
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
بررسی اجمالی
این آموزش مروری بر محدودیت ها و تنظیم کننده های ارائه شده توسط کتابخانه TensorFlow Lattice (TFL) است. در اینجا ما از برآوردگرهای کنسرو شده TFL در مجموعه داده های مصنوعی استفاده می کنیم، اما توجه داشته باشید که همه چیز در این آموزش را می توان با مدل های ساخته شده از لایه های TFL Keras نیز انجام داد.
قبل از ادامه، مطمئن شوید که زمان اجرا شما تمام بسته های مورد نیاز را نصب کرده است (همانطور که در سلول های کد زیر وارد شده است).
برپایی
نصب پکیج TF Lattice:
pip install -q tensorflow-lattice
واردات بسته های مورد نیاز:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
مقادیر پیش فرض استفاده شده در این راهنما:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
مجموعه داده های آموزشی برای رتبه بندی رستوران ها
یک سناریوی ساده را تصور کنید که در آن میخواهیم تعیین کنیم آیا کاربران روی نتیجه جستجوی رستوران کلیک میکنند یا خیر. وظیفه پیش بینی نرخ کلیک (CTR) با توجه به ویژگی های ورودی است:
- میانگین امتیاز (
avg_rating): یکی از ویژگی های عددی با ارزش در محدوده [1،5]. - تعدادی از بررسی (
num_reviews): یکی از ویژگی های عددی با ارزش پوش در 200، که ما به عنوان یک اقدام از trendiness استفاده کنید. - امتیاز دلار (
dollar_rating): یکی از ویژگی های طبقه با مقادیر رشته در مجموعه { "D"، "DD"، "DDD"، "DDDD"}.
در اینجا ما یک مجموعه داده مصنوعی ایجاد می کنیم که در آن CTR واقعی با فرمول داده می شود:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
که در آن \(b(\cdot)\) ترجمه هر dollar_rating به ارزش پایه:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
این فرمول الگوهای معمولی کاربر را منعکس می کند. به عنوان مثال، با توجه به رفع سایر موارد، کاربران رستورانهایی با رتبهبندی ستارههای بالاتر را ترجیح میدهند و رستورانهای "\$\$" کلیکهای بیشتری نسبت به "\$" دریافت میکنند و به دنبال آنها "\$\$\$" و "\$\$\$" کلیک میکنند. \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
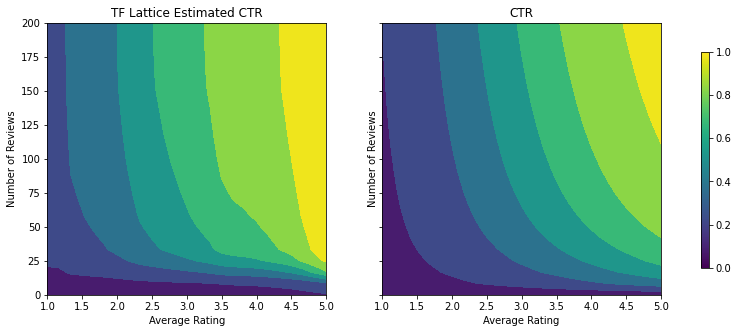
بیایید به نمودارهای کانتور این تابع CTR نگاهی بیندازیم.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
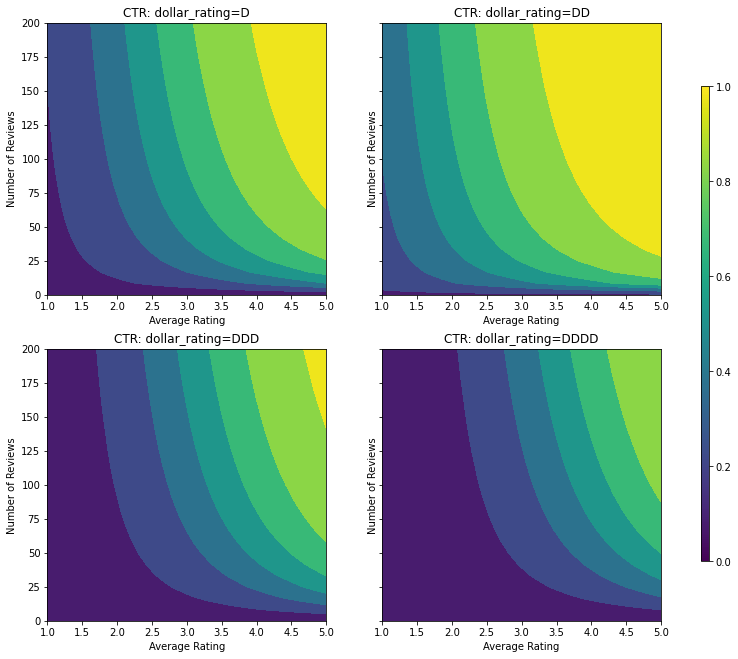
آماده سازی داده ها
اکنون باید مجموعه داده های مصنوعی خود را ایجاد کنیم. ما با تولید مجموعه داده های شبیه سازی شده از رستوران ها و ویژگی های آنها شروع می کنیم.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
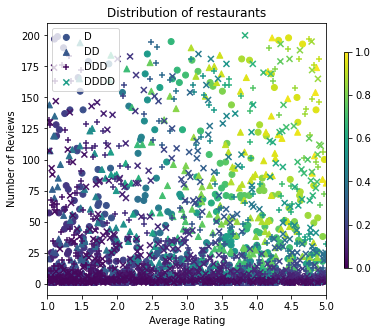
بیایید مجموعه داده های آموزش، اعتبار سنجی و آزمایش را تولید کنیم. هنگامی که یک رستوران در نتایج جستجو مشاهده می شود، می توانیم تعامل کاربر (کلیک یا بدون کلیک) را به عنوان یک نقطه نمونه ثبت کنیم.
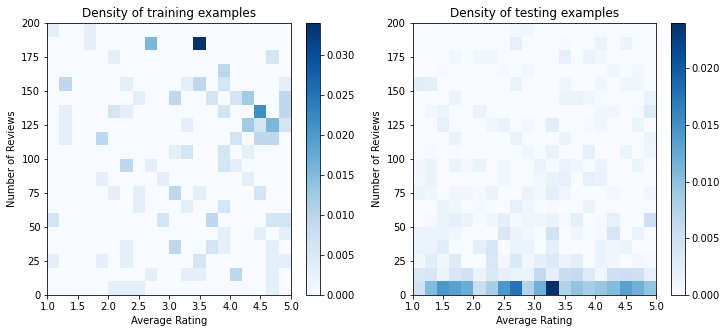
در عمل، کاربران اغلب از تمام نتایج جستجو عبور نمی کنند. این بدان معناست که کاربران احتمالاً فقط رستورانهایی را خواهند دید که قبلاً توسط مدل رتبهبندی فعلی در حال استفاده «خوب» در نظر گرفته شدهاند. در نتیجه، رستورانهای «خوب» بیشتر تحت تأثیر قرار میگیرند و بیش از حد در مجموعه دادههای آموزشی نشان داده میشوند. هنگام استفاده از ویژگیهای بیشتر، مجموعه داده آموزشی میتواند شکافهای بزرگی در بخشهای «بد» فضای ویژگی داشته باشد.
