
TL;DR : Reduzca el código repetitivo para crear, entrenar y ofrecer modelos de clasificación de TensorFlow con TensorFlow Ranking Pipelines; Utilice estrategias distribuidas adecuadas para aplicaciones de clasificación a gran escala según el caso de uso y los recursos.
Introducción
TensorFlow Ranking Pipeline consta de una serie de procesos de procesamiento de datos, creación de modelos, capacitación y servicio que le permiten construir, entrenar y servir modelos de clasificación escalables basados en redes neuronales a partir de registros de datos con un esfuerzo mínimo. La canalización es más eficiente cuando el sistema se amplía. En general, si su modelo tarda 10 minutos o más en ejecutarse en una sola máquina, considere usar este marco de canalización para distribuir la carga y acelerar el procesamiento.
TensorFlow Ranking Pipeline se ha ejecutado de manera constante y estable en experimentos y producciones a gran escala con big data (terabytes+) y grandes modelos (más de 100 millones de FLOP) en sistemas distribuidos (más de 1.000 CPU y más de 100 GPU y TPU). Una vez que se prueba un modelo de TensorFlow con model.fit en una pequeña parte de los datos, se recomienda la canalización para escaneo de hiperparámetros, entrenamiento continuo y otras situaciones a gran escala.
Canal de clasificación
En TensorFlow, una canalización típica para construir, entrenar y servir un modelo de clasificación incluye los siguientes pasos típicos.
- Definir la estructura del modelo:
- Crear entradas;
- Crear capas de preprocesamiento;
- Crear arquitectura de red neuronal;
- Modelo de tren:
- Genere conjuntos de datos de entrenamiento y validación a partir de registros de datos;
- Prepare el modelo con los hiperparámetros adecuados:
- Optimizador;
- Pérdidas de clasificación;
- Métricas de clasificación;
- Configure estrategias distribuidas para entrenar en múltiples dispositivos.
- Configure devoluciones de llamadas para diversas contabilidades.
- Modelo de exportación para servir;
- Modelo de servicio:
- Determinar el formato de los datos en el momento de la entrega;
- Elija y cargue el modelo entrenado;
- Proceso con modelo cargado.
Uno de los principales objetivos de la canalización de TensorFlow Ranking es reducir el código repetitivo en los pasos, como la carga y el preprocesamiento de conjuntos de datos, la compatibilidad de los datos por lista y la función de puntuación puntual, y la exportación de modelos. El otro objetivo importante es imponer el diseño consistente de muchos procesos inherentemente correlacionados; por ejemplo, las entradas del modelo deben ser compatibles tanto con los conjuntos de datos de entrenamiento como con el formato de datos en el servicio.
Guía de uso
Con todo el diseño anterior, el lanzamiento de un modelo de clasificación TF se divide en los siguientes pasos, como se muestra en la Figura 1.
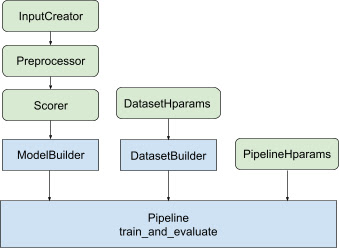
Ejemplo de uso de una red neuronal distribuida
En este ejemplo, aprovechará las funciones integradas tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder y tfr.keras.pipeline.SimplePipeline que toman feature_spec para definir consistentemente las características de entrada en las entradas del modelo y servidor de conjunto de datos. La versión portátil con un tutorial paso a paso se puede encontrar en el tutorial de clasificación distribuida .
Primero defina feature_spec para las características de contexto y de ejemplo.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
Siga los pasos ilustrados en la Figura 1:
Defina input_creator a partir de feature_spec s.
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
Luego defina transformaciones de características de preprocesamiento para el mismo conjunto de características de entrada.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
Defina el anotador con el modelo DNN feedforward incorporado.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
Cree el model_builder con input_creator , preprocessor y scorer .
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
Ahora configure los hiperparámetros para dataset_builder .
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
Crea el dataset_builder .
