
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Gradientes y diferenciación automática
La diferenciación automática es útil para implementar algoritmos de aprendizaje automático, como la retropropagación para entrenar redes neuronales.
En esta guía, explorará formas de calcular gradientes con TensorFlow, especialmente en ejecución entusiasta .
Configuración
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
Informática de gradientes
Para diferenciar automáticamente, TensorFlow necesita recordar qué operaciones suceden y en qué orden durante el paso hacia adelante . Luego, durante el paso hacia atrás , TensorFlow recorre esta lista de operaciones en orden inverso para calcular los gradientes.
Cintas de degradado
TensorFlow proporciona la API tf.GradientTape para la diferenciación automática; es decir, calcular el gradiente de un cálculo con respecto a algunas entradas, generalmente tf.Variable s. TensorFlow "graba" operaciones relevantes ejecutadas dentro del contexto de un tf.GradientTape en una "cinta". Luego, TensorFlow usa esa cinta para calcular los gradientes de un cálculo "grabado" mediante la diferenciación de modo inverso .
Aquí hay un ejemplo simple:
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
Una vez que haya registrado algunas operaciones, use GradientTape.gradient(target, sources) para calcular el gradiente de algún objetivo (a menudo una pérdida) en relación con alguna fuente (a menudo las variables del modelo):
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
dy_dx.numpy()
6.0
El ejemplo anterior usa escalares, pero tf.GradientTape funciona con la misma facilidad en cualquier tensor:
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
Para obtener el gradiente de loss con respecto a ambas variables, puede pasar ambas como fuentes al método de gradient . La cinta es flexible acerca de cómo se pasan las fuentes y aceptará cualquier combinación anidada de listas o diccionarios y devolverá el degradado estructurado de la misma manera (ver tf.nest ).
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
El gradiente con respecto a cada fuente tiene la forma de la fuente:
print(w.shape)
print(dl_dw.shape)
(3, 2) (3, 2)
Aquí está de nuevo el cálculo del gradiente, esta vez pasando un diccionario de variables:
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b']
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([-1.6920902, -3.2363236], dtype=float32)>
Gradientes con respecto a un modelo
Es común recopilar tf.Variables en un tf.Module o una de sus subclases ( layers.Layer , keras.Model ) para marcar y exportar .
En la mayoría de los casos, querrá calcular gradientes con respecto a las variables entrenables de un modelo. Dado que todas las subclases de tf.Module agregan sus variables en la propiedad Module.trainable_variables , puede calcular estos gradientes en unas pocas líneas de código:
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
loss = tf.reduce_mean(y**2)
# Calculate gradients with respect to every trainable variable
grad = tape.gradient(loss, layer.trainable_variables)
for var, g in zip(layer.trainable_variables, grad):
print(f'{var.name}, shape: {g.shape}')
dense/kernel:0, shape: (3, 2) dense/bias:0, shape: (2,)
Controlar lo que ve la cinta
El comportamiento predeterminado es registrar todas las operaciones después de acceder a una tf.Variable entrenable. Las razones de esto son:
- La cinta necesita saber qué operaciones registrar en la pasada hacia adelante para calcular los gradientes en la pasada hacia atrás.
- La cinta contiene referencias a salidas intermedias, por lo que no desea registrar operaciones innecesarias.
- El caso de uso más común consiste en calcular el gradiente de una pérdida con respecto a todas las variables entrenables de un modelo.
Por ejemplo, lo siguiente no puede calcular un gradiente porque tf.Tensor no está "observado" de forma predeterminada y tf.Variable no se puede entrenar:
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
# Not a variable
x3 = tf.constant(3.0, name='x3')
with tf.GradientTape() as tape:
y = (x0**2) + (x1**2) + (x2**2)
grad = tape.gradient(y, [x0, x1, x2, x3])
for g in grad:
print(g)
tf.Tensor(6.0, shape=(), dtype=float32) None None None
Puede enumerar las variables que la cinta está observando mediante el método GradientTape.watched_variables :
[var.name for var in tape.watched_variables()]
['x0:0']
tf.GradientTape proporciona ganchos que dan al usuario control sobre lo que se ve o no.