هنگامی که مدل برای رتبهبندی استفاده میشود، اغلب بر روی تمام نتایج مرتبط با توزیع یکنواختتر که به خوبی توسط مجموعه داده آموزشی نشان داده نمیشود، ارزیابی میشود. یک مدل انعطافپذیر و پیچیده ممکن است در این مورد به دلیل برازش بیش از حد نقاط دادهای که بیش از حد نشان داده شدهاند شکست بخورد و بنابراین قابلیت تعمیمپذیری ندارد. ما این موضوع را با استفاده از دامنه دانش به اضافه کردن محدودیت های شکل که راهنمای مدل به پیش بینی معقول هنگامی که می توانید آنها را از مجموعه داده ها آموزش انتخاب کنید تا مسئولیت رسیدگی به.
در این مثال مجموعه داده آموزشی بیشتر از تعاملات کاربر با رستوران های خوب و محبوب تشکیل شده است. مجموعه داده آزمایشی دارای توزیع یکنواخت برای شبیه سازی تنظیمات ارزیابی مورد بحث در بالا است. توجه داشته باشید که چنین مجموعه داده آزمایشی در یک تنظیم مشکل واقعی در دسترس نخواهد بود.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
تعریف input_fns مورد استفاده برای آموزش و ارزیابی:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
تناسب درختان با گرادیان تقویت شده
بیایید شروع کردن با تنها دو ویژگی است: avg_rating و num_reviews .
ما چند تابع کمکی برای رسم و محاسبه اعتبارسنجی و معیارهای تست ایجاد می کنیم.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
میتوانیم درختهای تصمیم تقویتشده با گرادیان TensorFlow را در مجموعه داده قرار دهیم:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
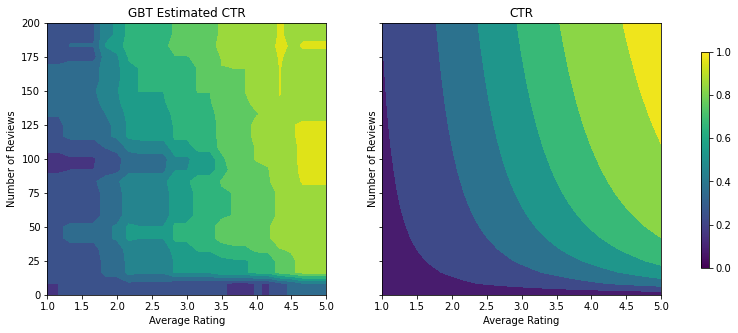
حتی اگر این مدل شکل کلی CTR واقعی را دریافت کرده و دارای معیارهای اعتبارسنجی مناسبی است، در چندین بخش از فضای ورودی رفتاری ضد شهودی دارد: با افزایش میانگین رتبهبندی یا تعداد مرورها، CTR تخمینی کاهش مییابد. این به دلیل کمبود نقاط نمونه در مناطقی است که به خوبی توسط مجموعه داده آموزشی پوشش داده نشده است. مدل به سادگی راهی برای استنباط رفتار صحیح صرفاً از داده ها ندارد.
برای حل این مسئله، محدودیت شکل را اعمال میکنیم که مدل باید مقادیر خروجی را به طور یکنواخت با توجه به میانگین رتبهبندی و تعداد بررسیها افزایش دهد. بعداً خواهیم دید که چگونه این را در TFL پیاده سازی کنیم.
نصب DNN
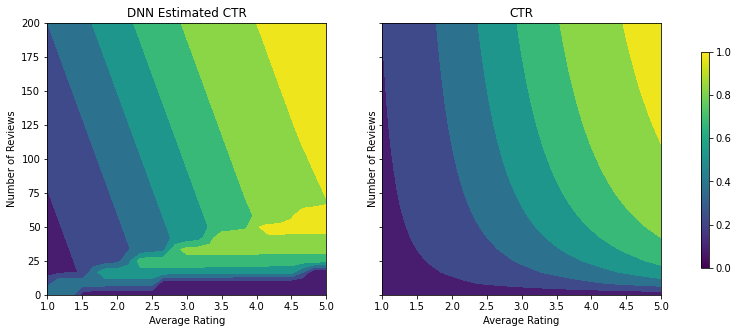
می توانیم همان مراحل را با یک طبقه بندی کننده DNN تکرار کنیم. ما میتوانیم الگوی مشابهی را مشاهده کنیم: نداشتن نقاط نمونه کافی با تعداد کم مرورها منجر به برونیابی بیمعنی میشود. توجه داشته باشید که حتی اگر معیار اعتبار سنجی بهتر از راه حل درختی است، متریک آزمایش بسیار بدتر است.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
محدودیت های شکل
شبکه TensorFlow (TFL) بر اعمال محدودیتهای شکل برای محافظت از رفتار مدل فراتر از دادههای آموزشی متمرکز است. این محدودیت های شکل برای لایه های TFL Keras اعمال می شود. اطلاعات مربوط به آنها را می توان در یافت مقاله JMLR ما .
در این آموزش ما از برآوردگرهای کنسرو TF برای پوشش محدودیتهای شکل مختلف استفاده میکنیم، اما توجه داشته باشید که تمام این مراحل را میتوان با مدلهای ایجاد شده از لایههای TFL Keras انجام داد.
همانطور که با هر برآوردگر TensorFlow دیگر، TFL کنسرو برآوردگرهای استفاده ستون ویژگی برای تعریف فرمت ورودی و استفاده از یک input_fn آموزش در رابطه با در داده ها. استفاده از برآوردگرهای کنسرو شده TFL همچنین به موارد زیر نیاز دارد:
- پیکربندی مدل: تعریف معماری مدل و هر ویژگی محدودیت شکل و regularizers.
- input_fn تجزیه و تحلیل ویژگی های: یک TF input_fn عبور داده برای مقدار دهی اولیه TFL.
برای توضیحات کاملتر، لطفاً به آموزش تخمینگرهای کنسرو شده یا اسناد API مراجعه کنید.
یکنواختی
ابتدا نگرانی های یکنواختی را با افزودن قیود شکل یکنواختی به هر دو ویژگی برطرف می کنیم.
