
| |
 在 Github 上查看源代码 在 Github 上查看源代码 |
|
API 文档: tf.RaggedTensor tf.ragged
设置
!pip install --pre -U tensorflow
import math
import tensorflow as tf
2022-12-14 22:26:04.392854: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 22:26:04.392948: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 22:26:04.392958: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
概述
数据有多种形状;张量也应当有多种形状。不规则张量是嵌套的可变长度列表的 TensorFlow 等效项。它们使存储和处理包含非均匀形状的数据变得容易,包括:
- 可变长度特征,例如电影的演员名单。
- 成批的可变长度顺序输入,例如句子或视频剪辑。
- 分层输入,例如细分为节、段落、句子和单词的文本文档。
- 结构化输入中的各个字段,例如协议缓冲区。
不规则张量的功能
超过一百种 TensorFlow 运算支持不规则张量,包括数学运算(如 tf.add 和 tf.reduce_mean)、数组运算(如 tf.concat 和 tf.tile)、字符串操作运算(如 tf.substr)、控制流运算(如 tf.while_loop 和 tf.map_fn)等:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
还有专门针对不规则张量的方法和运算,包括工厂方法、转换方法和值映射运算。有关支持的运算列表,请参阅 tf.ragged 包文档。
许多 TensorFlow API 都支持不规则张量,包括 Keras、Dataset、tf.function、SavedModel 和 tf.Example。有关详情,请参阅下面的 TensorFlow API 部分。
与普通张量一样,您可以使用 Python 风格的索引来访问不规则张量的特定切片。有关详情,请参阅下面的索引部分。
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
与普通张量一样,您可以使用 Python 算术和比较运算符来执行逐元素运算。有关详情,请参阅下面的重载运算符部分。
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
如果需要对 RaggedTensor 的值进行逐元素转换,您可以使用 tf.ragged.map_flat_values(它采用一个函数加上一个或多个参数的形式),并应用这个函数来转换 RaggedTensor 的值。
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
不规则张量可以转换为嵌套的 Python list 和 NumPy array:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
构造不规则张量
构造不规则张量的最简单方式是使用 tf.ragged.constant,它会构建与给定的嵌套 Python list 或 NumPy array 相对应的 RaggedTensor:
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
还可以通过将扁平的值张量与行分区张量进行配对来构造不规则张量,行分区张量使用 tf.RaggedTensor.from_value_rowids、tf.RaggedTensor.from_row_lengths 和 tf.RaggedTensor.from_row_splits 等工厂类方法指示如何将值分成各行。
tf.RaggedTensor.from_value_rowids
如果您知道每个值属于哪一行,可以使用 value_rowids 行分区张量构建 RaggedTensor:
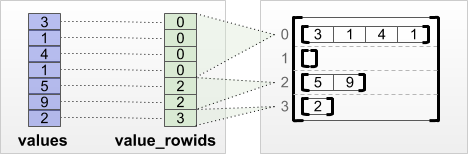
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
如果知道每行的长度,可以使用 row_lengths 行分区张量:
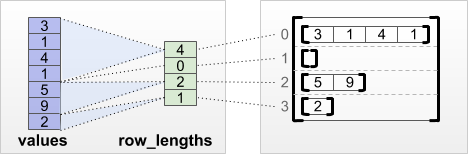
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
如果知道指示每行开始和结束的索引,可以使用 row_splits 行分区张量:
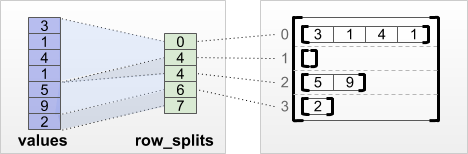
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