Para registrar gradientes con respecto a un tf.Tensor , debe llamar a GradientTape.watch(x) :
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
print(dy_dx.numpy())
6.0
Por el contrario, para deshabilitar el comportamiento predeterminado de ver todas las tf.Variables , establezca watch_accessed_variables=False al crear la cinta de degradado. Este cálculo utiliza dos variables, pero solo conecta el gradiente de una de las variables:
x0 = tf.Variable(0.0)
x1 = tf.Variable(10.0)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.softplus(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
Dado que GradientTape.watch no se invocó en x0 , no se calcula ningún gradiente con respecto a él:
# dys/dx1 = exp(x1) / (1 + exp(x1)) = sigmoid(x1)
grad = tape.gradient(ys, {'x0': x0, 'x1': x1})
print('dy/dx0:', grad['x0'])
print('dy/dx1:', grad['x1'].numpy())
dy/dx0: None dy/dx1: 0.9999546
resultados intermedios
También puede solicitar gradientes de la salida con respecto a los valores intermedios calculados dentro del contexto tf.GradientTape .
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x * x
z = y * y
# Use the tape to compute the gradient of z with respect to the
# intermediate value y.
# dz_dy = 2 * y and y = x ** 2 = 9
print(tape.gradient(z, y).numpy())
18.0
De forma predeterminada, los recursos que contiene GradientTape se liberan tan pronto como se llama al método GradientTape.gradient . Para calcular múltiples gradientes sobre el mismo cálculo, cree una cinta de gradiente con persistent=True . Esto permite múltiples llamadas al método de gradient a medida que se liberan recursos cuando el objeto de cinta se recolecta como basura. Por ejemplo:
x = tf.constant([1, 3.0])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
y = x * x
z = y * y
print(tape.gradient(z, x).numpy()) # [4.0, 108.0] (4 * x**3 at x = [1.0, 3.0])
print(tape.gradient(y, x).numpy()) # [2.0, 6.0] (2 * x at x = [1.0, 3.0])
[ 4. 108.] [2. 6.]
del tape # Drop the reference to the tape
Notas sobre el rendimiento
Hay una pequeña sobrecarga asociada con la realización de operaciones dentro de un contexto de cinta de degradado. Para la ejecución más ansiosa, esto no será un costo notable, pero aún debe usar el contexto de la cinta alrededor de las áreas solo donde se requiere.
Las cintas de gradiente usan memoria para almacenar resultados intermedios, incluidas entradas y salidas, para usar durante el pase hacia atrás.
Para mayor eficiencia, algunas operaciones (como
ReLU) no necesitan mantener sus resultados intermedios y se podan durante el pase hacia adelante. Sin embargo, si usapersistent=Trueen su cinta, no se descarta nada y su uso máximo de memoria será mayor.
Gradientes de objetivos no escalares
Un gradiente es fundamentalmente una operación en un escalar.
x = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient(y0, x).numpy())
print(tape.gradient(y1, x).numpy())
4.0 -0.25
Por lo tanto, si solicita el gradiente de múltiples objetivos, el resultado para cada fuente es:
- El gradiente de la suma de los objetivos, o equivalentemente
- La suma de los gradientes de cada objetivo.
x = tf.Variable(2.0)
with tf.GradientTape() as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient({'y0': y0, 'y1': y1}, x).numpy())
3.75
De manera similar, si los objetivos no son escalares, se calcula el gradiente de la suma:
x = tf.Variable(2.)
with tf.GradientTape() as tape:
y = x * [3., 4.]
print(tape.gradient(y, x).numpy())
7.0
Esto simplifica tomar el gradiente de la suma de un conjunto de pérdidas, o el gradiente de la suma de un cálculo de pérdidas por elementos.
