

视频分类是识别视频所表示内容的机器学习任务。视频分类模型在包含一组独特类(如不同的动作或活动)的视频数据集上训练。该模型接收视频帧作为输入,并输出每一类在视频中表示的概率。
视频分类和图像分类模型都使用图像作为输入来预测这些图像属于预定义类的概率。然而,视频分类模型还会处理相邻帧之间的时空关系以识别视频中的动作。
例如,可以对视频动作识别模型进行训练,以识别奔跑、鼓掌和挥手等人类动作。下图展示了 Android 视频分类模型的输出。
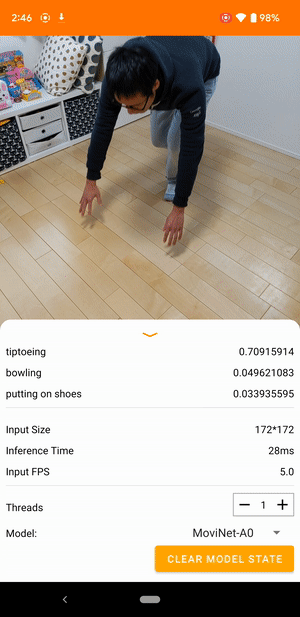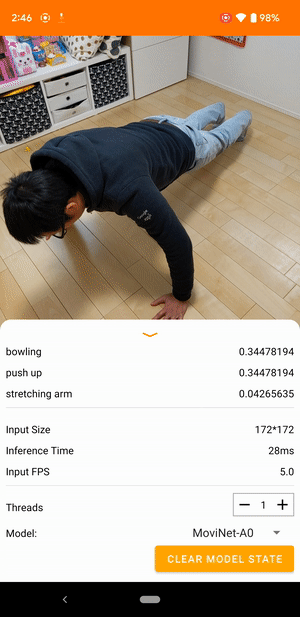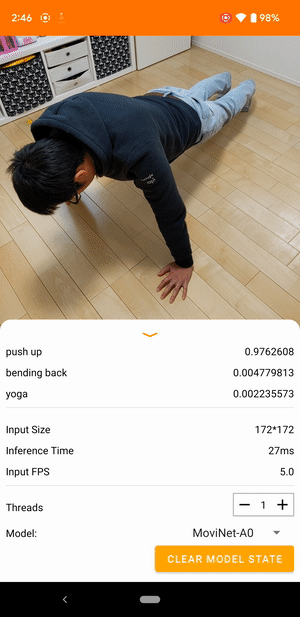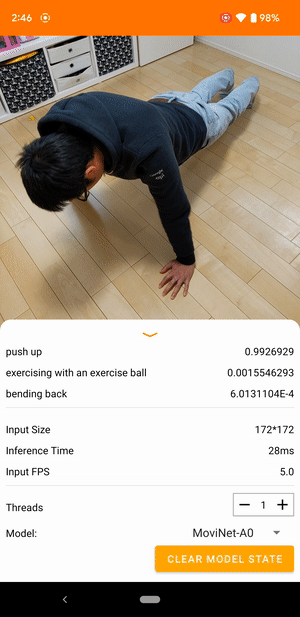
开始
如果您使用的平台不是 Android 或 Raspberry PI,或者您已经熟悉 TensorFlow Lite API,请下载入门视频分类模型和支持文件。您还可以使用 TensorFlow Lite Support Library 构建您自己的自定义推断流水线。
如果您是 TensorFlow Lite 新用户,并且使用的是 Android 或 Raspberry Pi,请浏览以下可以帮助您入门的示例应用。
Android
Android 应用使用设备的后置摄像头进行连续的视频分类。使用 TensorFlow Lite Java API 执行推断。演示应用会对帧进行分类,并实时显示预测的分类。
Raspberry Pi
Raspberry Pi 示例使用 TensorFlow Lite 和 Python 执行连续的视频分类。将 Raspberry Pi 连接到摄像头,如 Pi 摄像头,以执行实时视频分类。要查看摄像头的结果,请将显示器连接到 Raspberry Pi,并使用 SSH 访问 Pi shell(以避免将键盘连接到 Pi)。
在开始之前,将您的 Raspberry Pi 设置为 Raspberry Pi OS(最好更新到 Buster 版)。
模型说明
移动视频网络 (MoViNets) 是一系列针对移动设备优化的高效视频分类模型。MoViNet 在几个大规模视频动作识别数据集上展示了最先进的准确率和效率,非常适合视频动作识别任务。
TensorFlow Lite 的 MoviNet 模型有三种变体:MoviNet-A0、MoviNet-A1 和 MoviNet-A2。这些变体使用 Kinetics-600 数据集进行训练,以识别 600 种不同的人类动作。MoviNet-A0 最小、最快,但准确率最低。MoviNet-A2 最大、最慢,但准确率最高。MoviNet-A1 是 A0 和 A2 之间的折衷。
工作原理
在训练期间,向视频及其关联的标签提供视频分类模型。每个标签都是模型将学习识别的不同概念或类的名称。对于视频动作识别,视频将是人工动作,标签将是关联的动作。
视频分类模型可以学习预测新视频是否属于在训练期间提供的任何类。此过程称为推断。您还可以使用迁移学习通过使用预先存在的模型来识别新的视频类别。
