
Copyright 2018 The TF-Agents Authors.
 GitHub에서 소스 보기 GitHub에서 소스 보기 |
소개
이 예는 TF-Agents 라이브러리를 사용하여 Cartpole 환경에서 Categorical DQN(C51) 에이전트를 훈련하는 방법을 보여줍니다.
전제 조건으로 DQN 튜토리얼을 살펴보아야 합니다. 이 튜토리얼에서는 DQN 튜토리얼에 익숙하다고 가정합니다. 여기서는 주로 DQN과 C51의 차이점에 중점을 둡니다.
설정
tf-agents를 아직 설치하지 않은 경우 다음을 실행합니다.
sudo apt-get install -y xvfb ffmpegpip install -q 'gym==0.10.11'pip install -q 'imageio==2.4.0'pip install -q PILLOWpip install -q 'pyglet==1.3.2'pip install -q pyvirtualdisplaypip install -q tf-agents
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib
import matplotlib.pyplot as plt
import PIL.Image
import pyvirtualdisplay
import tensorflow as tf
from tf_agents.agents.categorical_dqn import categorical_dqn_agent
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.eval import metric_utils
from tf_agents.metrics import tf_metrics
from tf_agents.networks import categorical_q_network
from tf_agents.policies import random_tf_policy
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
tf.compat.v1.enable_v2_behavior()
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
하이퍼 매개변수
env_name = "CartPole-v1" # @param {type:"string"}
num_iterations = 15000 # @param {type:"integer"}
initial_collect_steps = 1000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 100000 # @param {type:"integer"}
fc_layer_params = (100,)
batch_size = 64 # @param {type:"integer"}
learning_rate = 1e-3 # @param {type:"number"}
gamma = 0.99
log_interval = 200 # @param {type:"integer"}
num_atoms = 51 # @param {type:"integer"}
min_q_value = -20 # @param {type:"integer"}
max_q_value = 20 # @param {type:"integer"}
n_step_update = 2 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 1000 # @param {type:"integer"}
환경
이전과 같이 훈련용과 평가용으로 각각 하나의 환경을 로드합니다. 여기서는 200개가 아니라 500개의 보다 큰 최대 보상을 가진 CartPole-v1(DQN 튜토리얼에서는 CartPole-v0이었음)을 사용합니다.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
에이전트
C51은 DQN을 기반으로 하는 Q-러닝 알고리즘으로, DQN과 마찬가지로 불연속 행동 공간이 있는 모든 환경에서 사용할 수 있습니다.
C51이 DQN과 가장 다른 점은 각 상태-행동 쌍에 대한 Q-value를 단순히 예측하는 것이 아니라 Q-값의 확률 분포에 대한 히스토그램 모델을 예측한다는 것입니다.

알고리즘은 단순히 예상 값이 아닌 분포를 학습함으로써 훈련 중에 더 안정적으로 유지되어 최종 성능을 향상할 수 있습니다. 단일 평균이 정확한 그림을 제공하지 않는 바이 모달 또는 멀티 모달 값 분포가 있는 상황에서 특히 그렇습니다.
값이 아닌 확률 분포에 대해 훈련하려면 손실 함수를 계산하기 위해 C51에서 복잡한 분포 계산을 수행해야 합니다. 하지만 걱정하지 마세요. 이 모든 작업은 TF-Agents에서 처리합니다!
C51 에이전트를 만들려면 먼저 CategoricalQNetwork를 만들어야 합니다. CategoricalQNetwork의 API는 추가 인수 num_atoms가 있다는 점을 제외하고 QNetwork의 API와 동일합니다. 이것은 확률 분포 추정의 지원 포인트 수를 나타냅니다. (위의 이미지에는 각각 파란색 세로 막대로 표시된 10개의 지원 포인트가 포함되어 있습니다.) 이름에서 알 수 있듯이 기본 원자 수는 51개입니다.
categorical_q_net = categorical_q_network.CategoricalQNetwork(
train_env.observation_spec(),
train_env.action_spec(),
num_atoms=num_atoms,
fc_layer_params=fc_layer_params)
또한, 방금 생성한 네트워크를 훈련하기 위해 optimizer가 필요하고, 네트워크가 몇 번 업데이트되었는지 추적하기 위해train_step_counter 변수가 필요합니다.