有关完整的工厂方法列表,请参阅 tf.RaggedTensor 类文档。
注:默认情况下,这些工厂方法会添加断言,说明行分区张量结构良好且与值数量保持一致。如果您能够保证输入的结构良好且一致,可以使用 validate=False 参数跳过此类检查。
可以在不规则张量中存储什么
与普通 Tensor 一样,RaggedTensor 中的所有值必须具有相同的类型;所有值必须处于相同的嵌套深度(张量的秩):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
示例用例
以下示例演示了如何使用 RaggedTensor,通过为每个句子的开头和结尾使用特殊标记,为一批可变长度查询构造和组合一元与二元嵌入向量。有关本例中使用的运算的更多详细信息,请参阅 tf.ragged 软件包文档。
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[ 0.02510674 -0.04737939 0.01799836 0.1717977 ] [ 0.4977201 0.38424173 -0.40286708 -0.39982286] [ 0.16051094 0.2062596 -0.05239218 0.10338864]], shape=(3, 4), dtype=float32)
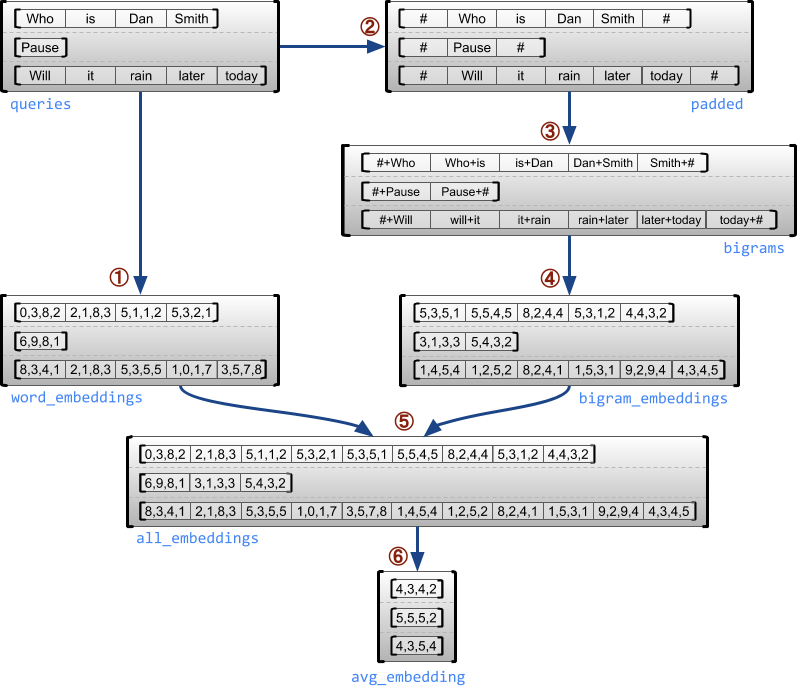
不规则维度和均匀维度
不规则维度是切片可能具有不同长度的维度。例如,rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] 的内部(列)维度是不规则的,因为列切片 (rt[0, :], ..., rt[4, :]) 具有不同的长度。切片全都具有相同长度的维度称为均匀维度。
不规则张量的最外层维度始终是统一维度,因为它只包含一个切片(因此不可能有不同的切片长度)。其余维度可能是不规则维度,也可能是统一维度。例如,我们可以使用形状为 [num_sentences, (num_words), embedding_size] 的不规则张量为一批句子中的每个单词存储单词嵌入向量,其中 (num_words) 周围的括号表示维度是不规则维度。
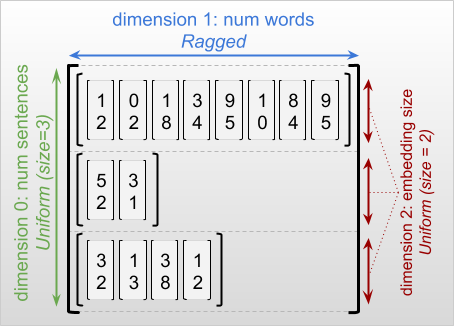
不规则张量可以有多个不规则维度。例如,我们可以使用形状为 [num_documents, (num_paragraphs), (num_sentences), (num_words)] 的张量存储一批结构化文本文档(其中,括号同样用于表示不规则维度)。
与 tf.Tensor 一样,不规则张量的秩是其总维数(包括不规则维度和均匀维度)。潜在的不规则张量是一个值,这个值可能是 tf.Tensor 或 tf.RaggedTensor。
描述 RaggedTensor 的形状时,按照惯例,不规则维度会通过括号进行指示。例如,如上面所见,存储一批句子中每个单词的单词嵌入向量的三维 RaggedTensor 的形状可以写为 [num_sentences, (num_words), embedding_size]。
RaggedTensor.shape 特性返回不规则张量的 tf.TensorShape,其中不规则维度的大小为 None:
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
可以使用方法 tf.RaggedTensor.bounding_shape 查找给定 RaggedTensor 的紧密边界形状:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
不规则张量和稀疏张量对比
不规则张量不应该被认为是一种稀疏张量。尤其是,稀疏张量是以紧凑的格式对相同数据建模的 tf.Tensor 的高效编码;而不规则张量是对扩展的数据类建模的 tf.Tensor 的扩展。这种区别在定义运算时至关重要:
- 对稀疏张量或密集张量应用某一运算应当始终获得相同结果。
- 对不规则张量或稀疏张量应用某一运算可能获得不同结果。
一个说明性的示例是,考虑如何为不规则张量和稀疏张量定义 concat、stack 和 tile 之类的数组运算。连接不规则张量时,会将每一行连在一起,形成一个具有组合长度的行:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
但连接稀疏张量时,相当于连接相应的密集张量,如以下示例所示(其中 Ø 表示缺失的值):
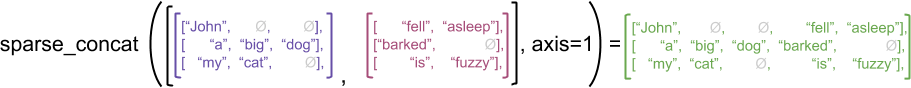
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
另一个说明为什么这种区别非常重要的示例是,考虑一个运算(如 tf.reduce_mean)的“每行平均值”的定义。对于不规则张量,一行的平均值是该行的值总和除以该行的宽度。但对于稀疏张量来说,一行的平均值是该行的值总和除以稀疏张量的总宽度(大于等于最长行的宽度)。
