
این آموزش به شما نشان می دهد که چگونه با استفاده از TensorFlow Lite یک برنامه اندروید بسازید تا متن زبان طبیعی را طبقه بندی کنید. این برنامه برای یک دستگاه اندروید فیزیکی طراحی شده است اما می تواند بر روی شبیه ساز دستگاه نیز اجرا شود.
برنامه مثال از TensorFlow Lite برای طبقه بندی متن به عنوان مثبت یا منفی استفاده می کند و از کتابخانه Task برای زبان طبیعی (NL) برای فعال کردن اجرای مدل های یادگیری ماشینی طبقه بندی متن استفاده می کند.
اگر یک پروژه موجود را به روز می کنید، می توانید از برنامه نمونه به عنوان مرجع یا الگو استفاده کنید. برای دستورالعملهایی درباره نحوه افزودن طبقهبندی متن به یک برنامه موجود، به بهروزرسانی و اصلاح برنامه خود مراجعه کنید.
نمای کلی طبقه بندی متن
طبقه بندی متن، وظیفه یادگیری ماشینی است که مجموعه ای از دسته بندی های از پیش تعریف شده را به متن باز اختصاص می دهد. یک مدل طبقهبندی متن بر روی مجموعهای از متن زبان طبیعی آموزش داده میشود، جایی که کلمات یا عبارات به صورت دستی طبقهبندی میشوند.
مدل آموزش دیده متن را به عنوان ورودی دریافت می کند و سعی می کند متن را بر اساس مجموعه کلاس های شناخته شده ای که برای طبقه بندی آموزش داده شده است طبقه بندی کند. به عنوان مثال، مدلهای موجود در این مثال، یک قطعه متن را میپذیرند و تعیین میکنند که آیا احساس متن مثبت است یا منفی. برای هر قطعه از متن، مدل طبقهبندی متن نمرهای را به دست میدهد که نشاندهنده اطمینان از طبقهبندی صحیح متن به عنوان مثبت یا منفی است.
برای اطلاعات بیشتر در مورد نحوه تولید مدل های این آموزش، به آموزش طبقه بندی متن با TensorFlow Lite Model Maker مراجعه کنید.
مدل ها و مجموعه داده ها
این آموزش از مدل هایی استفاده می کند که با استفاده از مجموعه داده SST-2 (Stanford Sentiment Treebank) آموزش داده شده اند. SST-2 شامل 67349 نقد فیلم برای آموزش و 872 نقد فیلم برای آزمایش است که هر نقد به عنوان مثبت یا منفی طبقه بندی می شود. مدل های مورد استفاده در این برنامه با استفاده از ابزار TensorFlow Lite Model Maker آموزش داده شده اند.
برنامه نمونه از مدل های از پیش آموزش دیده زیر استفاده می کند:
میانگین بردار کلمه (
NLClassifier) -NLClassifierTask Library، متن ورودی را در دسته های مختلف طبقه بندی می کند و می تواند اکثر مدل های طبقه بندی متن را مدیریت کند.MobileBERT (
BertNLClassifier) -BertNLClassifierکتابخانه وظیفه شبیه به NLClassifier است اما برای مواردی که نیاز به توکن سازی های خارج از نمودار Wordpiece و Sentencepiece دارند طراحی شده است.
برنامه نمونه را راه اندازی و اجرا کنید
برای راه اندازی برنامه طبقه بندی متن، برنامه نمونه را از GitHub دانلود کرده و با استفاده از Android Studio اجرا کنید.
سیستم مورد نیاز
- Android Studio نسخه 2021.1.1 (Bumblebee) یا بالاتر.
- Android SDK نسخه 31 یا بالاتر
- دستگاه Android با حداقل نسخه سیستم عامل SDK 21 (Android 7.0 - Nougat) با حالت توسعه دهنده فعال یا شبیه ساز Android.
