| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Visão geral
GPUs e TPUs podem reduzir radicalmente o tempo necessário para executar uma única etapa de treinamento. Alcançar o desempenho máximo requer um pipeline de entrada eficiente que forneça dados para a próxima etapa antes que a etapa atual seja concluída. A API tf.data ajuda a criar pipelines de entrada flexíveis e eficientes. Este documento demonstra como usar a API tf.data para criar pipelines de entrada do TensorFlow de alto desempenho.
Antes de continuar, consulte o guia Build TensorFlow input pipelines para saber como usar a API tf.data .
Recursos
- Crie pipelines de entrada do TensorFlow
- API
tf.data.Dataset - Analise o desempenho do
tf.datacom o TF Profiler
Configurar
import tensorflow as tf
import time
Ao longo deste guia, você irá iterar em um conjunto de dados e medir o desempenho. Fazer benchmarks de desempenho reproduzíveis pode ser difícil. Diferentes fatores que afetam a reprodutibilidade incluem:
- A carga atual da CPU
- O tráfego de rede
- Mecanismos complexos, como cache
Para obter um benchmark reproduzível, você construirá um exemplo artificial.
O conjunto de dados
Comece definindo uma classe herdada de tf.data.Dataset chamada ArtificialDataset . Este conjunto de dados:
- Gera amostras
num_samples(o padrão é 3) - Dorme algum tempo antes do primeiro item para simular a abertura de um arquivo
- Dorme por algum tempo antes de produzir cada item para simular a leitura de dados de um arquivo
class ArtificialDataset(tf.data.Dataset):
def _generator(num_samples):
# Opening the file
time.sleep(0.03)
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
time.sleep(0.015)
yield (sample_idx,)
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_signature = tf.TensorSpec(shape = (1,), dtype = tf.int64),
args=(num_samples,)
)
Esse conjunto de dados é semelhante ao tf.data.Dataset.range , adicionando um atraso fixo no início e entre cada amostra.
O circuito de treinamento
Em seguida, escreva um loop de treinamento fictício que mede quanto tempo leva para iterar em um conjunto de dados. O tempo de treinamento é simulado.
def benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
for sample in dataset:
# Performing a training step
time.sleep(0.01)
print("Execution time:", time.perf_counter() - start_time)
Otimizar o desempenho
Para mostrar como o desempenho pode ser otimizado, você melhorará o desempenho do ArtificialDataset .
A abordagem ingênua
Comece com um pipeline ingênuo sem truques, iterando sobre o conjunto de dados como está.
benchmark(ArtificialDataset())
Execution time: 0.26497629899995445
Sob o capô, é assim que seu tempo de execução foi gasto:

O gráfico mostra que a execução de uma etapa de treinamento envolve:
- Abrindo um arquivo se ele ainda não foi aberto
- Buscando uma entrada de dados do arquivo
- Usando os dados para treinamento
No entanto, em uma implementação síncrona ingênua como aqui, enquanto seu pipeline está buscando os dados, seu modelo fica ocioso. Por outro lado, enquanto seu modelo está treinando, o pipeline de entrada fica ocioso. O tempo da etapa de treinamento é, portanto, a soma dos tempos de abertura, leitura e treinamento.
As próximas seções se baseiam nesse pipeline de entrada, ilustrando as práticas recomendadas para projetar pipelines de entrada TensorFlow de alto desempenho.
Pré-busca
A pré-busca sobrepõe o pré-processamento e a execução do modelo de uma etapa de treinamento. Enquanto o modelo está executando a etapa de treinamento s , o pipeline de entrada está lendo os dados da etapa s+1 . Isso reduz o tempo da etapa ao máximo (em oposição à soma) do treinamento e o tempo necessário para extrair os dados.
