
TL;DR : টেনসরফ্লো র্যাঙ্কিং পাইপলাইনগুলির সাথে টেনসরফ্লো র্যাঙ্কিং মডেলগুলি তৈরি, প্রশিক্ষণ এবং পরিবেশন করতে বয়লারপ্লেট কোড হ্রাস করুন; বৃহৎ স্কেল র্যাঙ্কিং অ্যাপ্লিকেশনের জন্য সঠিক বিতরণ কৌশল ব্যবহার করুন ব্যবহারের ক্ষেত্রে এবং সংস্থানগুলি দেওয়া।
ভূমিকা
টেনসরফ্লো র্যাঙ্কিং পাইপলাইনে ডেটা প্রসেসিং, মডেল বিল্ডিং, ট্রেনিং এবং পরিবেশন প্রক্রিয়ার একটি সিরিজ রয়েছে যা আপনাকে ন্যূনতম প্রচেষ্টায় ডেটা লগ থেকে স্কেলেবল নিউরাল নেটওয়ার্ক-ভিত্তিক র্যাঙ্কিং মডেলগুলি তৈরি, প্রশিক্ষণ এবং পরিবেশন করতে দেয়। সিস্টেম স্কেল আপ যখন পাইপলাইন সবচেয়ে দক্ষ. সাধারণভাবে, যদি আপনার মডেলটি একটি একক মেশিনে চালানোর জন্য 10 মিনিট বা তার বেশি সময় নেয়, তাহলে লোড বিতরণ করতে এবং প্রক্রিয়াকরণের গতি বাড়াতে এই পাইপলাইন ফ্রেমওয়ার্কটি ব্যবহার করার কথা বিবেচনা করুন।
টেনসরফ্লো র্যাঙ্কিং পাইপলাইনটি বিগ ডাটা (টেরাবাইট+) এবং বিগ মডেল (100M+ FLOPs) সহ ডিস্ট্রিবিউটেড সিস্টেমে (1K+ CPU এবং 100+ GPU এবং TPUs) সহ বৃহৎ মাত্রার পরীক্ষা-নিরীক্ষা এবং উৎপাদনে ক্রমাগত এবং স্থিরভাবে চালিত হয়েছে। একবার ডেটার একটি ছোট অংশে model.fit দিয়ে একটি টেনসরফ্লো মডেল প্রমাণিত হলে, পাইপলাইনটি হাইপার-প্যারামিটার স্ক্যানিং, ক্রমাগত প্রশিক্ষণ এবং অন্যান্য বড় মাপের পরিস্থিতির জন্য সুপারিশ করা হয়।
র্যাঙ্কিং পাইপলাইন
টেনসরফ্লোতে, একটি র্যাঙ্কিং মডেল তৈরি, প্রশিক্ষণ এবং পরিবেশন করার জন্য একটি সাধারণ পাইপলাইন নিম্নলিখিত সাধারণ পদক্ষেপগুলি অন্তর্ভুক্ত করে।
- মডেল গঠন সংজ্ঞায়িত করুন:
- ইনপুট তৈরি করুন;
- প্রাক-প্রক্রিয়াকরণ স্তর তৈরি করুন;
- নিউরাল নেটওয়ার্ক আর্কিটেকচার তৈরি করুন;
- ট্রেন মডেল:
- ডেটা লগ থেকে ট্রেন এবং বৈধতা ডেটাসেট তৈরি করুন;
- যথাযথ হাইপার-প্যারামিটার সহ মডেল প্রস্তুত করুন:
- অপ্টিমাইজার;
- র্যাঙ্কিং ক্ষতি;
- র্যাঙ্কিং মেট্রিক্স;
- একাধিক ডিভাইস জুড়ে প্রশিক্ষণের জন্য বিতরণ করা কৌশলগুলি কনফিগার করুন।
- বিভিন্ন হিসাবরক্ষণের জন্য কলব্যাক কনফিগার করুন।
- পরিবেশনের জন্য রপ্তানি মডেল;
- পরিবেশন মডেল:
- পরিবেশন এ তথ্য বিন্যাস নির্ধারণ;
- প্রশিক্ষিত মডেল চয়ন করুন এবং লোড করুন;
- লোড মডেল সঙ্গে প্রক্রিয়া.
