
| |
معرفی
مدلهای زبان بزرگ (LLM) دستهای از مدلهای یادگیری ماشین هستند که برای تولید متن بر اساس مجموعه دادههای بزرگ آموزش داده میشوند. آنها را می توان برای وظایف پردازش زبان طبیعی (NLP) از جمله تولید متن، پاسخ به سؤال و ترجمه ماشینی استفاده کرد. آنها بر اساس معماری ترانسفورماتور هستند و بر روی حجم عظیمی از داده های متنی، اغلب شامل میلیاردها کلمه، آموزش دیده اند. حتی LLM ها در مقیاس کوچکتر، مانند GPT-2، می توانند عملکرد چشمگیری داشته باشند. تبدیل مدلهای TensorFlow به مدلهای سبکتر، سریعتر و کممصرف به ما امکان میدهد مدلهای هوش مصنوعی تولیدی را روی دستگاه اجرا کنیم، با مزایای امنیت بهتر کاربر، زیرا دادهها هرگز از دستگاه شما خارج نمیشوند.
این رانبوک به شما نشان میدهد که چگونه یک برنامه اندروید با TensorFlow Lite برای اجرای Keras LLM بسازید و پیشنهادهایی برای بهینهسازی مدل با استفاده از تکنیکهای کوانتیزاسیون ارائه میدهد، که در غیر این صورت به مقدار بسیار بیشتری از حافظه و قدرت محاسباتی بیشتری برای اجرا نیاز دارد.
ما چارچوب برنامه Android خود را منبع باز قرار داده ایم که هر TFLite LLM سازگار می تواند به آن وصل شود. در اینجا دو دمو وجود دارد:
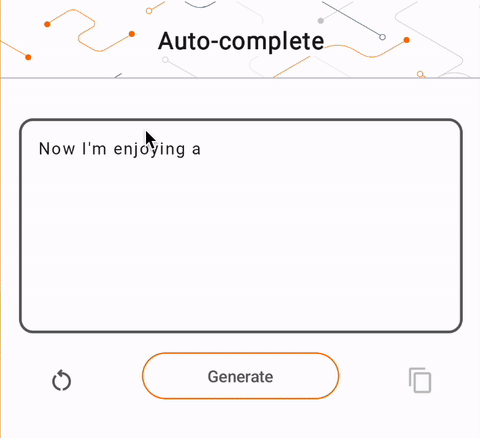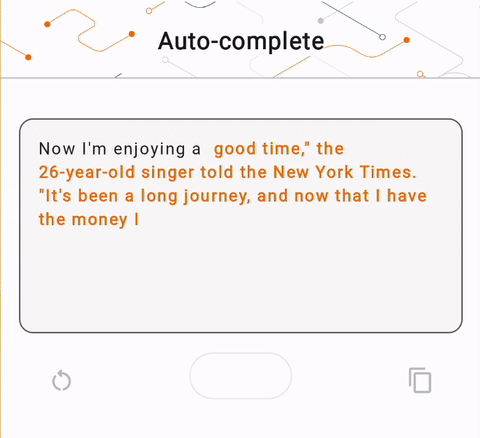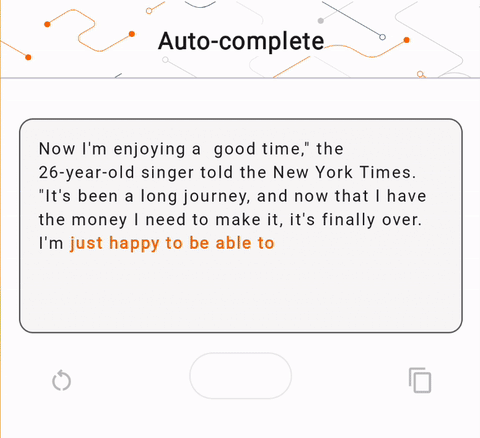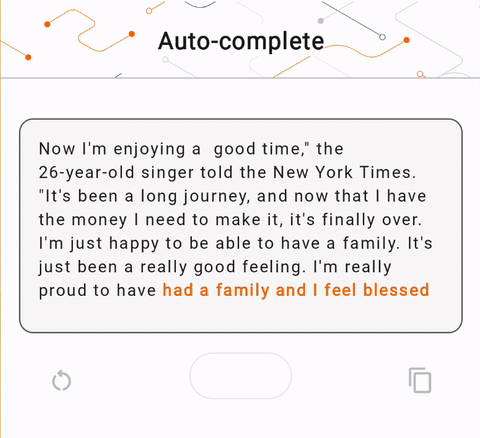