به دستور TFL برای به اجرا درآوردن محدودیت شکل، ما محدودیت در تنظیمات ویژگی را مشخص کنید. کد نشان می دهد زیر چگونه ما می توانیم خروجی نیاز به یکنواخت با توجه به هر دو افزایش num_reviews و avg_rating با تنظیم monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
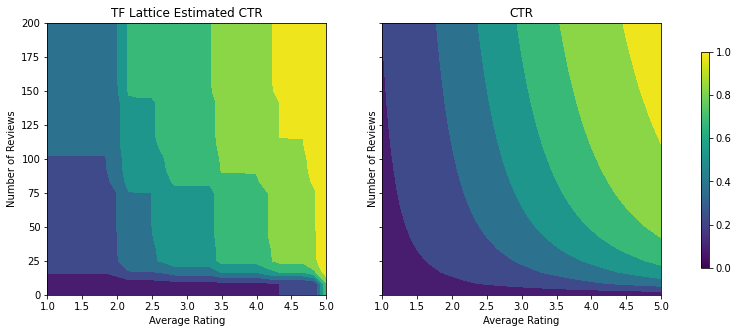
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
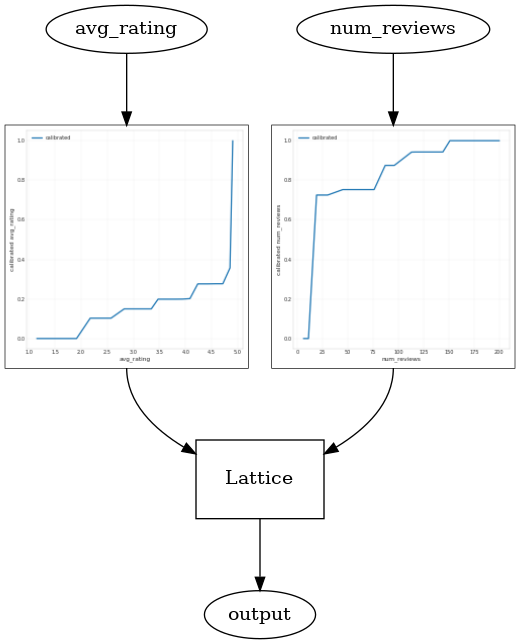
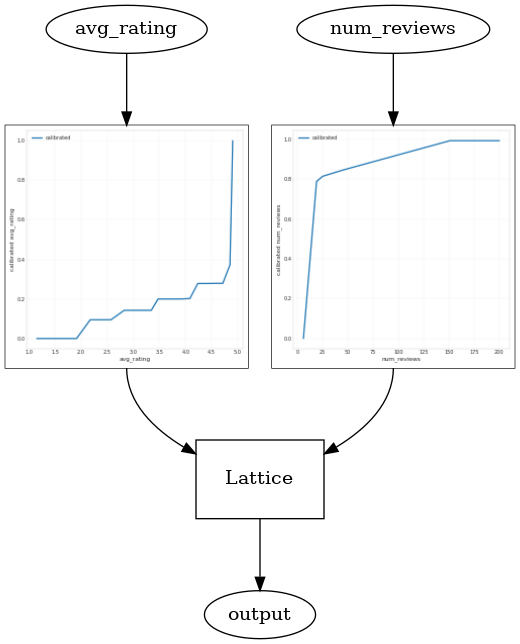
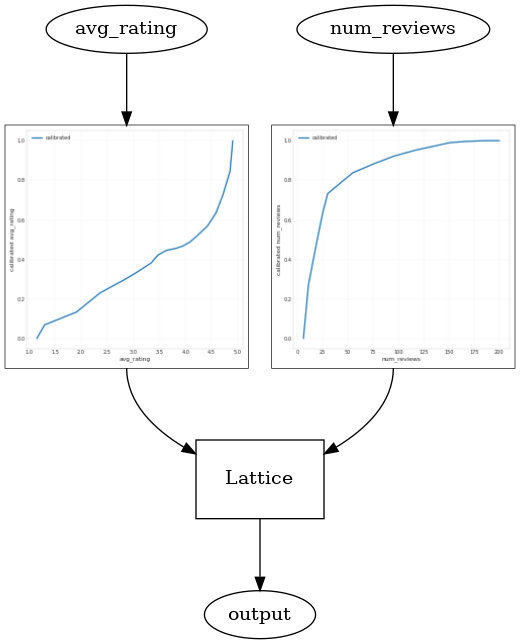
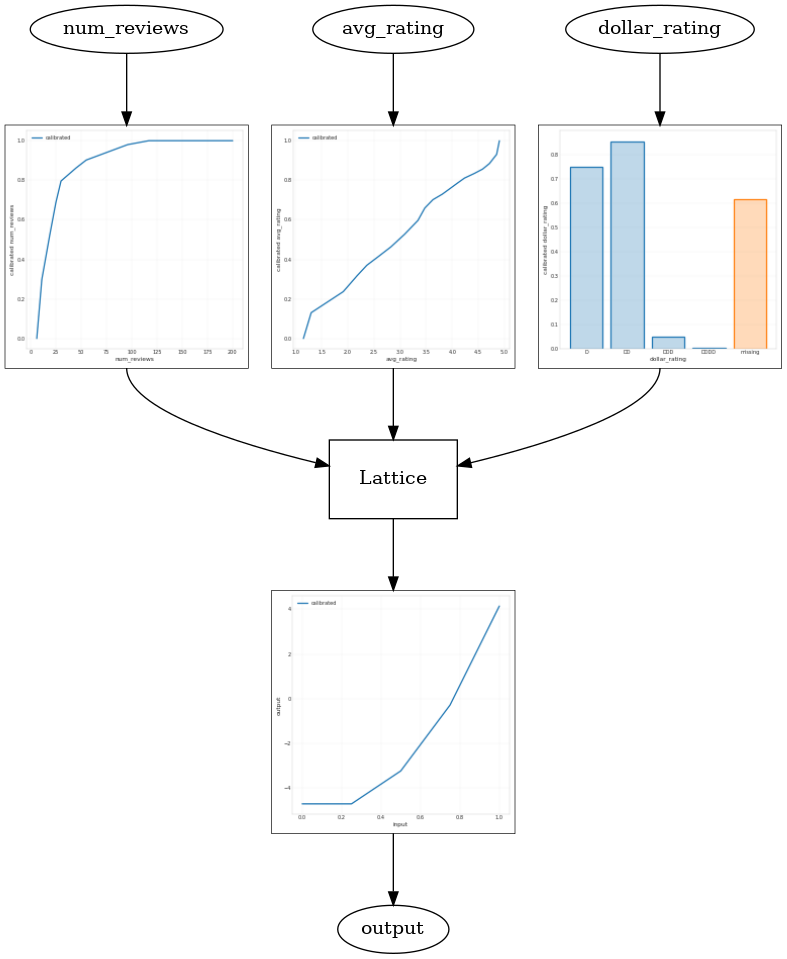
با استفاده از یک CalibratedLatticeConfig ایجاد یک طبقه بندی کنسرو که برای اولین بار از یک کالیبراتور برای هر ورودی (یک تابع خطی قطعه و زرنگ است برای ویژگی های عددی) اعمال می شود دنبال آن یک لایه شبکه به صورت غیر خطی فیوز ویژگی های کالیبره شده است. ما می توانید استفاده کنید tfl.visualization به تجسم مدل. به طور خاص، نمودار زیر دو کالیبراتور آموزش دیده موجود در طبقه بندی کنسرو را نشان می دهد.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
با اضافه شدن محدودیتها، CTR تخمینی همیشه با افزایش میانگین رتبهبندی یا افزایش تعداد بررسیها افزایش مییابد. این کار با اطمینان از یکنواخت بودن کالیبراتورها و شبکه انجام می شود.
