
TL;DR : کد دیگ بخار را برای ساخت، آموزش و ارائه مدل های رتبه بندی TensorFlow با خطوط لوله رتبه بندی TensorFlow کاهش دهید. با توجه به موارد استفاده و منابع، از استراتژی های توزیع شده مناسب برای برنامه های رتبه بندی در مقیاس بزرگ استفاده کنید.
مقدمه
خط لوله رتبه بندی TensorFlow از مجموعه ای از پردازش داده ها، ساخت مدل، آموزش و ارائه فرآیندها تشکیل شده است که به شما امکان می دهد با کمترین تلاش، مدل های رتبه بندی مبتنی بر شبکه عصبی مقیاس پذیر را بسازید، آموزش دهید و ارائه دهید. خط لوله زمانی کارآمدتر است که سیستم افزایش یابد. به طور کلی، اگر مدل شما 10 دقیقه یا بیشتر طول میکشد تا روی یک ماشین اجرا شود، از این چارچوب خط لوله برای توزیع بار و سرعت بخشیدن به پردازش استفاده کنید.
خط لوله رتبه بندی TensorFlow به طور مداوم و پایدار در آزمایش ها و تولیدات در مقیاس بزرگ با داده های بزرگ (ترابایت +) و مدل های بزرگ (100 میلیون FLOP) روی سیستم های توزیع شده (1K+ CPU و 100+ GPU و TPU) اجرا شده است. هنگامی که یک مدل TensorFlow با model.fit در بخش کوچکی از دادهها اثبات شد، خط لوله برای اسکن فرا پارامتری، آموزش مداوم و سایر موقعیتهای مقیاس بزرگ توصیه میشود.
خط لوله رتبه بندی
در TensorFlow، یک خط لوله معمولی برای ساخت، آموزش و ارائه یک مدل رتبه بندی شامل مراحل معمولی زیر است.
- تعریف ساختار مدل:
- ایجاد ورودی؛
- ایجاد لایه های پیش پردازش؛
- ایجاد معماری شبکه عصبی؛
- مدل قطار:
- ایجاد مجموعه دادههای قطار و اعتبارسنجی از سیاهههای مربوط به دادهها.
- مدلی را با پارامترهای فوق مناسب تهیه کنید:
- بهینه ساز؛
- ضررهای رتبه بندی؛
- معیارهای رتبه بندی؛
- راهبردهای توزیع شده را برای آموزش در چندین دستگاه پیکربندی کنید.
- پیکربندی تماس های برگشتی برای حسابداری های مختلف.
- مدل صادراتی برای خدمت;
- مدل سرو:
- تعیین فرمت داده در هنگام ارائه.
- مدل آموزش دیده را انتخاب و بارگذاری کنید.
- فرآیند با مدل بارگذاری شده
یکی از اهداف اصلی خط لوله رتبه بندی TensorFlow کاهش کد دیگ بخار در مراحلی مانند بارگیری و پیش پردازش داده ها، سازگاری داده های لیست و تابع امتیاز دهی نقطه ای و صادرات مدل است. هدف مهم دیگر اجرای طراحی سازگار بسیاری از فرآیندهای ذاتی مرتبط است، به عنوان مثال، ورودیهای مدل باید هم با مجموعه دادههای آموزشی و هم با قالب دادهها در هنگام ارائه سازگار باشند.
استفاده از راهنمای
با تمام طراحی فوق، راه اندازی یک مدل رتبه بندی TF در مراحل زیر قرار می گیرد، همانطور که در شکل 1 نشان داده شده است.
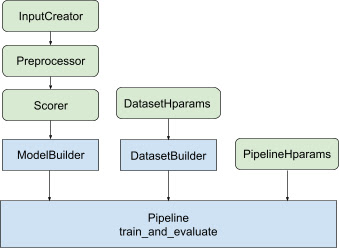
مثال با استفاده از شبکه عصبی توزیع شده
در این مثال، شما از tfr.keras.model.FeatureSpecInputCreator داخلی، tfr.keras.pipeline.SimpleDatasetBuilder و tfr.keras.pipeline.SimplePipeline که feature_spec را میگیرند برای تعریف مداوم ویژگیهای ورودی در ورودیهای مدل و سرور مجموعه داده نسخه نوت بوک را با توضیح گام به گام می توانید در آموزش رتبه بندی توزیع شده پیدا کنید.
ابتدا feature_spec s را برای ویژگی های متن و نمونه تعریف کنید.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
مراحل نشان داده شده در شکل 1 را دنبال کنید:
input_creator از feature_spec s تعریف کنید.
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
سپس تبدیل ویژگی های پیش پردازش را برای همان مجموعه ویژگی های ورودی تعریف کنید.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
امتیاز دهنده را با مدل DNN پیشخور داخلی تعریف کنید.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
با input_creator ، preprocessor و scorer ، model_builder را بسازید.
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
اکنون hyperparameters را برای dataset_builder تنظیم کنید.
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
dataset_builder بسازید.
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
همچنین هایپرپارامترها را برای خط لوله تنظیم کنید.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
ranking_pipeline بسازید و آموزش دهید.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
طراحی خط لوله رتبه بندی TensorFlow
خط لوله رتبه بندی TensorFlow به صرفه جویی در زمان مهندسی با کد دیگ بخار کمک می کند، در عین حال امکان انعطاف پذیری سفارشی سازی از طریق overriding و subclass را فراهم می کند. برای رسیدن به این هدف، خط لوله کلاسهای قابل تنظیم tfr.keras.model.AbstractModelBuilder ، tfr.keras.pipeline.AbstractDatasetBuilder و tfr.keras.pipeline.AbstractPipeline را برای راهاندازی خط لوله رتبهبندی TensorFlow معرفی میکند.