Si necesita un gradiente separado para cada elemento, consulte Jacobianos .
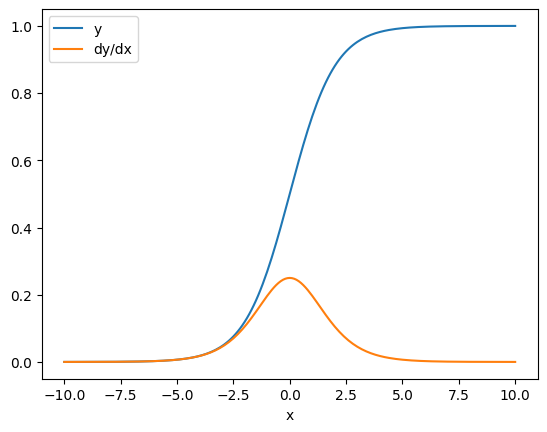
En algunos casos, puede omitir el jacobiano. Para un cálculo por elementos, el gradiente de la suma da la derivada de cada elemento con respecto a su elemento de entrada, ya que cada elemento es independiente:
x = tf.linspace(-10.0, 10.0, 200+1)
with tf.GradientTape() as tape:
tape.watch(x)
y = tf.nn.sigmoid(x)
dy_dx = tape.gradient(y, x)
plt.plot(x, y, label='y')
plt.plot(x, dy_dx, label='dy/dx')
plt.legend()
_ = plt.xlabel('x')
Flujo de control
Debido a que una cinta de gradiente registra las operaciones a medida que se ejecutan, el flujo de control de Python se maneja naturalmente (por ejemplo, declaraciones if y while ).
Aquí se usa una variable diferente en cada rama de un if . El gradiente solo se conecta a la variable que se utilizó:
x = tf.constant(1.0)
v0 = tf.Variable(2.0)
v1 = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
if x > 0.0:
result = v0
else:
result = v1**2
dv0, dv1 = tape.gradient(result, [v0, v1])
print(dv0)
print(dv1)
tf.Tensor(1.0, shape=(), dtype=float32) None
Solo recuerde que las declaraciones de control en sí mismas no son diferenciables, por lo que son invisibles para los optimizadores basados en gradientes.
Dependiendo del valor de x en el ejemplo anterior, la cinta registra result = v0 o result = v1**2 . El gradiente con respecto a x siempre es None .
dx = tape.gradient(result, x)
print(dx)
None
Obtener un degradado de None
Cuando un objetivo no está conectado a una fuente, obtendrá un gradiente de None .
x = tf.Variable(2.)
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y * y
print(tape.gradient(z, x))
None
Aquí, obviamente, z no está conectado a x , pero hay varias formas menos obvias en las que se puede desconectar un gradiente.
1. Reemplazó una variable con un tensor
En la sección sobre "controlar lo que ve la cinta" , vio que la cinta verá automáticamente una tf.Variable pero no una tf.Tensor .
Un error común es reemplazar inadvertidamente un tf.Variable con un tf.Tensor , en lugar de usar Variable.assign para actualizar el tf.Variable . Aquí hay un ejemplo:
x = tf.Variable(2.0)
for epoch in range(2):
with tf.GradientTape() as tape:
y = x+1
print(type(x).__name__, ":", tape.gradient(y, x))
x = x + 1 # This should be `x.assign_add(1)`
ResourceVariable : tf.Tensor(1.0, shape=(), dtype=float32) EagerTensor : None
2. Hizo cálculos fuera de TensorFlow
La cinta no puede registrar la ruta de degradado si el cálculo sale de TensorFlow. Por ejemplo:
x = tf.Variable([[1.0, 2.0],
[3.0, 4.0]], dtype=tf.float32)
with tf.GradientTape() as tape:
x2 = x**2
# This step is calculated with NumPy
y = np.mean(x2, axis=0)
# Like most ops, reduce_mean will cast the NumPy array to a constant tensor
# using `tf.convert_to_tensor`.
y = tf.reduce_mean(y, axis=0)
print(tape.gradient(y, x))
None
3. Tomó gradientes a través de un número entero o cadena
Los enteros y las cadenas no son diferenciables. Si una ruta de cálculo utiliza estos tipos de datos, no habrá gradiente.