TensorFlow API
Keras
tf.keras 是 TensorFlow 的高级 API,用于构建和训练深度学习模型。通过在 tf.keras.Input 或 tf.keras.layers.InputLayer 上设置 ragged=True,不规则张量可以作为输入传送到 Keras 模型。不规则张量还可以在 Keras 层之间传递,并由 Keras 模型返回。以下示例显示了一个使用不规则张量训练的小 LSTM 模型。
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU. Epoch 1/5 1/1 [==============================] - 3s 3s/step - loss: 2.5281 Epoch 2/5 1/1 [==============================] - 0s 16ms/step - loss: 1.8739 Epoch 3/5 1/1 [==============================] - 0s 15ms/step - loss: 1.7525 Epoch 4/5 1/1 [==============================] - 0s 15ms/step - loss: 1.6736 Epoch 5/5 1/1 [==============================] - 0s 19ms/step - loss: 1.6017 1/1 [==============================] - 0s 186ms/step [[0.05265009] [0.000567 ] [0.03915224] [0.0021234 ]]
tf.Example
tf.Example 是 TensorFlow 数据的标准 protobuf 编码。使用 tf.Example 编码的数据往往包括可变长度特征。例如,以下代码定义了一批具有不同特征长度的四条 tf.Example 消息:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
您可以使用 tf.io.parse_example 解析此编码数据,它采用序列化字符串的张量和特征规范字典,并将字典映射特征名称返回给张量。要将可变长度特征读入不规则张量,我们只需在特征规范字典中使用 tf.io.RaggedFeature:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature 还可用于读取具有多个不规则维度的特征。有关详情,请参阅 API 文档。
数据集
tf.data 是一个 API,可用于通过简单的可重用代码块构建复杂的输入流水线。它的核心数据结构是 tf.data.Dataset,表示一系列元素,每个元素包含一个或多个分量。
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
使用不规则张量构建数据集
可以采用从 tf.Tensor 或 NumPy array 构建数据集时使用的方法,如 Dataset.from_tensor_slices,从不规则张量构建数据集:
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
注:Dataset.from_generator 目前还不支持不规则张量,但不久后将会支持这种张量。
批处理和取消批处理具有不规则张量的数据集
可以使用 Dataset.batch 方法对具有不规则张量的数据集进行批处理(将 n 个连续元素组合成单个元素)。
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
相反,可以使用 Dataset.unbatch 将批处理后的数据集转换为扁平数据集。
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
对具有可变长度非不规则张量的数据集进行批处理
如果您有一个包含非不规则张量的数据集,而且各个元素的张量长度不同,则可以应用 dense_to_ragged_batch 转换,将这些非不规则张量批处理成不规则张量:
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
转换具有不规则张量的数据集
还可以使用 Dataset.map 在数据集中创建或转换不规则张量:
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.function
tf.function 是预计算 Python 函数的 TensorFlow 计算图的装饰器,它可以大幅改善 TensorFlow 代码的性能。不规则张量能够透明地与 @tf.function 装饰的函数一起使用。例如,以下函数对不规则张量和非不规则张量均有效:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2022-12-14 22:26:12.602591: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