该模型是一种接收连续视频并实时响应的流模型。模型会一边接收视频流,一边识别视频中是否有表示来自训练数据集中任何类的内容。模型会针对每一帧返回这些类以及视频表示各个类的概率。给定时间的示例输出可能如下所示:
| 动作 | 概率 |
|---|---|
| 广场舞 | 0.02 |
| 穿针 | 0.08 |
| 摆弄手指 | 0.23 |
| 挥手 | 0.67 |
输出中的每个动作对应于训练数据中的标签。概率表示动作被显示在视频中的可能性。
模型输入
该模型接受 RGB 视频帧的流作为输入。输入视频的大小是灵活的,但理想情况下它应与模型训练分辨率和帧速率匹配:
- MoviNet-A0: 172 x 172, 5 fps
- MoviNet-A1: 172 x 172, 5 fps
- MoviNet-A1: 224 x 224, 5 fps
输入视频的颜色值范围应在 0 到 1 之间,遵循常见的图像输入约定。
在内部,该模型还通过使用在先前帧中收集的信息来分析每个帧的上下文。实现方式是通过从模型输出中获取内部状态并将其馈送到模型中用于接下来的帧。
模型输出
该模型会返回一系列标签及其对应的得分。这些得分是表示每个类的预测值的 logit 值。可以使用 softmax 函数 (tf.nn.softmax) 将这些得分转换为概率。
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
在内部,模型输出还包括模型的内部状态,并将其馈送回模型中用于接下来的帧。
性能基准
性能基准测试数值使用基准测试工具生成。MoviNet 仅支持 CPU。
模型性能通过模型在给定硬件上运行推断所需的时间来衡量。时间越短,意味着模型越快。准确率通过模型正确地对视频中的类别进行分类的频率来衡量。
| 模型名称 | 大小 | 准确率 * | 设备 | CPU ** |
|---|---|---|---|---|
| MoviNet-A0(整数量化) | 3.1 MB | 65% | Pixel 4 | 5 ms |
| Pixel 3 | 11 ms | |||
| MoviNet-A1(整数量化) | 4.5 MB | 70% | Pixel 4 | 8 ms |
| Pixel 3 | 19 ms | |||
| MoviNet-A2(整数量化) | 5.1 MB | 72% | Pixel 4 | 15 ms |
| Pixel 3 | 36 毫秒 |
- Top-1 准确率在 Kinetics-600 数据集上测得。
** 延迟在单线程的 CPU 上运行时测得。
模型自定义
预训练模型可以从 Kinetics-600 数据集中识别 600 中人类动作。您还可以使用迁移学习来重新训练模型,以识别不在原始集合中的人类动作。为此,您需要为要合并到模型中的每个新动作提供一组训练视频。
有关自定义数据的微调模型的更多信息,请参阅 MoViNets 仓库和MoViNets 教程。
补充阅读和资源
请使用以下资源了解有关本页讨论的概念的更多信息: