
Copyright 2021 Los autores de TF-Agents.
Empezar
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este tutorial es una guía paso a paso sobre cómo usar la biblioteca TF-Agents para problemas contextuales de bandidos donde las acciones (armas) tienen sus propias características, como una lista de películas representadas por características (género, año de lanzamiento, ...).
Requisito previo
Se supone que el lector está un poco familiarizado con la biblioteca bandido de la carretera TF-agentes, en particular, ha trabajado a través del tutorial para Bandidos en TF-Agentes antes de leer este tutorial.
Bandidos con armas múltiples con funciones de brazo
En el escenario "clásico" Contextual Multi-Armed Bandits, un agente recibe un vector de contexto (también conocido como observación) en cada paso de tiempo y tiene que elegir entre un conjunto finito de acciones numeradas (brazos) para maximizar su recompensa acumulativa.
Ahora considere el escenario en el que un agente recomienda a un usuario la próxima película para ver. Cada vez que se debe tomar una decisión, el agente recibe como contexto cierta información sobre el usuario (historial de reproducciones, preferencia de género, etc.), así como la lista de películas para elegir.
Podríamos tratar de formular este problema haciendo que la información del usuario como el contexto y los brazos estaríamos movie_1, movie_2, ..., movie_K , pero este método tiene varios inconvenientes:
- El número de acciones debería ser todas las películas del sistema y es engorroso agregar una nueva película.
- El agente tiene que aprender un modelo para cada película.
- No se tiene en cuenta la similitud entre películas.
En lugar de numerar las películas, podemos hacer algo más intuitivo: podemos representar películas con un conjunto de características que incluyen género, duración, reparto, clasificación, año, etc. Las ventajas de este enfoque son múltiples:
- Generalización en películas.
- El agente aprende solo una función de recompensa que modela la recompensa con funciones de usuario y película.
- Fácil de quitar o introducir nuevas películas en el sistema.
En esta nueva configuración, el número de acciones ni siquiera tiene que ser el mismo en cada paso de tiempo.
Bandidos por brazo en TF-Agents
La suite TF-Agents Bandit está desarrollada para que uno pueda usarla también para el caso de cada brazo. Hay entornos por brazo, y también la mayoría de las políticas y agentes pueden operar en modo por brazo.
Antes de sumergirnos en la codificación de un ejemplo, necesitamos las importaciones necesarias.
Instalación
pip install tf-agents
Importaciones
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
Parámetros: siéntase libre de jugar
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
Un entorno simple por brazo
El entorno estocástico estacionario, explicado en el otro tutorial , tiene una contraparte per-brazo.
Para inicializar el entorno por brazo, uno tiene que definir funciones que generen
- global y características por-brazo: Estas funciones no tienen parámetros de entrada y generar un único (global o per-brazo) vector de características cuando se le llama.
- recompensa: Esta función toma como parámetro la concatenación de un mundial y un vector de características por cada brazo, y genera una recompensa. Básicamente, esta es la función que el agente tendrá que "adivinar". Vale la pena señalar aquí que en el caso de cada brazo, la función de recompensa es idéntica para cada brazo. Esta es una diferencia fundamental con el caso clásico de los bandidos, donde el agente tiene que estimar las funciones de recompensa para cada brazo de forma independiente.
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
Ahora estamos equipados para inicializar nuestro entorno.
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
A continuación podemos comprobar qué produce este entorno.
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -9., -4., -3., 3., 5., -9., 6., -5., 4., -8., -6.,
-1., -7., -5., 7., 8., 2., 5., -8., 0., -4., 4.,
-1., -1., -4., 6., 8., 6., 9., -5., -1., -1., 2.,
5., -1., -8., 1., 0., 0., 5.],
[ 5., 7., 0., 3., -8., -7., -5., -2., -8., -7., -7.,
-8., 5., -3., 5., 4., -5., 2., -6., -10., -4., -2.,
2., -1., -1., 8., -7., 7., 2., -3., -10., -1., -4.,
-7., 3., 4., 8., -2., 9., 5.],
[ -6., -2., -1., -1., 6., -3., 4., 9., 2., -2., 3.,
1., 0., -7., 5., 5., -8., -4., 5., 7., -10., -4.,
5., 6., 8., -10., 7., -1., -8., -8., -6., -6., 4.,
-10., -8., 3., 8., -9., -5., 8.],
[ -1., 8., -8., -7., 9., 2., -6., 8., 4., -2., 1.,
8., -4., 3., 1., -6., -9., 3., -5., 7., -9., 6.,
6., -3., 1., 2., -1., 3., 7., 4., -8., 1., 1.,
3., -4., 1., -4., -5., -9., 4.],
[ -9., 8., 9., -8., 2., 9., -1., -9., -1., 9., -8.,
-4., 1., 1., 9., 6., -6., -10., -6., 2., 6., -4.,
-7., -2., -7., -8., -4., 5., -6., -1., 8., -3., -7.,
4., -9., -9., 6., -9., 6., -2.],
[ 0., -6., -5., -8., -10., 2., -4., 9., 9., -1., 5.,
-7., -1., -3., -10., -10., 3., -2., -7., -9., -4., -8.,
-4., -1., 7., -2., -4., -4., 9., 2., -2., -8., 6.,
5., -4., 7., 0., 6., -3., 2.],
[ 8., 5., 3., 5., 9., 4., -10., -5., -4., -4., -5.,
3., 5., -4., 9., -2., -7., -6., -2., -8., -7., -10.,
0., -2., 3., 1., -10., -8., 3., 9., -5., -6., 1.,
-7., -1., 3., -7., -2., 1., -1.],
[ 3., 9., 8., 6., -2., 9., 9., 7., 0., 5., -5.,
6., 9., 3., 2., 9., 4., -1., -3., 3., -1., -4.,
-9., -1., -3., 8., 0., 4., -1., 4., -3., 4., -5.,
-3., -6., -4., 7., -9., -7., -1.],
[ 5., -1., 9., -5., 8., 7., -7., -5., 0., -4., -5.,
6., -3., -1., 7., 3., -7., -9., 6., 4., 9., 6.,
-3., 3., -2., -6., -4., -7., -5., -6., -2., -1., -9.,
-4., -9., -2., -7., -6., -3., 6.],
[ -7., 1., -8., 1., -8., -9., 5., 1., -4., -2., -5.,
3., -1., -4., -4., 5., 0., -10., -4., -1., -5., 3.,
8., -5., -4., -10., -8., -6., -10., -1., -6., 1., 7.,
8., 6., -2., -4., -9., 7., -1.],
[ -2., 3., 8., -5., 0., 5., 8., -5., 6., -8., 5.,
8., -5., -5., -5., -10., 4., 8., -4., -7., 4., -6.,
-9., -8., -5., 4., -1., -2., -7., -10., -6., -8., -6.,
3., 1., 6., 9., 6., -8., -3.],
[ 9., -6., -2., -10., 2., -8., 8., -7., -5., 8., -10.,
4., -5., 9., 7., 9., -2., -9., -5., -2., 9., 0.,
-6., 2., 4., 6., -7., -4., -5., -7., -8., -8., 8.,
-7., -1., -5., 0., -7., 7., -6.],
[ -1., -3., 1., 8., 4., 7., -1., -8., -4., 6., 9.,
5., -10., 4., -4., 5., -2., 0., 3., 4., 3., -5.,
-2., 7., 4., -4., -9., 9., -6., -5., -8., 4., -10.,
-6., 3., 0., 6., -10., 4., 3.],
[ 8., 8., -5., 0., -7., 5., -6., -8., 2., -3., -5.,
5., 0., 6., -10., 3., -4., 1., -8., -9., 6., -5.,
5., -10., 1., 0., 3., 5., 2., -9., -6., 9., 7.,
9., -10., 4., -4., -10., -5., 1.],
[ 8., 3., -5., -2., -8., -6., 6., -7., 8., 1., -8.,
0., -2., 3., -6., 0., -10., 6., -8., -2., -5., 4.,
-1., -9., -7., 3., -1., -4., -1., -10., -3., -7., -3.,
4., -7., -6., -1., 9., -3., 2.],
[ 8., 7., 6., -5., -3., 0., 1., -2., 0., -3., 9.,
-8., 5., 1., 1., 1., -5., 4., -4., 0., -4., -3.,
7., -10., 3., 6., 4., 5., 2., -7., 0., -3., -5.,
2., -6., 4., 5., 8., -1., -3.],
[ 8., -9., -4., 8., -2., 9., 5., 5., -3., -4., 0.,
-5., 5., -2., -10., -4., -3., 5., 8., 6., -2., -2.,
-1., -8., -5., -9., 1., -1., 5., 6., 4., 9., -5.,
6., -2., 7., -7., -9., 4., 2.],
[ 2., 4., 6., 2., 6., -6., -2., 5., 8., 1., 3.,
8., 6., 9., -3., -1., 4., 7., -5., 7., 0., -10.,
9., -6., -4., -7., 1., -2., -2., 3., -1., 2., 5.,
8., 4., -9., 1., -4., 9., 6.],
[ -8., -5., 9., 3., 9., -10., -8., 3., -8., 0., -4.,
-8., -3., -4., -3., 0., 8., 3., -10., 7., 7., -3.,
8., 4., -3., 9., 3., 7., 2., 7., -8., -3., -4.,
-7., 3., -9., -10., 2., 5., 7.],
[ 5., -7., -8., 6., -8., 1., -8., 4., 2., 6., -6.,
-5., 4., -1., 3., -8., -3., 6., 5., -5., 1., -7.,
8., -10., 8., 1., 3., 7., 2., 2., -1., 1., -3.,
7., 1., 6., -6., 0., -9., 6.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 5., -6., 4., ..., -3., 3., 4.],
[-5., -6., -4., ..., 3., 4., -4.],
[ 1., -1., 5., ..., -1., -3., 1.],
...,
[ 3., 3., -5., ..., 4., 4., 0.],
[ 5., 1., -3., ..., -2., -2., -3.],
[-6., 4., 2., ..., 4., 5., -5.]],
[[-5., -3., 1., ..., -2., -1., 1.],
[ 1., 4., -1., ..., -1., -4., -4.],
[ 4., -6., 5., ..., 2., -2., 4.],
...,
[ 0., 4., -4., ..., -1., -3., 1.],
[ 3., 4., 5., ..., -5., -2., -2.],
[ 0., 4., -3., ..., 5., 1., 3.]],
[[-2., -6., -6., ..., -6., 1., -5.],
[ 4., 5., 5., ..., 1., 4., -4.],
[ 0., 0., -3., ..., -5., 0., -2.],
...,
[-3., -1., 4., ..., 5., -2., 5.],
[-3., -6., -2., ..., 3., 1., -5.],
[ 5., -3., -5., ..., -4., 4., -5.]],
...,
[[ 4., 3., 0., ..., 1., -6., 4.],
[-5., -3., 5., ..., 0., -1., -5.],
[ 0., 4., 3., ..., -2., 1., -3.],
...,
[-5., -2., -5., ..., -5., -5., -2.],
[-2., 5., 4., ..., -2., -2., 2.],
[-1., -4., 4., ..., -5., 2., -3.]],
[[-1., -4., 4., ..., -3., -5., 4.],
[-4., -6., -2., ..., -1., -6., 0.],
[ 0., 0., 5., ..., 4., -4., 0.],
...,
[ 2., 3., 5., ..., -6., -5., 5.],
[-5., -5., 2., ..., 0., 4., -2.],
[ 4., -5., -4., ..., -5., -5., -1.]],
[[ 3., 0., 2., ..., 2., 1., -3.],
[-5., -4., 3., ..., -6., 0., -2.],
[-4., -5., 3., ..., -6., -3., 0.],
...,
[-6., -6., 4., ..., -1., -5., -2.],
[-4., 3., -1., ..., 1., 4., 4.],
[ 5., 2., 2., ..., -3., 1., -4.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-130.17787 344.98013 371.39893 75.433975 396.35742
-176.46881 56.62174 -158.03278 491.3239 -156.10696
-1.0527252 -264.42285 22.356699 -395.89832 125.951546
142.99467 -322.3012 -24.547596 -159.47539 -44.123775 ], shape=(20,), dtype=float32)
Vemos que la especificación de observación es un diccionario con dos elementos:
- Uno con llave
'global': esta es la parte contexto mundial, la forma que coincide con el parámetroGLOBAL_DIM. - Uno con clave
'per_arm': Este es el contexto per-brazo, y su forma es[NUM_ACTIONS, PER_ARM_DIM]. Esta parte es el marcador de posición para las características del brazo para cada brazo en un paso de tiempo.