如果您希望为 tf.function 明确指定 input_signature,可以使用 tf.RaggedTensorSpec 执行此操作。
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
具体函数
具体函数封装通过 tf.function 构建的各个跟踪图。不规则张量可以透明地与具体函数一起使用。
# Preferred way to use ragged tensors with concrete functions (TF 2.3+):
try:
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
except Exception as e:
print(f"Not supported before TF 2.3: {type(e)}: {e}")
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
SavedModel
SavedModel 是序列化 TensorFlow 程序,包括权重和计算。它可以通过 Keras 模型或自定义模型构建。在任何一种情况下,不规则张量都可以透明地与 SavedModel 定义的函数和方法一起使用。
示例:保存 Keras 模型
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpc0mv81kq/assets
INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpc0mv81kq/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.05265009],
[0.000567 ],
[0.03915224],
[0.0021234 ]], dtype=float32)>
示例:保存自定义模型
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmpfs/tmp/tmp1pnf5uz8/assets INFO:tensorflow:Assets written to: /tmpfs/tmp/tmp1pnf5uz8/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
注:SavedModel 签名是具体函数。如上文的“具体函数”部分所述,从 TensorFlow 2.3 开始,只有具体函数才能正确处理不规则张量。如果您需要在先前版本的 TensorFlow 中使用 SavedModel 签名,建议您将不规则张量分解成其分量张量。
重载运算符
RaggedTensor 类会重载标准 Python 算术和比较运算符,使其易于执行基本的逐元素数学:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
由于重载运算符执行逐元素计算,因此所有二进制运算的输入必须具有相同的形状,或者可以广播至相同的形状。在最简单的广播情况下,单个标量与不规则张量中的每个值逐元素组合:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
有关更高级用例的讨论,请参阅广播部分。
不规则张量重载与正常 Tensor 相同的一组运算符:一元运算符 -、~ 和 abs();二元运算符 +、-、*、/、//、%、**、&、|、^、==、<、<=、> 和 >=。
索引
不规则张量支持 Python 风格的索引,包括多维索引和切片。以下示例使用二维和三维不规则张量演示了不规则张量索引。
索引示例:二维不规则张量
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
索引示例:三维不规则张量
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor 支持多维索引和切片,但有一个限制:不允许索引到不规则维度。这种情况会出现问题,因为指示的值可能在某些行中存在,而在其他行中不存在。在这种情况下,我们不知道是应该 (1) 引发 IndexError;(2) 使用默认值;还是 (3) 跳过该值并返回一个行数比开始时少的张量。根据 Python 的指导原则(“当面对不明确的情况时,不要尝试去猜测”),我们目前不允许此运算。
张量类型转换
RaggedTensor 类定义了可用于在 RaggedTensor 与 tf.Tensor 或 tf.SparseTensors 之间转换的方法:
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
评估不规则张量
要访问不规则张量中的值,您可以:
- 使用
