
Copyright 2018 The TF-Agents Authors.
| |
 GitHub でソースを表示{ GitHub でソースを表示{ |
はじめに
ここでは、Cartpole環境でTF-Agentライブラリを使用してCategorical DQN (C51)エージェントをトレーニングする方法を紹介します。
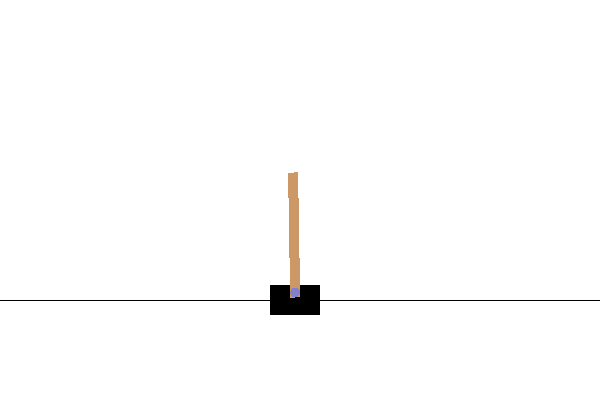
はじめる前に、 DQNチュートリアルをご覧ください。このチュートリアルは、DQNチュートリアルに精通されていることを前提とし、主にDQNとC51の違いについて見ていきます。
セットアップ
TF-agentをまだインストールしていない場合は、次を実行します。
sudo apt-get install -y xvfb ffmpegpip install -q 'gym==0.10.11'pip install -q 'imageio==2.4.0'pip install -q PILLOWpip install -q 'pyglet==1.3.2'pip install -q pyvirtualdisplaypip install -q tf-agents
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib
import matplotlib.pyplot as plt
import PIL.Image
import pyvirtualdisplay
import tensorflow as tf
from tf_agents.agents.categorical_dqn import categorical_dqn_agent
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.eval import metric_utils
from tf_agents.metrics import tf_metrics
from tf_agents.networks import categorical_q_network
from tf_agents.policies import random_tf_policy
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
tf.compat.v1.enable_v2_behavior()
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
ハイパーパラメータ
env_name = "CartPole-v1" # @param {type:"string"}
num_iterations = 15000 # @param {type:"integer"}
initial_collect_steps = 1000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 100000 # @param {type:"integer"}
fc_layer_params = (100,)
batch_size = 64 # @param {type:"integer"}
learning_rate = 1e-3 # @param {type:"number"}
gamma = 0.99
log_interval = 200 # @param {type:"integer"}
num_atoms = 51 # @param {type:"integer"}
min_q_value = -20 # @param {type:"integer"}
max_q_value = 20 # @param {type:"integer"}
n_step_update = 2 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 1000 # @param {type:"integer"}
環境
前回のように環境を読み込みます。1つはトレーニング用で、もう1つは評価用です。ここでは、最大報酬が200ではなく500であるCartPole-v1(DQNチュートリアルではCartPole-v0を使用)を使用します。
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
エージェント
C51は、DQNに基づくQ学習アルゴリズムです。 DQNと同様に、個別の行動空間がある任意の環境で使用できます。
C51とDQNの主な違いは、各状態と行動のペアのQ値を単に予測するのではなく、C51はQ値の確率分布のヒストグラムモデルを予測することです。

単なる推定値ではなく分布を学習することで、アルゴリズムはトレーニング時に安定性を維持でき、最終的なパフォーマンスが向上します。これは、単一の平均では正確な画像が得られない、バイモーダルまたはマルチモーダルの値の分布がある場合に特に有用です。
C51は値ではなく確率分布でトレーニングするために、損失関数を計算するために複雑な分布計算を実行する必要がありますが、これらはすべてTF-Agentで処理されます。
C51 Agentを作成するには、まずCategoricalQNetworkを作成する必要があります。CategoricalQNetworkのAPIは、QNetworkのAPIと同じですが、引数num_atomsが追加されます。これは、確率分布の推定におけるサポートポイントの数を表します。(上の画像には10個のサポートポイントが含まれており、それぞれが青い縦棒で表されています。)名前からわかるように、デフォルトのatom数は51です。
categorical_q_net = categorical_q_network.CategoricalQNetwork(
train_env.observation_spec(),
train_env.action_spec(),
num_atoms=num_atoms,
fc_layer_params=fc_layer_params)
また、先ほど作成したネットワークをトレーニングするためのoptimizerと、ネットワークが更新された回数を追跡するためのtrain_step_counter変数も必要です。
簡単なDqnAgentとのもう1つの重要な違いは、引数としてmin_q_valueとmax_q_valueを指定する必要があることです。これらは、サポートの最も極端な値(51のatomの最も極端な値)を指定します。特定の環境に合わせてこれらを適切に選択してください。 ここでは、-20と20を使用します。
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate)
train_step_counter = tf.compat.v2.Variable(0)
