
TensorFlow Ranking 라이브러리는 최근 연구에서 잘 확립된 접근 방식과 기술을 사용하여 머신러닝 모델의 순위를 매기는 확장 가능한 학습을 구축하는 데 도움이 됩니다. 순위 모델은 웹페이지와 같은 유사한 항목의 목록을 가져와서 관련성이 가장 높은 페이지부터 관련성이 가장 낮은 페이지까지 해당 항목의 최적화된 목록을 생성합니다. 모델 순위를 매기는 학습은 검색, 질문 답변, 추천 시스템 및 대화 시스템에 적용됩니다. 이 라이브러리를 사용하면 Keras API를 사용하여 애플리케이션에 대한 순위 모델 구축을 가속화할 수 있습니다. Ranking 라이브러리는 또한 분산 처리 전략을 사용하여 대규모 데이터 세트와 효과적으로 작업할 수 있도록 모델 구현을 더 쉽게 확장할 수 있도록 워크플로 유틸리티를 제공합니다.
이 개요에서는 이 라이브러리를 사용하여 모델 순위를 지정하기 위한 학습 개발에 대한 간략한 요약을 제공하고, 라이브러리에서 지원되는 일부 고급 기술을 소개하고, 순위 지정 애플리케이션을 위한 분산 처리를 지원하기 위해 제공되는 워크플로 유틸리티에 대해 논의합니다.
모델 순위를 매기는 학습 개발
TensorFlow Ranking 라이브러리를 사용한 모델 구축은 다음과 같은 일반적인 단계를 따릅니다.
- Keras 레이어(
tf.keras.layers)를 사용하여 채점 함수 지정 -
tfr.keras.metrics.NDCGMetric과 같이 평가에 사용하려는 측정항목을 정의하세요. -
tfr.keras.losses.SoftmaxLoss와 같은 손실 함수를 지정합니다. -
tf.keras.Model.compile()사용하여 모델을 컴파일하고 데이터로 훈련합니다.
영화 추천 튜토리얼은 이 라이브러리를 사용하여 모델 순위를 지정하는 학습을 구축하는 기본 사항을 안내합니다. 대규모 순위 모델 구축에 대한 자세한 내용은 분산 순위 지원 섹션을 확인하세요.
고급 순위 기술
TensorFlow Ranking 라이브러리는 Google 연구원 및 엔지니어가 연구하고 구현한 고급 순위 기술 적용을 지원합니다. 다음 섹션에서는 이러한 기술 중 일부에 대한 개요와 이를 애플리케이션에서 사용을 시작하는 방법을 제공합니다.
BERT 목록 입력 순서
Ranking 라이브러리는 BERT 와 LTR 모델링을 결합하여 목록 입력 순서를 최적화하는 점수 아키텍처인 TFR-BERT의 구현을 제공합니다. 이 접근 방식의 적용 예로서 쿼리와 이 쿼리에 대한 응답으로 순위를 지정하려는 n개 문서 목록을 고려해보세요. <query, document> 쌍에 걸쳐 독립적으로 점수가 매겨진 BERT 표현을 학습하는 대신, LTR 모델은 순위 손실을 적용하여 정답 레이블과 관련하여 전체 순위 목록의 유용성을 최대화하는 BERT 표현을 공동으로 학습합니다. 다음 그림은 이 기술을 보여줍니다.
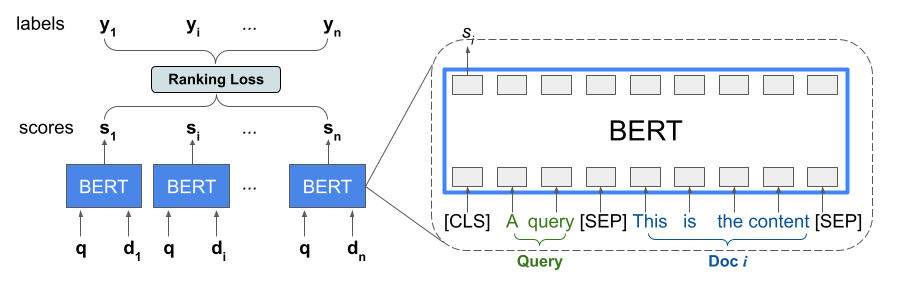
이 접근 방식은 쿼리에 대한 응답으로 순위를 매길 문서 목록을 <query, document> 튜플 목록으로 평면화합니다. 그런 다음 이러한 튜플은 BERT 사전 훈련된 언어 모델에 공급됩니다. 그런 다음 전체 문서 목록에 대해 풀링된 BERT 출력은 TensorFlow Ranking에서 사용할 수 있는 특수 순위 손실 중 하나와 공동으로 미세 조정됩니다.