tf.RaggedTensor.to_list()将不规则张量转换为嵌套 Python 列表。 - 使用
tf.RaggedTensor.numpy()将不规则张量转换为 NumPy 数组,该数组的值为嵌套 NumPy 数组。 - 使用
tf.RaggedTensor.values和tf.RaggedTensor.row_splits属性,或tf.RaggedTensor.row_lengths()和tf.RaggedTensor.value_rowids()等行分区方法,将不规则张量分解成其分量。 - 使用 Python 索引从不规则张量中选择值。
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5]
不规则形状
张量的形状指定每个轴的大小。例如 [[1, 2], [3, 4], [5, 6]] 的形状为 [3, 2],因为有 3 行 2 列。TensorFlow 有两种独立但相关的方式来描述形状:
静态形状:关于静态已知的轴大小的信息(例如,在跟踪
tf.function时)。可以部分指定。动态形状:有关轴大小的运行时信息。
静态形状
张量的静态形状包含有关其轴大小的信息,这些信息在计算图构造时是已知的。对于 tf.Tensor 和 tf.RaggedTensor,它可以使用 .shape 属性获得,并使用 tf.TensorShape 进行编码:
x = tf.constant([[1, 2], [3, 4], [5, 6]])
x.shape # shape of a tf.tensor
TensorShape([3, 2])
rt = tf.ragged.constant([[1], [2, 3], [], [4]])
rt.shape # shape of a tf.RaggedTensor
TensorShape([4, None])
不规则维度的静态形状始终为 None(即未指定)。然而,反过来则不成立。如果 TensorShape 维度为 None,则可能表明维度是不规则的,或者表明维度是统一的,但其大小不是静态已知的。
动态形状
张量的动态形状包含有关其轴大小的信息,这些信息在计算图运行时是已知的。它使用 tf.shape 运算构造。对于 tf.Tensor,tf.shape 将形状作为一维整数 Tensor 返回,其中 tf.shape(x)[i] 为轴 i 的大小。
x = tf.constant([['a', 'b'], ['c', 'd'], ['e', 'f']])
tf.shape(x)
<tf.Tensor: shape=(2,), dtype=int32, numpy=array([3, 2], dtype=int32)>
然而,一维 Tensor 的表达性不足以描述 tf.RaggedTensor 的形状。相反,不规则张量的动态形状使用专用类型 tf.experimental.DynamicRaggedShape 进行编码。在下面的示例中,tf.shape(rt) 返回的 DynamicRaggedShape 表示不规则张量有 4 行,长度分别为 1、3、0 和 2:
rt = tf.ragged.constant([[1], [2, 3, 4], [], [5, 6]])
rt_shape = tf.shape(rt)
print(rt_shape)
<DynamicRaggedShape lengths=[4, (1, 3, 0, 2)] num_row_partitions=1>
动态形状:运算
DynamicRaggedShape 可与大多数需要形状的 TensorFlow 运算一起使用,包括 tf.reshape、tf.zeros、tf.ones、tf.fill、tf.broadcast_dynamic_shape 和 tf.broadcast_to。
print(f"tf.reshape(x, rt_shape) = {tf.reshape(x, rt_shape)}")
print(f"tf.zeros(rt_shape) = {tf.zeros(rt_shape)}")
print(f"tf.ones(rt_shape) = {tf.ones(rt_shape)}")
print(f"tf.fill(rt_shape, 9) = {tf.fill(rt_shape, 'x')}")
tf.reshape(x, rt_shape) = <tf.RaggedTensor [[b'a'], [b'b', b'c', b'd'], [], [b'e', b'f']]> tf.zeros(rt_shape) = <tf.RaggedTensor [[0.0], [0.0, 0.0, 0.0], [], [0.0, 0.0]]> tf.ones(rt_shape) = <tf.RaggedTensor [[1.0], [1.0, 1.0, 1.0], [], [1.0, 1.0]]> tf.fill(rt_shape, 9) = <tf.RaggedTensor [[b'x'], [b'x', b'x', b'x'], [], [b'x', b'x']]>