کاهش بازده
کاهش بازده بدان معنی است که افزایش حاشیه ای از افزایش ارزش از ویژگی های خاص کاهش می یابد به عنوان ما ارزش را افزایش دهد. در مورد ما انتظار داریم که num_reviews ویژگی زیر این الگو، بنابراین ما می توانیم کالیبراتور خود را براساس آن را پیکربندی کنید. توجه داشته باشید که ما می توانیم بازده کاهشی را به دو شرط کافی تجزیه کنیم:
- کالیبراتور به طور یکنواخت در حال افزایش است و
- کالیبراتور مقعر است
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
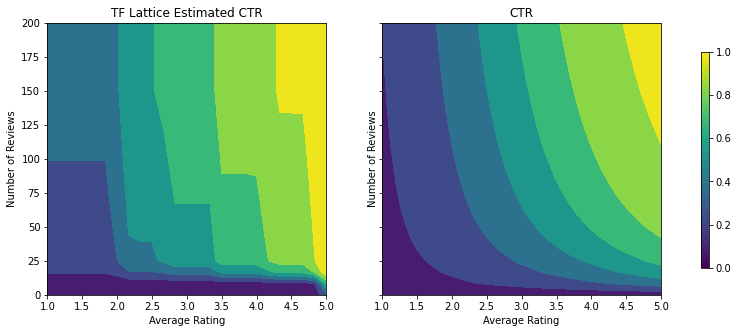
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
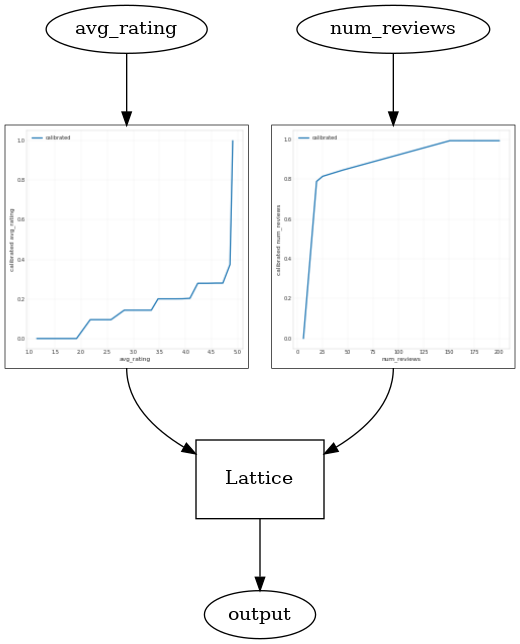
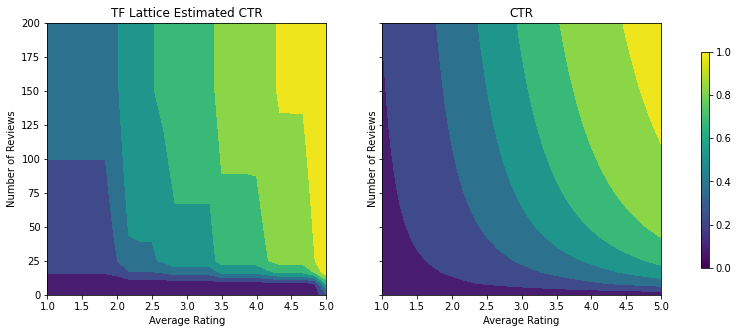
توجه کنید که چگونه متریک آزمایش با افزودن محدودیت تقعر بهبود می یابد. طرح پیش بینی نیز بهتر به حقیقت زمین شباهت دارد.
محدودیت شکل دو بعدی: اعتماد
رتبه بندی 5 ستاره برای رستورانی که فقط یک یا دو نظر داشته باشد احتمالاً یک رتبه غیرقابل اعتماد است (رستوران ممکن است در واقع خوب نباشد)، در حالی که رتبه 4 ستاره برای رستورانی با صدها نظر بسیار قابل اعتمادتر است (رستوران احتمالاً در این مورد خوب است). می بینیم که تعداد نظرات یک رستوران بر میزان اعتماد ما به میانگین امتیاز آن رستوران تأثیر می گذارد.
میتوانیم محدودیتهای اعتماد TFL را اعمال کنیم تا به مدل اطلاع دهیم که مقدار بزرگتر (یا کوچکتر) یک ویژگی نشاندهنده اتکا یا اعتماد بیشتر به ویژگی دیگر است. این است که با تنظیم انجام reflects_trust_in پیکربندی در پیکربندی ویژگی.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
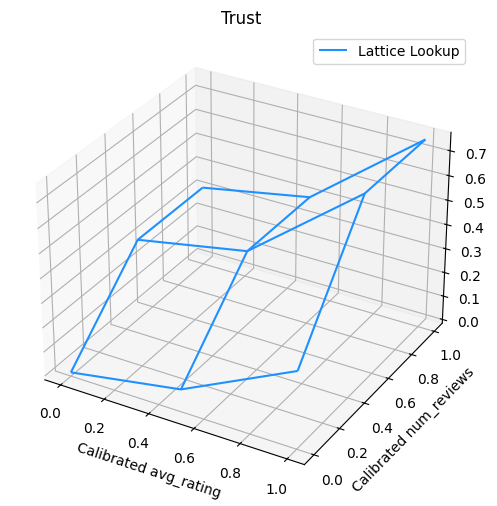
نمودار زیر تابع شبکه آموزش دیده را نشان می دهد. با توجه به محدودیت اعتماد، ما انتظار داریم که مقادیر بزرگتر کالیبره num_reviews می شیب بالاتر با توجه به کالیبره مجبور avg_rating ، و در نتیجه یک حرکت قابل توجه تری در خروجی شبکه.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
کالیبراتورهای صاف کننده
اکنون بیایید نگاهی به کالیبراتور از را avg_rating . اگرچه به طور یکنواخت در حال افزایش است، تغییرات در شیب آن ناگهانی است و تفسیر آن دشوار است. این نشان می دهد ما ممکن است بخواهید در صاف کردن این کالیبراتور با استفاده از تنظیم تنظیم کننده در regularizer_configs .
در اینجا ما یک درخواست wrinkle تنظیم کننده برای کاهش تغییرات در انحنای. شما همچنین می توانید با استفاده از laplacian تنظیم کننده به پهن کردن کالیبراتور و hessian تنظیم کننده، آن را به خطی تر است.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
کالیبراتورها اکنون صاف هستند و CTR کلی تخمین زده شده بهتر با حقیقت زمین مطابقت دارد. این هم در متریک آزمایش و هم در نمودارهای کانتور منعکس می شود.
یکنواختی جزئی برای کالیبراسیون دسته بندی
تاکنون تنها از دو ویژگی عددی در مدل استفاده کرده ایم. در اینجا ما یک ویژگی سوم را با استفاده از یک لایه کالیبراسیون طبقهبندی اضافه میکنیم. دوباره با تنظیم توابع کمکی برای رسم و محاسبه متریک شروع می کنیم.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
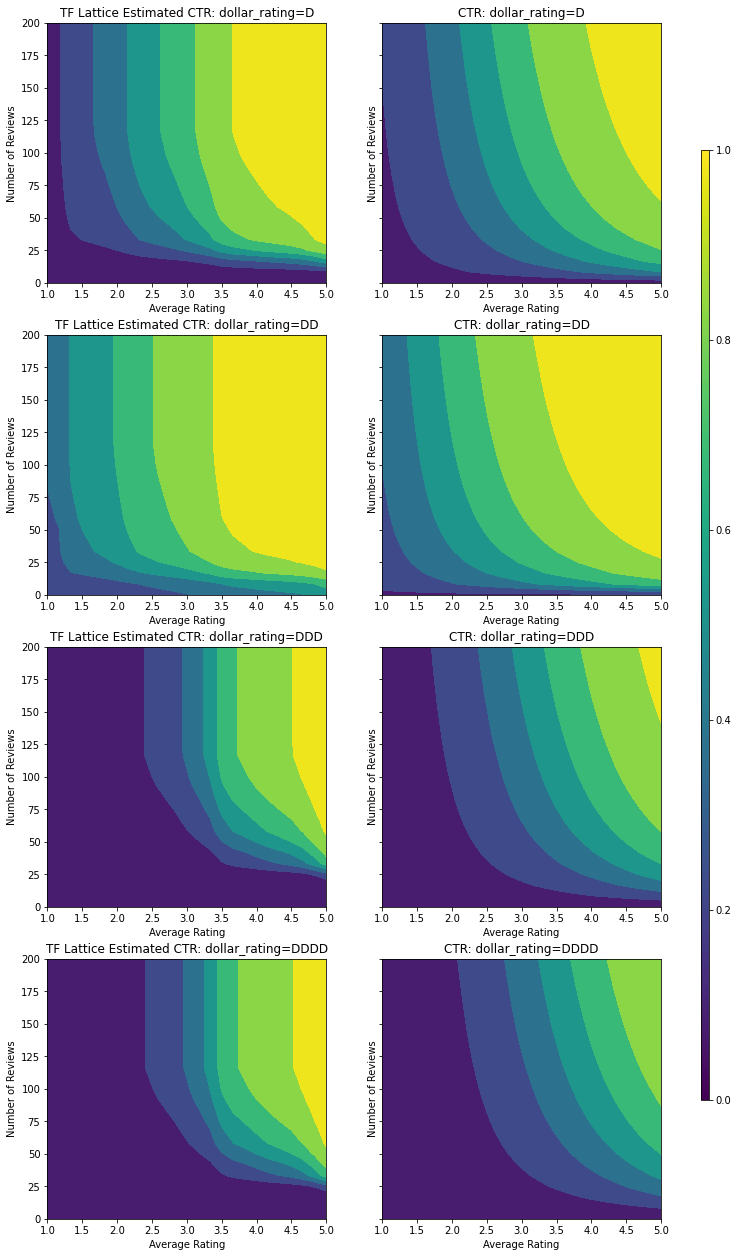
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
به شامل ویژگی سوم، dollar_rating ، ما باید به یاد بیاوریم که امکانات طبقه نیاز به یک درمان کمی متفاوت در TFL، هر دو به عنوان یک ستون از ویژگی های و به عنوان یک پیکربندی ویژگی. در اینجا ما محدودیت یکنواختی جزئی را اعمال میکنیم که خروجیهای رستورانهای «DD» باید بزرگتر از رستورانهای «D» باشد، وقتی همه ورودیهای دیگر ثابت هستند. این کار با انجام monotonicity تنظیم در پیکربندی ویژگی.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
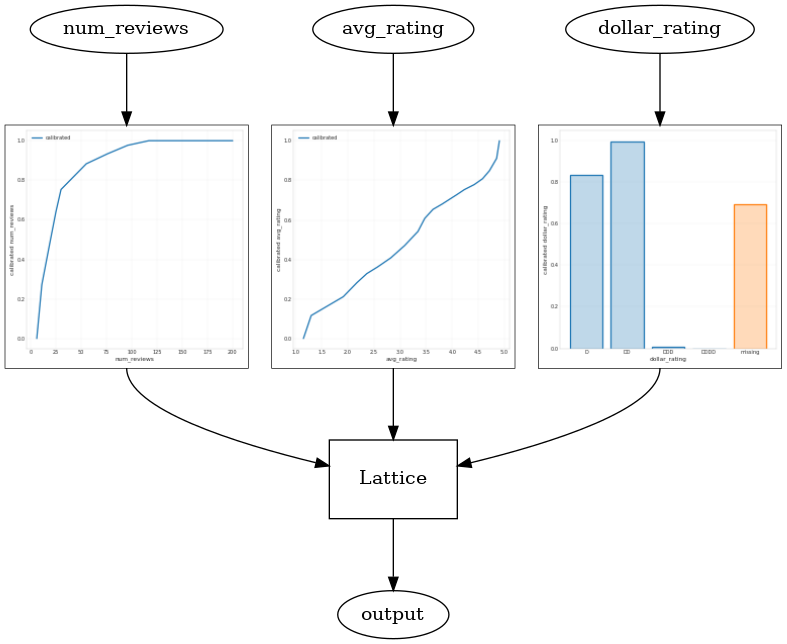
این کالیبراتور طبقه بندی ترجیح خروجی مدل را نشان می دهد: DD > D > DDD > DDDD، که با تنظیمات ما سازگار است. توجه داشته باشید که ستونی برای مقادیر از دست رفته نیز وجود دارد. اگرچه هیچ ویژگی گمشده ای در داده های آموزشی و آزمایشی ما وجود ندارد، این مدل در صورتی که در طول سرویس دهی مدل پایین دستی اتفاق بیفتد، مقدار گمشده را در اختیار ما قرار می دهد.