A API tf.data fornece a transformação tf.data.Dataset.prefetch . Ele pode ser usado para desacoplar o momento em que os dados são produzidos do momento em que os dados são consumidos. Em particular, a transformação usa um thread em segundo plano e um buffer interno para pré-buscar elementos do conjunto de dados de entrada antes do momento em que são solicitados. O número de elementos para pré-busca deve ser igual (ou possivelmente maior que) ao número de lotes consumidos por uma única etapa de treinamento. Você pode ajustar manualmente esse valor ou defini-lo como tf.data.AUTOTUNE , que solicitará que o tempo de execução tf.data ajuste o valor dinamicamente em tempo de execução.
Observe que a transformação de pré-busca oferece benefícios sempre que houver uma oportunidade de sobrepor o trabalho de um "produtor" ao trabalho de um "consumidor".
benchmark(
ArtificialDataset()
.prefetch(tf.data.AUTOTUNE)
)
Execution time: 0.21731788600027357

Agora, como mostra o gráfico de tempo de execução de dados, enquanto a etapa de treinamento está sendo executada para a amostra 0, o pipeline de entrada está lendo os dados para a amostra 1 e assim por diante.
Paralelizando a extração de dados
Em uma configuração do mundo real, os dados de entrada podem ser armazenados remotamente (por exemplo, no Google Cloud Storage ou HDFS). Um pipeline de conjunto de dados que funciona bem ao ler dados localmente pode se tornar afunilado na E/S ao ler dados remotamente devido às seguintes diferenças entre armazenamento local e remoto:
- Tempo até o primeiro byte : Ler o primeiro byte de um arquivo de um armazenamento remoto pode levar muito mais tempo do que do armazenamento local.
- Taxa de transferência de leitura : embora o armazenamento remoto geralmente ofereça grande largura de banda agregada, a leitura de um único arquivo pode utilizar apenas uma pequena fração dessa largura de banda.
Além disso, uma vez que os bytes brutos são carregados na memória, também pode ser necessário desserializar e/ou descriptografar os dados (por exemplo, protobuf ), o que requer computação adicional. Essa sobrecarga está presente independentemente de os dados serem armazenados local ou remotamente, mas pode ser pior no caso remoto se os dados não forem pré-buscados de forma eficaz.
Para mitigar o impacto das várias sobrecargas de extração de dados, a transformação tf.data.Dataset.interleave pode ser usada para paralelizar a etapa de carregamento de dados, intercalando o conteúdo de outros conjuntos de dados (como leitores de arquivos de dados). O número de conjuntos de dados a serem sobrepostos pode ser especificado pelo argumento cycle_length , enquanto o nível de paralelismo pode ser especificado pelo argumento num_parallel_calls . Semelhante à transformação de prefetch -busca, a transformação de interleave oferece suporte a tf.data.AUTOTUNE , que delegará a decisão sobre qual nível de paralelismo usar para o tempo de execução tf.data .
Intercalação sequencial
Os argumentos padrão da transformação tf.data.Dataset.interleave a fazem intercalar amostras únicas de dois conjuntos de dados sequencialmente.
benchmark(
tf.data.Dataset.range(2)
.interleave(lambda _: ArtificialDataset())
)
Execution time: 0.4987426460002098

Este gráfico de tempo de execução de dados permite exibir o comportamento da transformação de interleave , buscando amostras alternativamente dos dois conjuntos de dados disponíveis. No entanto, nenhuma melhoria de desempenho está envolvida aqui.
Intercalação paralela
Agora, use o argumento num_parallel_calls da transformação de interleave . Isso carrega vários conjuntos de dados em paralelo, reduzindo o tempo de espera para que os arquivos sejam abertos.
benchmark(
tf.data.Dataset.range(2)
.interleave(
lambda _: ArtificialDataset(),
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.283668874000341

Desta vez, como mostra o gráfico de tempo de execução dos dados, a leitura dos dois conjuntos de dados é paralelizada, reduzindo o tempo global de processamento dos dados.