agent = categorical_dqn_agent.CategoricalDqnAgent(
train_env.time_step_spec(),
train_env.action_spec(),
categorical_q_network=categorical_q_net,
optimizer=optimizer,
min_q_value=min_q_value,
max_q_value=max_q_value,
n_step_update=n_step_update,
td_errors_loss_fn=common.element_wise_squared_loss,
gamma=gamma,
train_step_counter=train_step_counter)
agent.initialize()
最後に注意すべき点は、\(n\) = 2のnステップ更新を使用する引数も追加されていることです。1ステップのQ学習(\(n\) = 1)では、(ベルマン最適化方程式に基づいて)1ステップの戻り値を使用して、その時点のタイムステップと次のタイムステップでのQ値間の誤差のみを計算します。 1ステップの戻り値は次のように定義されます。
\(G_t = R_{t + 1} + \gamma V(s_{t + 1})\)
\(V(s) = \max_a{Q(s, a)}\)と定義します。
nステップ更新では、標準の1ステップの戻り関数は\(n\)倍に拡張されます。
\(G_t^n = R_{t + 1} + \gamma R_{t + 2} + \gamma^2 R_{t + 3} + \dots + \gamma^n V(s_{t + n})\)
nステップ更新により、エージェントは将来からブートストラップできるようになり、正しい\(n\)値を使用することで、多くの場合、学習が迅速になります。
C51とnステップの更新は、多くの場合、優先再生と組み合わされてRainbow agentの中核となっていますが、優先再生の実装による測定可能な改善は見られませんでした。さらに、C51エージェントをnステップの更新のみと組み合わせた場合、エージェントは、テストしたAtari環境のサンプルで他のRainbowエージェントと同様に機能することが明らかになっています。
指標と評価
ポリシーの評価に使用される最も一般的なメトリックは、平均利得です。利得は、エピソードの環境でポリシーを実行中に取得した報酬の総計です。通常、数エピソードが実行され、平均利得が生成されます。
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
random_policy = random_tf_policy.RandomTFPolicy(train_env.time_step_spec(),
train_env.action_spec())
compute_avg_return(eval_env, random_policy, num_eval_episodes)
# Please also see the metrics module for standard implementations of different
# metrics.
19.8
データ収集
DQNチュートリアルと同様に、ランダムポリシーを使用して再生バッファーと初期データ収集を設定します。
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.collect_data_spec,
batch_size=train_env.batch_size,
max_length=replay_buffer_capacity)
def collect_step(environment, policy):
time_step = environment.current_time_step()
action_step = policy.action(time_step)
next_time_step = environment.step(action_step.action)
traj = trajectory.from_transition(time_step, action_step, next_time_step)
# Add trajectory to the replay buffer
replay_buffer.add_batch(traj)
for _ in range(initial_collect_steps):
collect_step(train_env, random_policy)
# This loop is so common in RL, that we provide standard implementations of
# these. For more details see the drivers module.
# Dataset generates trajectories with shape [BxTx...] where
# T = n_step_update + 1.
dataset = replay_buffer.as_dataset(
num_parallel_calls=3, sample_batch_size=batch_size,
num_steps=n_step_update + 1).prefetch(3)
iterator = iter(dataset)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow/python/autograph/operators/control_flow.py:1218: ReplayBuffer.get_next (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=False) instead.
エージェントのトレーニング
トレーニングループには、環境からのデータ収集とエージェントのネットワークの最適化の両方が含まれます。途中で、エージェントのポリシーを時々評価して、状況を確認します。
以下の実行には7分ほどかかります。
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
agent.train = common.function(agent.train)
# Reset the train step
agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few steps using collect_policy and save to the replay buffer.
for _ in range(collect_steps_per_iteration):
collect_step(train_env, agent.collect_policy)