动态形状:索引和切片
DynamicRaggedShape 也可以被索引以获得统一维度的大小。例如,我们可以使用 tf.shape(rt)[0] 找到不规则张量中的行数(就像我们对非不规则张量做的那样):
rt_shape[0]
<tf.Tensor: shape=(), dtype=int32, numpy=4>
但是,使用索引来尝试检索不规则维度的大小是一种错误,因为它没有单一的大小。(由于 RaggedTensor 会跟踪哪些轴是不规则的,仅在 Eager execution 期间或跟踪 tf.function 时会引发此错误;在执行具体函数时永远不会引发此错误。)
try:
rt_shape[1]
except ValueError as e:
print("Got expected ValueError:", e)
Got expected ValueError: Index 1 is not uniform
此外,也可以对 DynamicRaggedShape 进行切片,前提是切片从轴 0 开始,或者仅包含密集维度。
rt_shape[:1]
<DynamicRaggedShape lengths=[4] num_row_partitions=0>
动态形状:编码
DynamicRaggedShape 使用两个字段进行编码:
inner_shape:一个整数向量,给出了密集tf.Tensor的形状。row_partitions:tf.experimental.RowPartition对象的列表,描述了应当如何对该内部形状的最外层维度进行分区以添加不规则轴。
有关行分区的更多信息,请参阅下面的“不规则张量编码”部分以及 tf.experimental.RowPartition 的 API 文档。
动态形状:构造
DynamicRaggedShape 最常通过将 tf.shape 应用于 RaggedTensor 来构造,但也可以直接构造:
tf.experimental.DynamicRaggedShape(
row_partitions=[tf.experimental.RowPartition.from_row_lengths([5, 3, 2])],
inner_shape=[10, 8])
<DynamicRaggedShape lengths=[3, (5, 3, 2), 8] num_row_partitions=1>
如果所有行的长度都是静态已知的,DynamicRaggedShape.from_lengths 也可用于构造动态不规则形状。(这对于测试和演示代码特别有用,因为极少会静态已知不规则维度的长度)。
tf.experimental.DynamicRaggedShape.from_lengths([4, (2, 1, 0, 8), 12])
<DynamicRaggedShape lengths=[4, (2, 1, 0, 8), 12] num_row_partitions=1>
广播
广播是使具有不同形状的张量获得兼容形状以便进行逐元素运算的过程。有关广播的更多背景信息,请参阅:
广播两个输入 x 和 y,使其具有兼容形状的基本步骤是:
如果
x和y没有相同的维数,则增加外层维度(使用大小 1),直至它们具有相同的维数。对于
x和y的大小不同的每一个维度:
- 如果
x或y在d维中的大小为1,则在d维中重复其值以匹配其他输入的大小。 - 否则,引发异常(
x和y非广播兼容)。
其中,均匀维度中一个张量的大小是一个数字(跨该维的切片大小);不规则维度中一个张量的大小是切片长度列表(跨该维的所有切片)。
广播示例
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
下面是一些不广播的形状示例:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Condition x == y did not hold. Indices of first 3 different values: [[1] [2] [3]] Corresponding x values: [ 4 8 12] Corresponding y values: [2 6 7] First 3 elements of x: [0 4 8] First 3 elements of y: [0 2 6]
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Condition x == y did not hold. Indices of first 2 different values: [[1] [3]] Corresponding x values: [3 6] Corresponding y values: [2 5] First 3 elements of x: [0 3 4] First 3 elements of y: [0 2 4]
