
Copyright 2018 The TF-Agents Authors.
 GitHub でソースを表示 GitHub でソースを表示 |
はじめに
強化学習 (RL) は、報酬を最大化するために、エージェントが環境に対して実行する行動を学ぶための一般的なフレームワークです。強化学習における主要なコンポーネントは、環境 (解決すべき問題) とエージェント (学習アルゴリズム) の 2 つです。
エージェントと環境は継続的に相互に対話します。各時間ステップで、エージェントはそのポリシー \(\pi(a_t|s_t)\) に基づいて環境に対して行動を実行します。\(s_t\) は環境からのその時点の観測で、報酬 \(r_{t+1}\) と環境からの次の観測 \(s_{t+1}\) を受け取ります。目標は、報酬 (リターン) の合計を最大化するようにポリシーを改善することです。
注:環境の状態と観測を区別することが重要です。観測は、エージェントが認識する環境の状態の一部です。たとえば、ポーカーゲームでは、環境の状態はすべてのプレーヤーのカードとコミュニティカードで構成されますが、エージェントは自分のカードといくつかのコミュニティカードしか観測できません。ほとんどの文献では、これらの用語は同じ意味で使用されており、観測結果は \(s\) とも表記されます。
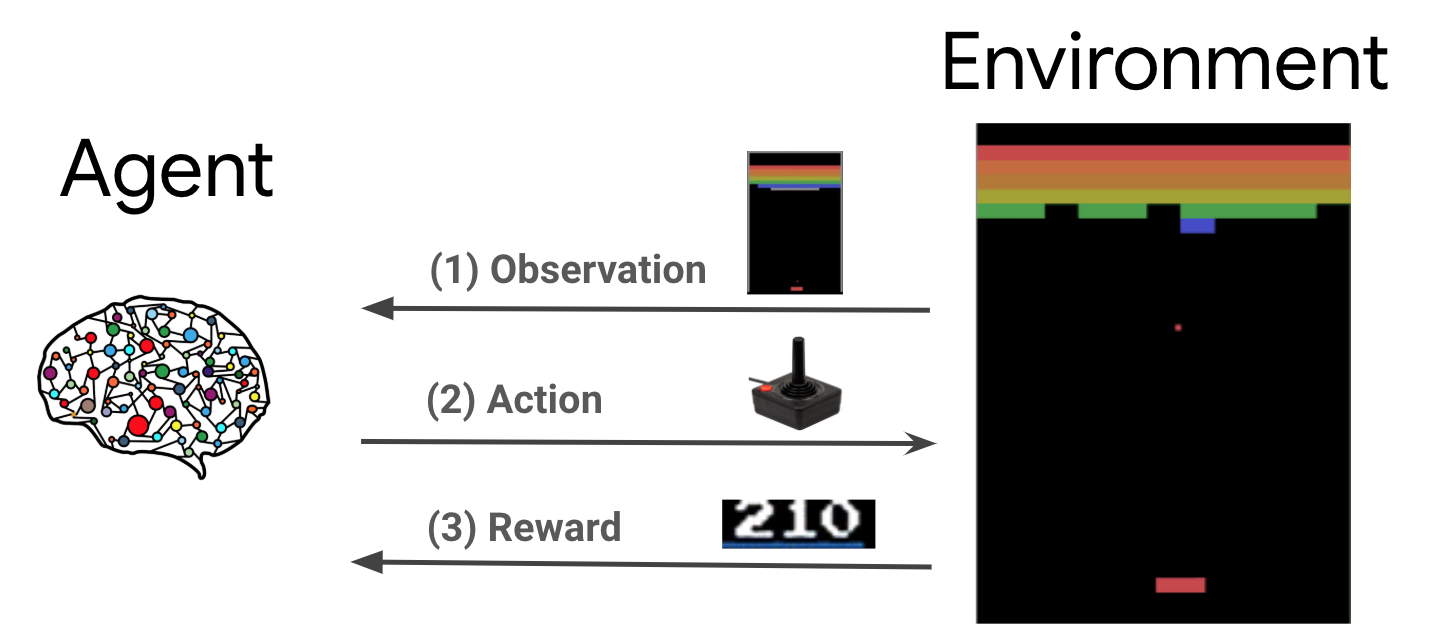
これは非常に一般的なフレームワークであり、ゲームやロボット工学など、さまざまな逐次的な意思決定の問題をモデル化できます。
CartPole環境
CartPole環境は、最もよく知られている古典的な強化学習の問題の 1 つです(強化学習の"Hello, World!")。台車の上に立てられた棒が倒れないように台車を制御するのが課題です。台車は摩擦のない軌道上を移動します。
- 環境 \(s_t\) からの観測は、台車の位置と速度、および棒の角度と角速度を表す 4D ベクトルです。
- エージェントは、\(a_t\) の 2 つの行動 (台車を右 (+1) または左 (-1) に動かす) のいずれかを実行してシステムを制御できます。
- 棒が倒れずに立っている場合は、時間ステップごとに報酬 \(r_{t+1} = 1\) が提供されます。以下の場合、エピソードは終了します。
- 棒が一定の制限された角度より傾いた場合
- 台車が指定された枠外に出た場合
- 時間ステップが 200 を経過した場合
エージェントの課題は、エピソードの報酬の合計 \(\sum_{t=0}^{T} \gamma^t r_t\) を最大化するポリシー \(\pi(a_t|s_t)\)を学ぶことです。ここでは、\(\gamma\)は\([0, 1]\) の割引係数であり、即時の報酬に対して将来の報酬を割引します。このパラメータは、報酬を迅速に取得することを重視するポリシーを作成することに役立ちます。
DQN エージェント
DQN (Deep Q-Network) アルゴリズムは、DeepMind により 2015 年に開発されたアルゴリズムで、大規模な強化学習とディープニューラルネットワークを組み合わせることで、幅広いAtariゲームを解くことができました (ゲームによっては超人的なレベルを達成)。このアルゴリズムは、ディープニューラルネットワークで Q-Learning と呼ばれる古典的な強化学習アルゴリズムの拡張と経験再生 (Experience Replay) と呼ばれる手法により開発されました。
Q 学習
Q 学習は Q 関数の概念に基づいています。ポリシー \(\pi\), \(Q^{\pi}(s, a)\) のQ関数(状態アクション値関数)は、最初に \(a\) を実行し、その後にポリシー \(\pi\) を実行し、状態 \(s\) から得られる予期される報酬または割引された報酬の合計を測定します。最適な Q 関数 \(Q^*(s, a)\) は、観測 \(s\) から開始して、行動 \(a\) を実行し、その後最適なポリシーを実行する場合に取得可能な最大の報酬として定義します。最適な Q 関数は、次のベルマン最適化方程式に従います。
\(\begin{equation}Q^\ast(s, a) = \mathbb{E}[ r + \gamma \max_{a'} Q^\ast(s', a') ]\end{equation}\)