El agente de LinUCB
El agente LinUCB implementa el algoritmo Bandit con el mismo nombre, que estima el parámetro de la función de recompensa lineal mientras también mantiene un elipsoide de confianza alrededor de la estimación. El agente elige el brazo que tiene la recompensa esperada estimada más alta, asumiendo que el parámetro se encuentra dentro del elipsoide de confianza.
La creación de un agente requiere el conocimiento de la observación y la especificación de la acción. Al definir el agente, fijamos el parámetro booleano accepts_per_arm_features establece en True .
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
El flujo de datos de entrenamiento
Esta sección ofrece un adelanto de la mecánica de cómo las funciones por brazo pasan de la política al entrenamiento. No dude en pasar a la siguiente sección (Definición de la métrica de arrepentimiento) y volver aquí más tarde si está interesado.
Primero, echemos un vistazo a la especificación de datos en el agente. El training_data_spec atributo de los agentes especifica cuáles son los elementos y la estructura de los datos de entrenamiento debe tener.
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type')})
Si tenemos una mirada más cercana a la observation parte de la especificación, vemos que no contiene características por el brazo!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
¿Qué pasó con las funciones por brazo? Para responder a esta pregunta, primero observamos que cuando los trenes de agentes LinUCB, pero no es necesario por las características del brazo de todas las armas, que sólo necesita los del brazo elegido. Por lo tanto, tiene sentido para soltar el tensor de la forma [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM] , ya que es muy derrochador, especialmente si el número de acciones es grande.
¡Pero aún así, las características por brazo del brazo elegido deben estar en alguna parte! Con este fin, nos aseguramos de que las tiendas de política LinUCB las características del brazo elegido dentro del policy_info campo de los datos de entrenamiento:
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
Vemos en la forma que el chosen_arm_features campo tiene sólo el vector de características de un brazo, y eso va a ser el brazo elegido. Tenga en cuenta que la policy_info , y con ella los chosen_arm_features , es parte de los datos de entrenamiento, como hemos visto desde la inspección de la especificación de datos de entrenamiento, y por lo tanto está disponible en tiempo de entrenamiento.
Definición de la métrica del arrepentimiento
Antes de iniciar el ciclo de entrenamiento, definimos algunas funciones de utilidad que ayudan a calcular el arrepentimiento de nuestro agente. Estas funciones ayudan a determinar la recompensa óptima esperada dado el conjunto de acciones (dado por las características de sus brazos) y el parámetro lineal que se oculta al agente.
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
Ahora estamos listos para comenzar nuestro ciclo de entrenamiento de bandidos. El controlador a continuación se encarga de elegir acciones utilizando la política, almacenar las recompensas de las acciones elegidas en el búfer de reproducción, calcular la métrica de arrepentimiento predefinida y ejecutar el paso de entrenamiento del agente.
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmp/ipykernel_12052/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
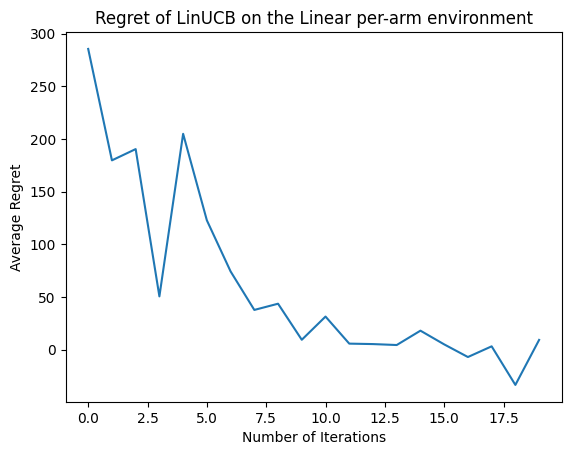
Ahora veamos el resultado. Si hicimos todo bien, el agente puede estimar bien la función de recompensa lineal y, por lo tanto, la política puede elegir acciones cuya recompensa esperada sea cercana a la óptima. Esto se indica mediante nuestra métrica de arrepentimiento definida anteriormente, que desciende y se acerca a cero.
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
¿Que sigue?
El ejemplo anterior se implementó en nuestra base de código, donde se puede elegir entre otros agentes, así, como el agente de épsilon-Greedy Neural .