对输入流水线进行准确分析。
以下代码段是一种反模式:
警告:这将导致输入流水线的分析不准确。
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
性能剖析用例
Profiler 在四个不同的轴上涵盖了许多用例。目前已支持部分组合,将来还会添加其他组合。其中一些用例包括:
- 本地与远程性能剖析:您可以通过两种常见方式设置性能剖析环境。在本地性能剖析中,将在执行模型的同一个计算机(例如带 GPU 的本地工作站)上调用性能剖析 API。在远程性能剖析中,将在与执行模型不同的计算机(例如 Cloud TPU)上调用性能剖析 API。
- 剖析多个工作进程的性能:您可以使用 TensorFlow 的分布式训练功能剖析多个机器的性能。
- 硬件平台:性能剖析 CPU、GPU 和 TPU。
下表提供了上文提及的 TensorFlow 支持的用例的概况:
| 性能剖析 API | 本地 | 远程 | 多 | 硬件 | : : : : 工作进程 : 平台 : | :--------------------------- | :-------- | :-------- | :-------- | :-------- | | TensorBoard Keras | 支持 | 不 | 不 | CPU、GPU | : Callback : : 支持 : 支持 : : | tf.profiler.experimental | 支持 | Not | 不 | CPU、GPU | : start/stop API : : 支持 : 支持 : : | tf.profiler.experimental | 支持 | 支持 | 支持 | CPU、GPU、| : client.trace API : : : : TPU : | Context manager API | 支持 | 不 | 不 | CPU、GPU | : : : 支持 : 支持 : :
实现最佳模型性能的最佳做法
在您的 TensorFlow 模型中根据以下建议(如适用)操作以实现最佳性能。
通常,请在设备上执行所有转换,并确保在平台上使用 cuDNN 和 Intel MKL 等库的最新兼容版本。
优化输入数据流水线
使用来自 [#input_pipeline_analyzer] 的数据优化您的数据输入流水线。高效的数据输入流水线可以通过减少设备空闲时间来显著提高模型执行速度。尝试将使用 tf.data API 提升性能指南中详述的最佳做法与下面的内容相结合,以提高您的数据输入流水线的效率。
通常,并行化任何不需要顺序执行的运算可以显著优化数据输入流水线。
在许多情况下,它有助于更改某些调用的顺序或调整参数以使其最适合您的模型。在优化输入数据流水线时,仅对数据加载器进行基准分析,而无需训练和反向传播步骤,以便独立量化优化的效果。
尝试使用合成数据运行您的模型以了解输入流水线是否为性能瓶颈。
使用
tf.data.Dataset.shard进行多 GPU 训练。确保在输入循环中尽早进行分片,以避免吞吐量降低。使用 TFRecords 时,确保对 TFRecords 列表而不是 TFRecords 的内容进行分片。通过使用
tf.data.AUTOTUNE动态设置num_parallel_calls的值来并行化多个运算。考虑限制
tf.data.Dataset.from_generator的使用,因为与纯 TensorFlow 运算相比,它的速度更慢。考虑限制
tf.py_function的使用,因为它不能被序列化并且不支持在分布式 TensorFlow 中运行。使用
tf.data.Options控制对输入流水线的静态优化。
另请阅读 tf.data 性能分析指南,以获取有关优化输入流水线的更多指导。
优化数据增强
在处理图像数据时,通过在应用空间转换(例如翻转、裁剪、旋转等)后转换为不同的数据类型,使您的数据增强更高效。
注:像 tf.image.resize 这样的某些运算会以透明方式将 dtype 更改为 fp32。如果没有自动完成,请确保将数据归一化为介于 0 和 1 之间的值。如果您已启用 AMP,则跳过此步骤可能会导致 NaN 错误。
使用 NVIDIA® DALI
在某些情况下,例如当您的系统具有较高的 GPU 与 CPU 比率时,上述所有优化可能不足以消除由于 CPU 周期限制而导致的数据加载器瓶颈。
如果您将 NVIDIA® GPU 用于计算机视觉和音频深度学习应用,请考虑使用数据加载库 (DALI) 来加速数据流水线。
查看 NVIDIA® DALI:运算文档来获取支持的 DALI 运算列表。
使用线程和并行执行
使用 tf.config.threading API 在多个 CPU 线程上运行运算以提高它们的执行速度。
TensorFlow 默认会自动设置并行线程数。可用于运行 TensorFlow 运算的线程池取决于可用的 CPU 线程数。
使用 tf.config.threading.set_intra_op_parallelism_threads 控制单个运算的最大并行加速。请注意,如果您并行运行多个运算,它们都将共享可用的线程池。
如果您有独立的非阻塞运算(计算图上彼此之间没有定向路径的运算),请使用 tf.config.threading.set_inter_op_parallelism_threads 以利用可用的线程池同时运行它们。
其他