# Sample a batch of data from the buffer and update the agent's network.
experience, unused_info = next(iterator)
train_loss = agent.train(experience)
step = agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1:.2f}'.format(step, avg_return))
returns.append(avg_return)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow/python/util/dispatch.py:201: calling foldr_v2 (from tensorflow.python.ops.functional_ops) with back_prop=False is deprecated and will be removed in a future version. Instructions for updating: back_prop=False is deprecated. Consider using tf.stop_gradient instead. Instead of: results = tf.foldr(fn, elems, back_prop=False) Use: results = tf.nest.map_structure(tf.stop_gradient, tf.foldr(fn, elems)) step = 200: loss = 3.2590088844299316 step = 400: loss = 2.632638454437256 step = 600: loss = 2.300567150115967 step = 800: loss = 1.9189338684082031 step = 1000: loss = 1.8005417585372925 step = 1000: Average Return = 62.60 step = 1200: loss = 1.5831822156906128 step = 1400: loss = 1.5459437370300293 step = 1600: loss = 1.4490900039672852 step = 1800: loss = 1.2279764413833618 step = 2000: loss = 1.1527073383331299 step = 2000: Average Return = 210.00 step = 2200: loss = 1.4644639492034912 step = 2400: loss = 1.1290091276168823 step = 2600: loss = 1.4811760187149048 step = 2800: loss = 0.947868287563324 step = 3000: loss = 1.0832934379577637 step = 3000: Average Return = 272.80 step = 3200: loss = 0.9990764856338501 step = 3400: loss = 0.8357860445976257 step = 3600: loss = 0.709689199924469 step = 3800: loss = 0.6691354513168335 step = 4000: loss = 0.757969856262207 step = 4000: Average Return = 404.80 step = 4200: loss = 0.7597946524620056 step = 4400: loss = 0.8957338333129883 step = 4600: loss = 0.7238802313804626 step = 4800: loss = 0.63671875 step = 5000: loss = 0.5388354063034058 step = 5000: Average Return = 251.10 step = 5200: loss = 0.4851800203323364 step = 5400: loss = 0.6211602687835693 step = 5600: loss = 0.6293035745620728 step = 5800: loss = 0.5646753907203674 step = 6000: loss = 0.5161392688751221 step = 6000: Average Return = 285.10 step = 6200: loss = 0.6528369784355164 step = 6400: loss = 0.5472080707550049 step = 6600: loss = 0.5291409492492676 step = 6800: loss = 0.4526470899581909 step = 7000: loss = 0.49972108006477356 step = 7000: Average Return = 378.10 step = 7200: loss = 0.5145469903945923 step = 7400: loss = 0.5111323595046997 step = 7600: loss = 0.5726427435874939 step = 7800: loss = 0.5441312193870544 step = 8000: loss = 0.3262447416782379 step = 8000: Average Return = 306.80 step = 8200: loss = 0.6022365093231201 step = 8400: loss = 0.5231387615203857 step = 8600: loss = 0.5393173694610596 step = 8800: loss = 0.5394942760467529 step = 9000: loss = 0.41384193301200867 step = 9000: Average Return = 336.60 step = 9200: loss = 0.47844964265823364 step = 9400: loss = 0.3494521379470825 step = 9600: loss = 0.3591991662979126 step = 9800: loss = 0.4692155718803406 step = 10000: loss = 0.32455652952194214 step = 10000: Average Return = 291.70 step = 10200: loss = 0.4829924404621124 step = 10400: loss = 0.2623593211174011 step = 10600: loss = 0.39539244771003723 step = 10800: loss = 0.37915438413619995 step = 11000: loss = 0.38126373291015625 step = 11000: Average Return = 378.00 step = 11200: loss = 0.4339791238307953 step = 11400: loss = 0.4831956624984741 step = 11600: loss = 0.2808476686477661 step = 11800: loss = 0.480874627828598 step = 12000: loss = 0.3181148171424866 step = 12000: Average Return = 239.60 step = 12200: loss = 0.33834972977638245 step = 12400: loss = 0.37028729915618896 step = 12600: loss = 0.2688298225402832 step = 12800: loss = 0.4945523142814636 step = 13000: loss = 0.3561866879463196 step = 13000: Average Return = 386.30 step = 13200: loss = 0.23996201157569885 step = 13400: loss = 0.2798241972923279 step = 13600: loss = 0.3246690034866333 step = 13800: loss = 0.17307987809181213 step = 14000: loss = 0.3604293763637543 step = 14000: Average Return = 432.20 step = 14200: loss = 0.1905684769153595 step = 14400: loss = 0.2769245505332947 step = 14600: loss = 0.2986299991607666 step = 14800: loss = 0.2771676182746887 step = 15000: loss = 0.3467143177986145 step = 15000: Average Return = 387.40
可視化
プロット
利得とグローバルステップをプロットして、エージェントのパフォーマンスを確認できます。Cartpole-v1では、棒が立ったままでいるタイムステップごとに環境は+1の報酬を提供します。最大ステップ数は500であるため、可能な最大利得値も500です。
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=550)
(-11.635000610351565, 550.0)

動画
各ステップで環境をレンダリングすると、エージェントのパフォーマンスを可視化できます。その前に、このColabに動画を埋め込む関数を作成しましょう。
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
次のコードは、いくつかのエピソードに渡るエージェントのポリシーを可視化します。
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned.
C51はCartPole-v1のDQNよりもわずかに優れていますが、2つのエージェントの違いは、複雑化する環境ではより重要になります。たとえば、完全なAtari 2600ベンチマークでは、C51は、ランダムエージェントに関して正規化した後、DQNよりも平均スコアが126%向上しています。n ステップ更新を含めると、スコアはさらに改善されます。
C51アルゴリズムの詳細については、強化学習における報酬分布(2017)を参照してください。