
このチュートリアルでは、TensorFlow Lite を使用して Android アプリケーションをビルドし、自然言語テキストを分類する方法を示します。このアプリケーションは、物理的な Android デバイス用に設計されていますが、デバイスエミュレーターでも実行できます。
サンプルアプリケーションでは、TensorFlow Lite を使用してテキストを肯定または否定に分類し、自然言語 (NL) の Task ライブラリを使用してテキスト分類機械学習モデルの実行を可能にします。
既存のプロジェクトを更新する場合は、サンプルアプリケーションをリファレンスまたはテンプレートとして使用できます。テキスト分類を既存のアプリケーションに追加する方法については、アプリケーションの更新と変更を参照してください。
テキスト分類の概要
テキスト分類は、定義済みの一連のカテゴリを自由記述テキストに割り当てる機械学習タスクです。テキスト分類モデルは、単語やフレーズが手動で分類される自然言語テキストのコーパスでトレーニングされます。
トレーニング済みのモデルは入力としてテキストを受け取り、分類するためにトレーニングされた一連の既知のクラスに従ってテキストを分類しようとします。たとえば、この例のモデルはテキストのスニペットを受け入れ、テキストのセンチメントが肯定か否定かを判断します。テキストの各スニペットについて、テキスト分類モデルは、肯定または否定のいずれかに正しく分類されているテキストの信頼度を示すスコアを出力します。
このチュートリアルのモデルの生成方法の詳細については、TensorFlow Lite Model Maker チュートリアルを使用したテキスト分類を参照してください。
モデルとデータセット
このチュートリアルでは、SST-2 (Stanford Sentiment Treebank) データセットを使用してトレーニングされたモデルを使用します。 SST-2 には、トレーニング用の 67,349 件の映画レビューと、テスト用の 872 件の映画レビューが含まれており、各レビューは肯定または否定に分類されています。このアプリで使用されるモデルは、TensorFlow Lite Model Maker ツールを使用してトレーニングされました。
サンプルアプリケーションでは、次の事前トレーニング済みモデルを使用します。
Average Word Vector (
NLClassifier) - Task Library のNLClassifierは、入力テキストをさまざまなカテゴリに分類し、ほとんどのテキスト分類モデルを処理できます。MobileBERT (
BertNLClassifier) - Task Library のBertNLClassifierは NLClassifier に似ていますが、グラフ外の Wordpiece および Sentencepiece のトークン化が必要な場合に合わせて調整されています。
サンプルアプリのセットアップと実行
テキスト分類アプリケーションをセットアップするには、サンプルアプリを GitHub からダウンロードし、Android Studio を使用して実行します。
システム要件
- Android Studio バージョン 2021.1.1 (Bumblebee) 以上
- Android SDK バージョン 31 以上
- OS バージョン SDK 21 (Android 7.0 - Nougat) 以上が搭載された Android デバイス (開発者モードが有効であること、または Android Emulator を使用)
サンプルコードの取得
サンプルコードのローカルコピーを作成します。このコードを使用して、Android Studio でプロジェクトを作成し、サンプルアプリケーションを実行します。
サンプルコードを複製してセットアップするには、次の手順を実行します。
- git リポジトリを複製します。
git clone https://github.com/tensorflow/examples.git - 必要に応じて、sparse checkout を使用するように git インスタンスを構成します。これで、テキスト分類のサンプルアプリのファイルのみを取得できます。
cd examples git sparse-checkout init --cone git sparse-checkout set lite/examples/text_classification/android
プロジェクトのインポートと実行
ダウンロードしたサンプルコードからプロジェクトを作成し、プロジェクトをビルドして、実行します。