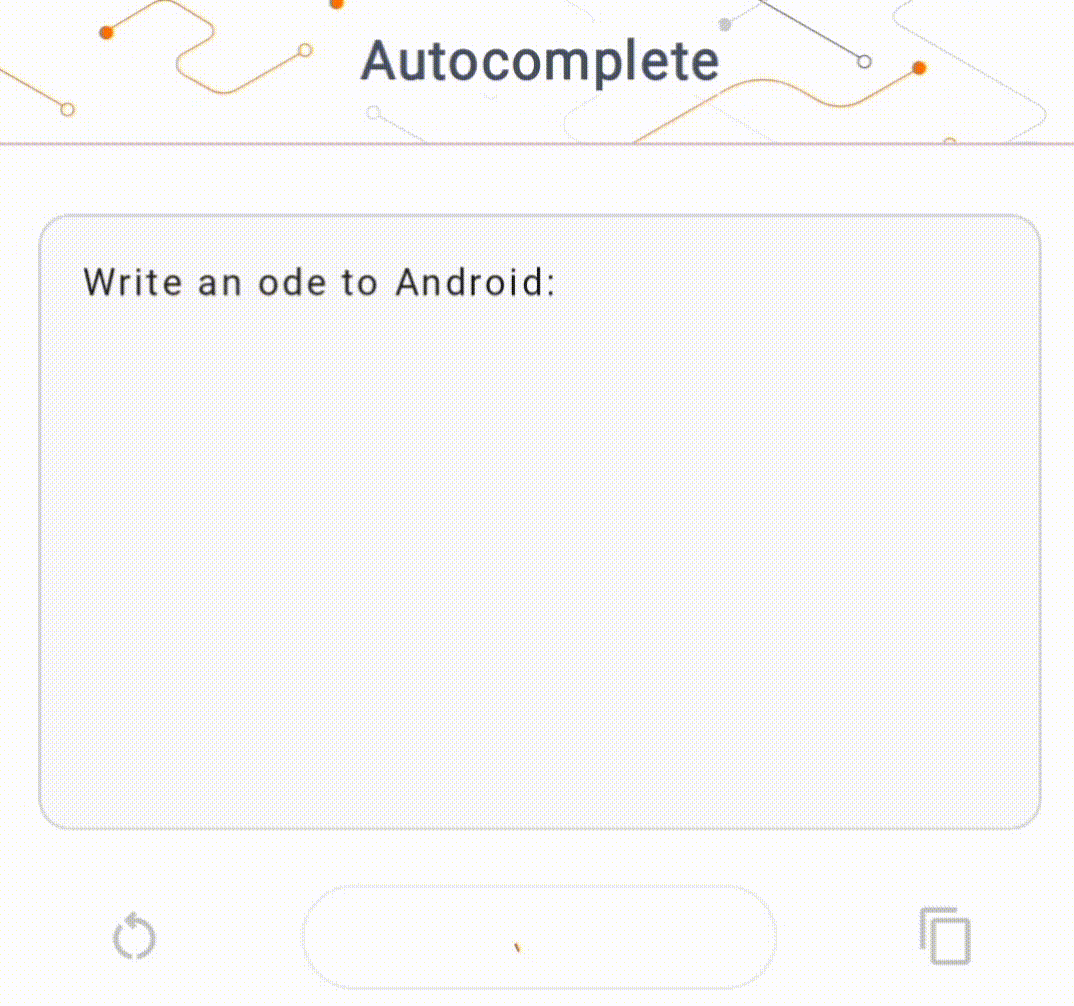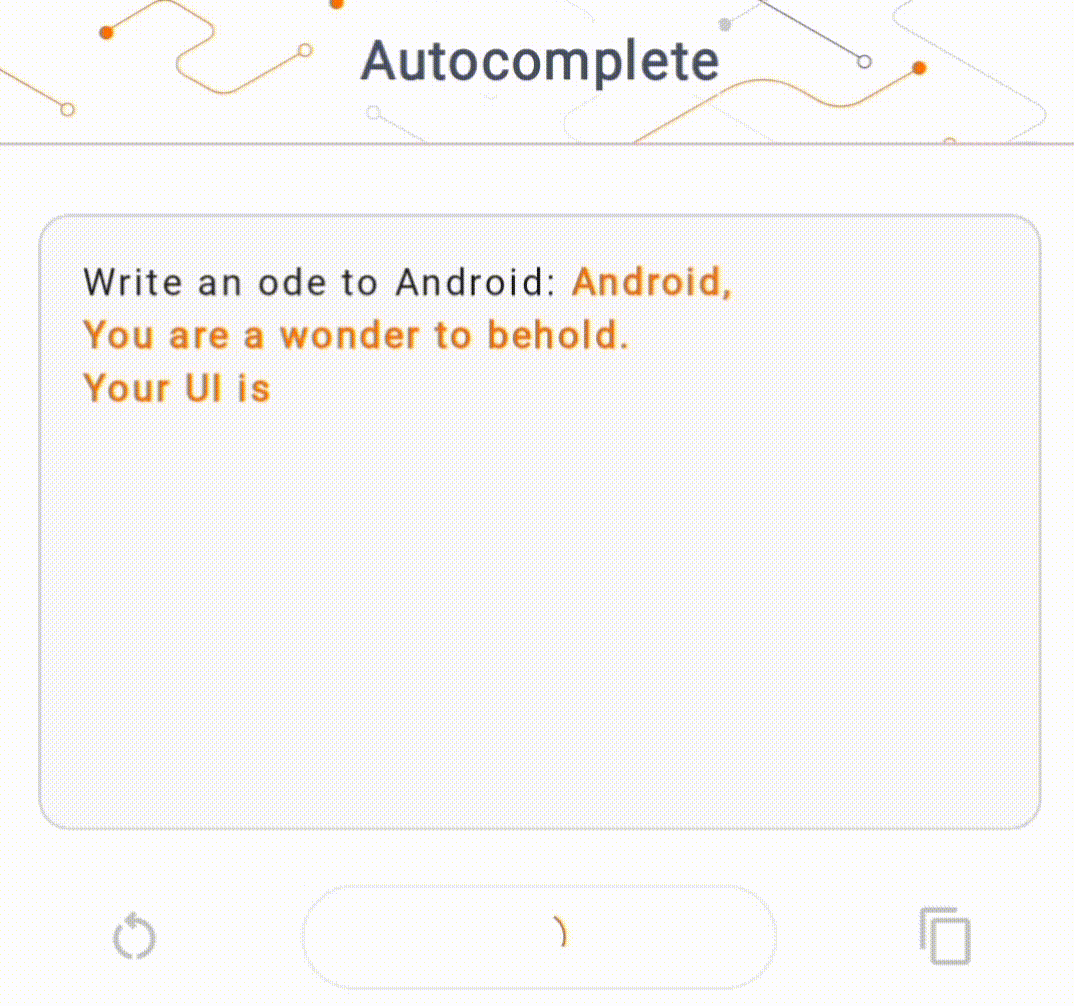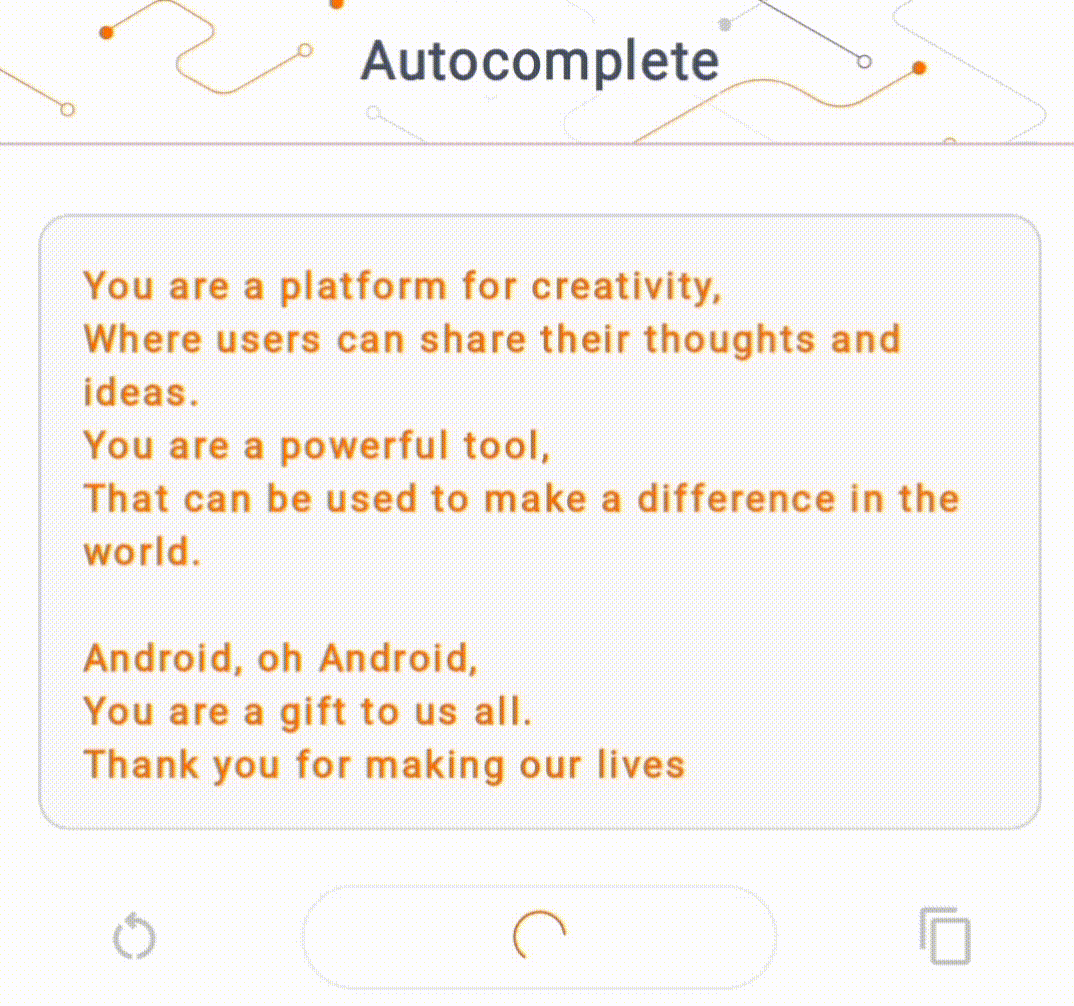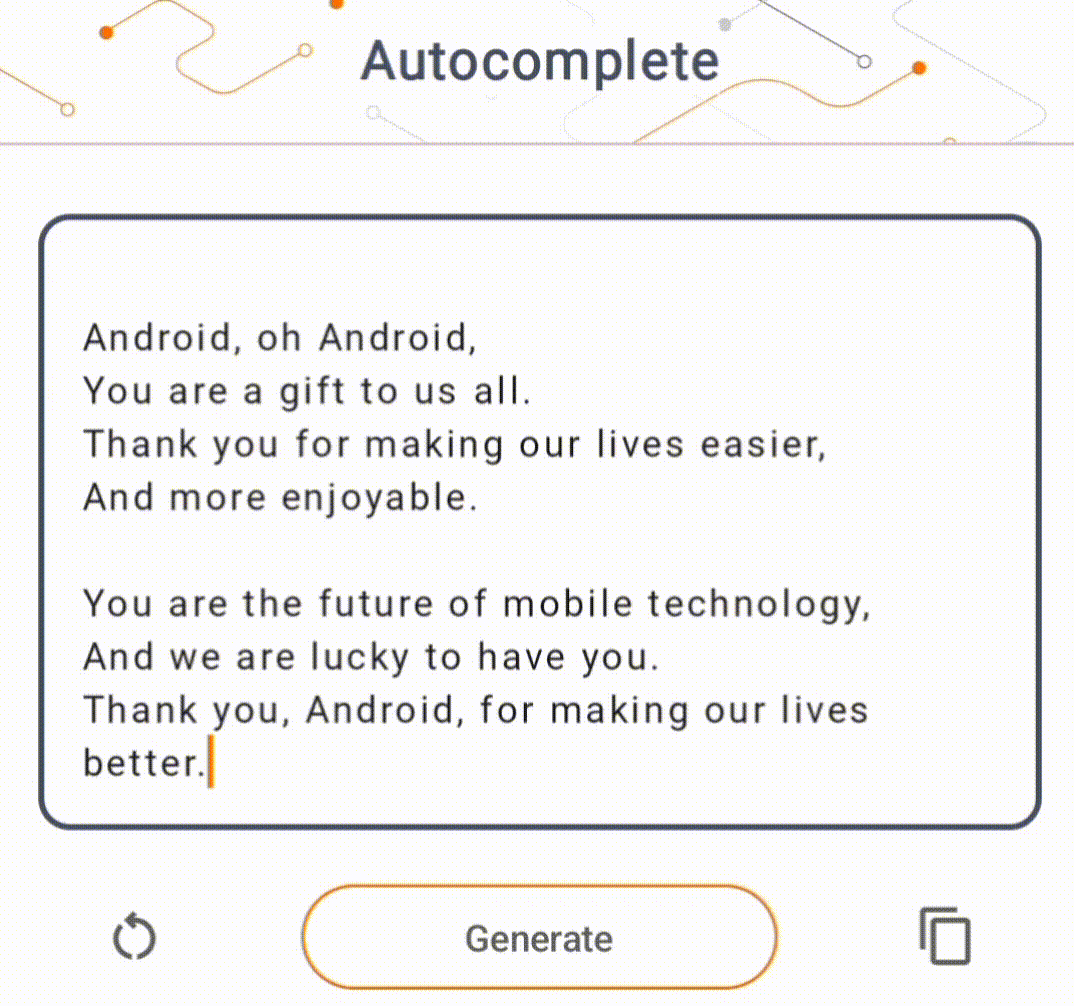
- در شکل 1، ما از مدل Keras GPT-2 برای انجام وظایف تکمیل متن روی دستگاه استفاده کردیم.
- در شکل 2، نسخه ای از مدل PalM تنظیم شده با دستورالعمل (1.5 میلیارد پارامتر) را به TFLite تبدیل کردیم و از طریق زمان اجرا TFLite اجرا شد.