کد نمونه را دریافت کنید
یک کپی محلی از کد نمونه ایجاد کنید. شما از این کد برای ایجاد یک پروژه در اندروید استودیو و اجرای نمونه برنامه استفاده خواهید کرد.
برای شبیه سازی و تنظیم کد مثال:
- کلون کردن مخزن git
git clone https://github.com/tensorflow/examples.git
- به صورت اختیاری، نمونه git خود را برای استفاده از پرداخت پراکنده پیکربندی کنید، بنابراین فقط فایلهای برنامه نمونه طبقهبندی متن را داشته باشید:
cd examples git sparse-checkout init --cone git sparse-checkout set lite/examples/text_classification/android
پروژه را وارد و اجرا کنید
یک پروژه از کد نمونه دانلود شده ایجاد کنید، پروژه را بسازید و سپس آن را اجرا کنید.
برای وارد کردن و ساخت نمونه پروژه کد:
- Android Studio را راه اندازی کنید.
- از Android Studio، File > New > Import Project را انتخاب کنید.
- به فهرست کد نمونه حاوی فایل build.gradle (
.../examples/lite/examples/text_classification/android/build.gradle) بروید و آن دایرکتوری را انتخاب کنید. - اگر Android Studio درخواست Gradle Sync کرد، OK را انتخاب کنید.
- مطمئن شوید که دستگاه اندرویدی شما به رایانه شما متصل است و حالت توسعه دهنده فعال است. روی فلش سبز
Runکلیک کنید.
اگر دایرکتوری صحیح را انتخاب کنید، Android Studio یک پروژه جدید ایجاد می کند و آن را می سازد. این فرآیند بسته به سرعت کامپیوتر شما و اگر از اندروید استودیو برای پروژه های دیگر استفاده کرده اید، ممکن است چند دقیقه طول بکشد. پس از اتمام ساخت، Android Studio یک پیام BUILD SUCCESSFUL را در پانل وضعیت Build Output نمایش می دهد.