مدل ساز
کد boilerplate مربوط به ساخت مدل Keras در AbstractModelBuilder یکپارچه شده است، که به AbstractPipeline منتقل می شود و در داخل خط لوله فراخوانی می شود تا مدل تحت محدوده استراتژی ساخته شود. این در شکل 1 نشان داده شده است. متدهای کلاس در کلاس پایه انتزاعی تعریف شده اند.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
میتوانید مستقیماً AbstractModelBuilder زیر کلاس قرار دهید و با روشهای مشخص برای سفارشیسازی بازنویسی کنید، مانند
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
در همان زمان، باید از ModelBuilder با ویژگیهای ورودی، تبدیلهای پیشپردازش، و توابع امتیازدهی که بهعنوان ورودیهای تابع input_creator ، preprocessor و scorer در کلاس ابتدایی بهجای طبقهبندی فرعی مشخص شدهاند، استفاده کنید.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
برای کاهش صفحات دیگ ایجاد این ورودیها، کلاسهای تابع tfr.keras.model.InputCreator برای input_creator ، tfr.keras.model.Preprocessor برای preprocessor ، و tfr.keras.model.Scorer برای scorer ، همراه با زیر کلاسهای بتن tfr.keras.model.FeatureSpecInputCreator ، tfr.keras.model.TypeSpecInputCreator ، tfr.keras.model.PreprocessorWithSpec ، tfr.keras.model.UnivariateScorer tfr.keras.model.GAMScorer tfr.keras.model.DNNScorer اینها باید بیشتر موارد استفاده رایج را پوشش دهند.
توجه داشته باشید که این کلاس های تابع، کلاس های Keras هستند، بنابراین نیازی به سریال سازی نیست. طبقه بندی فرعی روشی است که برای سفارشی کردن آنها توصیه می شود.
DatasetBuilder
کلاس DatasetBuilder دیگ بخار مربوط به مجموعه داده را جمع آوری می کند. داده ها به Pipeline ارسال می شوند و برای خدمت به مجموعه داده های آموزشی و اعتبار سنجی و تعریف امضاهای سرویس دهی برای مدل های ذخیره شده فراخوانی می شوند. همانطور که در شکل 1 نشان داده شده است، متدهای DatasetBuilder در کلاس پایه tfr.keras.pipeline.AbstractDatasetBuilder تعریف شده اند.
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
در یک کلاس DatasetBuilder مشخص، باید build_train_datasets ، build_valid_datasets و build_signatures را پیاده سازی کنید.
یک کلاس مشخص که مجموعه داده ها را از feature_spec s می سازد نیز ارائه شده است:
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
hparams که در DatasetBuilder استفاده می شوند در کلاس داده tfr.keras.pipeline.DatasetHparams مشخص شده اند.
خط لوله
خط لوله رتبه بندی بر اساس کلاس tfr.keras.pipeline.AbstractPipeline است:
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
یک کلاس خط لوله بتنی که مدل را با tf.distribute.strategy های مختلف سازگار با model.fit آموزش می دهد نیز ارائه شده است:
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
hparams مورد استفاده در tfr.keras.pipeline.ModelFitPipeline در کلاس داده tfr.keras.pipeline.PipelineHparams مشخص شده اند. این کلاس ModelFitPipeline برای اکثر موارد استفاده از رتبه بندی TF کافی است. مشتریان به راحتی می توانند آن را برای مقاصد خاص زیر طبقه بندی کنند.
پشتیبانی از استراتژی توزیع شده
لطفاً برای معرفی دقیق استراتژی های توزیع شده پشتیبانی شده از TensorFlow به آموزش توزیع شده مراجعه کنید. در حال حاضر، خط لوله رتبه بندی TensorFlow از tf.distribute.MirroredStrategy (پیش فرض)، tf.distribute.TPUStrategy ، tf.distribute.MultiWorkerMirroredStrategy و tf.distribute.ParameterServerStrategy پشتیبانی می کند. استراتژی Mirrored با اکثر سیستمهای تک ماشینی سازگار است. لطفاً strategy روی None برای عدم توزیع استراتژی تنظیم کنید.
به طور کلی، MirroredStrategy برای مدلهای نسبتا کوچک در اکثر دستگاههای دارای گزینههای CPU و GPU کار میکند. MultiWorkerMirroredStrategy برای مدل های بزرگی کار می کند که در یک کارگر مناسب نیستند. ParameterServerStrategy آموزش ناهمزمان انجام می دهد و به چندین کارگر در دسترس نیاز دارد. TPUStrategy برای مدلهای بزرگ و دادههای بزرگ زمانی که TPU در دسترس هستند ایدهآل است، با این حال، از نظر اشکال تانسوری که میتواند تحمل کند، انعطافپذیری کمتری دارد.
سوالات متداول
حداقل مجموعه مولفه ها برای استفاده از
RankingPipeline
کد مثال بالا را ببینید.چه می شود اگر من
modelکراس خودم را داشته باشم
برای آموزش با استراتژیهایtf.distribute،modelباید با تمام متغیرهای آموزشپذیر تعریفشده در strate.scope() ساخته شود. بنابراین مدل خود را درModelBuilderبپیچید،
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
سپس این model_builder را برای آموزش بیشتر وارد خط لوله کنید.