サンプルコードプロジェクトをインポートしてビルドするには、次の手順を実行します。
- Android Studio を起動します。
- Android Studio で、[File] > [New] > [Import Project] を選択します。
- build.gradle ファイルがあるサンプルコードディレクトリ (
.../examples/lite/examples/text_classification/android/build.gradle) に移動し、ディレクトリを選択します。 - Android Studio で Gradle Sync が要求される場合は、[OK] をクリックします。
- Android デバイスがコンピュータに接続され、開発者モードが有効であることを確認します。緑色の
Run矢印をクリックします。
正しいディレクトリを選択すると、Android Studio で新しいプロジェクトが作成、ビルドされます。Android Studio を他のプロジェクトでも使用している場合、コンピューターの速度によっては、この処理に数分かかる場合があります。ビルドが完了すると、Android Studio の [Build Output] ステータスパネルに BUILD SUCCESSFUL メッセージが表示されます。
プロジェクトを実行するには、次の手順を実行します。
- Android Studio で [Run] > [Run…] を選択して、プロジェクトを実行します。
- 接続されている Android デバイス (またはエミュレーター) を選択して、アプリをテストします。
アプリケーションの使用
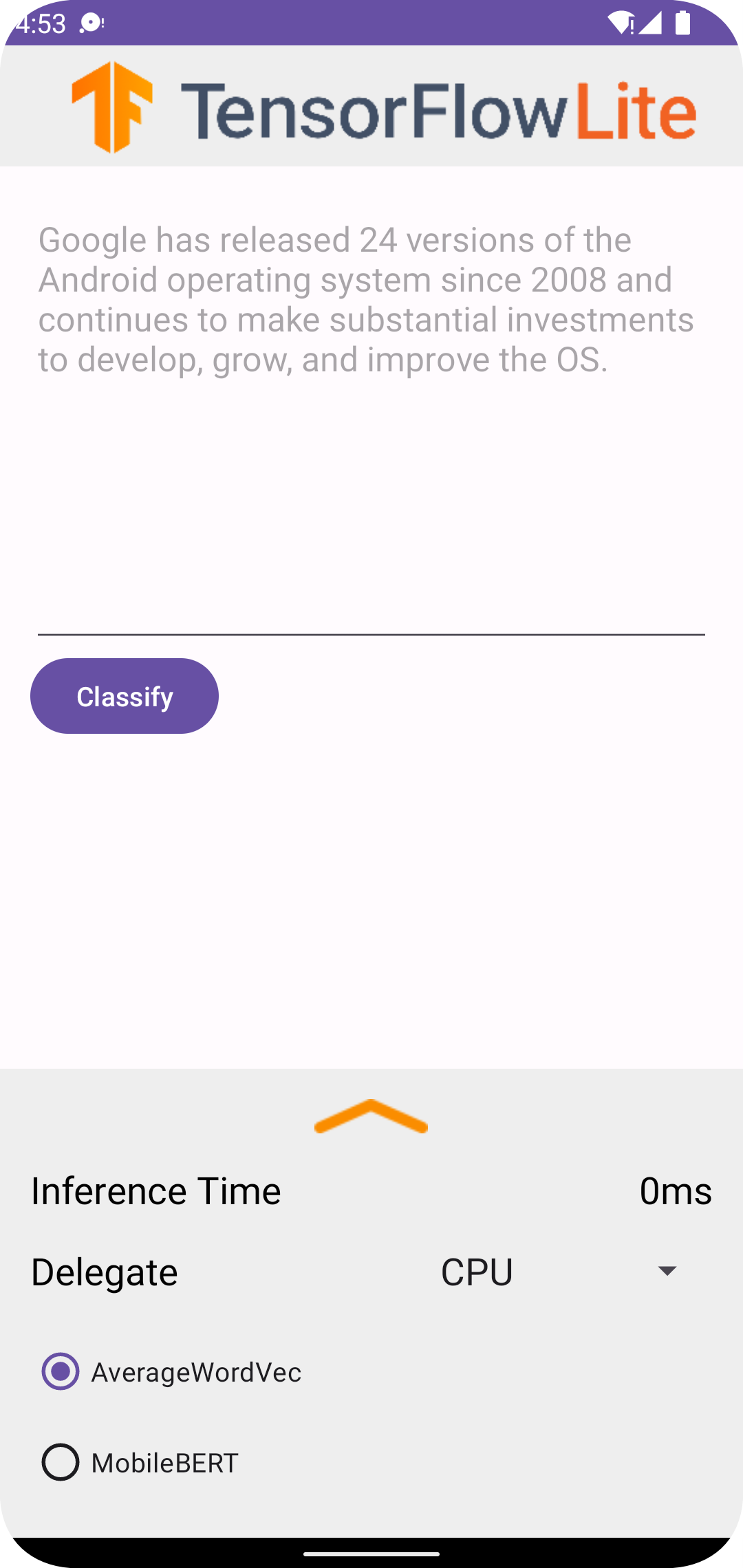
Android Studio でプロジェクトを実行すると、接続されたデバイスまたはデバイスエミュレーターでアプリケーションが自動的に開きます。
テキスト分類子を使用するには:
- テキストボックスにテキストのスニペットを入力します。
- デリゲートドロップダウンから、
CPUまたはNNAPIを選択します。 AverageWordVecまたはMobileBERTのいずれかを選択して、モデルを指定します。- [Classify] を選択します。
アプリケーションは、肯定のスコアと否定のスコアを出力します。これら 2 つのスコアの合計は 1 になり、入力テキストのセンチメントが肯定か否定かの可能性を測定します。数字が大きいほど、信頼度が高いことを示します。
これで、機能するテキスト分類アプリケーションができました。次のセクションを使用して、サンプルアプリケーションがどのように機能するか、およびテキスト分類機能を本番アプリケーションに実装する方法をよりよく理解してください。
アプリケーションの仕組み - サンプルアプリケーションの構造と主要なファイルのチュートリアル。
アプリケーションの変更 - テキスト分類を既存のアプリケーションに追加する手順。
サンプルアプリの仕組み
このアプリケーションは、自然言語 (NL) パッケージの Task ライブラリを使用して、テキスト分類モデルを実装します。 Average Word Vector と MobileBERT の 2 つのモデルは、TensorFlow Lite Model Maker を使用してトレーニングされました。アプリケーションは、デフォルトで CPU で実行され、NNAPI デリゲートを使用したハードウェアアクセラレーションのオプションがあります。
次のファイルとディレクトリには、このテキスト分類アプリケーションの重要なコードが含まれています。
- TextClassificationHelper.kt - テキスト分類子を初期化し、モデルとデリゲートの選択を処理します。
- MainActivity.kt -
TextClassificationHelperおよびResultsAdapterの呼び出しなど、アプリケーションを実装します。 - ResultsAdapter.kt - 結果を処理してフォーマットします。
アプリケーションの変更
次のセクションでは、独自の Android アプリを変更して、サンプルアプリに示されているモデルを実行するための主要な手順について説明します。これらの手順では、サンプルアプリを参照ポイントとして使用します。独自のアプリに必要な特定の変更は、サンプルアプリとは異なる場合があります。
Android プロジェクトを開く、または作成する