برای اجرای پروژه:
- از Android Studio، پروژه را با انتخاب Run > Run… اجرا کنید.
- یک دستگاه اندروید (یا شبیه ساز) متصل را برای آزمایش برنامه انتخاب کنید.
با استفاده از اپلیکیشن
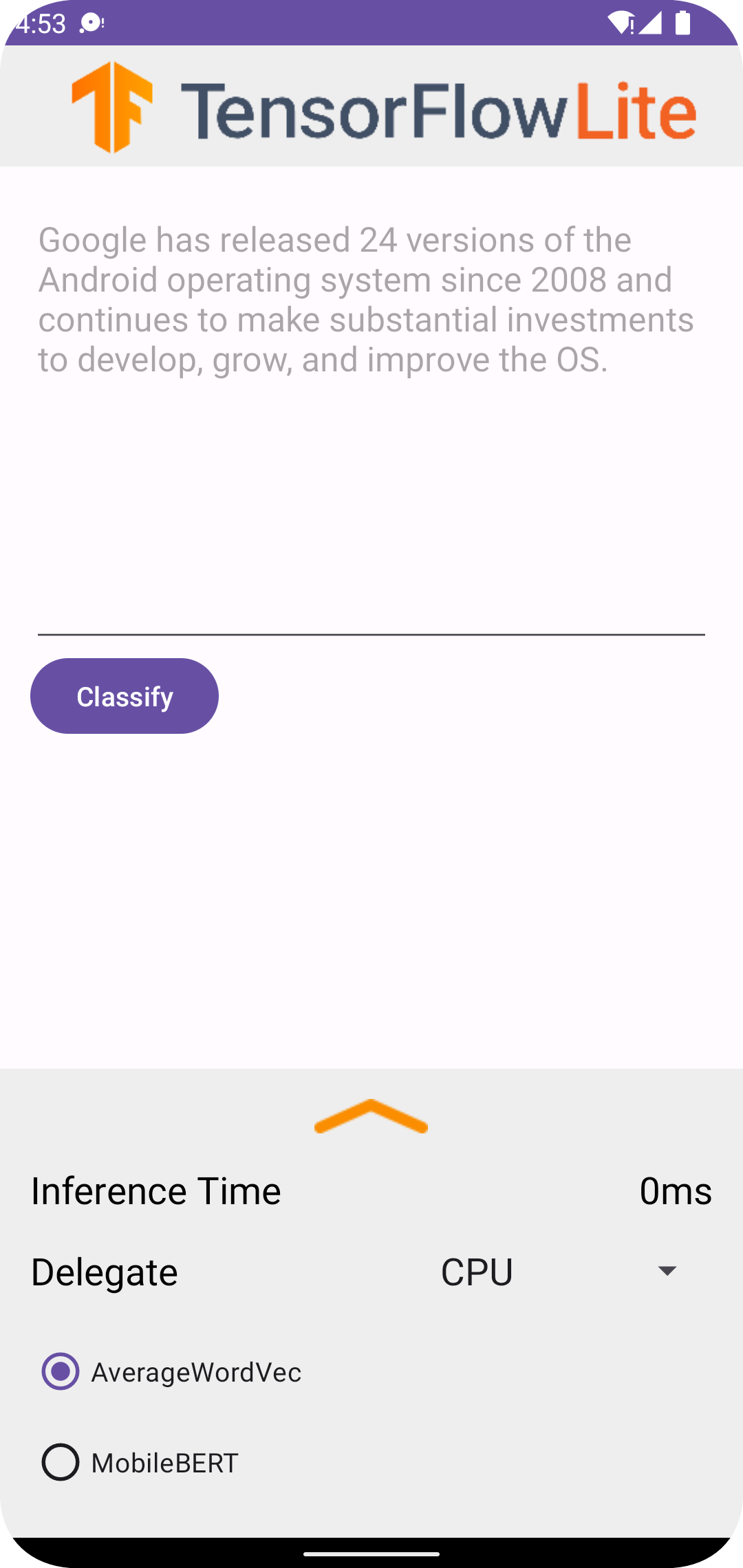
پس از اجرای پروژه در اندروید استودیو، برنامه به طور خودکار در دستگاه متصل یا شبیه ساز دستگاه باز می شود.
برای استفاده از طبقه بندی متن:
- یک قطعه متن را در کادر متن وارد کنید.
- از منوی کشویی Delegate ،
CPUیاNNAPIانتخاب کنید. - با انتخاب
AverageWordVecیاMobileBERTیک مدل را مشخص کنید. - Classify را انتخاب کنید.
خروجی برنامه یک نمره مثبت و یک نمره منفی است. مجموع این دو امتیاز 1 خواهد بود و احتمال مثبت یا منفی بودن احساس متن ورودی را اندازه گیری می کند. عدد بالاتر نشان دهنده سطح بالاتری از اطمینان است.
اکنون یک برنامه کاربردی طبقه بندی متن دارید. از بخشهای زیر برای درک بهتر نحوه عملکرد برنامه نمونه و نحوه پیادهسازی ویژگیهای طبقهبندی متن در برنامههای تولیدی خود استفاده کنید:
چگونه برنامه کار می کند - مروری بر ساختار و فایل های کلیدی برنامه مثال.
برنامه خود را اصلاح کنید - دستورالعمل های اضافه کردن طبقه بندی متن به یک برنامه موجود.
برنامه نمونه چگونه کار می کند
این برنامه از بسته کتابخانه وظیفه برای زبان طبیعی (NL) برای پیاده سازی مدل های طبقه بندی متن استفاده می کند. دو مدل Average Word Vector و MobileBERT با استفاده از TensorFlow Lite Model Maker آموزش داده شدند. برنامه به طور پیش فرض بر روی CPU اجرا می شود، با گزینه شتاب سخت افزاری با استفاده از نماینده NNAPI.
