
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
ওভারভিউ
এই টিউটোরিয়ালটি কিভাবে প্রমান TensorFlow জাফরি (TfL) গ্রন্থাগার ট্রেন মডেলের যে দায়িত্বের আচরণ করে ব্যবহার করা যেতে পারে, এবং কিছু অনুমানের যে নৈতিক বা ন্যায্য লঙ্ঘন করবেন না। বিশেষ করে, আমরা monotonicity সীমাবদ্ধতার ব্যবহার নির্দিষ্ট গুণাবলীর অন্যায্য দণ্ডনীয়তা এড়ানোর জন্য উপর ফোকাস করা। এই টিউটোরিয়ালটি কাগজ থেকে পরীক্ষা-নিরীক্ষা বিক্ষোভ অন্তর্ভুক্ত Deontological এথিক্স অনুযায়ী Monotonicity আকৃতি সীমাবদ্ধতাসমূহ সেরেনার ওয়াং মায়া গুপ্ত, দ্বারা প্রকাশিত AISTATS 2020 ।
আমরা পাবলিক ডেটাসেটে TFL টিনজাত অনুমানকারী ব্যবহার করব, কিন্তু মনে রাখবেন যে এই টিউটোরিয়ালের সমস্ত কিছু TFL Keras স্তরগুলি থেকে নির্মিত মডেলগুলির সাথেও করা যেতে পারে।
এগিয়ে যাওয়ার আগে, নিশ্চিত করুন যে আপনার রানটাইমে সমস্ত প্রয়োজনীয় প্যাকেজ ইনস্টল করা আছে (নিচের কোড কক্ষে আমদানি করা হয়েছে)।
সেটআপ
টিএফ ল্যাটিস প্যাকেজ ইনস্টল করা হচ্ছে:
pip install tensorflow-lattice seaborn
প্রয়োজনীয় প্যাকেজ আমদানি করা হচ্ছে:
import tensorflow as tf
import logging
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
এই টিউটোরিয়ালে ব্যবহৃত ডিফল্ট মান:
# List of learning rate hyperparameters to try.
# For a longer list of reasonable hyperparameters, try [0.001, 0.01, 0.1].
LEARNING_RATES = [0.01]
# Default number of training epochs and batch sizes.
NUM_EPOCHS = 1000
BATCH_SIZE = 1000
# Directory containing dataset files.
DATA_DIR = 'https://raw.githubusercontent.com/serenalwang/shape_constraints_for_ethics/master'
কেস স্টাডি #1: ল স্কুলে ভর্তি
এই টিউটোরিয়ালের প্রথম অংশে, আমরা ল স্কুল অ্যাডমিশন কাউন্সিল (LSAC) থেকে ল স্কুল অ্যাডমিশন ডেটাসেট ব্যবহার করে একটি কেস স্টাডি বিবেচনা করব। একজন শিক্ষার্থী দুটি বৈশিষ্ট্য ব্যবহার করে বারটি পাস করবে কিনা তা ভবিষ্যদ্বাণী করার জন্য আমরা একটি শ্রেণিবদ্ধকারীকে প্রশিক্ষণ দেব: শিক্ষার্থীর LSAT স্কোর এবং স্নাতক GPA।
ধরুন যে ক্লাসিফায়ারের স্কোরটি আইন স্কুলে ভর্তি বা বৃত্তি নির্দেশ করতে ব্যবহৃত হয়েছিল। মেধা-ভিত্তিক সামাজিক নিয়ম অনুসারে, আমরা আশা করব যে উচ্চতর GPA এবং উচ্চতর LSAT স্কোর সহ শিক্ষার্থীরা ক্লাসিফায়ারের কাছ থেকে উচ্চতর স্কোর পাবে। যাইহোক, আমরা লক্ষ্য করব যে মডেলগুলির পক্ষে এই স্বজ্ঞাত নিয়মগুলি লঙ্ঘন করা সহজ এবং কখনও কখনও উচ্চতর GPA বা LSAT স্কোর থাকার জন্য লোকেদের শাস্তি দেওয়া হয়।
এই অন্যায্য দণ্ডনীয়তা সমস্যা মোকাবেলার জন্য আমরা monotonicity সীমাবদ্ধতার যাতে একটি মডেল কখনোই penalizes উচ্চতর জিপিএ বা উচ্চতর LSAT স্কোর, সব অন্য সমান আরোপ করতে পারেন। এই টিউটোরিয়ালে, আমরা টিএফএল ব্যবহার করে সেই একঘেয়েমি সীমাবদ্ধতাগুলি কীভাবে আরোপ করা যায় তা দেখাব।