Paralelizando a transformação de dados
Ao preparar os dados, os elementos de entrada podem precisar ser pré-processados. Para isso, a API tf.data oferece a transformação tf.data.Dataset.map , que aplica uma função definida pelo usuário a cada elemento do conjunto de dados de entrada. Como os elementos de entrada são independentes uns dos outros, o pré-processamento pode ser paralelizado em vários núcleos de CPU. Para tornar isso possível, de forma semelhante às transformações de prefetch -busca e interleave , a transformação de map fornece o argumento num_parallel_calls para especificar o nível de paralelismo.
Escolher o melhor valor para o argumento num_parallel_calls depende de seu hardware, características de seus dados de treinamento (como tamanho e forma), o custo de sua função de mapa e quais outros processamentos estão acontecendo na CPU ao mesmo tempo. Uma heurística simples é usar o número de núcleos de CPU disponíveis. No entanto, quanto à transformação de prefetch -busca e interleave , a transformação de map suporta tf.data.AUTOTUNE que delegará a decisão sobre qual nível de paralelismo usar para o tempo de execução tf.data .
def mapped_function(s):
# Do some hard pre-processing
tf.py_function(lambda: time.sleep(0.03), [], ())
return s
Mapeamento sequencial
Comece usando a transformação de map sem paralelismo como exemplo de linha de base.
benchmark(
ArtificialDataset()
.map(mapped_function)
)
Execution time: 0.4505277170001136

Quanto à abordagem ingênua , aqui, como mostra o enredo, os tempos gastos para abertura, leitura, pré-processamento (mapeamento) e etapas de treinamento somam-se para uma única iteração.
Mapeamento paralelo
Agora, use a mesma função de pré-processamento, mas aplique-a em paralelo em várias amostras.
benchmark(
ArtificialDataset()
.map(
mapped_function,
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.2839677860001757

Como o gráfico de dados demonstra, as etapas de pré-processamento se sobrepõem, reduzindo o tempo total para uma única iteração.
Cache
A transformação tf.data.Dataset.cache pode armazenar em cache um conjunto de dados, na memória ou no armazenamento local. Isso evitará que algumas operações (como abertura de arquivos e leitura de dados) sejam executadas durante cada época.
benchmark(
ArtificialDataset()
.map( # Apply time consuming operations before cache
mapped_function
).cache(
),
5
)
Execution time: 0.3848854380003104

Aqui, o gráfico de tempo de execução de dados mostra que quando você armazena em cache um conjunto de dados, as transformações anteriores ao cache (como a abertura do arquivo e a leitura de dados) são executadas apenas durante a primeira época. As próximas épocas reutilizarão os dados armazenados em cache pela transformação de cache .
Se a função definida pelo usuário passada para a transformação de map for cara, aplique a transformação de cache após a transformação de map , desde que o conjunto de dados resultante ainda possa caber na memória ou no armazenamento local. Se a função definida pelo usuário aumentar o espaço necessário para armazenar o conjunto de dados além da capacidade do cache, aplique-o após a transformação do cache ou considere pré-processar seus dados antes do trabalho de treinamento para reduzir o uso de recursos.
Mapeamento de vetorização
Invocar uma função definida pelo usuário passada para a transformação de map tem sobrecarga relacionada ao agendamento e execução da função definida pelo usuário. Vetorize a função definida pelo usuário (ou seja, faça com que ela opere em um lote de entradas de uma só vez) e aplique a transformação em batch antes da transformação do map .
Para ilustrar essa boa prática, seu conjunto de dados artificial não é adequado. O atraso de agendamento é de cerca de 10 microssegundos (10e-6 segundos), muito menos do que as dezenas de milissegundos usadas no ArtificialDataset e, portanto, seu impacto é difícil de ver.
Para este exemplo, use a função base tf.data.Dataset.range e simplifique o loop de treinamento para sua forma mais simples.
fast_dataset = tf.data.Dataset.range(10000)
def fast_benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for _ in tf.data.Dataset.range(num_epochs):
for _ in dataset:
pass
tf.print("Execution time:", time.perf_counter() - start_time)
def increment(x):
return x+1
Mapeamento escalar
fast_benchmark(
fast_dataset
# Apply function one item at a time
.map(increment)
# Batch
.batch(256)
)
Execution time: 0.2712608739998359

O gráfico acima ilustra o que está acontecendo (com menos amostras) usando o método de mapeamento escalar. Mostra que a função mapeada é aplicada para cada amostra. Embora essa função seja muito rápida, ela possui algumas sobrecargas que afetam o desempenho do tempo.