در اینجا ما نیز CTR پیش بینی این مدل مشروط بر رسم dollar_rating . توجه داشته باشید که تمام محدودیت های مورد نیاز در هر یک از برش ها برآورده شده است.
کالیبراسیون خروجی
برای تمام مدلهای TFL که تا کنون آموزش دادهایم، لایه شبکه (که در نمودار مدل به عنوان "شبکه" نشان داده شده است) مستقیماً پیشبینی مدل را خروجی میدهد. گاهی اوقات ما مطمئن نیستیم که آیا خروجی شبکه باید تغییر مقیاس داده شود تا خروجی های مدل منتشر شود:
- ویژگی های می باشد \(log\) شمارش در حالی که برچسب شمارش هستند.
- شبکه طوری پیکربندی شده است که رئوس بسیار کمی داشته باشد اما توزیع برچسب نسبتاً پیچیده است.
در این موارد میتوانیم کالیبراتور دیگری بین خروجی شبکه و خروجی مدل اضافه کنیم تا انعطافپذیری مدل را افزایش دهیم. در اینجا اجازه دهید یک لایه کالیبراتور با 5 نقطه کلیدی را به مدلی که ساخته ایم اضافه کنیم. ما همچنین یک تنظیم کننده برای کالیبراتور خروجی اضافه می کنیم تا عملکرد را صاف نگه دارد.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
متریک و نمودارهای آزمایش نهایی نشان میدهند که چگونه استفاده از محدودیتهای عقل سلیم میتواند به مدل کمک کند از رفتار غیرمنتظره اجتناب کند و به کل فضای ورودی بهتر تعمیم یابد.
،| | | مشاهده منبع در GitHub | |
بررسی اجمالی
این آموزش مروری بر محدودیت ها و تنظیم کننده های ارائه شده توسط کتابخانه TensorFlow Lattice (TFL) است. در اینجا ما از برآوردگرهای کنسرو شده TFL در مجموعه داده های مصنوعی استفاده می کنیم، اما توجه داشته باشید که همه چیز در این آموزش را می توان با مدل های ساخته شده از لایه های TFL Keras نیز انجام داد.
قبل از ادامه، مطمئن شوید که زمان اجرا شما تمام بسته های مورد نیاز را نصب کرده است (همانطور که در سلول های کد زیر وارد شده است).
برپایی
نصب پکیج TF Lattice:
pip install -q tensorflow-lattice
واردات بسته های مورد نیاز:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
مقادیر پیش فرض استفاده شده در این راهنما:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
مجموعه داده های آموزشی برای رتبه بندی رستوران ها
یک سناریوی ساده را تصور کنید که در آن میخواهیم تعیین کنیم آیا کاربران روی نتیجه جستجوی رستوران کلیک میکنند یا خیر. وظیفه پیش بینی نرخ کلیک (CTR) با توجه به ویژگی های ورودی است:
- میانگین امتیاز (
avg_rating): یکی از ویژگی های عددی با ارزش در محدوده [1،5]. - تعدادی از بررسی (
num_reviews): یکی از ویژگی های عددی با ارزش پوش در 200، که ما به عنوان یک اقدام از trendiness استفاده کنید. - امتیاز دلار (
dollar_rating): یکی از ویژگی های طبقه با مقادیر رشته در مجموعه { "D"، "DD"، "DDD"، "DDDD"}.
در اینجا ما یک مجموعه داده مصنوعی ایجاد می کنیم که در آن CTR واقعی با فرمول داده می شود:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
که در آن \(b(\cdot)\) ترجمه هر dollar_rating به ارزش پایه:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
این فرمول الگوهای معمولی کاربر را منعکس می کند. به عنوان مثال، با توجه به رفع سایر موارد، کاربران رستورانهایی با رتبهبندی ستارههای بالاتر را ترجیح میدهند و رستورانهای "\$\$" کلیکهای بیشتری نسبت به "\$" دریافت میکنند و به دنبال آنها "\$\$\$" و "\$\$\$" کلیک میکنند. \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
بیایید به نمودارهای کانتور این تابع CTR نگاهی بیندازیم.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
آماده سازی داده ها
اکنون باید مجموعه داده های مصنوعی خود را ایجاد کنیم. ما با تولید مجموعه داده های شبیه سازی شده از رستوران ها و ویژگی های آنها شروع می کنیم.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
بیایید مجموعه داده های آموزش، اعتبار سنجی و آزمایش را تولید کنیم. هنگامی که یک رستوران در نتایج جستجو مشاهده می شود، می توانیم تعامل کاربر (کلیک یا بدون کلیک) را به عنوان یک نقطه نمونه ثبت کنیم.
در عمل، کاربران اغلب از تمام نتایج جستجو عبور نمی کنند. این بدان معناست که کاربران احتمالاً فقط رستورانهایی را خواهند دید که قبلاً توسط مدل رتبهبندی فعلی در حال استفاده «خوب» در نظر گرفته شدهاند. در نتیجه، رستورانهای «خوب» بیشتر تحت تأثیر قرار میگیرند و بیش از حد در مجموعه دادههای آموزشی نشان داده میشوند. هنگام استفاده از ویژگیهای بیشتر، مجموعه داده آموزشی میتواند شکافهای بزرگی در بخشهای «بد» فضای ویژگی داشته باشد.
هنگامی که مدل برای رتبهبندی استفاده میشود، اغلب بر روی تمام نتایج مرتبط با توزیع یکنواختتر که به خوبی توسط مجموعه داده آموزشی نشان داده نمیشود، ارزیابی میشود. یک مدل انعطافپذیر و پیچیده ممکن است در این مورد به دلیل برازش بیش از حد نقاط دادهای که بیش از حد نشان داده شدهاند شکست بخورد و بنابراین قابلیت تعمیمپذیری ندارد. ما این موضوع را با استفاده از دامنه دانش به اضافه کردن محدودیت های شکل که راهنمای مدل به پیش بینی معقول هنگامی که می توانید آنها را از مجموعه داده ها آموزش انتخاب کنید تا مسئولیت رسیدگی به.
در این مثال مجموعه داده آموزشی بیشتر از تعاملات کاربر با رستوران های خوب و محبوب تشکیل شده است. مجموعه داده آزمایشی دارای توزیع یکنواخت برای شبیه سازی تنظیمات ارزیابی مورد بحث در بالا است. توجه داشته باشید که چنین مجموعه داده آزمایشی در یک تنظیم مشکل واقعی در دسترس نخواهد بود.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
تعریف input_fns مورد استفاده برای آموزش و ارزیابی:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
تناسب درختان با گرادیان تقویت شده
بیایید شروع کردن با تنها دو ویژگی است: avg_rating و num_reviews .