راهنماها
تالیف مدل
برای این نمایش، از KerasNLP برای دریافت مدل GPT-2 استفاده خواهیم کرد. KerasNLP کتابخانهای است که شامل مدلهای از پیشآزمایششده پیشرفته برای وظایف پردازش زبان طبیعی است و میتواند از کاربران در تمام چرخه توسعه پشتیبانی کند. می توانید لیست مدل های موجود در مخزن KerasNLP را مشاهده کنید. گردش کار از اجزای مدولار ساخته شده است که دارای وزنها و معماریهای از پیش تعیینشدهای هستند که در صورت استفاده خارج از جعبه استفاده میشوند و در صورت نیاز به کنترل بیشتر، به راحتی قابل تنظیم هستند. ایجاد مدل GPT-2 را می توان با مراحل زیر انجام داد:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
یکی از وجوه مشترک بین این سه خط کد، متد from_preset() است که بخشی از Keras API را از یک معماری از پیش تعیین شده و/یا وزنها نمونهسازی میکند، بنابراین مدل از پیش آموزش دیده را بارگیری میکند. از این قطعه کد، سه جزء مدولار را نیز مشاهده خواهید کرد:
Tokenizer : ورودی رشته خام را به شناسه توکن عدد صحیح مناسب برای لایه Keras Embedding تبدیل می کند. GPT-2 به طور خاص از رمزگذاری جفت بایت (BPE) توکنایزر استفاده می کند.
پیش پردازنده : لایه ای برای توکن کردن و بسته بندی ورودی ها که باید به مدل Keras وارد شوند. در اینجا، پیش پردازنده، تانسور شناسههای رمز را پس از توکنسازی به طول مشخص (256) اضافه میکند.
Backbone : مدل Keras که از معماری ستون فقرات ترانسفورماتور SoTA پیروی می کند و دارای وزن های از پیش تعیین شده است.
علاوه بر این، می توانید اجرای کامل مدل GPT-2 را در GitHub بررسی کنید.
تبدیل مدل
TensorFlow Lite یک کتابخانه سیار برای استقرار روش ها بر روی موبایل، میکروکنترلرها و سایر دستگاه های لبه است. اولین قدم این است که یک مدل Keras را با استفاده از مبدل TensorFlow Lite به قالب فشرده تر TensorFlow Lite تبدیل کنید و سپس از مفسر TensorFlow Lite که برای دستگاه های تلفن همراه بسیار بهینه شده است، برای اجرای مدل تبدیل شده استفاده کنید.
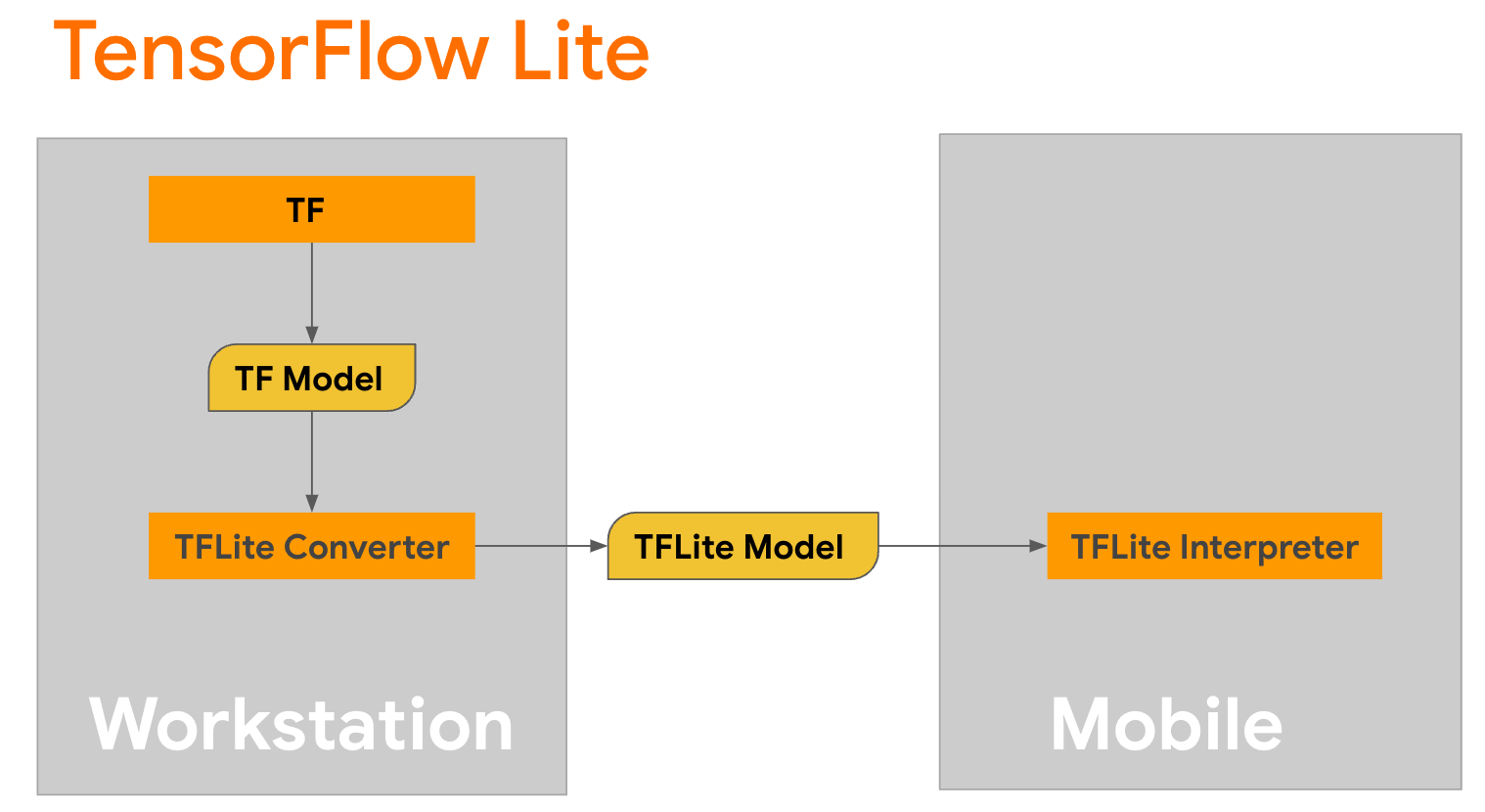 با تابع
با تابع generate() از GPT2CausalLM که تبدیل را انجام می دهد شروع کنید. generate() را بپیچید تا یک تابع TensorFlow بتن ایجاد کنید:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
توجه داشته باشید که می توانید از from_keras_model() از TFLiteConverter نیز برای انجام تبدیل استفاده کنید.