টেনসরফ্লো র্যাঙ্কিং পাইপলাইনের অন্যতম প্রধান উদ্দেশ্য হল ধাপে বয়লারপ্লেট কোড কমানো, যেমন ডেটাসেট লোডিং এবং প্রিপ্রসেসিং, তালিকা অনুযায়ী ডেটার সামঞ্জস্য এবং পয়েন্টওয়াইজ স্কোরিং ফাংশন এবং মডেল এক্সপোর্ট। অন্যান্য গুরুত্বপূর্ণ উদ্দেশ্য হল অনেক সহজাতভাবে সম্পর্কযুক্ত প্রক্রিয়াগুলির সামঞ্জস্যপূর্ণ নকশা প্রয়োগ করা, যেমন, মডেল ইনপুটগুলি অবশ্যই পরিবেশন করার সময় প্রশিক্ষণ ডেটাসেট এবং ডেটা ফর্ম্যাটের সাথে সামঞ্জস্যপূর্ণ হতে হবে।
গাইড ব্যবহার করুন
উপরের সমস্ত ডিজাইনের সাথে, একটি TF-র্যাঙ্কিং মডেল চালু করা নিম্নলিখিত ধাপগুলির মধ্যে পড়ে, যেমন চিত্র 1-এ দেখানো হয়েছে।
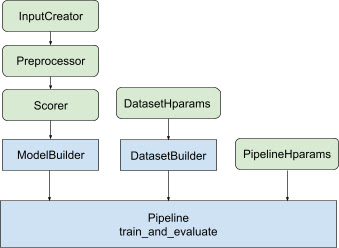
একটি বিতরণ করা নিউরাল নেটওয়ার্ক ব্যবহার করার উদাহরণ
এই উদাহরণে, আপনি অন্তর্নির্মিত tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder , এবং tfr.keras.pipeline.SimplePipeline ব্যবহার করবেন যা feature_spec s গ্রহণ করে মডেল ইনপুট ইনপুটকে ধারাবাহিকভাবে সংজ্ঞায়িত করতে ডেটাসেট সার্ভার। একটি ধাপে ধাপে ওয়াকথ্রু সহ নোটবুকের সংস্করণটি বিতরণ করা র্যাঙ্কিং টিউটোরিয়ালটিতে পাওয়া যাবে।
প্রসঙ্গ এবং উদাহরণ বৈশিষ্ট্য উভয়ের জন্য প্রথমে feature_spec সংজ্ঞায়িত করুন।
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
চিত্র 1 এ চিত্রিত পদক্ষেপগুলি অনুসরণ করুন:
feature_spec s থেকে input_creator সংজ্ঞায়িত করুন।
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
তারপর ইনপুট বৈশিষ্ট্যগুলির একই সেটের জন্য প্রিপ্রসেসিং বৈশিষ্ট্য রূপান্তরগুলি সংজ্ঞায়িত করুন।
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
বিল্ট-ইন ফিডফরোয়ার্ড DNN মডেল সহ স্কোরার সংজ্ঞায়িত করুন।
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
input_creator , preprocessor এবং scorer দিয়ে model_builder তৈরি করুন।
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
এখন dataset_builder এর জন্য হাইপারপ্যারামিটার সেট করুন।
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
dataset_builder তৈরি করুন।
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
এছাড়াও পাইপলাইনের জন্য হাইপারপ্যারামিটার সেট করুন।
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
ranking_pipeline এবং ট্রেন করুন।
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
টেনসরফ্লো র্যাঙ্কিং পাইপলাইনের ডিজাইন
টেনসরফ্লো র্যাঙ্কিং পাইপলাইন বয়লারপ্লেট কোডের সাথে ইঞ্জিনিয়ারিং সময় বাঁচাতে সাহায্য করে, একই সময়ে, ওভাররাইডিং এবং সাবক্লাসিংয়ের মাধ্যমে কাস্টমাইজেশনের নমনীয়তার অনুমতি দেয়। এটি অর্জনের জন্য, পাইপলাইন tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder , এবং tfr.keras.pipeline.AbstractPipeline টেনসরফ্লো র্যাঙ্কিং পাইপলাইন সেট আপ করার জন্য কাস্টমাইজযোগ্য ক্লাস প্রবর্তন করে।

মডেল বিল্ডার
Keras মডেল নির্মাণের সাথে সম্পর্কিত বয়লারপ্লেট কোডটি AbstractModelBuilder একত্রিত করা হয়েছে, যা AbstractPipeline পাঠানো হয় এবং কৌশলের সুযোগের অধীনে মডেলটি তৈরি করতে পাইপলাইনের ভিতরে ডাকা হয়। এটি চিত্র 1 এ দেখানো হয়েছে। ক্লাস পদ্ধতিগুলি বিমূর্ত বেস ক্লাসে সংজ্ঞায়িত করা হয়েছে।
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
আপনি সরাসরি AbstractModelBuilder সাবক্লাস করতে পারেন এবং কাস্টমাইজেশনের জন্য কংক্রিট পদ্ধতিগুলির সাথে ওভাররাইট করতে পারেন, যেমন
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
একই সময়ে, সাবক্লাসিংয়ের পরিবর্তে ক্লাস ইনিট-এ আপনার ইনপুট বৈশিষ্ট্য, প্রিপ্রসেস ট্রান্সফরমেশন, এবং ফাংশন ইনপুট input_creator , preprocessor এবং scorer হিসাবে নির্দিষ্ট স্কোরিং ফাংশন সহ ModelBuilder ব্যবহার করা উচিত।
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
এই ইনপুট তৈরির বয়লারপ্লেটগুলি কমাতে, tfr.keras.model.InputCreator input_creator preprocessor জন্য tfr.keras.model.Preprocessor , এবং scorer জন্য tfr.keras.model.Scorer কংক্রিট সাবক্লাস tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer tfr.keras.model.GAMScorer tfr.keras.model.DNNScorer এবং. এই সাধারণ ব্যবহারের ক্ষেত্রে অধিকাংশ কভার করা উচিত.
