
 GitHubでソースを表示 GitHubでソースを表示 |
APIドキュメント: tf.RaggedTensor tf.ragged
セットアップ
!pip install --pre -U tensorflow
import math
import tensorflow as tf
2022-12-14 20:10:30.858511: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 20:10:30.858599: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 20:10:30.858608: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
概要
データにはさまざまな形状があります。テンソルも同じです。不規則なテンソルは、TensorFlow 相当のネストされた可変長リストです。このテンソルを使用すると、次のような不均一な形状のデータを簡単に保存して処理できます。
- 映画の俳優のセットなど、可変長の特徴量。
- テキストや動画クリップなど、可変長シーケンシャル入力のバッチ。
- セクション、段落、文、単語に細分されたテキストドキュメントなどの階層的な入力。
- プロトコルバッファなどの構造化入力の個々のフィールド。
不規則なテンソルを使用してできること
不規則なテンソルは、100 個以上の TensorFlow 演算(tf.add や tf.reduce_mean など)、配列演算(tf.concat や tf.tile など)、文字列操作演算(tf.substr など)、制御フロー演算(tf.while_loop や tf.map_fn など)、およびその他多数の演算でサポートされています。
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
ファクトリメソッド、変換メソッド、および値のマッピング演算など、不規則なテンソルに固有のメソッドや演算も多数あります。サポートされている演算のリストについては、tf.ragged パッケージドキュメントをご覧ください。
不規則なテンソルは、Keras、Datasets、tf.function、SavedModels、および tf.Example など、多数の TensorFlow API でサポートされています。詳細については、以下の「TensorFlow API」のセクションをご覧ください。
通常のテンソルと同様に、Python スタイルのインデキシングを使用して、不規則なテンソルの特定のスライスにアクセスできます。詳細については、以下の「インデキシング」のセクションをご覧ください。
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
また、通常のテンソルと同様に、Python の算術演算子と比較演算子を使用して、要素ごとの演算を実行できます。詳細については、以下の「オーバーロードされた演算子」をご覧ください。
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
RaggedTensor の値に要素ごとの変換を実行する必要がある場合は、 tf.ragged.map_flat_values を使用できます。これは、関数と 1 つ以上の引数をとり、関数を適用して RaggedTensor の値を変換します。
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
不規則なテンソルは、ネストされた Python list と NumPy の array に変換できます。
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
不規則なテンソルを構築する
不規則なテンソルを構築するには、tf.ragged.constant を使用するのが最も簡単な方法です。これは、特定のネストされた Python list または NumPy の array に応じた RaggedTensor を構築します。
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
不規則なテンソルは、フラット値のテンソルと行を分割するテンソルを組み合わせ、tf.RaggedTensor.from_value_rowids、tf.RaggedTensor.from_row_lengths、および tf.RaggedTensor.from_row_splits などのファクトリクラスメソッドを使ってこれらの値をどのように行に分割するのかを示すことで、構築することもできます。
tf.RaggedTensor.from_value_rowids
各値が属する行がわかっている場合は、value_rowids 行分割テンソルを使用して、RaggedTensor を構築できます。
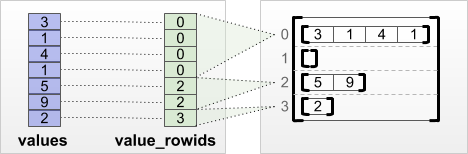
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
各行の長さがわかっている場合は、row_lengths 行分割テンソルを使用できます。
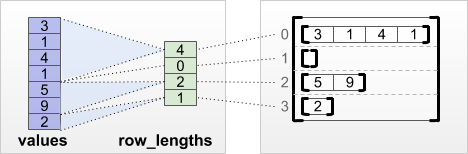
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
各行が開始および終了するインデックスがわかっている場合は、row_splits 行分割テンソルを使用できます。
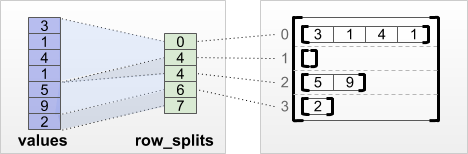
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
ファクトリメソッドの全リストについては、tf.RaggedTensor クラスのドキュメントをご覧ください。
注意: デフォルトでは、これらのファクトリメソッドによって、行分割テンソルが整形されており、値の数と一貫しているというアサーションが追加されます。入力の整形と一貫性を保証できる場合は、validate=False パラメータを使用してこれらの検査を省略できます。
不規則なテンソルに格納できるもの
通常の Tensor と同様に、RaggedTensor の値にはすべて同じ型が必要で、値にはすべて同じネストの深度(テンソルの階数)が必要です。
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
使用事例
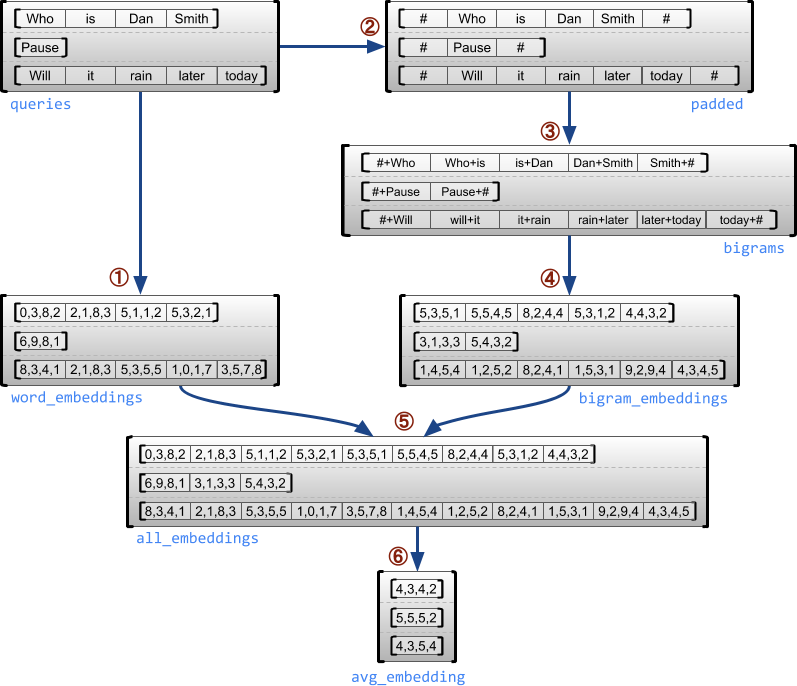
次の例は、各文の最初と最後に特殊マーカーを使用して、可変長クエリのバッチのユニグラムとバイグラムの埋め込みを構築して組み合わせるために RaggedTensor を使用する方法を示しています。この例で使用されている演算に関する詳細は、tf.ragged パッケージドキュメントをご覧ください。
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.01155425 0.10677658 0.08944342 -0.10517415] [-0.25956473 -0.08448458 0.06543094 -0.00812991] [ 0.07745109 -0.13418645 0.1892357 0.00991403]], shape=(3, 4), dtype=float32)
不規則な次元と一様次元
不規則な次元とは、スライスの長さが異なる次元を指します。たとえば、内側の(列の)次元 rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] は不規則です。これは、列スライス(rt[0, :], ..., rt[4, :])の長さが異なるからです。スライスの長さがすべて同一の次元は一様次元と呼ばれます。
不規則なテンソルの一番外側の次元は、必ず一様です。これは、単一のスライスで構成されているためです(単一であるため長さが異なることがない)。残りの次元は、不規則または一様です。たとえば、形状 [num_sentences, (num_words), embedding_size]((num_words) の括弧は次元が不規則であることを示す)の不規則な次元を使用して、文のバッチの各語に対する語の埋め込みを格納することができます。
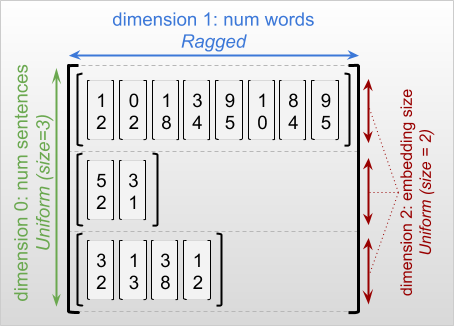
不規則なテンソルは、複数の不規則な次元を持つことができます。たとえば、形状 [num_documents, (num_paragraphs), (num_sentences), (num_words)](括弧は不規則な次元であることを示す)のテンソルを使用して、構造化テキストドキュメントのバッチを格納できます。
tf.Tensor と同様に、不規則なテンソルの階数は、次元の合計数(不規則な次元と一様次元の両方を含む)です。潜在的に不規則なテンソル は、tf.Tensor または tf.RaggedTensor のいずれかである値です。
RaggedTensor の形状を記述する場合、不規則な次元は従来、それを丸括弧で囲むことで示されます。たとえば、上記の例で示したように、文のバッチの各語に対する語の埋め込みを格納する 3-D RaggedTensor の形は、[num_sentences, (num_words), embedding_size] と記述できます。
RaggedTensor.shape 属性は、不規則なテンソルの tf.TensorShape を返します。不規則な次元のサイズは None です。
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
メソッド tf.RaggedTensor.bounding_shape は、指定された RaggedTensor の密着する境界形状を見つけるために使用できます。
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
不規則とスパース
不規則なテンソルをスパーステンソルの一種として捉えてはいけません。具体的には、スパーステンソルは、tf.Tensor の効率的なエンコーディングで、同一のデータをコンパクトな形式でモデルする一方、不規則なテンソルは tf.Tensor の拡張で、データの拡張クラスをモデルします。演算を定義する場合に、この違いが非常に重要となります。
- スパーステンソルまたは密なテンソルに演算を適用すると、同じ結果を得られます。
- 不規則なテンソルまたはスパーステンソルに演算を適用すると、異なる結果が得られる場合があります。
実例として、concat、stack、および tile などの配列演算が不規則なテンソルとスパーステンソルにどのように定義されているか考察してみましょう。不規則なテンソルを連結すると、各行が結合されて、長さが組み合わされた単一の行が形成されます。

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
ところが、次の例で説明されているように、スパーステンソルを連結すると、対応する密のテンソルと同じ結果が得られます(Ø は欠落した値)。
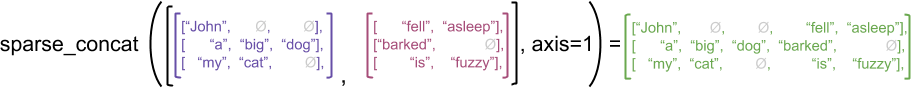
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
この区別が重要であることを示すもう 1 つの例として、tf.reduce_mean などの演算の「各行の平均値」の定義を考察してみましょう。不規則なテンソルでは、行の平均値は、行の値の合計を行の幅で除算した値となりますが、スパーステンソルでは、行の平均値は、行の値の合計をスパーステンソルの全体的な幅(最長行の幅以上になる)で除算した値となります。
TensorFlow API
Keras
tf.keras は、ディープラーニングモデルの構築とトレーニングに使用する TensorFlow の高位 API です。不規則なテンソルは、tf.keras.Input または tf.keras.layers.InputLayer に ragged=True を設定することで、Keras モデルに入力として渡すことができます。また、Keras レイヤー間で渡して、Keras モデルによって返すことも可能です。次の例は、不規則なテンソルを使用してトレーニングされる LSTM トイモデルを示します。
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU. Epoch 1/5 1/1 [==============================] - 2s 2s/step - loss: 3.0112 Epoch 2/5 1/1 [==============================] - 0s 16ms/step - loss: 1.8928 Epoch 3/5 1/1 [==============================] - 0s 15ms/step - loss: 1.8111 Epoch 4/5 1/1 [==============================] - 0s 15ms/step - loss: 1.7511 Epoch 5/5 1/1 [==============================] - 0s 16ms/step - loss: 1.7005 1/1 [==============================] - 0s 195ms/step [[0.03842294] [0.01246321] [0.0355459 ] [0.01623641]]
tf.Example
tf.Example は、TensorFlow データの標準的な protobuf エンコーディングです。tf.Example でエンコードされるデータには通常、可変長の特徴量が含まれます。たとえば、次のコードは、異なる特徴の長さを持つ 4 つの tf.Example メッセージのバッチを定義しています。
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
このエンコードされたデータは、tf.io.parse_example を使用して解析できます。シリアル化文字列のテンソルと特徴の仕様を表すディクショナリを取り、ディクショナリのマッピング特徴名をテンソルに返します。不規則なテンソルに可変長の特徴を読み取るには、特徴仕様ディクショナリで tf.io.RaggedFeature を使用します。
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
複数の不規則な次元を持つ特徴を読み取るには、tf.io.RaggedFeature も使用できます。詳細については、API ドキュメントをご覧ください。
データセット
tf.data は、単純で再利用可能なピースから複雑な入力パイプラインを構築できる API です。そのコアデータ構造は tf.data.Dataset で、一連の要素を表し、その各要素には 1 つ以上のコンポーネントが含まれます。
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
不規則なテンソルを伴うデータセットを構築する
データセットは、tf.Tensor または NumPy の array から構築する際に使用されるのと同じメソッド、つまり Dataset.from_tensor_slices を使用して、不規則なテンソルから構築できます。
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
注意: Dataset.from_generator は不規則なテンソルにまだ対応していませんが、近々サポートされる予定です。
不規則なテンソルを伴うデータセットをバッチ処理またはバッチ解除する
不規則なテンソルを伴うデータセットは、Dataset.batch メソッドを使用してバッチ処理できます(n 個の連続した要素を単一の要素に組み合わせます)。
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
逆に、バッチ処理されたデータセットは、Dataset.unbatch を使用して、フラットデータセットに変換できます。
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
可変長の非不規則テンソルを伴うデータセットをバッチ処理する
非不規則テンソルを含むデータセットで、テンソルの長さが要素間で異なる場合は、dense_to_ragged_batch 変換を使用して、それらの非不規則テンソルを不規則なテンソルにバッチ処理できます。
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
不規則なテンソルを伴うデータセットを変換する
また、Dataset.map を使って、データセットの不規則なテンソルを作成または変換することができます。
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.function
tf.function は、Python 関数向けに TensorFlow グラフを事前計算するデコレータで、TensorFlow コードのパフォーマンスを大幅に改善できます。不規則なテンソルは、@tf.function でデコレートされた関数と透過的に使用することができます。たとえば、次の関数は、不規則なテンソルと非不規則テンソルの両方で動作します。
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2022-12-14 20:10:38.961609: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
tf.function で input_signature を明示的に指定する場合は、tf.RaggedTensorSpec を使用して行います。
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
具象関数
具象関数は、tf.function で構築された個別のトレース済みグラフをカプセル化します。不規則なテンソルは、具象関数と透過的に使用できます。
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
SavedModel
SavedModel は、シリアル化された TensorFlow プログラムで、重みと計算の両方が含まれます。Keras モデルまたはカスタムモデルから構築することができますが、いずれの場合でも、不規則なテンソルは SavedModel によって定義された関数とメソッドを使って、透過的に使用することができます。
例: Keras モデルを保存する
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmpfs/tmp/tmp217ivt8w/assets
INFO:tensorflow:Assets written to: /tmpfs/tmp/tmp217ivt8w/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.03842294],
[0.01246321],
[0.0355459 ],
[0.01623641]], dtype=float32)>
例: カスタムモデルを保存する
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpgyw6vslh/assets INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpgyw6vslh/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
注意: SavedModel シグネチャは具象関数です。上記の「具象関数」のセクションで説明したとおり、具象関数による不規則なテンソルの処理は、TensorFlow 2.3 以降でのみ正しく行われます。TensorFlow の旧バージョンで SavedModel シグネチャを使用する必要がある場合は、不規則なテンソルをコンポーネントテンソルに分解することをお勧めします。
オーバーロードされた演算
RaggedTensor クラスは標準的な Python 算術と比較演算をオーバーロードするため、基本的な要素ごとの計算が簡単に行えるようになります。
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
オーバーロードされた演算は、要素ごとの計算を実行するため、すべての二項演算への入力が同じ形状であるか、同じ形状にブロードキャスト可能である必要があります。最も単純なブロードキャストの場合、単一のスカラーは、不規則なテンソルの各値と要素ごとに組み合わされます。
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
より高度な事例については、ブロードキャストに関するセクションをご覧ください。
不規則なテンソルは、通常の Tensor と同じ一連の演算子をオーバーロードします。それらは、単項演算子の -、~、および abs()、二項演算子の +、-、*、/、//、%、**、&、|、^、==、<、<=、>、および >= です。
インデキシング
不規則なテンソルは、多次元のインデキシングとスライシングを含む、Python 形式のインデキシングをサポートしています。次の例では、2D と 3D の不規則なテンソルによる不規則なテンソルのインデキシングを示しています。
インデキシングの例: 2D 不規則テンソル
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
インデキシングの例: 3D 不規則テンソル
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor は多次元のインデキシングとスライシングをサポートしていますが、1 つだけ制限があります。それは、不規則な次元へのインデキシングはできないということです。示された値が一部の行のみに存在することがあるため、これは悩ましいことです。このような場合は、(1)IndexError を発するべきか、(2)デフォルト値を使用すべきか、(3)その値をスキップして、開始した数より少ない行数のテンソルを返すべきか、明確ではありません。Python の基本原則(「曖昧なものに出逢ったら、その意味を適当に推測してはいけない。」)に則り、現在のところこの演算を許可していません。
テンソル型の変換
RaggedTensor クラスは、RaggedTensor と tf.Tensor または tf.SparseTensors 間の変換に使用できるメソッドを定義します。
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
不規則なテンソルの評価
不規則なテンソルの値にアクセスするには、次を行えます。
tf.RaggedTensor.to_listを使用して、不規則なテンソルをネストされた Python リストに変換する。tf.RaggedTensor.numpyを使用して、不規則なテンソルを NumPy 配列にネストされた値を持つ NumPy 配列に変換する。tf.RaggedTensor.valuesとtf.RaggedTensor.row_splitsプロパティ、またはtf.RaggedTensor.row_lengthsやtf.RaggedTensor.value_rowidsなどの行分割メソッドを使用して、不規則なテンソルをコンポーネントに分解する。- Python インデキシングを使用して、不規則なテンソルから値を選択する。
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5]
不規則な形状
テンソルの形状は、各軸のサイズを指定します。たとえば、[[1, 2], [3, 4], [5, 6]] の形状は [3, 2](3 行と 2 列)です。TensorFlow には、形状を記述する 2 つの別個の関連する方法があります。
静的形状: 静的にわかっている軸サイズに関する情報(例:
tf.functionのトレース時)。部分的に指定することができます。動的形状: 軸のサイズに関するランタイム情報。
静的形状
Tensor の静的形状には、グラフ構築時に知られている軸サイズに関する情報が含まれています。tf.Tensor と tf.RaggedTensor の両方で、.shape プロパティを使用して利用でき、tf.TensorShape を使用してエンコードされます。
x = tf.constant([[1, 2], [3, 4], [5, 6]])
x.shape # shape of a tf.tensor
TensorShape([3, 2])
rt = tf.ragged.constant([[1], [2, 3], [], [4]])
rt.shape # shape of a tf.RaggedTensor
TensorShape([4, None])
不規則なサイズの静的形状は常に None(つまり、未指定)です。ただし、逆は真ではありません。TensorShape 次元が None の場合、次元が不規則、または、次元が均一であるが、そのサイズが静的にわかっていないことを示します。
動的形状
テンソルの動的形状には、グラフの実行時に認識される軸サイズに関する情報が含まれています。これは、tf.shape 演算を使用して構築されます。tf.Tensor の場合、tf.shape は形状を 1D 整数 Tensor として返します。ここで tf.shape(x)[i ] は軸 i のサイズです。
x = tf.constant([['a', 'b'], ['c', 'd'], ['e', 'f']])
tf.shape(x)
<tf.Tensor: shape=(2,), dtype=int32, numpy=array([3, 2], dtype=int32)>
ただし、1次元 Tensor は、tf.RaggedTensor の形状を記述するほど表現力がありません。代わりに、不規則なテンソルの動的形状は、専用の形状tf.experimental.DynamicRaggedShape を使用してエンコードされます。 次の例では、tf.shape(rt) によって返される DynamicRaggedShape は、不規則なテンソルが長さ 1、3、0、2 の 4 つの行を持っていることを示しています。
rt = tf.ragged.constant([[1], [2, 3, 4], [], [5, 6]])
rt_shape = tf.shape(rt)
print(rt_shape)
<DynamicRaggedShape lengths=[4, (1, 3, 0, 2)] num_row_partitions=1>
動的形状: 演算
DynamicRaggedShape は、tf.reshape、tf.zeros、tf.ones、tf.fill、tf.broadcast_dynamic_shape、tf.broadcast_to など、形状を想定するほとんどの TensorFlow の演算で使用できます。
print(f"tf.reshape(x, rt_shape) = {tf.reshape(x, rt_shape)}")
print(f"tf.zeros(rt_shape) = {tf.zeros(rt_shape)}")
print(f"tf.ones(rt_shape) = {tf.ones(rt_shape)}")
print(f"tf.fill(rt_shape, 9) = {tf.fill(rt_shape, 'x')}")
tf.reshape(x, rt_shape) = <tf.RaggedTensor [[b'a'], [b'b', b'c', b'd'], [], [b'e', b'f']]> tf.zeros(rt_shape) = <tf.RaggedTensor [[0.0], [0.0, 0.0, 0.0], [], [0.0, 0.0]]> tf.ones(rt_shape) = <tf.RaggedTensor [[1.0], [1.0, 1.0, 1.0], [], [1.0, 1.0]]> tf.fill(rt_shape, 9) = <tf.RaggedTensor [[b'x'], [b'x', b'x', b'x'], [], [b'x', b'x']]>
動的形状: インデキシングとスライス
DynamicRaggedShape は、均一な次元のサイズを取得するためにインデックスを付けることもできます。たとえば、tf.shape(rt)[0] を使用して不規則テンソルの行数を見つけることができます(非不規則テンソルの場合と同様)。
rt_shape[0]
<tf.Tensor: shape=(), dtype=int32, numpy=4>
ただし、インデキシングを使用して不規則な次元のサイズを取得しようとするとエラーになります。これは、サイズが 1 つでないためです。(RaggedTensor は不規則な軸を追跡するため、このエラーは eager 実行時または tf.function をトレースするときにのみスローされます。具体的な 関数の実行時にはスローされません。)
try:
rt_shape[1]
except ValueError as e:
print("Got expected ValueError:", e)
Got expected ValueError: Index 1 is not uniform
また、DynamicRaggedShape は、スライスが軸 0 で始まるか、密な次元のみを含む限り、スライスできます。
rt_shape[:1]
<DynamicRaggedShape lengths=[4] num_row_partitions=0>
動的形状: エンコーディング
DynamicRaggedShape 次の 2 つのフィールドを使用してエンコードされます。
inner_shape: 密なtf.Tensorの形状を与える整数ベクトル。row_partitions:tf.experimental.RowPartitionオブジェクトのリストで、不規則な軸を追加するために内部形状の最も外側の次元を分割する方法を記述します。
行パーティションの詳細については、以下の「RaggedTensor エンコーディング」セクションと tf.experimental.RowPartition の API ドキュメントを参照してください。
動的形状: 構築
DynamicRaggedShape は、ほとんどの場合、{code 1}tf.shape を RaggedTensor に適用することによって構築されますが、直接構築することもできます。
tf.experimental.DynamicRaggedShape(
row_partitions=[tf.experimental.RowPartition.from_row_lengths([5, 3, 2])],
inner_shape=[10, 8])
<DynamicRaggedShape lengths=[3, (5, 3, 2), 8] num_row_partitions=1>
すべての行の長さが静的に知られている場合は、DynamicRaggedShape.from_lengths を使用して動的な不規則な形状を構築することもできます。(不規則な次元の長さが静的に知られることはほとんどありませんが、これはテストおよびデモンストレーションコードに役立ちます)。
tf.experimental.DynamicRaggedShape.from_lengths([4, (2, 1, 0, 8), 12])
<DynamicRaggedShape lengths=[4, (2, 1, 0, 8), 12] num_row_partitions=1>
ブロードキャスト
ブロードキャストとは、さまざまな形状のテンソルに要素単位の演算で互換性のある形状を持たせるプロセスです。ブロードキャストの詳しい背景については、次をご覧ください。
次は、互換性のある形状を持たせるために x と y の 2 つの入力をブロードキャストする基本手順です。
xとyの次元数が異なる場合は、次元数が同じになるまで外側の次元(サイズ 1)を追加します。xとyのサイズが異なる各次元に対し、次のことを行います。
xまたはyの次元dがサイズ1の場合は、もう片方の入力のサイズに一致するように、次元dでその値を繰り返します。- そうでない場合は、例外(
xとyはブロードキャスト互換ではない)を発します。
一様次元内のテンソルのサイズは単一の数字であり(その次元のスライスのサイズ)、不規則な次元内のテンソルサイズはスライスの長さのリスト(その次元のすべてのスライス)です。
ブロードキャストの例
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
次は、ブロードキャストしない形状の例です。
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Condition x == y did not hold. Indices of first 3 different values: [[1] [2] [3]] Corresponding x values: [ 4 8 12] Corresponding y values: [2 6 7] First 3 elements of x: [0 4 8] First 3 elements of y: [0 2 6]
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Condition x == y did not hold. Indices of first 2 different values: [[1] [3]] Corresponding x values: [3 6] Corresponding y values: [2 5] First 3 elements of x: [0 3 4] First 3 elements of y: [0 2 4]
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Condition x == y did not hold. Indices of first 3 different values: [[1] [2] [3]] Corresponding x values: [2 4 6] Corresponding y values: [3 6 9] First 3 elements of x: [0 2 4] First 3 elements of y: [0 3 6]
RaggedTensor エンコーディング
不規則なテンソルは、RaggedTensor クラスを使ってエンコードされています。内部的に、各 RaggedTensor は次の項目で構成されています。
valuesテンソル。可変長の行をフラットリストに連結します。row_partition。フラット化された値がどのように行に分割されているかを示します。
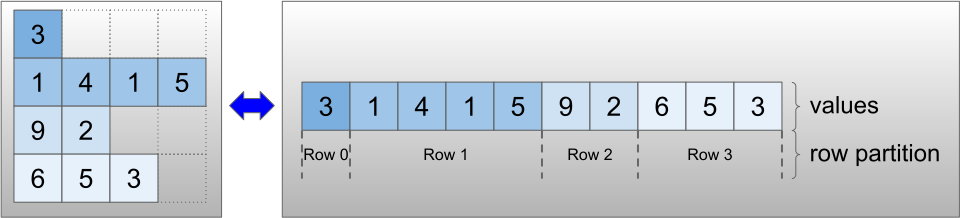
row_partition は、次の 4 つのエンコーディングで保存できます。
row_splitsは、行間の分割ポイントを指定する整数ベクトルです。value_rowidsは、各値の行インデックスを指定する整数ベクトルです。row_lengthsは、各行の長さを指定する整数ベクトルです。uniform_row_lengthは、すべての行の単一の長さを指定する整数スカラーです。
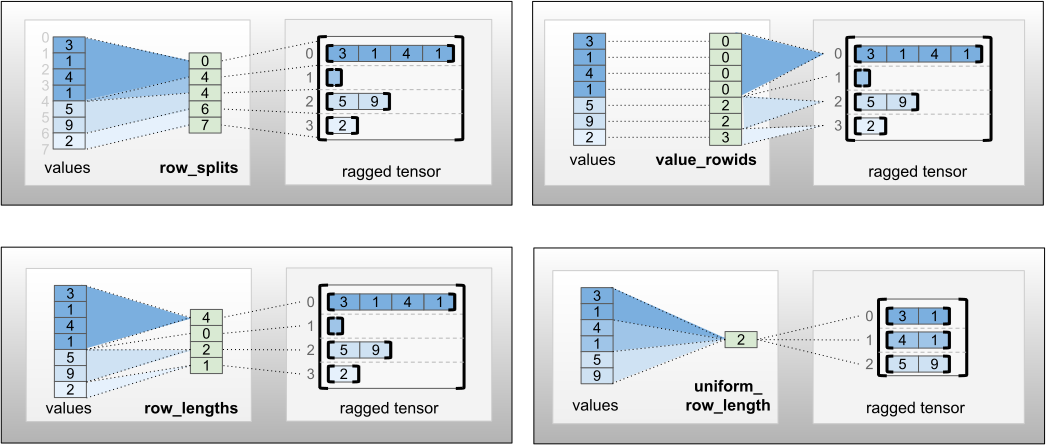
整数スカラー nrows は、valuerowids のある空の後続の行、または uniform_row_length のある空の行を構成するように、row_partition エンコーディングに含めることができます。
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
行分割に使用するエンコーディングの選択は、不規則なテンソルによって内部的に管理されており、一部の文脈で効率性を改善することができます。具体的には、異なる行分割スキームのメリットと欠点には次のようなものがあります。
- 効率的なインデキシング:
row_splitsエンコーディングにより、不規則なテンソルへの一定時間のインデキシングとスライシングが可能になります。 - 効率的な連結:
row_lengthsエンコーディングは、不規則なテンソルを連結する場合により効率性が高くなります。2 つのテンソルを連結する際に、行の長さが変化しないためです。 - 小さなエンコーディングサイズ:
value_rowidsエンコーディングは、空の行が大量にある不規則なテンソルを格納する際により効率性が高くなります。テンソルのサイズが、値の合計数にのみ依存しているためです。一方、row_splitsとrow_lengthsエンコーディングは、より長い行のある不規則なテンソルを格納する際により効率性が高くなります。各行に必要なスカラー値が 1 つのみであるためです。 - 互換性:
value_rowidsスキームは、演算で使用されるセグメンテーション形式に一致しています(tf.segment_sumなどの演算)。row_limitsスキームは、tf.sequence_mask演算で使用される形式に一致しています。 - 一様次元: 以下で説明するように、一様次元を伴う不規則なテンソルのエンコードには、
uniform_row_lengthエンコーディングが使用されます。
複数の不規則な次元
複数の不規則な次元を伴う不規則なテンソルは、values テンソルにネストされた RaggedTensor を使用することで、エンコードされます。それぞれのネストされた RaggedTensor は、単一の不規則な次元を追加します。
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
ファクトリ関数 tf.RaggedTensor.from_nested_row_splits は、row_splits テンソルのリストを提供することで、複数の不規則な次元を持つ RaggedTensor を直接構築するために使用できます。
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
不規則な階数とフラット値
不規則なテンソルの不規則な階数は、Tensor が持つ基底の values が何回分割されたかを表す数字です(RaggedTensor オブジェクトのネスト深度)。最も内側の values テンソルは flat_values と呼ばれます。次の例では、conversations には ragged_rank=3 があり、flat_values は 24 個の文字列を持つ 1D Tensor です。
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
一様の内部次元
一様の内部次元を伴う不規則なテンソルは、flat_values(最内部の values)に多次元の tf.Tensor を使用することでエンコードされます。
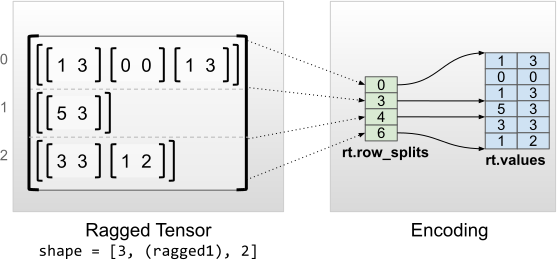
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3],
[0, 0],
[1, 3]], [[5, 3]], [[3, 3],
[1, 2]]]>
Shape: (3, None, 2)
Number of partitioned dimensions: 1
Flat values shape: (6, 2)
Flat values:
[[1 3]
[0 0]
[1 3]
[5 3]
[3 3]
[1 2]]
一様の非内部次元
一様の非内部次元を伴う不規則なテンソルは、uniform_row_length で行を分割してエンコードします。
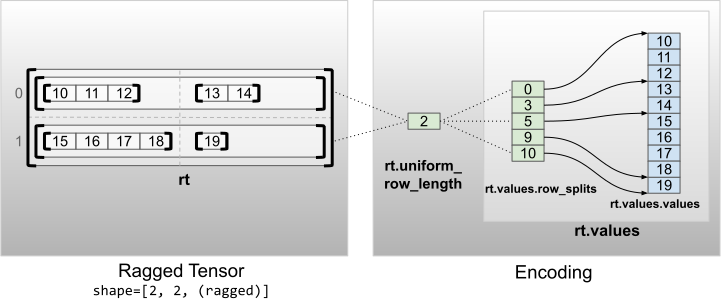
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2