اکنون یک تابع کمکی تعریف کنید که استنتاج را با یک ورودی و یک مدل TFLite اجرا کند. عملیات متنی TensorFlow در زمان اجرا TFLite عملیات داخلی نیستند، بنابراین باید این عملیات سفارشی را اضافه کنید تا مفسر بتواند از این مدل استنباط کند. این تابع کمکی یک ورودی و یک تابع را می پذیرد که تبدیل را انجام می دهد، یعنی تابع generator() تعریف شده در بالا.
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
اکنون می توانید مدل را تبدیل کنید:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
کوانتیزاسیون
TensorFlow Lite یک تکنیک بهینه سازی به نام کوانتیزاسیون را پیاده سازی کرده است که می تواند اندازه مدل را کاهش دهد و استنتاج را تسریع کند. از طریق فرآیند کوانتیزاسیون، شناورهای 32 بیتی به اعداد صحیح 8 بیتی کوچکتر نگاشت می شوند، بنابراین برای اجرای کارآمدتر در سخت افزارهای مدرن، اندازه مدل با ضریب 4 کاهش می یابد. روش های مختلفی برای انجام کوانتیزه کردن در TensorFlow وجود دارد. برای اطلاعات بیشتر می توانید از صفحات بهینه سازی مدل TFLite و جعبه ابزار بهینه سازی مدل TensorFlow دیدن کنید. در زیر انواع کوانتیزاسیون به اختصار توضیح داده شده است.
در اینجا، با تنظیم پرچم بهینهسازی مبدل بر روی tf.lite.Optimize.DEFAULT ، از کوانتیزهسازی محدوده دینامیکی پس از آموزش در مدل GPT-2 استفاده خواهید کرد و بقیه فرآیند تبدیل همان چیزی است که قبلاً توضیح داده شد. ما آزمایش کردیم که با این تکنیک کوانتیزاسیون، تاخیر در پیکسل 7 حدود 6.7 ثانیه با حداکثر طول خروجی 100 است.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
محدوده دینامیکی
کوانتیزاسیون محدوده دینامیکی نقطه شروع توصیه شده برای بهینه سازی مدل های روی دستگاه است. این می تواند به کاهش 4 برابری در اندازه مدل دست یابد، و یک نقطه شروع توصیه شده است زیرا استفاده از حافظه کاهش یافته و محاسبات سریعتر را بدون نیاز به ارائه یک مجموعه داده نماینده برای کالیبراسیون فراهم می کند. این نوع کوانتیزه کردن به صورت ایستا فقط وزن ها را از نقطه شناور تا عدد صحیح 8 بیتی در زمان تبدیل کوانتیزه می کند.
FP16
مدلهای ممیز شناور را میتوان با کمی کردن وزنها به نوع float16 نیز بهینه کرد. مزایای کوانتیزه کردن float16 کاهش اندازه مدل تا نصف (از آنجایی که همه وزنها به نصف اندازه خود میرسند)، ایجاد حداقل کاهش دقت، و پشتیبانی از نمایندگان GPU که میتوانند مستقیماً روی دادههای float16 کار کنند (که منجر به محاسبات سریعتر از float32 میشود) است. داده ها). مدلی که به وزنه های float16 تبدیل شده است همچنان می تواند بدون تغییرات اضافی روی CPU اجرا شود. وزنهای float16 قبل از اولین استنتاج به float32 تبدیل میشوند، که در ازای کمترین تأثیر بر تأخیر و دقت، اندازه مدل را کاهش میدهد.