আইন স্কুল ডেটা লোড করুন
# Load data file.
law_file_name = 'lsac.csv'
law_file_path = os.path.join(DATA_DIR, law_file_name)
raw_law_df = pd.read_csv(law_file_path, delimiter=',')
প্রিপ্রসেস ডেটাসেট:
# Define label column name.
LAW_LABEL = 'pass_bar'
def preprocess_law_data(input_df):
# Drop rows with where the label or features of interest are missing.
output_df = input_df[~input_df[LAW_LABEL].isna() & ~input_df['ugpa'].isna() &
(input_df['ugpa'] > 0) & ~input_df['lsat'].isna()]
return output_df
law_df = preprocess_law_data(raw_law_df)
ট্রেন/বৈধতা/পরীক্ষা সেটে ডেটা বিভক্ত করুন
def split_dataset(input_df, random_state=888):
"""Splits an input dataset into train, val, and test sets."""
train_df, test_val_df = train_test_split(
input_df, test_size=0.3, random_state=random_state)
val_df, test_df = train_test_split(
test_val_df, test_size=0.66, random_state=random_state)
return train_df, val_df, test_df
law_train_df, law_val_df, law_test_df = split_dataset(law_df)
তথ্য বিতরণ কল্পনা করুন
প্রথমে আমরা তথ্যের বিতরণ কল্পনা করব। বার পাশ করা সমস্ত ছাত্রদের জন্য এবং বার পাশ না করা সমস্ত ছাত্রদের জন্য আমরা GPA এবং LSAT স্কোর প্লট করব।
def plot_dataset_contour(input_df, title):
plt.rcParams['font.family'] = ['serif']
g = sns.jointplot(
x='ugpa',
y='lsat',
data=input_df,
kind='kde',
xlim=[1.4, 4],
ylim=[0, 50])
g.plot_joint(plt.scatter, c='b', s=10, linewidth=1, marker='+')
g.ax_joint.collections[0].set_alpha(0)
g.set_axis_labels('Undergraduate GPA', 'LSAT score', fontsize=14)
g.fig.suptitle(title, fontsize=14)
# Adust plot so that the title fits.
plt.subplots_adjust(top=0.9)
plt.show()
law_df_pos = law_df[law_df[LAW_LABEL] == 1]
plot_dataset_contour(
law_df_pos, title='Distribution of students that passed the bar')

law_df_neg = law_df[law_df[LAW_LABEL] == 0]
plot_dataset_contour(
law_df_neg, title='Distribution of students that failed the bar')

বার পরীক্ষা পাসের পূর্বাভাস দিতে ক্যালিব্রেটেড রৈখিক মডেল ট্রেন করুন
এর পরে, আমরা TfL থেকে একটি মডেলটির ক্রমাঙ্ক রৈখিক মডেল প্রশিক্ষণ ভবিষ্যদ্বাণী করা হোক বা না হোক একজন ছাত্র বার পাস করবে। দুটি ইনপুট বৈশিষ্ট্য হবে LSAT স্কোর এবং স্নাতক GPA, এবং প্রশিক্ষণের লেবেল হবে শিক্ষার্থী বার পাস করেছে কিনা।
আমরা প্রথমে কোনো বাধা ছাড়াই একটি ক্যালিব্রেটেড লিনিয়ার মডেলকে প্রশিক্ষণ দেব। তারপর, আমরা একঘেয়ে সীমাবদ্ধতা সহ একটি ক্যালিব্রেটেড লিনিয়ার মডেলকে প্রশিক্ষণ দেব এবং মডেলের আউটপুট এবং নির্ভুলতার পার্থক্য পর্যবেক্ষণ করব।
টিএফএল ক্যালিব্রেটেড লিনিয়ার এস্টিমেটর প্রশিক্ষণের জন্য হেল্পার ফাংশন
এই ফাংশনগুলি এই ল স্কুল কেস স্টাডির পাশাপাশি নীচের ক্রেডিট ডিফল্ট কেস স্টাডির জন্য ব্যবহার করা হবে।
def train_tfl_estimator(train_df, monotonicity, learning_rate, num_epochs,
batch_size, get_input_fn,
get_feature_columns_and_configs):
"""Trains a TFL calibrated linear estimator.