これらの手順の残りの部分に従うには、Android Studio の Android 開発プロジェクトが必要です。以下の手順に沿って、既存のプロジェクトを開くか、新しいプロジェクトを作成します。
既存の Android 開発プロジェクトを開くには:
- Android Studio で、[File] > [Open] を選択し、既存のプロジェクトを選択します。
基本的な Android 開発プロジェクトを作成するには:
- Android Studio の手順に沿って、基本的なプロジェクトを作成します。
Android Studio の使用の詳細については、Android Studio のドキュメントを参照してください。
プロジェクト依存関係の追加
独自のアプリケーションでは、特定のプロジェクト依存関係を追加して TensorFlow Lite 機械学習モデルを実行し、文字列などのデータを、使用しているモデルで処理できるテンソルデータ形式に変換するユーティリティ関数にアクセスする必要があります。
次の手順では、必要なプロジェクトおよびモデル依存関係を Android アプリプロジェクトに追加する方法について説明します。
モジュール依存関係を追加するには、次の手順を実行します。
TensorFlow Lite を使用するモジュールで、モジュールの
build.gradleファイルを更新して、次の依存関係を追加します。サンプルアプリケーションでは、依存関係は app/build.gradle にあります。
dependencies { ... implementation 'org.tensorflow:tensorflow-lite-task-text:0.4.0' }プロジェクトには Text タスクライブラリ (
tensorflow-lite-task-text) が含まれている必要があります。グラフィックス処理装置 (GPU) で実行するためにこのアプリを変更する場合、GPU ライブラリ (
tensorflow-lite-gpu-delegate-plugin) は GPU でアプリを実行するためのインフラストラクチャを提供し、デリゲート (tensorflow-lite-gpu) は、互換性リストを提供します。このアプリを GPU で実行することは、このチュートリアルの範囲外です。Android Studio で、[File] > [Sync Project with Gradle Files] を選択して、プロジェクト依存関係を同期します。
ML モデルの初期化
Android アプリでは、モデルで予測を実行する前に、TensorFlow Lite 機械学習モデルをパラメータで初期化する必要があります。
TensorFlow Lite モデルは *.tflite ファイルとして保存されます。モデルファイルには予測ロジックが含まれており、通常は、予測クラス名など、予測結果の解釈方法に関するメタデータが含まれています。通常、モデルファイルは、コード例のように、開発プロジェクトの src/main/assets ディレクトリに保存されます。
<project>/src/main/assets/mobilebert.tflite<project>/src/main/assets/wordvec.tflite
注意: サンプルアプリでは、[download_model.gradle](https://github.com/tensorflow/examples/blob/master/lite/examples/text_classification/android/app/download_model.gradle) ファイルを使用して、ビルド時に平均単語ベクトルおよび MobileBERT モデルをダウンロードします。このアプローチは、本番アプリには不要または推奨されません。
便宜上の観点と、コードを読みやすくするため、この例では、モデルの設定を定義する比較オブジェクトが宣言されています。
アプリでモデルを初期化するには、次の手順を実行します。
コンパニオンオブジェクトを作成して、モデルの設定を定義します。サンプルアプリケーションでは、このオブジェクトは TextClassificationHelper.kt にあります。
companion object { const val DELEGATE_CPU = 0 const val DELEGATE_NNAPI = 1 const val WORD_VEC = "wordvec.tflite" const val MOBILEBERT = "mobilebert.tflite" }分類子オブジェクトをビルドしてモデルの設定を作成し、