کوانتیزاسیون کامل عدد صحیح
کوانتیزاسیون کامل اعداد صحیح هر دو اعداد ممیز شناور 32 بیتی، از جمله وزن ها و فعال سازی ها را به نزدیک ترین اعداد صحیح 8 بیتی تبدیل می کند. این نوع کوانتیزاسیون منجر به یک مدل کوچکتر با افزایش سرعت استنتاج می شود که در هنگام استفاده از میکروکنترلرها بسیار ارزشمند است. این حالت زمانی توصیه میشود که فعالسازیها به کوانتیزاسیون حساس باشند.
ادغام برنامه اندروید
می توانید از این مثال اندروید پیروی کنید تا مدل TFLite خود را در یک برنامه اندروید ادغام کنید.
پیش نیازها
اگر قبلاً این کار را نکردهاید، Android Studio را با دنبال کردن دستورالعملهای وبسایت نصب کنید.
- Android Studio 2022.2.1 یا بالاتر.
- دستگاه اندروید یا شبیه ساز اندروید با حافظه بیش از 4G
ساخت و اجرا با اندروید استودیو
- Android Studio را باز کنید و از صفحه خوش آمدید، Open an موجود Android Studio را انتخاب کنید.
- از پنجره Open File یا Project که ظاهر میشود، به دایرکتوری
lite/examples/generative_ai/androidبروید و از هر جایی که مخزن GitHub نمونه TensorFlow Lite را شبیهسازی کردید، انتخاب کنید. - همچنین ممکن است نیاز به نصب پلتفرم ها و ابزارهای مختلف با توجه به پیام های خطا داشته باشید.
- مدل tflite تبدیل شده را به
autocomplete.tfliteتغییر نام دهید و آن را در پوشهapp/src/main/assets/کپی کنید. - منوی Build -> Make Project را برای ساخت برنامه انتخاب کنید. (Ctrl+F9 بسته به نسخه شما).
- روی منوی Run -> Run 'app' کلیک کنید. (Shift+F10 بسته به نسخه شما)
از طرف دیگر، می توانید از wrapper gradle نیز برای ساخت آن در خط فرمان استفاده کنید. لطفاً برای اطلاعات بیشتر به مستندات Gradle مراجعه کنید.
(اختیاری) ساخت فایل .aar
به طور پیش فرض برنامه به طور خودکار فایل های .aar مورد نیاز را دانلود می کند. اما اگر میخواهید خودتان بسازید، به پوشه app/libs/build_aar/ run ./build_aar.sh بروید. این اسکریپت عملیات های لازم را از TensorFlow Text می کشد و aar را برای اپراتورهای Select TF می سازد.
پس از کامپایل، یک فایل جدید tftext_tflite_flex.aar ایجاد می شود. فایل .aar را در پوشه app/libs/ جایگزین کنید و برنامه را دوباره بسازید.