মনে রাখবেন যে এই ফাংশন ক্লাসগুলি কেরাস ক্লাস, তাই সিরিয়ালাইজেশনের প্রয়োজন নেই। সাবক্লাসিং তাদের কাস্টমাইজ করার জন্য প্রস্তাবিত উপায়।
ডেটাসেট বিল্ডার
DatasetBuilder ক্লাস ডেটাসেট সম্পর্কিত বয়লারপ্লেট সংগ্রহ করে। ডেটা Pipeline প্রেরণ করা হয় এবং প্রশিক্ষণ এবং বৈধতা ডেটাসেটগুলি পরিবেশন করতে এবং সংরক্ষিত মডেলগুলির জন্য পরিবেশন স্বাক্ষরগুলিকে সংজ্ঞায়িত করতে বলা হয়। চিত্র 1 এ দেখানো হয়েছে, DatasetBuilder পদ্ধতিগুলি tfr.keras.pipeline.AbstractDatasetBuilder বেস ক্লাসে সংজ্ঞায়িত করা হয়েছে,
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
একটি কংক্রিট DatasetBuilder ক্লাসে, আপনাকে অবশ্যই build_train_datasets , build_valid_datasets এবং build_signatures প্রয়োগ করতে হবে।
একটি কংক্রিট ক্লাস যা feature_spec এস থেকে ডেটাসেট তৈরি করে তাও প্রদান করা হয়েছে:
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
DatasetBuilder ব্যবহৃত hparams tfr.keras.pipeline.DatasetHparams ডেটাক্লাসে নির্দিষ্ট করা হয়েছে।
পাইপলাইন
র্যাঙ্কিং পাইপলাইন tfr.keras.pipeline.AbstractPipeline ক্লাসের উপর ভিত্তি করে:
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
একটি কংক্রিট পাইপলাইন শ্রেণী যা মডেলকে বিভিন্ন tf.distribute.strategy s সহ model.fit এর সাথে সামঞ্জস্যপূর্ণ প্রশিক্ষণ দেয়:
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
tfr.keras.pipeline.ModelFitPipeline এ ব্যবহৃত hparams tfr.keras.pipeline.PipelineHparams ডেটাক্লাসে নির্দিষ্ট করা হয়েছে। এই ModelFitPipeline ক্লাসটি বেশিরভাগ TF র্যাঙ্কিং ব্যবহারের ক্ষেত্রে যথেষ্ট। ক্লায়েন্টরা সহজেই নির্দিষ্ট উদ্দেশ্যে এটিকে সাবক্লাস করতে পারে।
বিতরণ কৌশল সমর্থন
TensorFlow সমর্থিত বিতরণ করা কৌশলগুলির বিস্তারিত পরিচয়ের জন্য অনুগ্রহ করে বিতরণ করা প্রশিক্ষণ দেখুন। বর্তমানে, TensorFlow র্যাঙ্কিং পাইপলাইন tf.distribute.MirroredStrategy (ডিফল্ট), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy এবং tf.distribute.ParameterServerStrategy সমর্থন করে। মিররড কৌশল বেশিরভাগ একক মেশিন সিস্টেমের সাথে সামঞ্জস্যপূর্ণ। অনুগ্রহ করে strategy সেট করুন None এর জন্য কোনো বিতরণ করা কৌশল নেই।
সাধারণভাবে, MirroredStrategy সিপিইউ এবং জিপিইউ বিকল্প সহ বেশিরভাগ ডিভাইসে অপেক্ষাকৃত ছোট মডেলের জন্য কাজ করে। MultiWorkerMirroredStrategy বড় মডেলের জন্য কাজ করে যেগুলো একজন শ্রমিকের সাথে খাপ খায় না। ParameterServerStrategy অ্যাসিঙ্ক্রোনাস প্রশিক্ষণ দেয় এবং একাধিক কর্মী উপলব্ধ। TPUStrategy বড় মডেল এবং বড় ডেটার জন্য আদর্শ যখন টিপিইউ পাওয়া যায়, তবে, এটি পরিচালনা করতে পারে এমন টেনসর আকারের ক্ষেত্রে এটি কম নমনীয়।
FAQs
RankingPipelineব্যবহার করার জন্য উপাদানগুলির ন্যূনতম সেট৷
উপরে উদাহরণ কোড দেখুন.আমার নিজের কেরাস
modelথাকলে কি হবে
tf.distributeকৌশলগুলির সাথে প্রশিক্ষিত হওয়ার জন্য, strategy.scope() এর অধীনে সংজ্ঞায়িত সমস্ত প্রশিক্ষনযোগ্য ভেরিয়েবল দিয়েmodelতৈরি করতে হবে। সুতরাং আপনার মডেলটিকেModelBuilderমোড়ানো এইভাবে,
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
তারপর আরও প্রশিক্ষণের জন্য এই মডেল_বিল্ডারকে পাইপলাইনে খাওয়ান।