이 아키텍처는 사전 학습된 언어 모델 성능을 크게 향상 시켜 특히 여러 사전 학습된 언어 모델이 결합된 경우 여러 인기 순위 작업에 대한 최첨단 성능을 제공할 수 있습니다. 이 기술에 대한 자세한 내용은 관련 연구를 참조하세요. TensorFlow Ranking 예제 코드 에서 간단한 구현으로 시작할 수 있습니다.
신경 순위 일반화 추가 모델(GAM)
대출 적격성 평가, 광고 타겟팅 또는 의료 치료 안내와 같은 일부 순위 시스템의 경우 투명성과 설명 가능성이 중요한 고려 사항입니다. 가중치 요인을 잘 이해한 일반화된 가법 모델 (GAM)을 적용하면 순위 모델을 더 쉽게 설명하고 해석할 수 있습니다.
GAM은 회귀 및 분류 작업을 통해 광범위하게 연구되었지만 이를 순위 지정 애플리케이션에 적용하는 방법은 덜 명확합니다. 예를 들어 GAM을 간단히 적용하여 목록의 각 개별 항목을 모델링할 수 있지만 항목 상호 작용과 이러한 항목의 순위가 지정되는 컨텍스트를 모두 모델링하는 것은 더 어려운 문제입니다. TensorFlow Ranking은 순위 문제를 위해 설계된 일반화된 추가 모델의 확장인 신경 순위 GAM 구현을 제공합니다. GAM의 TensorFlow Ranking 구현을 사용 하면 모델 기능에 특정 가중치를 추가할 수 있습니다.
호텔 순위 시스템에 대한 다음 그림에서는 관련성, 가격 및 거리를 기본 순위 기능으로 사용합니다. 이 모델은 GAM 기술을 적용하여 사용자의 장치 컨텍스트에 따라 이러한 차원의 가중치를 다르게 적용합니다. 예를 들어 쿼리가 전화에서 나온 경우 사용자가 근처 호텔을 찾고 있다고 가정하면 거리에 더 큰 가중치가 부여됩니다.
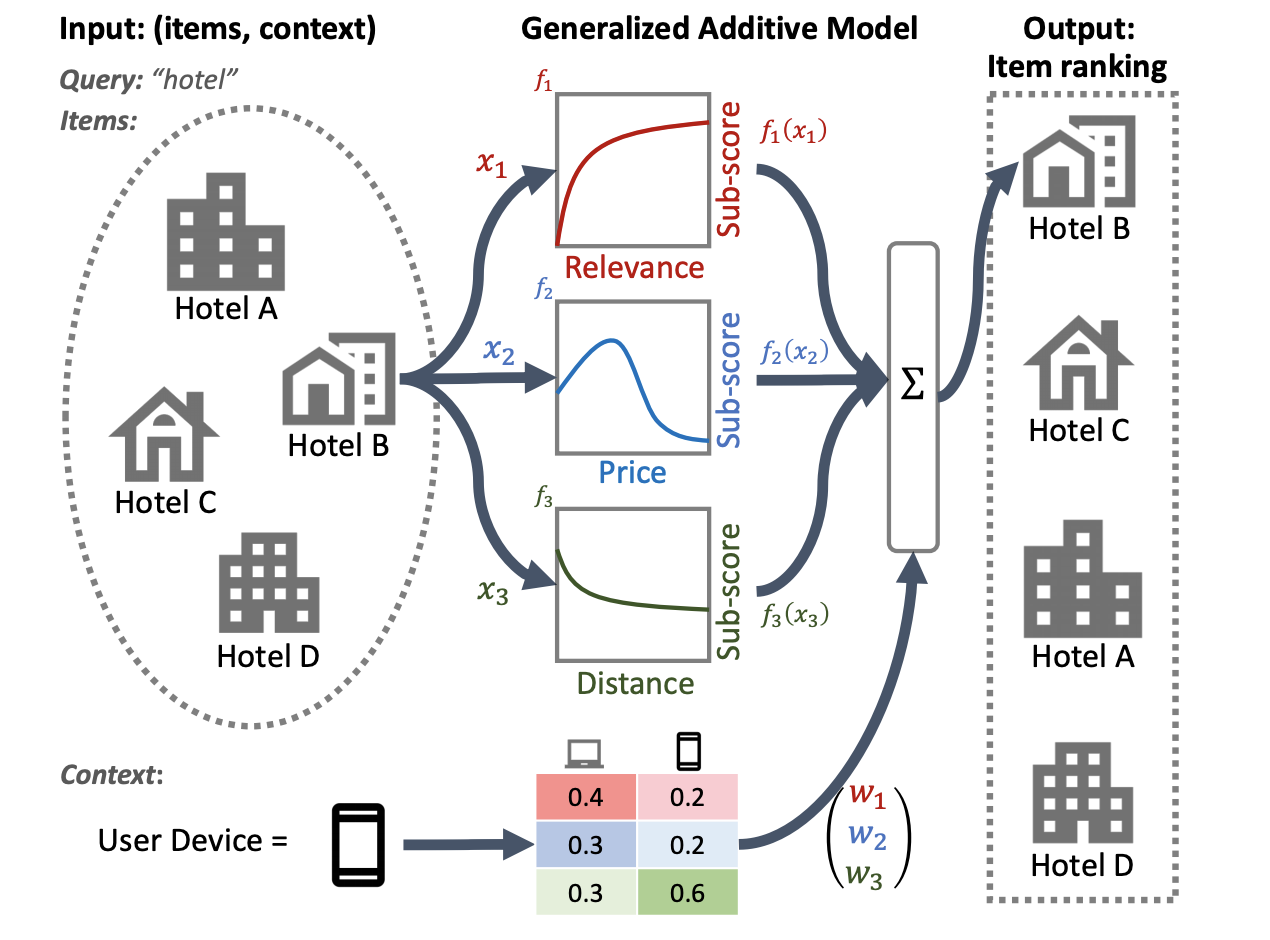
순위 모델과 함께 GAM을 사용하는 방법에 대한 자세한 내용은 관련 연구를 참조하세요. TensorFlow Ranking 예제 코드 에서 이 기술의 샘플 구현을 시작할 수 있습니다.
분산 순위 지원