BertNLClassifierまたはNLClassifierを使用して TensorFlow Lite オブジェクトを作成します。サンプルアプリケーションでは、これは TextClassificationHelper.kt 内の
initClassifier関数にあります。fun initClassifier() { ... if( currentModel == MOBILEBERT ) { ... bertClassifier = BertNLClassifier.createFromFileAndOptions( context, MOBILEBERT, options) } else if (currentModel == WORD_VEC) { ... nlClassifier = NLClassifier.createFromFileAndOptions( context, WORD_VEC, options) } }注意: テキスト分類を使用するほとんどの本番アプリは、両方ではなく、
BertNLClassifierまたはNLClassifierのいずれかを使用します。
ハードウェアアクセラレーションの有効化 (オプション)
アプリで TensorFlow Lite モデルを初期化するときには、ハードウェアアクセラレーション機能を使用して、モデルの予測計算を高速化することを検討してください。TensorFlow Lite デリゲートは、グラフィックス処理装置 (GPU) またはテンソル処理装置 (TPU) といった、モバイルデバイスの専用処理ハードウェアを使用して、機械学習の実行を高速化するソフトウェアモジュールです。
アプリでハードウェアアクセラレーションを有効にするには:
アプリケーションが使用するデリゲートを定義する変数を作成します。サンプルアプリケーションでは、この変数は TextClassificationHelper.kt の早い段階にあります。
var currentDelegate: Int = 0デリゲートセレクタを作成します。サンプルアプリケーションでは、デリゲートセレクタは TextClassificationHelper.kt 内の
initClassifier関数にあります。val baseOptionsBuilder = BaseOptions.builder() when (currentDelegate) { DELEGATE_CPU -> { // Default } DELEGATE_NNAPI -> { baseOptionsBuilder.useNnapi() } }
注意: GPU デリゲートを使用するようにこのアプリを変更することは可能ですが、これには、分類子を使用している同じスレッドで分類子を作成する必要があります。これは、このチュートリアルの範囲外です。
デリゲートを使用して TensorFlow Lite モデルを実行することをお勧めしますが、必須ではありません。TensorFlow Lite でのデリゲートの使用の詳細については、TensorFlow Lite Delegates を参照してください。
モデルのデータの準備
Android アプリでは、コードによって、未加工のテキストなどの既存のデータが、モデルで処理できるテンソルデータ形式に変換されて、モデルに入力され、解釈されます。モデルに渡されるテンソル内のデータには、モデルのトレーニングに使用されるデータの形式と一致する特定の次元または形状が必要です。
このテキスト分類アプリは文字列を入力として受け入れ、モデルは英語のコーパスだけでトレーニングされます。特殊文字と英語以外の単語は、推論中に無視されます。
モデルにテキストデータを提供するには:
ML モデルの初期化セクションとハードウェアアクセラレーションの有効化セクションで説明されているように、
initClassifier関数にデリゲートとモデルのコードが含まれていることを確認します。initブロックを使用してinitClassifier関数を呼び出します。サンプルアプリケーションでは、initは TextClassificationHelper.kt にあります。init { initClassifier() }
予測の実行
Android アプリでは、BertNLClassifier または NLClassifier オブジェクトのいずれかを初期化したら、モデルの入力テキストのフィードを開始して、「肯定」または「否定」に分類できます。
予測を実行するには:
選択した分類器 (