Args:
train_df: pandas dataframe containing training data.
monotonicity: if 0, then no monotonicity constraints. If 1, then all
features are constrained to be monotonically increasing.
learning_rate: learning rate of Adam optimizer for gradient descent.
num_epochs: number of training epochs.
batch_size: batch size for each epoch. None means the batch size is the full
dataset size.
get_input_fn: function that returns the input_fn for a TF estimator.
get_feature_columns_and_configs: function that returns TFL feature columns
and configs.
Returns:
estimator: a trained TFL calibrated linear estimator.
"""
feature_columns, feature_configs = get_feature_columns_and_configs(
monotonicity)
model_config = tfl.configs.CalibratedLinearConfig(
feature_configs=feature_configs, use_bias=False)
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=get_input_fn(input_df=train_df, num_epochs=1),
optimizer=tf.keras.optimizers.Adam(learning_rate))
estimator.train(
input_fn=get_input_fn(
input_df=train_df, num_epochs=num_epochs, batch_size=batch_size))
return estimator
def optimize_learning_rates(
train_df,
val_df,
test_df,
monotonicity,
learning_rates,
num_epochs,
batch_size,
get_input_fn,
get_feature_columns_and_configs,
):
"""Optimizes learning rates for TFL estimators.
Args:
train_df: pandas dataframe containing training data.
val_df: pandas dataframe containing validation data.
test_df: pandas dataframe containing test data.
monotonicity: if 0, then no monotonicity constraints. If 1, then all
features are constrained to be monotonically increasing.
learning_rates: list of learning rates to try.
num_epochs: number of training epochs.
batch_size: batch size for each epoch. None means the batch size is the full
dataset size.
get_input_fn: function that returns the input_fn for a TF estimator.
get_feature_columns_and_configs: function that returns TFL feature columns
and configs.
Returns:
A single TFL estimator that achieved the best validation accuracy.
"""
estimators = []
train_accuracies = []
val_accuracies = []
test_accuracies = []
for lr in learning_rates:
estimator = train_tfl_estimator(
train_df=train_df,
monotonicity=monotonicity,
learning_rate=lr,
num_epochs=num_epochs,
batch_size=batch_size,
get_input_fn=get_input_fn,
get_feature_columns_and_configs=get_feature_columns_and_configs)
estimators.append(estimator)
train_acc = estimator.evaluate(
input_fn=get_input_fn(train_df, num_epochs=1))['accuracy']
val_acc = estimator.evaluate(
input_fn=get_input_fn(val_df, num_epochs=1))['accuracy']
test_acc = estimator.evaluate(
input_fn=get_input_fn(test_df, num_epochs=1))['accuracy']
print('accuracies for learning rate %f: train: %f, val: %f, test: %f' %
(lr, train_acc, val_acc, test_acc))
train_accuracies.append(train_acc)
val_accuracies.append(val_acc)
test_accuracies.append(test_acc)
max_index = val_accuracies.index(max(val_accuracies))
return estimators[max_index]
আইন স্কুল ডেটাসেট বৈশিষ্ট্যগুলি কনফিগার করার জন্য সাহায্যকারী ফাংশন
এই সাহায্যকারী ফাংশন আইন স্কুল কেস স্টাডি নির্দিষ্ট.
