
TL;DR : ridurre il codice boilerplate per creare, addestrare e servire modelli TensorFlow Ranking con pipeline TensorFlow Ranking; Utilizzare strategie distribuite adeguate per applicazioni di classificazione su larga scala in base al caso d'uso e alle risorse.
Introduzione
TensorFlow Ranking Pipeline è costituito da una serie di processi di elaborazione dati, creazione di modelli, training e servizi che ti consentono di costruire, addestrare e servire modelli di ranking scalabili basati su rete neurale dai log di dati con sforzi minimi. La pipeline è più efficiente quando il sistema si espande. In generale, se l'esecuzione del modello richiede 10 minuti o più su un singolo computer, valutare l'utilizzo di questo framework di pipeline per distribuire il carico e accelerare l'elaborazione.
La TensorFlow Ranking Pipeline è stata costantemente e stabilmente utilizzata in esperimenti e produzioni su larga scala con big data (terabyte+) e grandi modelli (100 milioni+ di FLOP) su sistemi distribuiti (1K+ CPU e 100+ GPU e TPU). Una volta testato un modello TensorFlow con model.fit su una piccola parte dei dati, la pipeline è consigliata per la scansione degli iperparametri, la formazione continua e altre situazioni su larga scala.
Pipeline di classifica
In TensorFlow, una tipica pipeline per costruire, addestrare e servire un modello di classificazione include i seguenti passaggi tipici.
- Definire la struttura del modello:
- Creare input;
- Creare livelli di pre-elaborazione;
- Creare un'architettura di rete neurale;
- Modello del treno:
- Generare set di dati di training e convalida dai log di dati;
- Preparare il modello con gli iperparametri adeguati:
- Ottimizzatore;
- Perdite in classifica;
- Metriche di posizionamento;
- Configura strategie distribuite per l'addestramento su più dispositivi.
- Configurare richiamate per varie contabilità.
- Modello di esportazione per servire;
- Servire il modello:
- Determinare il formato dei dati al momento del servizio;
- Scegli e carica il modello addestrato;
- Processo con modello caricato.
Uno degli obiettivi principali della pipeline TensorFlow Ranking è ridurre il codice boilerplate nei passaggi, come il caricamento e la preelaborazione del set di dati, la compatibilità dei dati listwise e della funzione di punteggio pointwise e l'esportazione del modello. L'altro obiettivo importante è quello di applicare la progettazione coerente di molti processi intrinsecamente correlati, ad esempio, gli input del modello devono essere compatibili sia con i set di dati di addestramento che con il formato dei dati al momento del servizio.
Guida all'uso
Con tutta la progettazione di cui sopra, il lancio di un modello di classificazione TF prevede i seguenti passaggi, come mostrato nella Figura 1.
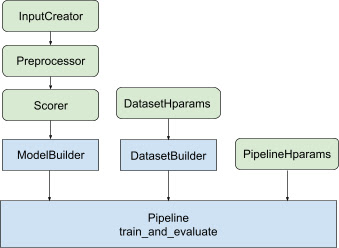
Esempio utilizzando una rete neurale distribuita
In questo esempio, utilizzerai tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder integrati e tfr.keras.pipeline.SimplePipeline che accettano feature_spec per definire in modo coerente le funzionalità di input negli input del modello e server del set di dati. La versione notebook con una procedura dettagliata può essere trovata nel tutorial sulla classificazione distribuita .
Per prima cosa definisci feature_spec sia per le funzionalità di contesto che per quelle di esempio.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
Seguire i passaggi illustrati nella Figura 1:
Definire input_creator da feature_spec s.
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
Quindi definire le trasformazioni delle funzionalità di preelaborazione per lo stesso set di funzionalità di input.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
Definisci il punteggio con il modello DNN feedforward integrato.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
Crea model_builder con input_creator , preprocessor e scorer .
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
Ora imposta gli iperparametri per dataset_builder .
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
Crea dataset_builder .
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
Imposta anche gli iperparametri per la pipeline.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
Crea ranking_pipeline e allenati.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
Progettazione della pipeline di classificazione TensorFlow
La pipeline di classificazione TensorFlow aiuta a risparmiare tempo di progettazione con il codice boilerplate e, allo stesso tempo, consente flessibilità di personalizzazione tramite override e sottoclassi. Per raggiungere questo obiettivo, la pipeline introduce classi personalizzabili tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder e tfr.keras.pipeline.AbstractPipeline per impostare la pipeline TensorFlow Ranking.