ما چند تابع کمکی برای رسم و محاسبه اعتبارسنجی و معیارهای تست ایجاد می کنیم.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
میتوانیم درختهای تصمیم تقویتشده با گرادیان TensorFlow را در مجموعه داده قرار دهیم:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
حتی اگر این مدل شکل کلی CTR واقعی را دریافت کرده و دارای معیارهای اعتبارسنجی مناسبی است، در چندین بخش از فضای ورودی رفتاری ضد شهودی دارد: با افزایش میانگین رتبهبندی یا تعداد مرورها، CTR تخمینی کاهش مییابد. این به دلیل کمبود نقاط نمونه در مناطقی است که به خوبی توسط مجموعه داده آموزشی پوشش داده نشده است. مدل به سادگی راهی برای استنباط رفتار صحیح صرفاً از داده ها ندارد.
برای حل این مسئله، محدودیت شکل را اعمال میکنیم که مدل باید مقادیر خروجی را به طور یکنواخت با توجه به میانگین رتبهبندی و تعداد بررسیها افزایش دهد. بعداً خواهیم دید که چگونه این را در TFL پیاده سازی کنیم.
نصب DNN
می توانیم همان مراحل را با یک طبقه بندی کننده DNN تکرار کنیم. ما میتوانیم الگوی مشابهی را مشاهده کنیم: نداشتن نقاط نمونه کافی با تعداد کم مرورها منجر به برونیابی بیمعنی میشود. توجه داشته باشید که حتی اگر معیار اعتبار سنجی بهتر از راه حل درختی است، متریک آزمایش بسیار بدتر است.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
محدودیت های شکل
شبکه TensorFlow (TFL) بر اعمال محدودیتهای شکل برای محافظت از رفتار مدل فراتر از دادههای آموزشی متمرکز است. این محدودیت های شکل برای لایه های TFL Keras اعمال می شود. اطلاعات مربوط به آنها را می توان در یافت مقاله JMLR ما .
در این آموزش ما از برآوردگرهای کنسرو TF برای پوشش محدودیتهای شکل مختلف استفاده میکنیم، اما توجه داشته باشید که تمام این مراحل را میتوان با مدلهای ایجاد شده از لایههای TFL Keras انجام داد.
همانطور که با هر برآوردگر TensorFlow دیگر، TFL کنسرو برآوردگرهای استفاده ستون ویژگی برای تعریف فرمت ورودی و استفاده از یک input_fn آموزش در رابطه با در داده ها. استفاده از برآوردگرهای کنسرو شده TFL همچنین به موارد زیر نیاز دارد:
- پیکربندی مدل: تعریف معماری مدل و هر ویژگی محدودیت شکل و regularizers.
- input_fn تجزیه و تحلیل ویژگی های: یک TF input_fn عبور داده برای مقدار دهی اولیه TFL.
برای توضیحات کاملتر، لطفاً به آموزش تخمینگرهای کنسرو شده یا اسناد API مراجعه کنید.
یکنواختی
ابتدا نگرانی های یکنواختی را با افزودن قیود شکل یکنواختی به هر دو ویژگی برطرف می کنیم.
به دستور TFL برای به اجرا درآوردن محدودیت شکل، ما محدودیت در تنظیمات ویژگی را مشخص کنید. کد نشان می دهد زیر چگونه ما می توانیم خروجی نیاز به یکنواخت با توجه به هر دو افزایش num_reviews و avg_rating با تنظیم monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
با استفاده از یک CalibratedLatticeConfig ایجاد یک طبقه بندی کنسرو که برای اولین بار از یک کالیبراتور برای هر ورودی (یک تابع خطی قطعه و زرنگ است برای ویژگی های عددی) اعمال می شود دنبال آن یک لایه شبکه به صورت غیر خطی فیوز ویژگی های کالیبره شده است. ما می توانید استفاده کنید tfl.visualization به تجسم مدل. به طور خاص، نمودار زیر دو کالیبراتور آموزش دیده موجود در طبقه بندی کنسرو را نشان می دهد.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
با اضافه شدن محدودیتها، CTR تخمینی همیشه با افزایش میانگین رتبهبندی یا افزایش تعداد بررسیها افزایش مییابد. این کار با اطمینان از یکنواخت بودن کالیبراتورها و شبکه انجام می شود.
کاهش بازده
کاهش بازده بدان معنی است که افزایش حاشیه ای از افزایش ارزش از ویژگی های خاص کاهش می یابد به عنوان ما ارزش را افزایش دهد. در مورد ما انتظار داریم که num_reviews ویژگی زیر این الگو، بنابراین ما می توانیم کالیبراتور خود را براساس آن را پیکربندی کنید. توجه داشته باشید که ما می توانیم بازده کاهشی را به دو شرط کافی تجزیه کنیم:
- کالیبراتور به طور یکنواخت در حال افزایش است و
- کالیبراتور مقعر است
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
توجه کنید که چگونه متریک آزمایش با افزودن محدودیت تقعر بهبود می یابد. طرح پیش بینی نیز بهتر به حقیقت زمین شباهت دارد.
محدودیت شکل دو بعدی: اعتماد
رتبه بندی 5 ستاره برای رستورانی که فقط یک یا دو نظر داشته باشد احتمالاً یک رتبه غیرقابل اعتماد است (رستوران ممکن است در واقع خوب نباشد)، در حالی که رتبه 4 ستاره برای رستورانی با صدها نظر بسیار قابل اعتمادتر است (رستوران احتمالاً در این مورد خوب است). می بینیم که تعداد نظرات یک رستوران بر میزان اعتماد ما به میانگین امتیاز آن رستوران تأثیر می گذارد.
میتوانیم محدودیتهای اعتماد TFL را اعمال کنیم تا به مدل اطلاع دهیم که مقدار بزرگتر (یا کوچکتر) یک ویژگی نشاندهنده اتکا یا اعتماد بیشتر به ویژگی دیگر است. این است که با تنظیم انجام reflects_trust_in پیکربندی در پیکربندی ویژگی.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
نمودار زیر تابع شبکه آموزش دیده را نشان می دهد. با توجه به محدودیت اعتماد، ما انتظار داریم که مقادیر بزرگتر کالیبره num_reviews می شیب بالاتر با توجه به کالیبره مجبور avg_rating ، و در نتیجه یک حرکت قابل توجه تری در خروجی شبکه.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
کالیبراتورهای صاف کننده
اکنون بیایید نگاهی به کالیبراتور از را avg_rating . اگرچه به طور یکنواخت در حال افزایش است، تغییرات در شیب آن ناگهانی است و تفسیر آن دشوار است. این نشان می دهد ما ممکن است بخواهید در صاف کردن این کالیبراتور با استفاده از تنظیم تنظیم کننده در regularizer_configs .