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Condition x == y did not hold. Indices of first 3 different values: [[1] [2] [3]] Corresponding x values: [2 4 6] Corresponding y values: [3 6 9] First 3 elements of x: [0 2 4] First 3 elements of y: [0 3 6]
RaggedTensor 编码
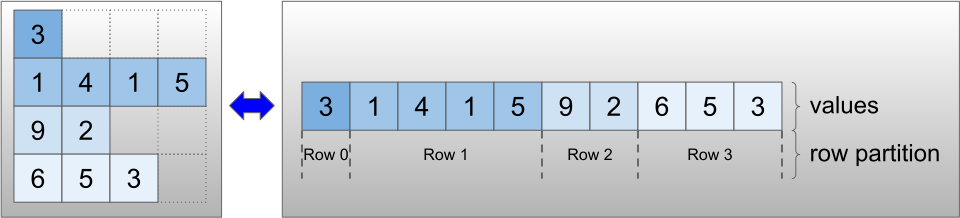
不规则张量使用 RaggedTensor 类进行编码。在内部,每个 RaggedTensor 包含:
- 一个
values张量,它将可变长度行连接成扁平列表。 - 一个
row_partition,它指示如何将这些扁平值分成各行。
可以使用四种不同的编码存储 row_partition:
row_splits是一个整型向量,用于指定行之间的拆分点。value_rowids是一个整型向量,用于指定每个值的行索引。row_lengths是一个整型向量,用于指定每一行的长度。uniform_row_length是一个整型标量,用于指定所有行的单个长度。
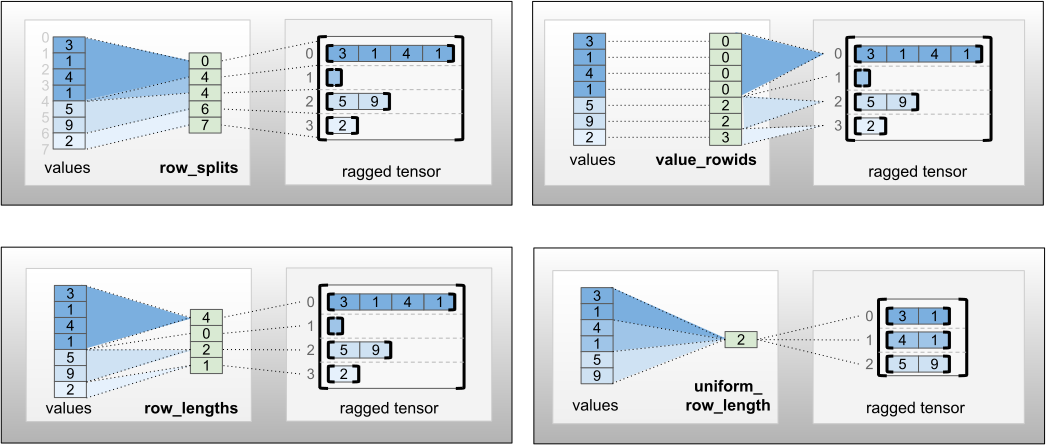
整型标量 nrows 还可以包含在 row_partition 编码中,以考虑具有 value_rowids 的空尾随行或具有 uniform_row_length 的空行。
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
选择为行分区使用哪种编码由不规则张量在内部进行管理,以提高某些环境下的效率。特别要指出的是,不同行分区方案的某些优点和缺点是:
- 高效索引:
row_splits编码可以实现不规则张量的恒定时间索引和切片。 - 高效连接:
row_lengths编码在连接不规则张量时更有效,因为当两个张量连接在一起时,行长度不会改变。 - 较小的编码大小:
value_rowids编码在存储具有大量空行的不规则张量时更有效,因为张量的大小只取决于值的总数。另一方面,row_splits和row_lengths编码在存储具有较长行的不规则张量时更有效,因为它们每行只需要一个标量值。 - 兼容性:
value_rowids方案与tf.segment_sum等运算使用的分段格式相匹配。row_limits方案与tf.sequence_mask等运算使用的格式相匹配。 - 均匀维:如下文所述,
uniform_row_length编码用于对具有均匀维的不规则张量进行编码。
多个不规则维度
具有多个不规则维度的不规则张量通过为 values 张量使用嵌套 RaggedTensor 进行编码。每个嵌套 RaggedTensor 都会增加一个不规则维度。
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
工厂函数 tf.RaggedTensor.from_nested_row_splits 可用于通过提供一个 row_splits 张量列表,直接构造具有多个不规则维度的 RaggedTensor:
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
不规则秩和扁平值
不规则张量的不规则秩是底层 values 张量的分区次数(即 RaggedTensor 对象的嵌套深度)。最内层的 values 张量称为其 flat_values。在以下示例中,conversations 具有 ragged_rank=3,其 flat_values 为具有 24 个字符串的一维 Tensor:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
均匀内层维度
具有均匀内层维度的不规则张量通过为 flat_values(即最内层 values)使用多维 tf.Tensor 进行编码。
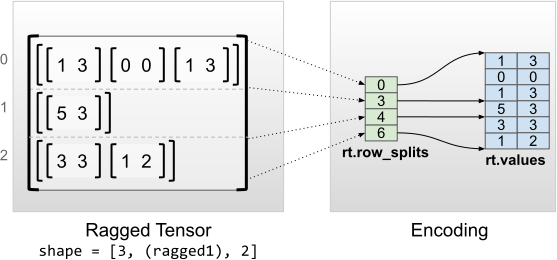
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3],
[0, 0],
[1, 3]], [[5, 3]], [[3, 3],
[1, 2]]]>
Shape: (3, None, 2)
Number of partitioned dimensions: 1
Flat values shape: (6, 2)
Flat values:
[[1 3]
[0 0]
[1 3]
[5 3]
[3 3]
[1 2]]
均匀非内层维度
具有均匀非内层维度的不规则张量通过使用 uniform_row_length 对行分区进行编码。
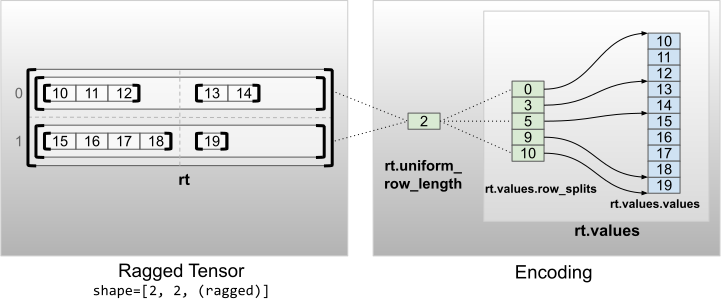
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2