
TL;DR : TensorFlow ランキング パイプラインを使用して TensorFlow ランキング モデルを構築、トレーニング、提供するための定型コードを削減します。ユースケースとリソースを考慮して、大規模なランキング アプリケーションには適切な分散戦略を使用してください。
導入
TensorFlow ランキング パイプラインは、一連のデータ処理、モデル構築、トレーニング、提供プロセスで構成されており、最小限の労力でデータ ログからスケーラブルなニューラル ネットワーク ベースのランキング モデルを構築、トレーニング、提供できます。パイプラインは、システムがスケールアップすると最も効率的になります。一般に、モデルを 1 台のマシンで実行するのに 10 分以上かかる場合は、このパイプライン フレームワークを使用して負荷を分散し、処理を高速化することを検討してください。
TensorFlow ランキング パイプラインは、分散システム (1,000 個以上の CPU、100 個以上の GPU および TPU) 上のビッグ データ (テラバイト以上) と大きなモデル (1 億以上の FLOP) を使用した大規模な実験と本番環境で、常に安定して実行されています。 TensorFlow モデルがデータのごく一部に対してmodel.fitで証明されると、ハイパーパラメーター スキャン、継続的トレーニング、その他の大規模な状況にパイプラインが推奨されます。
ランキングパイプライン
TensorFlow では、ランキング モデルを構築、トレーニング、提供するための一般的なパイプラインには、次の一般的な手順が含まれます。
- モデル構造を定義します。
- 入力を作成します。
- 前処理レイヤーを作成します。
- ニューラル ネットワーク アーキテクチャを作成します。
- 鉄道模型:
- サーブモデル:
- 提供時にデータ形式を決定します。
- トレーニング済みモデルを選択してロードします。
- ロードされたモデルで処理します。
TensorFlow ランキング パイプラインの主な目的の 1 つは、データセットの読み込みと前処理、リスト単位のデータとポイント単位のスコアリング関数の互換性、モデルのエクスポートなどのステップにおける定型コードを削減することです。もう 1 つの重要な目的は、多くの本質的に相関するプロセスの一貫した設計を強制することです。たとえば、モデル入力はトレーニング データセットと提供時のデータ形式の両方と互換性がなければなりません。
ご利用ガイド
上記のすべての設計により、TF ランキング モデルの起動は、図 1 に示すように次の手順に分類されます。
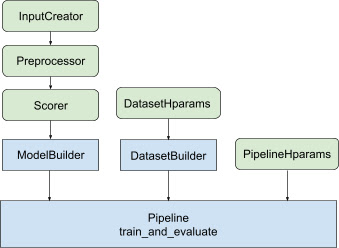
分散ニューラルネットワークを使用した例
この例では、 feature_specを取り込む組み込みのtfr.keras.model.FeatureSpecInputCreator 、 tfr.keras.pipeline.SimpleDatasetBuilder 、およびtfr.keras.pipeline.SimplePipelineを利用して、モデル入力の入力特徴量を一貫して定義し、データセットサーバー。ステップバイステップのウォークスルーを備えたノートブック バージョンは、分散ランキング チュートリアルにあります。
まず、コンテキスト機能とサンプル機能の両方に対してfeature_specを定義します。
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
図 1 に示す手順に従います。
feature_specからinput_creatorを定義します。
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
次に、同じ入力フィーチャのセットに対して前処理フィーチャ変換を定義します。
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
組み込みのフィードフォワード DNN モデルを使用してスコアラーを定義します。
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
input_creator 、 preprocessor 、 scorerを使用してmodel_builderを作成します。
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
次に、 dataset_builderのハイパーパラメータを設定します。
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
dataset_builderを作成します。
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
パイプラインのハイパーパラメータも設定します。
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
ranking_pipelineを作成してトレーニングします。
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
TensorFlow ランキング パイプラインの設計
TensorFlow ランキング パイプラインは、ボイラープレート コードによるエンジニアリング時間を節約するのに役立ち、同時にオーバーライドとサブクラス化による柔軟なカスタマイズを可能にします。これを実現するために、パイプラインにはカスタマイズ可能なクラスtfr.keras.model.AbstractModelBuilder 、 tfr.keras.pipeline.AbstractDatasetBuilder 、およびtfr.keras.pipeline.AbstractPipelineが導入され、TensorFlow Rank パイプラインが設定されます。

モデルビルダー
Kerasモデルの構築に関連するボイラープレート コードはAbstractModelBuilderに統合されており、これはAbstractPipelineに渡され、パイプライン内で呼び出され、ストラテジー スコープの下でモデルを構築します。これを図 1 に示します。クラス メソッドは抽象基本クラスで定義されます。