Costruttore di modelli
Il codice boilerplate relativo alla costruzione del modello Keras è integrato in AbstractModelBuilder , che viene passato a AbstractPipeline e chiamato all'interno della pipeline per costruire il modello nell'ambito della strategia. Ciò è mostrato nella Figura 1. I metodi di classe sono definiti nella classe base astratta.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
Puoi direttamente sottoclassare AbstractModelBuilder e sovrascrivere con i metodi concreti per la personalizzazione, come
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
Allo stesso tempo, dovresti utilizzare ModelBuilder con funzionalità di input, trasformazioni di preelaborazione e funzioni di punteggio specificate come input di funzione input_creator , preprocessor e scorer nella classe init anziché in sottoclassi.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
Per ridurre i tempi di creazione di questi input, vengono fornite le classi di funzione tfr.keras.model.InputCreator per input_creator , tfr.keras.model.Preprocessor per preprocessor e tfr.keras.model.Scorer per scorer , insieme alle sottoclassi concrete tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer e tfr.keras.model.GAMScorer . Questi dovrebbero coprire la maggior parte dei casi d'uso comuni.
Tieni presente che queste classi di funzioni sono classi Keras, quindi non è necessaria la serializzazione. La creazione di sottoclassi è il modo consigliato per personalizzarli.
DatasetBuilder
La classe DatasetBuilder raccoglie il boilerplate relativo al set di dati. I dati vengono passati alla Pipeline e chiamati a servire i set di dati di addestramento e convalida e a definire le firme di servizio per i modelli salvati. Come mostrato nella Figura 1, i metodi DatasetBuilder sono definiti nella classe base tfr.keras.pipeline.AbstractDatasetBuilder ,
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
In una classe DatasetBuilder concreta, è necessario implementare build_train_datasets , build_valid_datasets e build_signatures .
Viene inoltre fornita una classe concreta che crea set di dati da feature_spec :
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
Gli hparams utilizzati nel DatasetBuilder sono specificati nella classe dati tfr.keras.pipeline.DatasetHparams .
Conduttura
La Ranking Pipeline si basa sulla classe tfr.keras.pipeline.AbstractPipeline :
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
Viene inoltre fornita una classe pipeline concreta che addestra il modello con diversi tf.distribute.strategy compatibili con model.fit :
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
Gli hparams utilizzati in tfr.keras.pipeline.ModelFitPipeline sono specificati nella classe dati tfr.keras.pipeline.PipelineHparams . Questa classe ModelFitPipeline è sufficiente per la maggior parte dei casi d'uso TF Ranking. I client possono facilmente sottoclassarlo per scopi specifici.
Supporto alla strategia distribuita
Fare riferimento alla formazione distribuita per un'introduzione dettagliata delle strategie distribuite supportate da TensorFlow. Attualmente, la pipeline TensorFlow Ranking supporta tf.distribute.MirroredStrategy (impostazione predefinita), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy e tf.distribute.ParameterServerStrategy . La strategia speculare è compatibile con la maggior parte dei sistemi a macchina singola. Imposta strategy su None per nessuna strategia distribuita.
In generale, MirroredStrategy funziona per modelli relativamente piccoli sulla maggior parte dei dispositivi con opzioni CPU e GPU. MultiWorkerMirroredStrategy funziona per modelli di grandi dimensioni che non rientrano in un lavoratore. ParameterServerStrategy esegue la formazione asincrona e richiede la disponibilità di più lavoratori. TPUStrategy è ideale per modelli e big data di grandi dimensioni quando sono disponibili le TPU, tuttavia è meno flessibile in termini di forme tensoriali che può gestire.
Domande frequenti
Il set minimo di componenti per l'utilizzo di
RankingPipeline
Vedi il codice di esempio sopra.E se avessi il mio
modelKeras?
Per essere addestrato con le strategietf.distribute,modeldeve essere costruito con tutte le variabili addestrabili definite in strategic.scope(). Quindi avvolgi il tuo modello inModelBuildercome,
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
Quindi inserisci questo model_builder nella pipeline per ulteriore formazione.