바닐라 DqnAgent와 다른 또 다른 주된 차이점은 이제 min_q_value 및 max_q_value를 인수로 지정해야 한다는 것입니다. 이러한 인수는 지원의 가장 극단적인 값(즉, 양쪽에서 51개 원자 중 가장 극단의 값)을 지정합니다. 특정 환경에 적합하게 선택해야 합니다. 여기서는 -20과 20을 사용합니다.
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate)
train_step_counter = tf.compat.v2.Variable(0)
agent = categorical_dqn_agent.CategoricalDqnAgent(
train_env.time_step_spec(),
train_env.action_spec(),
categorical_q_network=categorical_q_net,
optimizer=optimizer,
min_q_value=min_q_value,
max_q_value=max_q_value,
n_step_update=n_step_update,
td_errors_loss_fn=common.element_wise_squared_loss,
gamma=gamma,
train_step_counter=train_step_counter)
agent.initialize()
마지막으로 주목해야 할 점은 n-step 업데이트를 \(n\) = 2로 사용하는 인수를 추가했다는 것입니다. 단일 스텝 Q-learning (\(n\) = 1)에서는 단일 스텝 이익을 사용하여 현재 타임스텝과 다음 타임스텝에서 Q-값 사이의 오차만 계산합니다(Bellman 최적 방정식에 기초). 단일 스텝 이익은 다음과 같이 정의됩니다.
\(G_t = R_{t + 1} + \gamma V(s_{t + 1})\)
여기서 \(V(s) = \max_a{Q(s, a)}\)로 정의합니다.
N-step 업데이트에는 표준 단일 스텝 이익 함수를 \(n\)번 확장하는 과정이 포함됩니다.
\(G_t^n = R_{t + 1} + \gamma R_{t + 2} + \gamma^2 R_{t + 3} + \dots + \gamma^n V(s_{t + n})\)
N-step 업데이트를 통해 에이전트는 더 먼 미래로부터 부트스트랩을 수행할 수 있으며 \(n\)의 올바른 값으로 대개 학습 속도가 더 빨라집니다.
C51 및 n-step 업데이트는 종종 우선 순위가 지정된 재현과 결합하여 레인보우 에이전트의 코어를 형성하지만, 우선 순위가 지정된 재현을 구현하는 것으로는 측정 가능한 개선이 이루어지지 않았습니다. 또한, C51 에이전트와 n-step 업데이트만 결합하면 이 에이전트뿐만 아니라 다른 레인보우 에이전트도 테스트한 Atari 환경의 샘플에서 실행됩니다.
메트릭 및 평가
정책을 평가하는 데 사용되는 가장 일반적인 메트릭은 평균 이익입니다. 이익은 에피소드의 환경에서 정책을 실행하는 동안 얻은 보상의 합계이며 일반적으로 몇 개 에피소드에서 평균을 계산합니다. 다음과 같이 평균 이익 메트릭을 계산할 수 있습니다.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
random_policy = random_tf_policy.RandomTFPolicy(train_env.time_step_spec(),
train_env.action_spec())
compute_avg_return(eval_env, random_policy, num_eval_episodes)
# Please also see the metrics module for standard implementations of different
# metrics.
24.6
데이터 수집
DQN 튜토리얼에서와 같이 임의 정책으로 재현 버퍼 및 초기 데이터 수집을 설정합니다.