def get_input_fn_law(input_df, num_epochs, batch_size=None):
"""Gets TF input_fn for law school models."""
return tf.compat.v1.estimator.inputs.pandas_input_fn(
x=input_df[['ugpa', 'lsat']],
y=input_df['pass_bar'],
num_epochs=num_epochs,
batch_size=batch_size or len(input_df),
shuffle=False)
def get_feature_columns_and_configs_law(monotonicity):
"""Gets TFL feature configs for law school models."""
feature_columns = [
tf.feature_column.numeric_column('ugpa'),
tf.feature_column.numeric_column('lsat'),
]
feature_configs = [
tfl.configs.FeatureConfig(
name='ugpa',
lattice_size=2,
pwl_calibration_num_keypoints=20,
monotonicity=monotonicity,
pwl_calibration_always_monotonic=False),
tfl.configs.FeatureConfig(
name='lsat',
lattice_size=2,
pwl_calibration_num_keypoints=20,
monotonicity=monotonicity,
pwl_calibration_always_monotonic=False),
]
return feature_columns, feature_configs
প্রশিক্ষিত মডেল আউটপুট ভিজ্যুয়ালাইজেশন জন্য সাহায্যকারী ফাংশন
def get_predicted_probabilities(estimator, input_df, get_input_fn):
predictions = estimator.predict(
input_fn=get_input_fn(input_df=input_df, num_epochs=1))
return [prediction['probabilities'][1] for prediction in predictions]
def plot_model_contour(estimator, input_df, num_keypoints=20):
x = np.linspace(min(input_df['ugpa']), max(input_df['ugpa']), num_keypoints)
y = np.linspace(min(input_df['lsat']), max(input_df['lsat']), num_keypoints)
x_grid, y_grid = np.meshgrid(x, y)
positions = np.vstack([x_grid.ravel(), y_grid.ravel()])
plot_df = pd.DataFrame(positions.T, columns=['ugpa', 'lsat'])
plot_df[LAW_LABEL] = np.ones(len(plot_df))
predictions = get_predicted_probabilities(
estimator=estimator, input_df=plot_df, get_input_fn=get_input_fn_law)
grid_predictions = np.reshape(predictions, x_grid.shape)
plt.rcParams['font.family'] = ['serif']
plt.contour(
x_grid,
y_grid,
grid_predictions,
colors=('k',),
levels=np.linspace(0, 1, 11))
plt.contourf(
x_grid,
y_grid,
grid_predictions,
cmap=plt.cm.bone,
levels=np.linspace(0, 1, 11)) # levels=np.linspace(0,1,8));
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
cbar = plt.colorbar()
cbar.ax.set_ylabel('Model score', fontsize=20)
cbar.ax.tick_params(labelsize=20)
plt.xlabel('Undergraduate GPA', fontsize=20)
plt.ylabel('LSAT score', fontsize=20)
অসংযত (নন-একঘেয়ে) ক্যালিব্রেটেড লিনিয়ার মডেল ট্রেন
nomon_linear_estimator = optimize_learning_rates(
train_df=law_train_df,
val_df=law_val_df,
test_df=law_test_df,