در اینجا ما یک درخواست wrinkle تنظیم کننده برای کاهش تغییرات در انحنای. شما همچنین می توانید با استفاده از laplacian تنظیم کننده به پهن کردن کالیبراتور و hessian تنظیم کننده، آن را به خطی تر است.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
کالیبراتورها اکنون صاف هستند و CTR کلی تخمین زده شده بهتر با حقیقت زمین مطابقت دارد. این هم در متریک آزمایش و هم در نمودارهای کانتور منعکس می شود.
یکنواختی جزئی برای کالیبراسیون دسته بندی
تاکنون تنها از دو ویژگی عددی در مدل استفاده کرده ایم. در اینجا ما یک ویژگی سوم را با استفاده از یک لایه کالیبراسیون طبقهبندی اضافه میکنیم. دوباره با تنظیم توابع کمکی برای رسم و محاسبه متریک شروع می کنیم.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
به شامل ویژگی سوم، dollar_rating ، ما باید به یاد بیاوریم که امکانات طبقه نیاز به یک درمان کمی متفاوت در TFL، هر دو به عنوان یک ستون از ویژگی های و به عنوان یک پیکربندی ویژگی. در اینجا ما محدودیت یکنواختی جزئی را اعمال میکنیم که خروجیهای رستورانهای «DD» باید بزرگتر از رستورانهای «D» باشد، وقتی همه ورودیهای دیگر ثابت هستند. این کار با انجام monotonicity تنظیم در پیکربندی ویژگی.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
این کالیبراتور طبقه بندی ترجیح خروجی مدل را نشان می دهد: DD > D > DDD > DDDD، که با تنظیمات ما سازگار است. توجه داشته باشید که ستونی برای مقادیر از دست رفته نیز وجود دارد. اگرچه هیچ ویژگی گمشده ای در داده های آموزشی و آزمایشی ما وجود ندارد، این مدل در صورتی که در طول سرویس دهی مدل پایین دستی اتفاق بیفتد، مقدار گمشده را در اختیار ما قرار می دهد.
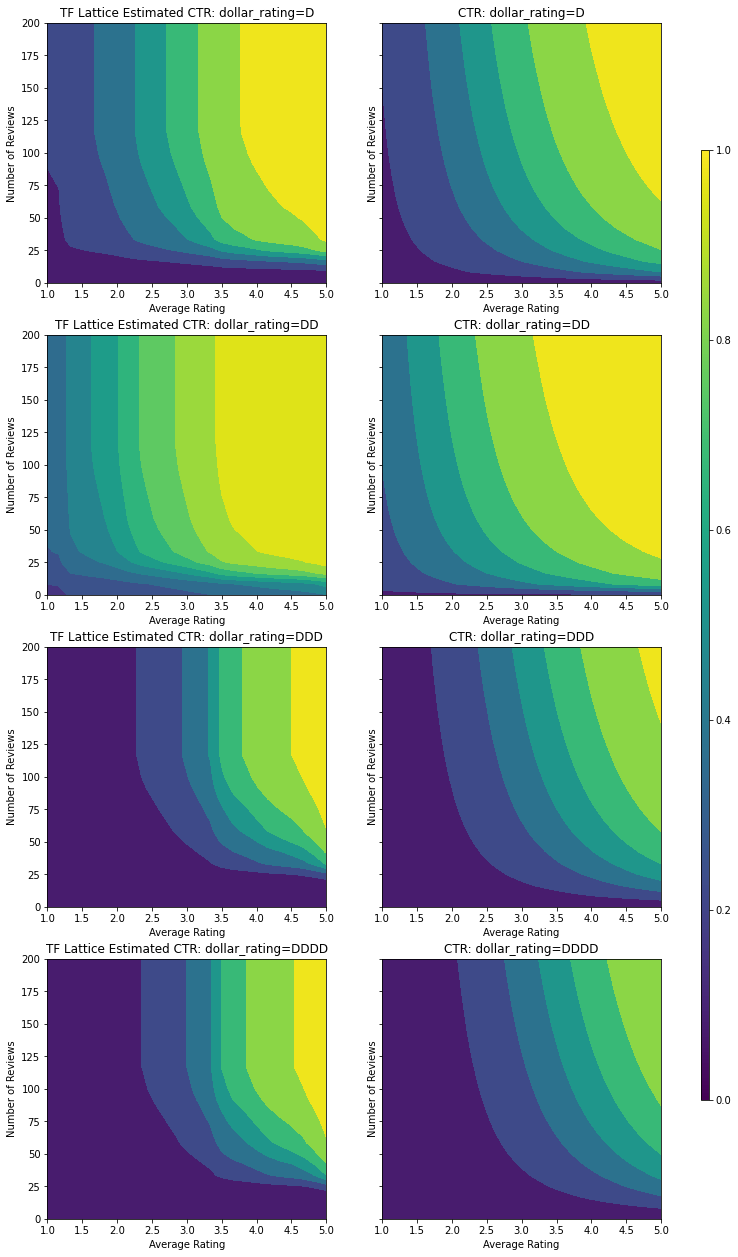
در اینجا ما نیز CTR پیش بینی این مدل مشروط بر رسم dollar_rating . توجه داشته باشید که تمام محدودیت های مورد نیاز در هر یک از برش ها برآورده شده است.
کالیبراسیون خروجی
برای تمام مدلهای TFL که تا کنون آموزش دادهایم، لایه شبکه (که در نمودار مدل به عنوان "شبکه" نشان داده شده است) مستقیماً پیشبینی مدل را خروجی میدهد. گاهی اوقات ما مطمئن نیستیم که آیا خروجی شبکه باید تغییر مقیاس داده شود تا خروجی های مدل منتشر شود:
- ویژگی های می باشد \(log\) شمارش در حالی که برچسب شمارش هستند.
- شبکه طوری پیکربندی شده است که رئوس بسیار کمی داشته باشد اما توزیع برچسب نسبتاً پیچیده است.
در این موارد میتوانیم کالیبراتور دیگری بین خروجی شبکه و خروجی مدل اضافه کنیم تا انعطافپذیری مدل را افزایش دهیم. در اینجا اجازه دهید یک لایه کالیبراتور با 5 نقطه کلیدی را به مدلی که ساخته ایم اضافه کنیم. ما همچنین یک تنظیم کننده برای کالیبراتور خروجی اضافه می کنیم تا عملکرد را صاف نگه دارد.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
متریک و نمودارهای آزمایش نهایی نشان میدهند که چگونه استفاده از محدودیتهای عقل سلیم میتواند به مدل کمک کند از رفتار غیرمنتظره اجتناب کند و به کل فضای ورودی بهتر تعمیم یابد.