Mapeamento vetorizado
fast_benchmark(
fast_dataset
.batch(256)
# Apply function on a batch of items
# The tf.Tensor.__add__ method already handle batches
.map(increment)
)
Execution time: 0.02737950600021577

Desta vez, a função mapeada é chamada uma vez e se aplica a um lote de amostra. Como mostra o gráfico do tempo de execução dos dados, embora a função possa levar mais tempo para ser executada, a sobrecarga aparece apenas uma vez, melhorando o desempenho geral do tempo.
Reduzindo a pegada de memória
Várias transformações, incluindo interleave , prefetch e shuffle , mantêm um buffer interno de elementos. Se a função definida pelo usuário passada para a transformação de map alterar o tamanho dos elementos, a ordenação da transformação de mapa e as transformações que os elementos de buffer afetarão o uso da memória. Em geral, escolha a ordem que resulta em menor consumo de memória, a menos que uma ordem diferente seja desejável para o desempenho.
Cache de cálculos parciais
Recomenda-se armazenar em cache o conjunto de dados após a transformação do map , exceto se essa transformação tornar os dados muito grandes para caber na memória. Uma compensação pode ser alcançada se sua função mapeada puder ser dividida em duas partes: uma que consome tempo e uma que consome memória. Nesse caso, você pode encadear suas transformações como abaixo:
dataset.map(time_consuming_mapping).cache().map(memory_consuming_mapping)
Dessa forma, a parte demorada é executada apenas durante a primeira época e você evita usar muito espaço de cache.
Resumo das melhores práticas
Aqui está um resumo das práticas recomendadas para projetar pipelines de entrada do TensorFlow de alto desempenho:
- Use a transformação de
prefetch-busca para sobrepor o trabalho de um produtor e consumidor - Paralelize a transformação de leitura de dados usando a transformação de
interleave - Paralelize a transformação do
mapdefinindo o argumentonum_parallel_calls - Use a
cachede cache para armazenar dados em cache na memória durante a primeira época - Vetorize funções definidas pelo usuário passadas para a transformação do
map - Reduza o uso de memória ao aplicar as transformações
interleave,prefetcheshuffle
Reproduzindo as figuras
Para aprofundar o entendimento da API tf.data.Dataset , você pode brincar com seus próprios pipelines. Abaixo está o código usado para plotar as imagens deste guia. Pode ser um bom ponto de partida, mostrando algumas soluções alternativas para dificuldades comuns, como:
- Reprodutibilidade do tempo de execução
- Execução ansiosa de funções mapeadas
- transformação de
interleavechamável
import itertools
from collections import defaultdict
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
O conjunto de dados
Semelhante ao ArtificialDataset você pode construir um dataset retornando o tempo gasto em cada etapa.
class TimeMeasuredDataset(tf.data.Dataset):
# OUTPUT: (steps, timings, counters)
OUTPUT_TYPES = (tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32)
OUTPUT_SHAPES = ((2, 1), (2, 2), (2, 3))
_INSTANCES_COUNTER = itertools.count() # Number of datasets generated
_EPOCHS_COUNTER = defaultdict(itertools.count) # Number of epochs done for each dataset
def _generator(instance_idx, num_samples):
epoch_idx = next(TimeMeasuredDataset._EPOCHS_COUNTER[instance_idx])
# Opening the file
open_enter = time.perf_counter()
time.sleep(0.03)
open_elapsed = time.perf_counter() - open_enter
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
read_enter = time.perf_counter()
time.sleep(0.015)
read_elapsed = time.perf_counter() - read_enter
yield (
[("Open",), ("Read",)],
[(open_enter, open_elapsed), (read_enter, read_elapsed)],
[(instance_idx, epoch_idx, -1), (instance_idx, epoch_idx, sample_idx)]
)
open_enter, open_elapsed = -1., -1. # Negative values will be filtered
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_types=cls.OUTPUT_TYPES,
output_shapes=cls.OUTPUT_SHAPES,
args=(next(cls._INSTANCES_COUNTER), num_samples)
)
Este conjunto de dados fornece amostras de forma [[2, 1], [2, 2], [2, 3]] e do tipo [tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32] . Cada amostra é:
(
[("Open"), ("Read")],
[(t0, d), (t0, d)],
[(i, e, -1), (i, e, s)]
)
Onde:
-
OpeneReadsão identificadores de etapas -
t0é o timestamp quando a etapa correspondente começou -
dé o tempo gasto na etapa correspondente -
ié o índice de instância -
eé o índice de época (número de vezes que o conjunto de dados foi iterado) -
sé o índice de amostra
O ciclo de iteração
Torne o loop de iteração um pouco mais complicado para agregar todos os tempos. Isso só funcionará com conjuntos de dados gerando amostras conforme detalhado acima.
def timelined_benchmark(dataset, num_epochs=2):
# Initialize accumulators
steps_acc = tf.zeros([0, 1], dtype=tf.dtypes.string)
times_acc = tf.zeros([0, 2], dtype=tf.dtypes.float32)
values_acc = tf.zeros([0, 3], dtype=tf.dtypes.int32)
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
epoch_enter = time.perf_counter()
for (steps, times, values) in dataset:
# Record dataset preparation informations
steps_acc = tf.concat((steps_acc, steps), axis=0)
times_acc = tf.concat((times_acc, times), axis=0)
values_acc = tf.concat((values_acc, values), axis=0)
# Simulate training time
train_enter = time.perf_counter()
time.sleep(0.01)
train_elapsed = time.perf_counter() - train_enter
# Record training informations
steps_acc = tf.concat((steps_acc, [["Train"]]), axis=0)
times_acc = tf.concat((times_acc, [(train_enter, train_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [values[-1]]), axis=0)
epoch_elapsed = time.perf_counter() - epoch_enter
# Record epoch informations
steps_acc = tf.concat((steps_acc, [["Epoch"]]), axis=0)
times_acc = tf.concat((times_acc, [(epoch_enter, epoch_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [[-1, epoch_num, -1]]), axis=0)
time.sleep(0.001)
tf.print("Execution time:", time.perf_counter() - start_time)
return {"steps": steps_acc, "times": times_acc, "values": values_acc}
O método de plotagem
Por fim, defina uma função capaz de traçar uma linha do tempo com os valores retornados pela função timelined_benchmark .
def draw_timeline(timeline, title, width=0.5, annotate=False, save=False):
# Remove invalid entries (negative times, or empty steps) from the timelines
invalid_mask = np.logical_and(timeline['times'] > 0, timeline['steps'] != b'')[:,0]
steps = timeline['steps'][invalid_mask].numpy()
times = timeline['times'][invalid_mask].numpy()
values = timeline['values'][invalid_mask].numpy()
# Get a set of different steps, ordered by the first time they are encountered
step_ids, indices = np.stack(np.unique(steps, return_index=True))
step_ids = step_ids[np.argsort(indices)]
# Shift the starting time to 0 and compute the maximal time value
min_time = times[:,0].min()
times[:,0] = (times[:,0] - min_time)
end = max(width, (times[:,0]+times[:,1]).max() + 0.01)
cmap = mpl.cm.get_cmap("plasma")
plt.close()
fig, axs = plt.subplots(len(step_ids), sharex=True, gridspec_kw={'hspace': 0})
fig.suptitle(title)
fig.set_size_inches(17.0, len(step_ids))
plt.xlim(-0.01, end)
for i, step in enumerate(step_ids):
step_name = step.decode()
ax = axs[i]
ax.set_ylabel(step_name)
ax.set_ylim(0, 1)
ax.set_yticks([])
ax.set_xlabel("time (s)")
ax.set_xticklabels([])
ax.grid(which="both", axis="x", color="k", linestyle=":")
# Get timings and annotation for the given step
entries_mask = np.squeeze(steps==step)
serie = np.unique(times[entries_mask], axis=0)
annotations = values[entries_mask]
ax.broken_barh(serie, (0, 1), color=cmap(i / len(step_ids)), linewidth=1, alpha=0.66)
if annotate:
for j, (start, width) in enumerate(serie):
annotation = "\n".join([f"{l}: {v}" for l,v in zip(("i", "e", "s"), annotations[j])])
ax.text(start + 0.001 + (0.001 * (j % 2)), 0.55 - (0.1 * (j % 2)), annotation,
horizontalalignment='left', verticalalignment='center')
if save:
plt.savefig(title.lower().translate(str.maketrans(" ", "_")) + ".svg")
Use wrappers para função mapeada
Para executar a função mapeada em um contexto ansioso, você precisa envolvê-la em uma chamada tf.py_function .