monotonicity=0,
learning_rates=LEARNING_RATES,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
get_input_fn=get_input_fn_law,
get_feature_columns_and_configs=get_feature_columns_and_configs_law)
2021-09-30 20:56:50.475180: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected accuracies for learning rate 0.010000: train: 0.949061, val: 0.945876, test: 0.951781
plot_model_contour(nomon_linear_estimator, input_df=law_df)
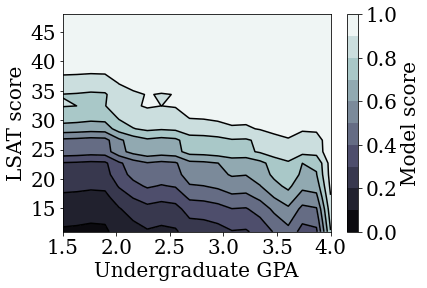
একঘেয়ে ক্যালিব্রেটেড রৈখিক মডেল ট্রেন করুন
mon_linear_estimator = optimize_learning_rates(
train_df=law_train_df,
val_df=law_val_df,
test_df=law_test_df,
monotonicity=1,
learning_rates=LEARNING_RATES,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
get_input_fn=get_input_fn_law,
get_feature_columns_and_configs=get_feature_columns_and_configs_law)
accuracies for learning rate 0.010000: train: 0.949249, val: 0.945447, test: 0.951781
plot_model_contour(mon_linear_estimator, input_df=law_df)

অন্যান্য সীমাবদ্ধ মডেল প্রশিক্ষণ
আমরা দেখিয়েছি যে TFL ক্যালিব্রেটেড লিনিয়ার মডেলগুলিকে LSAT স্কোর এবং GPA উভয় ক্ষেত্রেই একঘেয়ে হতে প্রশিক্ষিত করা যেতে পারে নির্ভুলতার ক্ষেত্রে খুব বেশি ত্যাগ ছাড়াই।
কিন্তু, ডিপ নিউরাল নেটওয়ার্ক (DNN) বা গ্রেডিয়েন্ট বুস্টেড ট্রি (GBTs) এর মতো অন্যান্য ধরনের মডেলের সাথে ক্যালিব্রেটেড লিনিয়ার মডেল কীভাবে তুলনা করে? ডিএনএন এবং জিবিটি-তে কি যুক্তিসঙ্গতভাবে ন্যায্য আউটপুট আছে বলে মনে হচ্ছে? এই প্রশ্নের সমাধান করার জন্য, আমরা পরবর্তীতে একটি সীমাবদ্ধ DNN এবং GBT প্রশিক্ষণ দেব। প্রকৃতপক্ষে, আমরা লক্ষ্য করব যে DNN এবং GBT উভয়ই সহজেই LSAT স্কোর এবং স্নাতক GPA-এ একঘেয়েতা লঙ্ঘন করে।
একটি সীমাবদ্ধ ডিপ নিউরাল নেটওয়ার্ক (DNN) মডেলকে প্রশিক্ষণ দিন
উচ্চ বৈধতা নির্ভুলতা অর্জনের জন্য আর্কিটেকচারটি পূর্বে অপ্টিমাইজ করা হয়েছিল।
feature_names = ['ugpa', 'lsat']
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=[
tf.feature_column.numeric_column(feature) for feature in feature_names
],
hidden_units=[100, 100],
optimizer=tf.keras.optimizers.Adam(learning_rate=0.008),
activation_fn=tf.nn.relu)
dnn_estimator.train(
input_fn=get_input_fn_law(
law_train_df, batch_size=BATCH_SIZE, num_epochs=NUM_EPOCHS))
dnn_train_acc = dnn_estimator.evaluate(
input_fn=get_input_fn_law(law_train_df, num_epochs=1))['accuracy']
dnn_val_acc = dnn_estimator.evaluate(
input_fn=get_input_fn_law(law_val_df, num_epochs=1))['accuracy']
dnn_test_acc = dnn_estimator.evaluate(
input_fn=get_input_fn_law(law_test_df, num_epochs=1))['accuracy']