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
También establezca los hiperparámetros para la canalización.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
Haz el ranking_pipeline y entrena.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
Diseño del canal de clasificación de TensorFlow
TensorFlow Ranking Pipeline ayuda a ahorrar tiempo de ingeniería con código repetitivo y, al mismo tiempo, permite flexibilidad de personalización mediante anulación y subclasificación. Para lograr esto, la canalización introduce clases personalizables tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder y tfr.keras.pipeline.AbstractPipeline para configurar la canalización de TensorFlow Ranking.

Constructor de modelos
El código repetitivo relacionado con la construcción del modelo Keras está integrado en AbstractModelBuilder , que se pasa a AbstractPipeline y se llama dentro de la canalización para construir el modelo bajo el alcance de la estrategia. Esto se muestra en la Figura 1. Los métodos de clase se definen en la clase base abstracta.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
Puede subclasificar directamente AbstractModelBuilder y sobrescribir con los métodos concretos para la personalización, como
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
Al mismo tiempo, debe usar ModelBuilder con características de entrada, transformaciones de preproceso y funciones de puntuación especificadas como entradas de función input_creator , preprocessor y scorer en la clase init en lugar de subclases.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
Para reducir los requisitos de creación de estas entradas, se proporcionan clases de funciones tfr.keras.model.InputCreator para input_creator , tfr.keras.model.Preprocessor para preprocessor y tfr.keras.model.Scorer para scorer , junto con subclases concretas tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer y tfr.keras.model.GAMScorer . Estos deberían cubrir la mayoría de los casos de uso comunes.
Tenga en cuenta que estas clases de funciones son clases de Keras, por lo que no es necesaria la serialización. La subclasificación es la forma recomendada de personalizarlos.
Generador de conjuntos de datos
La clase DatasetBuilder recopila texto estándar relacionado con conjuntos de datos. Los datos se pasan a Pipeline y se llaman para servir los conjuntos de datos de capacitación y validación y para definir las firmas de servicio para los modelos guardados. Como se muestra en la Figura 1, los métodos DatasetBuilder se definen en la clase base tfr.keras.pipeline.AbstractDatasetBuilder .
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
En una clase DatasetBuilder concreta, debes implementar build_train_datasets , build_valid_datasets y build_signatures .
También se proporciona una clase concreta que crea conjuntos de datos a partir de feature_spec :
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
Los hparams que se utilizan en DatasetBuilder se especifican en la clase de datos tfr.keras.pipeline.DatasetHparams .
Tubería
Ranking Pipeline se basa en la clase tfr.keras.pipeline.AbstractPipeline :
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
También se proporciona una clase de canalización concreta que entrena el modelo con diferentes tf.distribute.strategy compatibles con model.fit :
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
Los hparams utilizados en tfr.keras.pipeline.ModelFitPipeline se especifican en la clase de datos tfr.keras.pipeline.PipelineHparams . Esta clase ModelFitPipeline es suficiente para la mayoría de los casos de uso de TF Ranking. Los clientes pueden subclasificarlo fácilmente para fines específicos.
Soporte de estrategia distribuida
Consulte la capacitación distribuida para obtener una introducción detallada de las estrategias distribuidas compatibles con TensorFlow. Actualmente, la canalización de TensorFlow Ranking admite tf.distribute.MirroredStrategy (predeterminado), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy y tf.distribute.ParameterServerStrategy . La estrategia reflejada es compatible con la mayoría de los sistemas de una sola máquina. Establezca strategy en None para que no haya una estrategia distribuida.
En general, MirroredStrategy funciona para modelos relativamente pequeños en la mayoría de los dispositivos con opciones de CPU y GPU. MultiWorkerMirroredStrategy funciona para modelos grandes que no caben en un solo trabajador. ParameterServerStrategy realiza capacitación asincrónica y requiere varios trabajadores disponibles. TPUStrategy es ideal para grandes modelos y grandes datos cuando los TPU están disponibles; sin embargo, es menos flexible en términos de las formas de tensor que puede manejar.
Preguntas frecuentes
El conjunto mínimo de componentes para usar
RankingPipeline
Vea el código de ejemplo arriba.¿Qué pasa si tengo mi propio
modelde Keras?
Para ser entrenado con estrategiastf.distribute,modeldebe construirse con todas las variables entrenables definidas en Strategy.scope(). Así que envuelva su modelo enModelBuildercomo,
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
Luego, introduzca este model_builder en la canalización para obtener más capacitación.