def map_decorator(func):
def wrapper(steps, times, values):
# Use a tf.py_function to prevent auto-graph from compiling the method
return tf.py_function(
func,
inp=(steps, times, values),
Tout=(steps.dtype, times.dtype, values.dtype)
)
return wrapper
Comparação de pipelines
_batch_map_num_items = 50
def dataset_generator_fun(*args):
return TimeMeasuredDataset(num_samples=_batch_map_num_items)
Ingênuo
@map_decorator
def naive_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001) # Time consuming step
time.sleep(0.0001) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, [["Map"]]), axis=0),
tf.concat((times, [[map_enter, map_elapsed]]), axis=0),
tf.concat((values, [values[-1]]), axis=0)
)
naive_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.flat_map(dataset_generator_fun)
.map(naive_map)
.batch(_batch_map_num_items, drop_remainder=True)
.unbatch(),
5
)
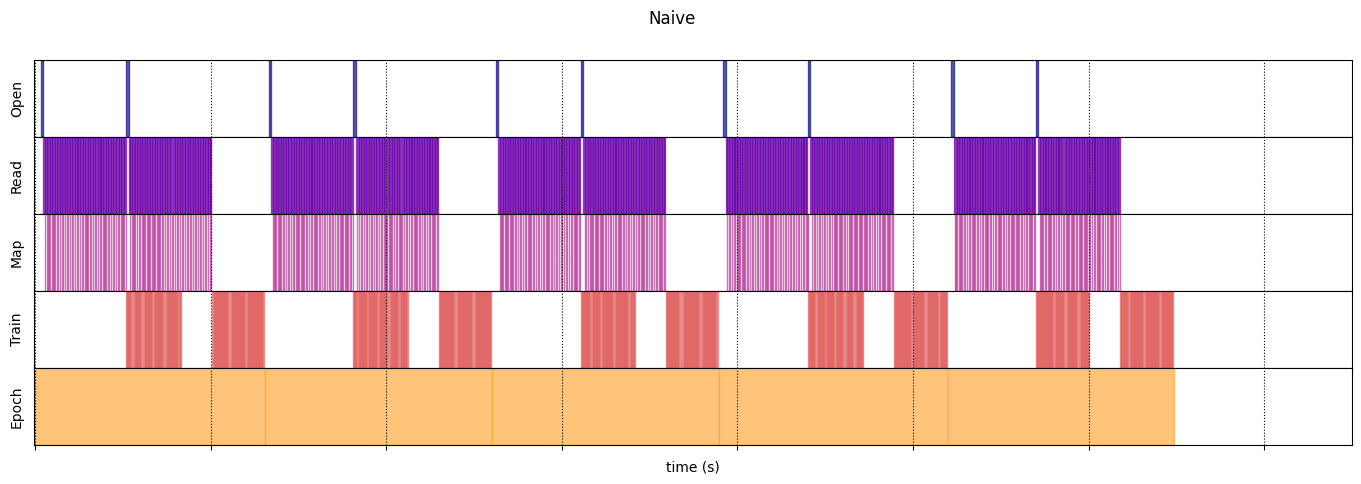
WARNING:tensorflow:From /tmp/ipykernel_23983/64197174.py:36: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_types is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead WARNING:tensorflow:From /tmp/ipykernel_23983/64197174.py:36: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_shapes is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead Execution time: 13.13538893499981
