
TL; DR : ลดโค้ดสำเร็จรูปเพื่อสร้าง ฝึกฝน และให้บริการโมเดลการจัดอันดับ TensorFlow ด้วย TensorFlow Ranking Pipelines ใช้กลยุทธ์การกระจายที่เหมาะสมสำหรับแอปพลิเคชันการจัดอันดับขนาดใหญ่ตามกรณีการใช้งานและทรัพยากร
การแนะนำ
TensorFlow Ranking Pipeline ประกอบด้วยชุดการประมวลผลข้อมูล การสร้างโมเดล การฝึกอบรม และกระบวนการให้บริการที่ช่วยให้คุณสามารถสร้าง ฝึกอบรม และให้บริการโมเดลการจัดอันดับตามโครงข่ายประสาทเทียมที่ปรับขนาดได้จากบันทึกข้อมูลโดยใช้ความพยายามเพียงเล็กน้อย ไปป์ไลน์จะมีประสิทธิภาพมากที่สุดเมื่อระบบขยายขนาด โดยทั่วไป หากโมเดลของคุณใช้เวลา 10 นาทีขึ้นไปในการทำงานบนเครื่องเดียว ให้พิจารณาใช้เฟรมเวิร์กไปป์ไลน์นี้เพื่อกระจายโหลดและเพิ่มความเร็วในการประมวลผล
TensorFlow Ranking Pipeline ดำเนินการอย่างต่อเนื่องและเสถียรในการทดลองและการผลิตขนาดใหญ่ด้วยข้อมูลขนาดใหญ่ (เทราไบต์+) และโมเดลขนาดใหญ่ (100M+ ของ FLOP) บนระบบแบบกระจาย (1K+ CPU และ 100+ GPU และ TPU) เมื่อโมเดล TensorFlow ได้รับการพิสูจน์ด้วย model.fit กับส่วนเล็กๆ ของข้อมูลแล้ว ไปป์ไลน์จะได้รับการแนะนำสำหรับการสแกนไฮเปอร์พารามิเตอร์ การฝึกอบรมอย่างต่อเนื่อง และสถานการณ์ขนาดใหญ่อื่นๆ
ท่อจัดอันดับ
ใน TensorFlow ไปป์ไลน์ทั่วไปสำหรับสร้าง ฝึกฝน และให้บริการโมเดลการจัดอันดับจะมีขั้นตอนทั่วไปดังต่อไปนี้
- กำหนดโครงสร้างแบบจำลอง:
- สร้างอินพุต;
- สร้างเลเยอร์ก่อนการประมวลผล
- สร้างสถาปัตยกรรมเครือข่ายประสาทเทียม
- โมเดลรถไฟ:
- สร้างชุดข้อมูลการฝึกอบรมและการตรวจสอบความถูกต้องจากบันทึกข้อมูล
- เตรียมโมเดลด้วยไฮเปอร์พารามิเตอร์ที่เหมาะสม:
- เครื่องมือเพิ่มประสิทธิภาพ;
- การสูญเสียอันดับ;
- ตัวชี้วัดการจัดอันดับ;
- กำหนดค่า กลยุทธ์แบบกระจาย เพื่อฝึกอบรมบนอุปกรณ์หลายเครื่อง
- กำหนด ค่าการโทรกลับ สำหรับการทำบัญชีต่างๆ
- รูปแบบการส่งออกสำหรับการให้บริการ
- รูปแบบการให้บริการ:
- กำหนดรูปแบบข้อมูลขณะให้บริการ
- เลือกและโหลดโมเดลที่ผ่านการฝึกอบรม
- กระบวนการกับโมเดลที่โหลด
วัตถุประสงค์หลักประการหนึ่งของไปป์ไลน์การจัดอันดับ TensorFlow คือการลดโค้ดสำเร็จรูปในขั้นตอนต่างๆ เช่น การโหลดชุดข้อมูลและการประมวลผลล่วงหน้า ความเข้ากันได้ของข้อมูลแบบรายการและฟังก์ชันการให้คะแนนแบบจุด และการส่งออกแบบจำลอง วัตถุประสงค์ที่สำคัญอีกประการหนึ่งคือการบังคับใช้การออกแบบที่สอดคล้องกันของกระบวนการต่างๆ ที่มีความสัมพันธ์กันโดยเนื้อแท้ เช่น อินพุตแบบจำลองจะต้องเข้ากันได้กับทั้งชุดข้อมูลการฝึกอบรมและรูปแบบข้อมูลในการให้บริการ
ใช้คำแนะนำ
ด้วยการออกแบบทั้งหมดข้างต้น การเปิดตัวโมเดลการจัดอันดับ TF จึงมีขั้นตอนต่อไปนี้ ดังแสดงในรูปที่ 1
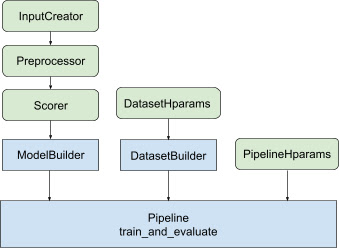
ตัวอย่างการใช้โครงข่ายประสาทเทียมแบบกระจาย
ในตัวอย่างนี้ คุณจะใช้ประโยชน์จาก tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder มีอยู่แล้วภายใน และ tfr.keras.pipeline.SimplePipeline ที่ใช้ใน feature_spec s เพื่อกำหนดคุณลักษณะอินพุตในอินพุตของโมเดลและ เซิร์ฟเวอร์ชุดข้อมูล สามารถดูเวอร์ชันโน้ตบุ๊กพร้อมคำแนะนำแบบทีละขั้นตอนได้ใน บทช่วยสอนการจัดอันดับแบบกระจาย