print('accuracies for DNN: train: %f, val: %f, test: %f' %
(dnn_train_acc, dnn_val_acc, dnn_test_acc))
accuracies for DNN: train: 0.948874, val: 0.946735, test: 0.951559
plot_model_contour(dnn_estimator, input_df=law_df)

একটি সীমাবদ্ধ গ্রেডিয়েন্ট বুস্টেড ট্রিস (GBT) মডেলকে প্রশিক্ষণ দিন
উচ্চ বৈধতা নির্ভুলতা অর্জনের জন্য গাছের গঠন পূর্বে অপ্টিমাইজ করা হয়েছিল।
tree_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=[
tf.feature_column.numeric_column(feature) for feature in feature_names
],
n_batches_per_layer=2,
n_trees=20,
max_depth=4)
tree_estimator.train(
input_fn=get_input_fn_law(
law_train_df, num_epochs=NUM_EPOCHS, batch_size=BATCH_SIZE))
tree_train_acc = tree_estimator.evaluate(
input_fn=get_input_fn_law(law_train_df, num_epochs=1))['accuracy']
tree_val_acc = tree_estimator.evaluate(
input_fn=get_input_fn_law(law_val_df, num_epochs=1))['accuracy']
tree_test_acc = tree_estimator.evaluate(
input_fn=get_input_fn_law(law_test_df, num_epochs=1))['accuracy']
print('accuracies for GBT: train: %f, val: %f, test: %f' %
(tree_train_acc, tree_val_acc, tree_test_acc))
accuracies for GBT: train: 0.949249, val: 0.945017, test: 0.950896
plot_model_contour(tree_estimator, input_df=law_df)

কেস স্টাডি #2: ক্রেডিট ডিফল্ট
দ্বিতীয় কেস স্টাডি যা আমরা এই টিউটোরিয়ালে বিবেচনা করব তা হল একজন ব্যক্তির ক্রেডিট ডিফল্ট সম্ভাবনার পূর্বাভাস। আমরা UCI সংগ্রহস্থল থেকে ক্রেডিট কার্ড ক্লায়েন্ট ডেটাসেটের ডিফল্ট ব্যবহার করব। এই তথ্যটি 30,000 তাইওয়ানিজ ক্রেডিট কার্ড ব্যবহারকারীদের কাছ থেকে সংগ্রহ করা হয়েছে এবং এতে একটি বাইনারি লেবেল রয়েছে যে কোনও ব্যবহারকারী একটি টাইম উইন্ডোতে পেমেন্টে ডিফল্ট করেছে কিনা। বৈশিষ্ট্যগুলির মধ্যে বৈবাহিক অবস্থা, লিঙ্গ, শিক্ষা, এবং 2005 সালের এপ্রিল-সেপ্টেম্বর মাসের প্রতিটির জন্য একজন ব্যবহারকারী তাদের বিদ্যমান বিল পরিশোধে কতক্ষণ পিছিয়ে আছে তা অন্তর্ভুক্ত করে।
যেভাবে আমি প্রথমবার কেস স্টাডি করেছিল, আমরা আবার monotonicity সীমাবদ্ধতার ব্যবহার অন্যায্য দণ্ডনীয়তা এড়ানোর জন্য চিত্রিত যদি মডেল একটি ব্যবহারকারীর ক্রেডিট স্কোর নির্ধারণ করতে ব্যবহার করা হবে, তবে এটাই হল অনেকের কাছে অন্যায্য অনুভব করেছি যদি তারা তাদের বিল শুভস্য পরিশোধ শাস্তি হয়েছে, অন্য সব সমান। এইভাবে, আমরা একটি একঘেয়েমি সীমাবদ্ধতা প্রয়োগ করি যা মডেলটিকে প্রাথমিক অর্থপ্রদানের শাস্তি থেকে বিরত রাখে।
ক্রেডিট ডিফল্ট ডেটা লোড করুন
# Load data file.
credit_file_name = 'credit_default.csv'
credit_file_path = os.path.join(DATA_DIR, credit_file_name)
credit_df = pd.read_csv(credit_file_path, delimiter=',')