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
AbstractModelBuilder直接サブクラス化し、カスタマイズ用の具体的なメソッドで上書きすることができます。
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
同時に、サブクラス化する代わりに、クラス init の関数入力input_creator 、 preprocessor 、およびscorerとして指定された入力フィーチャ、前処理変換、およびスコアリング関数とともにModelBuilderを使用する必要があります。
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
これらの入力作成のボイラープレートを減らすために、 input_creator用の関数クラスtfr.keras.model.InputCreator 、 preprocessor用のtfr.keras.model.Preprocessor 、およびscorer用のtfr.keras.model.Scorerが、具体的なサブクラスtfr.keras.model.FeatureSpecInputCreator 、 tfr.keras.model.TypeSpecInputCreator 、 tfr.keras.model.PreprocessorWithSpec 、 tfr.keras.model.UnivariateScorer 、 tfr.keras.model.DNNScorer 、およびtfr.keras.model.GAMScorer 。これらは、一般的な使用例のほとんどをカバーするはずです。
これらの関数クラスは Keras クラスであるため、シリアル化する必要がないことに注意してください。サブクラス化は、それらをカスタマイズするための推奨される方法です。
データセットビルダー
DatasetBuilderクラスは、データセット関連のボイラープレートを収集します。データはPipelineに渡され、トレーニングおよび検証データセットを提供し、保存されたモデルの提供シグネチャを定義するために呼び出されます。図 1 に示すように、 DatasetBuilderメソッドはtfr.keras.pipeline.AbstractDatasetBuilder基本クラスで定義されています。
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
具体的なDatasetBuilderクラスでは、 build_train_datasets 、 build_valid_datasets 、およびbuild_signaturesを実装する必要があります。
feature_specからデータセットを作成する具象クラスも提供されます。
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
DatasetBuilderで使用されるhparams 、 tfr.keras.pipeline.DatasetHparamsデータクラスで指定されます。
パイプライン
ランキング パイプラインはtfr.keras.pipeline.AbstractPipelineクラスに基づいています。
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
model.fitと互換性のあるさまざまなtf.distribute.strategyを使用してモデルをトレーニングする具体的なパイプライン クラスも提供されます。
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
tfr.keras.pipeline.ModelFitPipelineで使用されるhparams 、 tfr.keras.pipeline.PipelineHparamsデータクラスで指定されます。このModelFitPipelineクラスは、ほとんどの TF ランキングのユースケースに十分です。クライアントは、特定の目的のためにそれを簡単にサブクラス化できます。
分散戦略のサポート
TensorFlow でサポートされる分散戦略の詳細については、分散トレーニングを参照してください。現在、TensorFlow ランキング パイプラインはtf.distribute.MirroredStrategy (デフォルト)、 tf.distribute.TPUStrategy 、 tf.distribute.MultiWorkerMirroredStrategy 、およびtf.distribute.ParameterServerStrategyサポートしています。ミラー化戦略は、ほとんどの単一マシン システムと互換性があります。分散戦略を使用しない場合は、 strategy Noneに設定してください。
一般に、 MirroredStrategy 、CPU および GPU オプションを備えたほとんどのデバイス上の比較的小規模なモデルで機能します。 MultiWorkerMirroredStrategy 、1 つのワーカーに収まらない大きなモデルに機能します。 ParameterServerStrategy非同期トレーニングを実行するため、複数のワーカーを使用できる必要があります。 TPUStrategy 、TPU が利用可能な場合にはビッグ モデルやビッグ データに最適ですが、処理できるテンソル形状の点では柔軟性に劣ります。
よくある質問
RankingPipeline使用するための最小限のコンポーネントのセット
上記のコード例を参照してください。独自の Keras
modelがある場合はどうなるでしょうかtf.distributeストラテジーを使用してトレーニングするには、strategy.scope() で定義されたすべてのトレーニング可能な変数を使用してmodelを構築する必要があります。したがって、ModelBuilderでモデルを次のようにラップします。
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
次に、この model_builder をパイプラインにフィードして、さらにトレーニングします。