ขั้นแรกให้กำหนด feature_spec สำหรับทั้งคุณสมบัติบริบทและตัวอย่าง
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
ทำตามขั้นตอนที่แสดงในรูปที่ 1:
กำหนด input_creator จาก feature_spec s
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
จากนั้นกำหนดการแปลงคุณสมบัติการประมวลผลล่วงหน้าสำหรับคุณสมบัติอินพุตชุดเดียวกัน
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
กำหนดผู้บันทึกคะแนนด้วยโมเดล DNN ฟีดฟอร์เวิร์ดในตัว
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
สร้าง model_builder ด้วย input_creator , preprocessor และ scorer
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
ตอนนี้ตั้งค่าไฮเปอร์พารามิเตอร์สำหรับ dataset_builder
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
สร้าง dataset_builder
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
ตั้งค่าไฮเปอร์พารามิเตอร์สำหรับไปป์ไลน์ด้วย
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
สร้าง ranking_pipeline และฝึกฝน
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
การออกแบบไปป์ไลน์การจัดอันดับ TensorFlow
ไปป์ไลน์การจัดอันดับ TensorFlow ช่วยประหยัดเวลาทางวิศวกรรมด้วยโค้ดสำเร็จรูป ขณะเดียวกันก็ให้ความยืดหยุ่นในการปรับแต่งผ่านการแทนที่และคลาสย่อย เพื่อให้บรรลุเป้าหมายนี้ ไปป์ไลน์จึงแนะนำคลาสที่ปรับแต่งได้ tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder และ tfr.keras.pipeline.AbstractPipeline เพื่อตั้งค่าไปป์ไลน์ TensorFlow Ranking

ModelBuilder
รหัสสำเร็จรูปที่เกี่ยวข้องกับการสร้างแบบจำลอง Keras จะถูกรวมไว้ใน AbstractModelBuilder ซึ่งส่งผ่านไปยัง AbstractPipeline และเรียกภายในไปป์ไลน์เพื่อสร้างแบบจำลองภายใต้ขอบเขตกลยุทธ์ ดังแสดงในรูปที่ 1 วิธีการเรียนถูกกำหนดไว้ในคลาสฐานนามธรรม
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
คุณสามารถซับคลาส AbstractModelBuilder ได้โดยตรง และเขียนทับด้วยวิธีการปรับแต่งที่เป็นรูปธรรม เช่น
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
ในเวลาเดียวกัน คุณควรใช้ ModelBuilder ที่มีคุณสมบัติอินพุต การแปลงการประมวลผลล่วงหน้า และฟังก์ชันการให้คะแนนที่ระบุเป็นฟังก์ชัน inputs input_creator , preprocessor และ scorer ในคลาส init แทนที่จะเป็นคลาสย่อย
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
เพื่อลดความจำเป็นในการสร้างอินพุตเหล่านี้ จึงจัดให้มีคลาสฟังก์ชัน tfr.keras.model.InputCreator สำหรับ input_creator , tfr.keras.model.Preprocessor สำหรับ preprocessor และ tfr.keras.model.Scorer สำหรับ scorer ไว้พร้อมกับคลาสย่อยที่เป็นรูปธรรม tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer และ tfr.keras.model.GAMScorer สิ่งเหล่านี้ควรครอบคลุมกรณีการใช้งานทั่วไปส่วนใหญ่
โปรดทราบว่าคลาสฟังก์ชันเหล่านี้เป็นคลาส Keras ดังนั้นจึงไม่จำเป็นต้องทำให้เป็นอนุกรม คลาสย่อยเป็นวิธีที่แนะนำสำหรับการปรับแต่งคลาสย่อย