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.collect_data_spec,
batch_size=train_env.batch_size,
max_length=replay_buffer_capacity)
def collect_step(environment, policy):
time_step = environment.current_time_step()
action_step = policy.action(time_step)
next_time_step = environment.step(action_step.action)
traj = trajectory.from_transition(time_step, action_step, next_time_step)
# Add trajectory to the replay buffer
replay_buffer.add_batch(traj)
for _ in range(initial_collect_steps):
collect_step(train_env, random_policy)
# This loop is so common in RL, that we provide standard implementations of
# these. For more details see the drivers module.
# Dataset generates trajectories with shape [BxTx...] where
# T = n_step_update + 1.
dataset = replay_buffer.as_dataset(
num_parallel_calls=3, sample_batch_size=batch_size,
num_steps=n_step_update + 1).prefetch(3)
iterator = iter(dataset)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow/python/autograph/operators/control_flow.py:1004: ReplayBuffer.get_next (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=False) instead.
에이전트 훈련하기
훈련 루프에는 환경에서 데이터를 수집하고 에이전트의 네트워크를 최적화하는 작업이 포함됩니다. 그 과정에서 에이전트의 정책을 평가하여 진행 상황을 파악할 수 있습니다.
다음을 실행하는 데 약 7분이 걸립니다.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
agent.train = common.function(agent.train)
# Reset the train step
agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few steps using collect_policy and save to the replay buffer.
for _ in range(collect_steps_per_iteration):
collect_step(train_env, agent.collect_policy)
# Sample a batch of data from the buffer and update the agent's network.
experience, unused_info = next(iterator)
train_loss = agent.train(experience)
step = agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1:.2f}'.format(step, avg_return))
returns.append(avg_return)
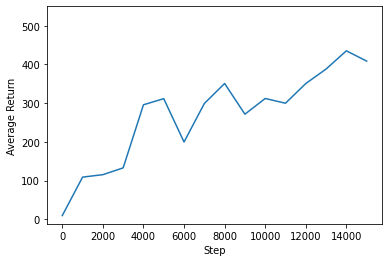
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow/python/util/dispatch.py:201: calling foldr_v2 (from tensorflow.python.ops.functional_ops) with back_prop=False is deprecated and will be removed in a future version. Instructions for updating: back_prop=False is deprecated. Consider using tf.stop_gradient instead. Instead of: results = tf.foldr(fn, elems, back_prop=False) Use: results = tf.nest.map_structure(tf.stop_gradient, tf.foldr(fn, elems)) step = 200: loss = 2.9235901832580566 step = 400: loss = 2.4912521839141846 step = 600: loss = 2.063544273376465 step = 800: loss = 1.9763214588165283 step = 1000: loss = 1.6374388933181763 step = 1000: Average Return = 109.00 step = 1200: loss = 1.6560289859771729 step = 1400: loss = 1.4648106098175049 step = 1600: loss = 1.3268578052520752 step = 1800: loss = 1.3720085620880127 step = 2000: loss = 1.3370134830474854 step = 2000: Average Return = 115.30 step = 2200: loss = 1.1713643074035645 step = 2400: loss = 1.2708210945129395 step = 2600: loss = 1.3232998847961426 step = 2800: loss = 1.2653660774230957 step = 3000: loss = 1.1402384042739868 step = 3000: Average Return = 132.90 step = 3200: loss = 1.0176886320114136 step = 3400: loss = 0.8608313798904419 step = 3600: loss = 0.929936408996582 step = 3800: loss = 0.8328216075897217 step = 4000: loss = 0.8802810907363892 step = 4000: Average Return = 295.80 step = 4200: loss = 0.7492141723632812 