توجه داشته باشید که همچنان باید aar استاندارد tensorflow-lite در فایل gradle خود قرار دهید.
اندازه پنجره زمینه
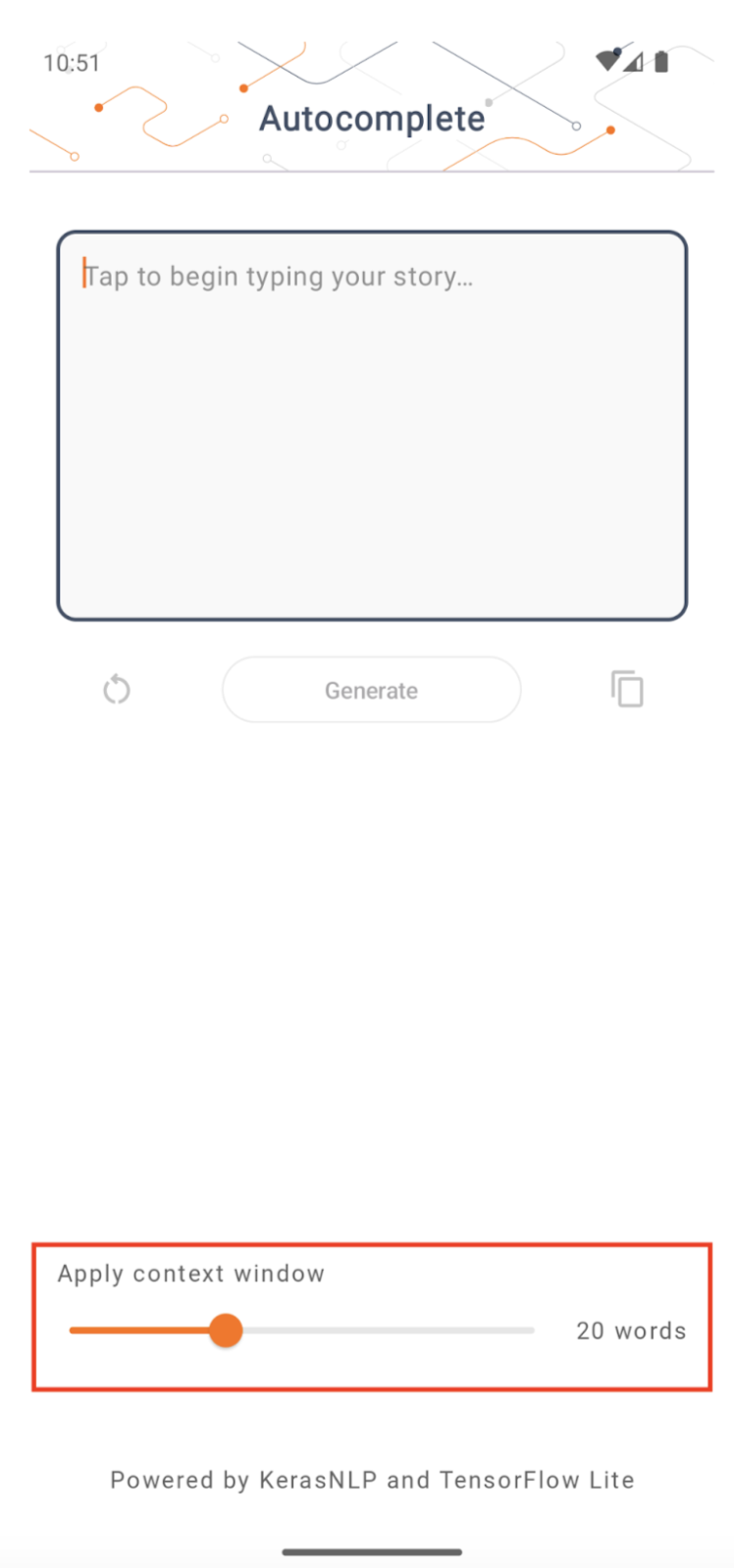
این برنامه دارای یک پارامتر قابل تغییر "اندازه پنجره زمینه" است که لازم است زیرا امروزه LLM ها معمولاً اندازه زمینه ثابتی دارند که تعداد کلمات/نشانه هایی را که می توان به عنوان "اعلان" به مدل وارد کرد محدود می کند (توجه داشته باشید که "کلمه" لزوماً نیست معادل "توکن" در این مورد، به دلیل روش های مختلف توکن سازی). این عدد مهم است زیرا:
- با تنظیم خیلی کوچک، مدل زمینه کافی برای تولید خروجی معنادار را نخواهد داشت
- اگر آن را خیلی بزرگ تنظیم کنید، مدل فضای کافی برای کار نخواهد داشت (زیرا دنباله خروجی شامل دستور است)
می توانید با آن آزمایش کنید، اما تنظیم آن روی 50% طول دنباله خروجی شروع خوبی است.
هوش مصنوعی ایمنی و مسئولیت پذیر
همانطور که در اعلامیه اصلی OpenAI GPT-2 اشاره شد، اخطارها و محدودیت های قابل توجهی در مورد مدل GPT-2 وجود دارد. در واقع، امروزه LLM ها به طور کلی دارای چالش های شناخته شده ای مانند توهم، انصاف، و سوگیری هستند. این به این دلیل است که این مدلها بر روی دادههای دنیای واقعی آموزش داده شدهاند که باعث میشود آنها مسائل دنیای واقعی را منعکس کنند.
این کد لبه فقط برای نشان دادن نحوه ایجاد یک برنامه با LLM با ابزار TensorFlow ایجاد شده است. مدل تولید شده در این کد لبه فقط برای اهداف آموزشی است و برای استفاده در تولید در نظر گرفته نشده است.
استفاده از تولید LLM مستلزم انتخاب متفکرانه مجموعه داده های آموزشی و کاهش ایمنی جامع است. یکی از این قابلیتهای ارائه شده در این برنامه اندروید، فیلتر ناسزاگویی است که ورودیهای بد کاربر یا خروجیهای مدل را رد میکند. اگر زبان نامناسبی شناسایی شود، برنامه در عوض آن عمل را رد می کند. برای کسب اطلاعات بیشتر در مورد هوش مصنوعی مسئول در زمینه LLM، حتماً جلسه فنی توسعه ایمن و مسئولانه با مدلهای زبان مولد را در Google I/O 2023 تماشا کنید و جعبه ابزار هوش مصنوعی مسئول را بررسی کنید.