currentModel) を使用し、入力テキストの分類にかかった時間 (inferenceTime) を測定するclassify関数を作成します。サンプルアプリケーションでは、classify関数は TextClassificationHelper.kt にあります。fun classify(text: String) { executor = ScheduledThreadPoolExecutor(1) executor.execute { val results: List<Category> // inferenceTime is the amount of time, in milliseconds, that it takes to // classify the input text. var inferenceTime = SystemClock.uptimeMillis() // Use the appropriate classifier based on the selected model if(currentModel == MOBILEBERT) { results = bertClassifier.classify(text) } else { results = nlClassifier.classify(text) } inferenceTime = SystemClock.uptimeMillis() - inferenceTime listener.onResult(results, inferenceTime) } }classifyからの結果をリスナーオブジェクトに渡します。fun classify(text: String) { ... listener.onResult(results, inferenceTime) }
モデル出力の処理
テキスト行を入力すると、モデルは「肯定」カテゴリと「否定」カテゴリの 0 から 1 までの浮動小数点数で表される予測スコアを生成します。
モデルから予測結果を取得するには、次の手順を実行します。
出力を処理するリスナーオブジェクトの
onResult関数を作成します。サンプルアプリケーションでは、リスナーオブジェクトは MainActivity.kt にあります。private val listener = object : TextClassificationHelper.TextResultsListener { override fun onResult(results: List<Category>, inferenceTime: Long) { runOnUiThread { activityMainBinding.bottomSheetLayout.inferenceTimeVal.text = String.format("%d ms", inferenceTime) adapter.resultsList = results.sortedByDescending { it.score } adapter.notifyDataSetChanged() } } ... }エラーを処理する
onError関数をリスナーオブジェクトに追加します。private val listener = object : TextClassificationHelper.TextResultsListener { ... override fun onError(error: String) { Toast.makeText(this@MainActivity, error, Toast.LENGTH_SHORT).show() } }
モデルが一連の予測結果を返すと、アプリケーションはユーザーに結果を提示するか、追加のロジックを実行することで、これらの予測に基づいて行動できます。サンプルアプリケーションでは、ユーザーインターフェイスに予測スコアが一覧表示されます。
Next steps
- TensorFlow Lite Model Maker を使用したテキスト分類チュートリアルを使用して、モデルを最初からトレーニングして実装します。
- その他の TensorFlow 用のテキスト処理ツールを考察します。
- TensorFlow Hub で他の BERT モデルをダウンロードします。
- 例を使って、TensorFlow Lite のさまざまな使用方法を考察します。
- モデルセクションで、TensorFlow Lite の機械学習モデルの使用方法について詳細に説明します。
- TensorFlow Lite 開発者ガイドで、モデルアプリケーションでの機械学習の実装について詳細に説明します。