فایلها و دایرکتوریهای زیر حاوی کد حیاتی برای این برنامه طبقهبندی متن هستند:
- TextClassificationHelper.kt - طبقهبندیکننده متن را راهاندازی میکند و مدل و انتخاب نماینده را مدیریت میکند.
- MainActivity.kt - برنامه را پیاده سازی می کند، از جمله فراخوانی
TextClassificationHelperوResultsAdapter. - ResultsAdapter.kt - نتایج را کنترل و قالب بندی می کند.
برنامه خود را اصلاح کنید
بخشهای زیر مراحل کلیدی تغییر برنامه Android خود را برای اجرای مدل نشان داده شده در برنامه مثال توضیح میدهند. این دستورالعمل ها از برنامه مثال به عنوان یک نقطه مرجع استفاده می کنند. تغییرات خاص مورد نیاز برای برنامه شخصی شما ممکن است با برنامه نمونه متفاوت باشد.
یک پروژه اندرویدی را باز یا ایجاد کنید
شما به یک پروژه توسعه اندروید در اندروید استودیو نیاز دارید تا به همراه بقیه این دستورالعمل ها عمل کنید. دستورالعمل های زیر را برای باز کردن یک پروژه موجود یا ایجاد یک پروژه جدید دنبال کنید.
برای باز کردن یک پروژه توسعه اندروید موجود:
- در Android Studio، File > Open را انتخاب کرده و پروژه موجود را انتخاب کنید.
برای ایجاد یک پروژه توسعه پایه اندروید:
- دستورالعمل های موجود در Android Studio را برای ایجاد یک پروژه اساسی دنبال کنید.
برای اطلاعات بیشتر در مورد استفاده از Android Studio، به مستندات Android Studio مراجعه کنید.
وابستگی های پروژه را اضافه کنید
در برنامه خود، باید وابستگیهای پروژه خاصی را برای اجرای مدلهای یادگیری ماشینی TensorFlow Lite اضافه کنید و به توابع ابزاری دسترسی داشته باشید که دادههایی مانند رشتهها را به یک قالب داده تانسور تبدیل میکنند که میتواند توسط مدلی که استفاده میکنید پردازش شود.
دستورالعملهای زیر نحوه افزودن وابستگیهای پروژه و ماژول مورد نیاز را به پروژه برنامه Android خود توضیح میدهند.
برای افزودن وابستگی های ماژول:
در ماژولی که از TensorFlow Lite استفاده می کند، فایل
build.gradleماژول را به روز کنید تا وابستگی های زیر را شامل شود.در برنامه مثال، وابستگی ها در app/build.gradle قرار دارند:
dependencies { ... implementation 'org.tensorflow:tensorflow-lite-task-text:0.4.0' }پروژه باید شامل کتابخانه وظایف متنی (
tensorflow-lite-task-text) باشد.اگر میخواهید این برنامه را طوری تغییر دهید که روی واحد پردازش گرافیکی (GPU) اجرا شود، کتابخانه GPU (
tensorflow-lite-gpu-delegate-plugin) زیرساختی را برای اجرای برنامه در GPU و Delegate (tensorflow-lite-gpuفراهم میکند. ) لیست سازگاری را ارائه می دهد. اجرای این برنامه روی GPU خارج از محدوده این آموزش است.در Android Studio، وابستگیهای پروژه را با انتخاب: File > Sync Project with Gradle Files همگامسازی کنید.
مدل های ML را راه اندازی کنید
در برنامه اندروید خود، باید قبل از اجرای پیشبینیها با مدل، مدل یادگیری ماشینی TensorFlow Lite را با پارامترها مقداردهی کنید.