Otimizado
@map_decorator
def time_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001 * values.shape[0]) # Time consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, tf.tile([[["1st map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
@map_decorator
def memory_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.0001 * values.shape[0]) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
# Use tf.tile to handle batch dimension
return (
tf.concat((steps, tf.tile([[["2nd map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
optimized_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.interleave( # Parallelize data reading
dataset_generator_fun,
num_parallel_calls=tf.data.AUTOTUNE
)
.batch( # Vectorize your mapped function
_batch_map_num_items,
drop_remainder=True)
.map( # Parallelize map transformation
time_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.cache() # Cache data
.map( # Reduce memory usage
memory_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.prefetch( # Overlap producer and consumer works
tf.data.AUTOTUNE
)
.unbatch(),
5
)
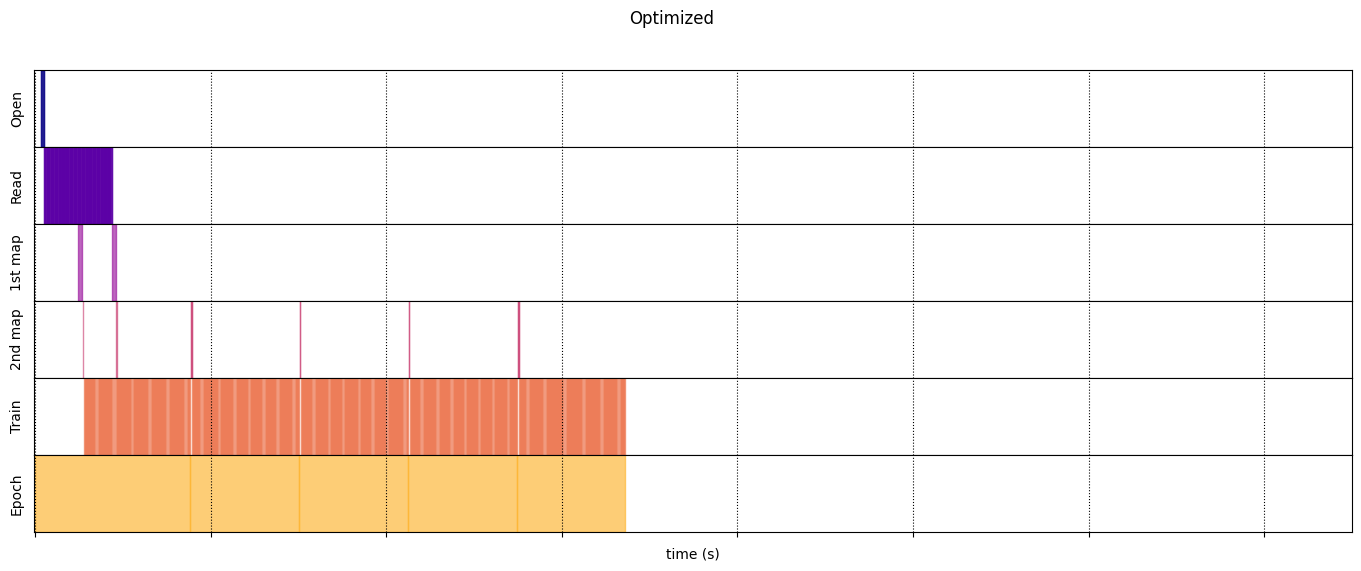
Execution time: 6.723691489999965
draw_timeline(naive_timeline, "Naive", 15)
draw_timeline(optimized_timeline, "Optimized", 15)