Nadie espera que las cadenas sean diferenciables, pero es fácil crear accidentalmente una constante o variable int si no especifica el dtype .
x = tf.constant(10)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
print(g.gradient(y, x))
WARNING:tensorflow:The dtype of the watched tensor must be floating (e.g. tf.float32), got tf.int32 WARNING:tensorflow:The dtype of the target tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 WARNING:tensorflow:The dtype of the source tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 None
TensorFlow no convierte automáticamente entre tipos, por lo que, en la práctica, a menudo obtendrá un error de tipo en lugar de un degradado faltante.
4. Tomó gradientes a través de un objeto con estado
El estado detiene los gradientes. Cuando lee de un objeto con estado, la cinta solo puede observar el estado actual, no el historial que condujo a él.
Un tf.Tensor es inmutable. No puedes cambiar un tensor una vez creado. Tiene un valor , pero no un estado . Todas las operaciones discutidas hasta ahora también son sin estado: la salida de un tf.matmul solo depende de sus entradas.
Una tf.Variable tiene un estado interno: su valor. Cuando usa la variable, se lee el estado. Es normal calcular un gradiente con respecto a una variable, pero el estado de la variable impide que los cálculos de gradiente vayan más atrás. Por ejemplo:
x0 = tf.Variable(3.0)
x1 = tf.Variable(0.0)
with tf.GradientTape() as tape:
# Update x1 = x1 + x0.
x1.assign_add(x0)
# The tape starts recording from x1.
y = x1**2 # y = (x1 + x0)**2
# This doesn't work.
print(tape.gradient(y, x0)) #dy/dx0 = 2*(x1 + x0)
None
De manera similar, los iteradores tf.data.Dataset y tf.queue s tienen estado y detendrán todos los gradientes en los tensores que pasan a través de ellos.
No se registró gradiente
Algunas tf.Operation s se registran como no diferenciables y devolverán None . Otros no tienen gradiente registrado .
La página tf.raw_ops muestra qué operaciones de bajo nivel tienen gradientes registrados.
Si intenta tomar un gradiente a través de una operación de flotación que no tiene ningún gradiente registrado, la cinta arrojará un error en lugar de devolver None de forma silenciosa. De esta forma sabrás que algo salió mal.
Por ejemplo, la función tf.image.adjust_contrast envuelve raw_ops.AdjustContrastv2 , que podría tener un degradado pero el degradado no está implementado:
image = tf.Variable([[[0.5, 0.0, 0.0]]])
delta = tf.Variable(0.1)
with tf.GradientTape() as tape:
new_image = tf.image.adjust_contrast(image, delta)
try:
print(tape.gradient(new_image, [image, delta]))
assert False # This should not happen.
except LookupError as e:
print(f'{type(e).__name__}: {e}')
LookupError: gradient registry has no entry for: AdjustContrastv2
Si necesita diferenciar a través de esta operación, deberá implementar el gradiente y registrarlo (usando tf.RegisterGradient ) o volver a implementar la función usando otras operaciones.
Ceros en lugar de Ninguno
En algunos casos, sería conveniente obtener 0 en lugar de None para gradientes no conectados. Puede decidir qué devolver cuando tiene gradientes desconectados usando el argumento unconnected_gradients :
x = tf.Variable([2., 2.])
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y**2
print(tape.gradient(z, x, unconnected_gradients=tf.UnconnectedGradients.ZERO))
tf.Tensor([0. 0.], shape=(2,), dtype=float32)