step = 4400: loss = 0.7726025581359863 step = 4600: loss = 0.6017787456512451 step = 4800: loss = 1.0069717168807983 step = 5000: loss = 0.7220809459686279 step = 5000: Average Return = 311.60 step = 5200: loss = 0.7488924264907837 step = 5400: loss = 0.5694210529327393 step = 5600: loss = 0.6721386313438416 step = 5800: loss = 0.7949295043945312 step = 6000: loss = 0.651282787322998 step = 6000: Average Return = 199.70 step = 6200: loss = 0.6233834624290466 step = 6400: loss = 0.8107583522796631 step = 6600: loss = 0.58380126953125 step = 6800: loss = 0.7505298852920532 step = 7000: loss = 0.5908092260360718 step = 7000: Average Return = 299.10 step = 7200: loss = 0.5538588762283325 step = 7400: loss = 0.6156070232391357 step = 7600: loss = 0.47887083888053894 step = 7800: loss = 0.5000264644622803 step = 8000: loss = 0.45284855365753174 step = 8000: Average Return = 350.80 step = 8200: loss = 0.6110968589782715 step = 8400: loss = 0.3919612169265747 step = 8600: loss = 0.7722547054290771 step = 8800: loss = 0.4046146869659424 step = 9000: loss = 0.46277034282684326 step = 9000: Average Return = 271.50 step = 9200: loss = 0.3679955005645752 step = 9400: loss = 0.5566927194595337 step = 9600: loss = 0.41106539964675903 step = 9800: loss = 0.4605582356452942 step = 10000: loss = 0.5555872321128845 step = 10000: Average Return = 312.10 step = 10200: loss = 0.7797821164131165 step = 10400: loss = 0.44633305072784424 step = 10600: loss = 0.5042504072189331 step = 10800: loss = 0.3371679484844208 step = 11000: loss = 0.4677901268005371 step = 11000: Average Return = 299.80 step = 11200: loss = 0.5636323094367981 step = 11400: loss = 0.5001413822174072 step = 11600: loss = 0.47711390256881714 step = 11800: loss = 0.40261152386665344 step = 12000: loss = 0.43015092611312866 step = 12000: Average Return = 350.70 step = 12200: loss = 0.34091717004776 step = 12400: loss = 0.6249416470527649 step = 12600: loss = 0.5073033571243286 step = 12800: loss = 0.39890575408935547 step = 13000: loss = 0.32381200790405273 step = 13000: Average Return = 388.10 step = 13200: loss = 0.4492424726486206 step = 13400: loss = 0.313627153635025 step = 13600: loss = 0.33874017000198364 step = 13800: loss = 0.46816664934158325 step = 14000: loss = 0.3927123546600342 step = 14000: Average Return = 435.20 step = 14200: loss = 0.33503296971321106 step = 14400: loss = 0.3649250566959381 step = 14600: loss = 0.3163893520832062 step = 14800: loss = 0.5127081871032715 step = 15000: loss = 0.3506118059158325 step = 15000: Average Return = 408.60
시각화
플롯하기
에이전트의 성과를 확인하기 위해 수익 대 글로벌 스텝을 플롯할 수 있습니다. Cartpole-v1에서 환경은 극이 머무르는 각 타임스텝에 대해 +1의 보상을 제공하며 최대 스텝 수는 500이므로 가능한 최대 수익도 500입니다.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=550)
(-11.57500081062317, 550.0)
비디오
각 스텝에서 환경을 렌더링하여 에이전트의 성능을 시각화하면 도움이 됩니다. 이를 수행하기 전에 먼저 이 Colab에 비디오를 포함하는 함수를 작성하겠습니다.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
다음 코드는 몇 가지 에피소드에 대한 에이전트 정책을 시각화합니다.
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned.
C51은 CartPole-v1에서 DQN보다 약간 더 나은 경향이 있지만, 점차 더 복잡해지는 환경에서는 두 에이전트 간의 차이가 점점 더 중요해집니다. 예를 들어, 전체 Atari 2600 벤치마크에서 C51은 무작위 에이전트에 대해 정규화한 후 DQN에 비해 126%의 평균 점수가 개선됨을 보여줍니다. n-step 업데이트를 포함하여 추가로 개선할 수 있습니다.
C51 알고리즘에 대한 자세한 내용 강화 학습에 대한 분포적 관점(2017)을 참조하세요.