# Define label column name.
CREDIT_LABEL = 'default'
ট্রেন/বৈধতা/পরীক্ষা সেটে ডেটা বিভক্ত করুন
credit_train_df, credit_val_df, credit_test_df = split_dataset(credit_df)
তথ্য বিতরণ কল্পনা করুন
প্রথমে আমরা তথ্যের বিতরণ কল্পনা করব। আমরা বিভিন্ন বৈবাহিক অবস্থা এবং ঋণ পরিশোধের অবস্থার লোকেদের জন্য পর্যবেক্ষণকৃত ডিফল্ট হারের গড় এবং মানক ত্রুটি প্লট করব। ঋণ পরিশোধের অবস্থা একজন ব্যক্তি তার ঋণ পরিশোধে কত মাস পিছিয়ে আছে তা প্রতিনিধিত্ব করে (এপ্রিল 2005 অনুযায়ী)।
def get_agg_data(df, x_col, y_col, bins=11):
xbins = pd.cut(df[x_col], bins=bins)
data = df[[x_col, y_col]].groupby(xbins).agg(['mean', 'sem'])
return data
def plot_2d_means_credit(input_df, x_col, y_col, x_label, y_label):
plt.rcParams['font.family'] = ['serif']
_, ax = plt.subplots(nrows=1, ncols=1)
plt.setp(ax.spines.values(), color='black', linewidth=1)
ax.tick_params(
direction='in', length=6, width=1, top=False, right=False, labelsize=18)
df_single = get_agg_data(input_df[input_df['MARRIAGE'] == 1], x_col, y_col)
df_married = get_agg_data(input_df[input_df['MARRIAGE'] == 2], x_col, y_col)
ax.errorbar(
df_single[(x_col, 'mean')],
df_single[(y_col, 'mean')],
xerr=df_single[(x_col, 'sem')],
yerr=df_single[(y_col, 'sem')],
color='orange',
marker='s',
capsize=3,
capthick=1,
label='Single',
markersize=10,
linestyle='')
ax.errorbar(
df_married[(x_col, 'mean')],
df_married[(y_col, 'mean')],
xerr=df_married[(x_col, 'sem')],
yerr=df_married[(y_col, 'sem')],
color='b',
marker='^',
capsize=3,
capthick=1,
label='Married',
markersize=10,
linestyle='')
leg = ax.legend(loc='upper left', fontsize=18, frameon=True, numpoints=1)
ax.set_xlabel(x_label, fontsize=18)
ax.set_ylabel(y_label, fontsize=18)
ax.set_ylim(0, 1.1)
ax.set_xlim(-2, 8.5)
ax.patch.set_facecolor('white')
leg.get_frame().set_edgecolor('black')
leg.get_frame().set_facecolor('white')
leg.get_frame().set_linewidth(1)
plt.show()
plot_2d_means_credit(credit_train_df, 'PAY_0', 'default',
'Repayment Status (April)', 'Observed default rate')

ক্রেডিট ডিফল্ট হারের পূর্বাভাস দিতে ক্যালিব্রেটেড লিনিয়ার মডেলকে প্রশিক্ষণ দিন
এর পরে, আমরা TfL থেকে একটি মডেলটির ক্রমাঙ্ক রৈখিক মডেল প্রশিক্ষণ ভবিষ্যদ্বাণী করা হোক বা না হোক একজন ব্যক্তির একটি ঋণ উপর ডিফল্ট করবে। দুটি ইনপুট বৈশিষ্ট্য হবে ব্যক্তির বৈবাহিক অবস্থা এবং কত মাস ব্যক্তি এপ্রিল মাসে তাদের ঋণ ফেরত দিতে পিছিয়ে আছে (ঋণ পরিশোধের অবস্থা)। প্রশিক্ষণ লেবেল হবে যে ব্যক্তি ঋণ খেলাপি কিনা।
আমরা প্রথমে কোনো বাধা ছাড়াই একটি ক্যালিব্রেটেড লিনিয়ার মডেলকে প্রশিক্ষণ দেব। তারপর, আমরা একঘেয়ে সীমাবদ্ধতা সহ একটি ক্যালিব্রেটেড লিনিয়ার মডেলকে প্রশিক্ষণ দেব এবং মডেলের আউটপুট এবং নির্ভুলতার পার্থক্য পর্যবেক্ষণ করব।
ক্রেডিট ডিফল্ট ডেটাসেট বৈশিষ্ট্যগুলি কনফিগার করার জন্য হেল্পার ফাংশন
এই সাহায্যকারী ফাংশন ক্রেডিট ডিফল্ট কেস স্টাডির জন্য নির্দিষ্ট।
def get_input_fn_credit(input_df, num_epochs, batch_size=None):
"""Gets TF input_fn for credit default models."""