DatasetBuilder
คลาส DatasetBuilder รวบรวมชุดข้อมูลสำเร็จรูปที่เกี่ยวข้องกับชุดข้อมูล ข้อมูลจะถูกส่งไปยัง Pipeline และเรียกใช้เพื่อให้บริการชุดข้อมูลการฝึกอบรมและการตรวจสอบความถูกต้อง และเพื่อกำหนดลายเซ็นการให้บริการสำหรับโมเดลที่บันทึกไว้ ดังแสดงในรูปที่ 1 เมธอด DatasetBuilder ถูกกำหนดไว้ในคลาสพื้นฐาน tfr.keras.pipeline.AbstractDatasetBuilder
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
ในคลาส DatasetBuilder ที่เป็นรูปธรรม คุณต้องใช้ build_train_datasets , build_valid_datasets และ build_signatures
คลาสที่เป็นรูปธรรมที่สร้างชุดข้อมูลจาก feature_spec ก็มีให้เช่นกัน:
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
hparams ที่ใช้ใน DatasetBuilder ระบุไว้ในคลาสข้อมูล tfr.keras.pipeline.DatasetHparams
ไปป์ไลน์
Ranking Pipeline ขึ้นอยู่กับคลาส tfr.keras.pipeline.AbstractPipeline :
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
คลาสไปป์ไลน์ที่เป็นรูปธรรมที่ฝึกโมเดลด้วย tf.distribute.strategy ที่แตกต่างกันซึ่งเข้ากันได้กับ model.fit ก็มีให้เช่นกัน:
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
hparams ที่ใช้ใน tfr.keras.pipeline.ModelFitPipeline ถูกระบุในคลาสข้อมูล tfr.keras.pipeline.PipelineHparams คลาส ModelFitPipeline นี้เพียงพอสำหรับกรณีการใช้งาน TF Ranking ส่วนใหญ่ ลูกค้าสามารถจัดคลาสย่อยได้อย่างง่ายดายเพื่อวัตถุประสงค์เฉพาะ
การสนับสนุนกลยุทธ์แบบกระจาย
โปรดดู การฝึกอบรมแบบกระจาย สำหรับการแนะนำโดยละเอียดเกี่ยวกับกลยุทธ์แบบกระจายที่รองรับ TensorFlow ปัจจุบันไปป์ไลน์การจัดอันดับ TensorFlow รองรับ tf.distribute.MirroredStrategy (ค่าเริ่มต้น), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy และ tf.distribute.ParameterServerStrategy กลยุทธ์แบบมิเรอร์เข้ากันได้กับระบบเครื่องจักรเดี่ยวส่วนใหญ่ โปรดตั้งค่า strategy เป็น None หากไม่มีกลยุทธ์แบบกระจาย
โดยทั่วไป MirroredStrategy ใช้ได้กับรุ่นที่ค่อนข้างเล็กบนอุปกรณ์ส่วนใหญ่ที่มีตัวเลือก CPU และ GPU MultiWorkerMirroredStrategy ใช้ได้กับโมเดลขนาดใหญ่ที่ไม่เหมาะกับผู้ปฏิบัติงานเพียงคนเดียว ParameterServerStrategy ทำการฝึกอบรมแบบอะซิงโครนัสและต้องมีผู้ปฏิบัติงานหลายคน TPUStrategy เหมาะอย่างยิ่งสำหรับโมเดลขนาดใหญ่และข้อมูลขนาดใหญ่เมื่อมี TPU พร้อมใช้งาน อย่างไรก็ตาม ในแง่ของรูปร่างเทนเซอร์จะมีความยืดหยุ่นน้อยกว่าที่ TPU สามารถรองรับได้
คำถามที่พบบ่อย
ชุดส่วนประกอบขั้นต่ำสำหรับการใช้
RankingPipeline
ดู โค้ดตัวอย่าง ด้านบนจะเป็นอย่างไรถ้าฉันมี
modelKeras ของตัวเอง
หากต้องการฝึกใช้กลยุทธ์tf.distributeจะต้องสร้างmodelด้วยตัวแปรที่สามารถฝึกได้ทั้งหมดที่กำหนดไว้ภายใต้ Strategy.scope() ดังนั้นให้รวมโมเดลของคุณในModelBuilderเป็น
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
จากนั้นป้อน model_builder นี้ไปยังไปป์ไลน์เพื่อการฝึกอบรมเพิ่มเติม