在 NVIDIA® GPU 上使用较小的模型时,您可以设置 tf.compat.v1.ConfigProto.force_gpu_compatible=True 来强制使用 CUDA 固定内存分配所有 CPU 张量,从而显著提升模型性能。但是,在对未知/非常大的模型使用此选项时要格外小心,因为这可能会对主机 (CPU) 性能产生负面影响。
提升设备性能
遵循此处和 GPU 性能优化指南中详述的最佳做法来优化设备端 TensorFlow 模型性能。
如果您使用的是 NVIDIA GPU,请通过运行以下命令将 GPU 和内存利用率记录到 CSV 文件中:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
配置数据布局
处理包含通道信息的数据(如图像)时,优化数据布局格式以优先选择通道在后(NHWC 优先于 NCHW)。
通道在后数据格式提高了 Tensor Core 的利用率并提供了明显的性能改进,尤其是在与 AMP 结合使用的卷积模型中。NCHW 数据布局仍然可以由 Tensor Core 进行运算,但是,这会因自动转置运算的出现而引入额外的开销。
您可以通过为 tf.keras.layers.Conv2D、tf.keras.layers.Conv3D 和 tf.keras.layers.RandomRotation 等层设置 data_format="channels_last" 来优化数据布局以优先选择 NHWC 布局。
使用 tf.keras.backend.set_image_data_format 设置 Keras 后端 API 的默认数据布局格式。
最大化 L2 缓存
使用 NVIDIA® GPU 时,在训练循环之前执行下面的代码段,将 L2 获取粒度最大化为 128 字节。
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
配置 GPU 线程使用率
GPU 线程模式决定如何使用 GPU 线程。
将线程模式设置为 gpu_private 以确保预处理不会窃取所有 GPU 线程。这将缩短训练期间的内核启动延迟。此外,您还可以设置每个 GPU 的线程数。使用环境变量设置这些值。
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
配置 GPU 内存选项
通常,增加批次大小并调整模型大小可以更好地利用 GPU 并获得更高的吞吐量。请注意,增加批次大小会改变模型的准确率,因此需要通过调整学习率等超参数来调整模型大小,以满足目标准确率要求。
此外,使用 tf.config.experimental.set_memory_growth 允许 GPU 内存增长,以避免所有可用内存全部分配给只需要一小部分内存的运算。这允许消耗 GPU 内存的其他进程在同一设备上运行。
要了解更多信息,请查看 GPU 指南中的限制 GPU 内存增长指导。
其他
将训练 mini-batch 大小(训练循环的一次迭代中每个设备使用的训练样本数)增加到不会导致 GPU 上发生内存不足 (OOM) 错误的最大数量。增加批次大小会影响模型的准确率,因此请确保通过调整超参数来调整模型大小,以满足目标准确率要求。
在生产代码中的张量分配期间禁用报告 OOM 错误。在
tf.compat.v1.RunOptions中设置report_tensor_allocations_upon_oom=False。对于具有卷积层的模型,如果使用批次归一化,请移除添加的偏差。批次归一化按其平均值移动值,这样便无需具有恒定的偏差项。
使用 TF Stats 了解设备端运算的运行效率。
使用
tf.function执行计算,并且可以选择启用jit_compile=True标志 (tf.function(jit_compile=True)。要了解更详情,请转到使用 XLA tf.function。最大程度减少步骤之间的主机 Python 运算并减少回调。每几步(而不是每一步)计算指标
使设备计算单元保持忙碌状态。
将数据同时发送到多个设备。
考虑使用 16 位数字表示,例如
fp16(IEEE 指定的半精度浮点格式)或者大脑浮点 bfloat16 格式。
其他资源
- TensorFlow Profiler:剖析模型性能教程,包含 Keras 和 TensorBoard,您可以在其中应用本指南中的建议。
- TensorFlow Dev Summit 2020 上的 TensorFlow 2 中的性能剖析演讲。
- TensorFlow Dev Summit 2020 上的 TensorFlow Profiler 演示。
已知问题/限制
在 TensorFlow 2.2 和 TensorFlow 2.3 上剖析多个 GPU 的性能
TensorFlow 2.2 和 2.3 仅支持单主机系统的多 GPU 性能剖析;不支持多主机系统的多 GPU 性能剖析。要剖析多工作进程 GPU 配置的性能,必须单独剖析每个工作进程的性能。从 TensorFlow 2.4 起,可以使用 tf.profiler.experimental.trace API 剖析多个工作进程的性能。
需要 CUDA® Toolkit 10.2 或更高版本才能剖析多个 GPU 的性能。由于 TensorFlow 2.2 和 2.3 仅支持 10.1 及更低版本的 CUDA® Toolkit 版本,您需要创建 libcudart.so.10.1 和 libcupti.so.10.1 的符号链接。
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1