return tf.compat.v1.estimator.inputs.pandas_input_fn(
x=input_df[['MARRIAGE', 'PAY_0']],
y=input_df['default'],
num_epochs=num_epochs,
batch_size=batch_size or len(input_df),
shuffle=False)
def get_feature_columns_and_configs_credit(monotonicity):
"""Gets TFL feature configs for credit default models."""
feature_columns = [
tf.feature_column.numeric_column('MARRIAGE'),
tf.feature_column.numeric_column('PAY_0'),
]
feature_configs = [
tfl.configs.FeatureConfig(
name='MARRIAGE',
lattice_size=2,
pwl_calibration_num_keypoints=3,
monotonicity=monotonicity,
pwl_calibration_always_monotonic=False),
tfl.configs.FeatureConfig(
name='PAY_0',
lattice_size=2,
pwl_calibration_num_keypoints=10,
monotonicity=monotonicity,
pwl_calibration_always_monotonic=False),
]
return feature_columns, feature_configs
প্রশিক্ষিত মডেল আউটপুট ভিজ্যুয়ালাইজেশন জন্য সাহায্যকারী ফাংশন
def plot_predictions_credit(input_df,
estimator,
x_col,
x_label='Repayment Status (April)',
y_label='Predicted default probability'):
predictions = get_predicted_probabilities(
estimator=estimator, input_df=input_df, get_input_fn=get_input_fn_credit)
new_df = input_df.copy()
new_df.loc[:, 'predictions'] = predictions
plot_2d_means_credit(new_df, x_col, 'predictions', x_label, y_label)
অসংযত (নন-একঘেয়ে) ক্যালিব্রেটেড লিনিয়ার মডেল ট্রেন
nomon_linear_estimator = optimize_learning_rates(
train_df=credit_train_df,
val_df=credit_val_df,
test_df=credit_test_df,
monotonicity=0,
learning_rates=LEARNING_RATES,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
get_input_fn=get_input_fn_credit,
get_feature_columns_and_configs=get_feature_columns_and_configs_credit)
accuracies for learning rate 0.010000: train: 0.818762, val: 0.830065, test: 0.817172
plot_predictions_credit(credit_train_df, nomon_linear_estimator, 'PAY_0')
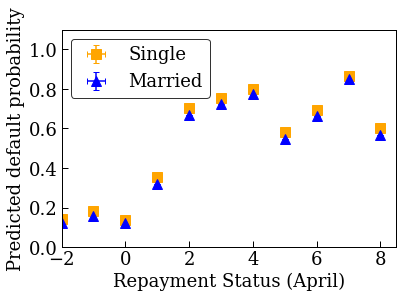
একঘেয়ে ক্যালিব্রেটেড রৈখিক মডেল ট্রেন করুন
mon_linear_estimator = optimize_learning_rates(
train_df=credit_train_df,
val_df=credit_val_df,
test_df=credit_test_df,
monotonicity=1,
learning_rates=LEARNING_RATES,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
get_input_fn=get_input_fn_credit,
get_feature_columns_and_configs=get_feature_columns_and_configs_credit)
accuracies for learning rate 0.010000: train: 0.818762, val: 0.830065, test: 0.817172
plot_predictions_credit(credit_train_df, mon_linear_estimator, 'PAY_0')