つまり、状態 \(s\) と行動 \(a\) からの最大のリターンは、即時の報酬 \(r\) とエピソードの最後まで最適なポリシーに従うことによって得られるリターン (\(\gamma\) で割引) の合計です。 (つまり、次の状態 \(s'\) からの最大報酬)。予測値は、即時の報酬 \(r\) と可能な次の状態 \(s'\) の両方の分布に対して計算されます。
Q 学習の背後にある基本的な考え方は、ベルマン最適化方程式を反復更新(\(Q_{i+1}(s, a) \leftarrow \mathbb{E}\left[ r + \gamma \max_{a'} Q_{i}(s', a')\right]\))として使用すると、最適な \(Q\) 関数(\(Q_i \rightarrow Q^*\) as \(i \rightarrow \infty\))に収束されるいうことです。詳細については、(DQN 関連論文)を参照してください。
ディープ Q 学習
ほとんどの問題では、\(Q\) 関数を \(s\) と \(a\) の各組み合わせの値を含む表として示すことは現実的ではありません。代わりに、Q 値を推定するために、パラメータ \(\theta\) を使用するニューラルネットワークなどの関数近似器 (\(Q(s, a; \theta) \approx Q^*(s, a)\)をトレーニングします。) 各ステップ \(i\) では、次の損失を最小限に抑えます。
\(\begin{equation}L_i(\theta_i) = \mathbb{E}*{s, a, r, s'\sim \rho(.)} \left[ (y_i - Q(s, a; \theta_i))^2 \right]\end{equation}\) where \(y_i = r + \gamma \max*{a'} Q(s', a'; \theta_{i-1})\)
ここで、\(y_i\)は TD (時間差) ターゲットと呼ばれ、\(y_i - Q\) は TD エラーと呼ばれます。環境から収集された \(\rho\) は動作の分布、遷移 \({s, a, r, s'}\) の分布を表します。
前のイテレーション \(\theta_{i-1}\) のパラメータは固定されており、更新されていないことに注意してください。実際には、最後のイテレーションではなく、数回前のイテレーションのネットワークパラメータのスナップショットを使用します。このコピーはターゲットネットワークと呼ばれます。
Q 学習は、環境における行動/データの収集に異なる行動ポリシーを使用しながら、グリーディなポリシー (\(a = \max_{a} Q(s, a; \theta)\)) について学習するオフポリシーアルゴリズムです。通常、この動作ポリシーは \(\epsilon\)-グリーディポリシーで、確率 \(1-\epsilon\) のグリーディな行動と確率 \(\epsilon\) のランダムな行動を選択して、状態と行動のスペースを適切に網羅します。
経験再生
DQN 損失の完全な予想値の計算を回避するために、確率的勾配降下法を使用してそれを最小化できます。最後の遷移 \({s, a, r, s'}\) のみを使用して損失が計算される場合、これは標準の Q 学習になります。
DQN が ATARI を学習する場合、ネットワークの更新をより安定させるために、経験再生 (Experience Replay) と呼ばれる手法が導入されました。データ収集の各時間ステップで、遷移は再生バッファと呼ばれる循環バッファに追加されます。次に、トレーニング時には、最新の遷移だけでなく、再生バッファからサンプリングされた遷移のミニバッチを使用して損失とその勾配が計算されます。これには、多くの更新で各遷移を再利用することによりデータ効率が向し、無相関遷移をバッチで使用することにより安定性が向上するという 2 つの利点があります。
TF-Agents ライブラリを使用した Cartpole 環境の DQN
TF-Agent は、エージェント自体、環境、ポリシー、ネットワーク、再生バッファ、データ収集ループ、メトリックなど、DQN エージェントのトレーニングに必要なすべてのコンポーネントを提供します。これらのコンポーネントは Python 関数または TensorFlow グラフオペレーションとして実装されており、それらの間で変換するためのラッパーも提供されています。さらに、TF-Agent は TensorFlow 2.0 モードをサポートしており、命令モードで TF を使用できます。
次に TF-Agent を使用して Cartpole 環境で DQN エージェントをトレーニングするためのチュートリアルを見てみましょう。