یک مدل TensorFlow Lite به عنوان یک فایل *.tflite ذخیره می شود. فایل مدل حاوی منطق پیشبینی است و معمولاً شامل ابردادههایی درباره نحوه تفسیر نتایج پیشبینی، مانند نامهای کلاسهای پیشبینی است. به طور معمول، فایل های مدل در دایرکتوری src/main/assets پروژه توسعه شما ذخیره می شوند، مانند نمونه کد:
-
<project>/src/main/assets/mobilebert.tflite -
<project>/src/main/assets/wordvec.tflite
برای راحتی و خوانایی کد، مثال یک شیء همراه را اعلام می کند که تنظیمات مدل را تعریف می کند.
برای مقداردهی اولیه مدل در برنامه خود:
یک شیء همراه برای تعریف تنظیمات مدل ایجاد کنید. در برنامه مثال، این شی در TextClassificationHelper.kt قرار دارد:
companion object { const val DELEGATE_CPU = 0 const val DELEGATE_NNAPI = 1 const val WORD_VEC = "wordvec.tflite" const val MOBILEBERT = "mobilebert.tflite" }تنظیمات مدل را با ساختن یک شی طبقه بندی کننده ایجاد کنید و یک شی TensorFlow Lite با استفاده از
BertNLClassifierیاNLClassifierبسازید.در برنامه مثال، این در تابع
initClassifierدر TextClassificationHelper.kt قرار دارد:fun initClassifier() { ... if( currentModel == MOBILEBERT ) { ... bertClassifier = BertNLClassifier.createFromFileAndOptions( context, MOBILEBERT, options) } else if (currentModel == WORD_VEC) { ... nlClassifier = NLClassifier.createFromFileAndOptions( context, WORD_VEC, options) } }
فعال کردن شتاب سخت افزاری (اختیاری)
هنگام راه اندازی یک مدل TensorFlow Lite در برنامه خود، باید از ویژگی های شتاب سخت افزاری برای سرعت بخشیدن به محاسبات پیش بینی مدل استفاده کنید. نمایندگان TensorFlow Lite ماژولهای نرمافزاری هستند که اجرای مدلهای یادگیری ماشین را با استفاده از سختافزار پردازش تخصصی روی یک دستگاه تلفن همراه، مانند واحد پردازش گرافیکی (GPU) یا واحدهای پردازش تانسور (TPU) تسریع میکنند.
برای فعال کردن شتاب سخت افزاری در برنامه خود:
یک متغیر برای تعریف نماینده ای که برنامه از آن استفاده خواهد کرد ایجاد کنید. در برنامه مثال، این متغیر در ابتدای TextClassificationHelper.kt قرار دارد:
var currentDelegate: Int = 0یک انتخابگر نماینده ایجاد کنید. در برنامه مثال، انتخابگر نماینده در تابع
initClassifierدر TextClassificationHelper.kt قرار دارد:val baseOptionsBuilder = BaseOptions.builder() when (currentDelegate) { DELEGATE_CPU -> { // Default } DELEGATE_NNAPI -> { baseOptionsBuilder.useNnapi() } }
استفاده از نمایندگان برای اجرای مدلهای TensorFlow Lite توصیه میشود، اما الزامی نیست. برای اطلاعات بیشتر در مورد استفاده از نمایندگان با TensorFlow Lite، به TensorFlow Lite Delegates مراجعه کنید.
داده ها را برای مدل آماده کنید
در برنامه Android شما، کد شما با تبدیل دادههای موجود مانند متن خام به قالب دادههای Tensor که میتواند توسط مدل شما پردازش شود، دادهها را برای تفسیر به مدل ارائه میکند. دادههای یک Tensor که به یک مدل منتقل میکنید باید ابعاد یا شکل خاصی داشته باشند که با قالب دادههای مورد استفاده برای آموزش مدل مطابقت داشته باشد.
این برنامه طبقهبندی متن یک رشته را به عنوان ورودی میپذیرد و مدلها منحصراً بر روی مجموعه زبان انگلیسی آموزش داده میشوند. کاراکترهای خاص و کلمات غیر انگلیسی در طول استنتاج نادیده گرفته می شوند.