TensorFlow Ranking은 데이터 처리, 모델 구축, 평가 및 프로덕션 배포를 포함하여 대규모 순위 시스템을 엔드 투 엔드로 구축하도록 설계되었습니다. 이종의 조밀하고 희박한 특성을 처리하고 최대 수백만 개의 데이터 포인트까지 확장할 수 있으며 대규모 순위 애플리케이션을 위한 분산 교육을 지원하도록 설계되었습니다.
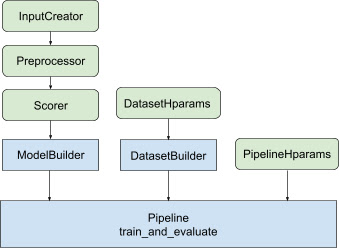
라이브러리는 반복적인 상용구 코드를 방지하고 순위 모델 교육부터 제공까지 적용할 수 있는 분산 솔루션을 생성하기 위해 최적화된 순위 파이프라인 아키텍처를 제공합니다. 순위 파이프라인은 MirroredStrategy , TPUStrategy , MultiWorkerMirroredStrategy 및 ParameterServerStrategy를 포함한 대부분의 TensorFlow 분산 전략을 지원합니다. 순위 파이프라인은 여러 입력 서명을 지원하는 tf.saved_model 형식으로 훈련된 순위 모델을 내보낼 수 있습니다. 또한 순위 파이프라인은 장기 실행 오류 복구에 도움이 되는 TensorBoard 데이터 시각화 및 BackupAndRestore 지원을 포함하여 유용한 콜백을 제공합니다. 훈련 운영.
순위 라이브러리는 모델 빌더, 데이터 빌더 및 하이퍼파라미터를 입력으로 사용하는 tfr.keras.pipeline 클래스 세트를 제공하여 분산 교육 구현을 구축하는 데 도움을 줍니다. Keras 기반 tfr.keras.ModelBuilder 클래스를 사용하면 분산 처리를 위한 모델을 생성할 수 있으며 확장 가능한 InputCreator, Preprocessor 및 Scorer 클래스와 함께 작동합니다.
TensorFlow Ranking 파이프라인 클래스는 DatasetBuilder 와 함께 작동하여 하이퍼파라미터를 통합할 수 있는 훈련 데이터를 설정합니다. 마지막으로 파이프라인 자체에는 하이퍼파라미터 집합이 PipelineHparams 객체로 포함될 수 있습니다.
분산 순위 튜토리얼을 사용하여 분산 순위 모델 구축을 시작하세요.