برای ارائه داده های متنی به مدل:
اطمینان حاصل کنید که تابع
initClassifierحاوی کد مربوط به نماینده و مدلها است، همانطور که در بخش Initialize the ML models و Enable hardware acceleration توضیح داده شده است.از بلوک
initبرای فراخوانی تابعinitClassifierاستفاده کنید. در برنامه مثال،initدر TextClassificationHelper.kt قرار دارد:init { initClassifier() }
پیش بینی ها را اجرا کنید
در برنامه اندرویدی خود، هنگامی که یک شی BertNLClassifier یا NLClassifier را مقداردهی اولیه کردید، می توانید متن ورودی را برای مدل به عنوان "مثبت" یا "منفی" طبقه بندی کنید.
برای اجرای پیش بینی ها:
یک تابع
classifyایجاد کنید، که از طبقهبندیکننده انتخابی (currentModel) استفاده میکند و زمان صرف شده برای طبقهبندی متن ورودی (inferenceTime) را اندازهگیری میکند. در برنامه مثال، تابعclassifyدر TextClassificationHelper.kt قرار دارد:fun classify(text: String) { executor = ScheduledThreadPoolExecutor(1) executor.execute { val results: List<Category> // inferenceTime is the amount of time, in milliseconds, that it takes to // classify the input text. var inferenceTime = SystemClock.uptimeMillis() // Use the appropriate classifier based on the selected model if(currentModel == MOBILEBERT) { results = bertClassifier.classify(text) } else { results = nlClassifier.classify(text) } inferenceTime = SystemClock.uptimeMillis() - inferenceTime listener.onResult(results, inferenceTime) } }نتایج را از
classifyبه شی شنونده منتقل کنید.fun classify(text: String) { ... listener.onResult(results, inferenceTime) }
خروجی مدل دسته
پس از اینکه یک خط متن را وارد کردید، مدل یک امتیاز پیشبینی ایجاد میکند که به صورت شناور بیان میشود، بین 0 و 1 برای دستههای «مثبت» و «منفی».
برای بدست آوردن نتایج پیش بینی از مدل:
یک تابع
onResultبرای شی شنونده ایجاد کنید تا خروجی را مدیریت کند. در برنامه مثال، شی شنونده در MainActivity.kt قرار داردprivate val listener = object : TextClassificationHelper.TextResultsListener { override fun onResult(results: List<Category>, inferenceTime: Long) { runOnUiThread { activityMainBinding.bottomSheetLayout.inferenceTimeVal.text = String.format("%d ms", inferenceTime) adapter.resultsList = results.sortedByDescending { it.score } adapter.notifyDataSetChanged() } } ... }برای رسیدگی به خطاها، تابع
onErrorرا به شی شنونده اضافه کنید:private val listener = object : TextClassificationHelper.TextResultsListener { ... override fun onError(error: String) { Toast.makeText(this@MainActivity, error, Toast.LENGTH_SHORT).show() } }
هنگامی که مدل مجموعه ای از نتایج پیش بینی را برگرداند، برنامه شما می تواند با ارائه نتیجه به کاربر یا اجرای منطق اضافی بر روی آن پیش بینی ها عمل کند. برنامه مثال، امتیازهای پیشبینی را در رابط کاربری فهرست میکند.
مراحل بعدی
- آموزش و پیاده سازی مدل ها از ابتدا با طبقه بندی متن با آموزش TensorFlow Lite Model Maker .
- ابزارهای پردازش متن بیشتری را برای TensorFlow کاوش کنید.
- سایر مدل های BERT را در تنسورفلو هاب دانلود کنید.
- کاربردهای مختلف TensorFlow Lite را در مثالها کاوش کنید.
- در مورد استفاده از مدلهای یادگیری ماشین با TensorFlow Lite در بخش Models بیشتر بیاموزید.
- در راهنمای برنامهنویس TensorFlow Lite درباره پیادهسازی یادگیری ماشین در برنامه تلفن همراه خود بیشتر بیاموزید.