
Scopri come integrare le pratiche di intelligenza artificiale responsabile nel tuo flusso di lavoro ML utilizzando TensorFlow
TensorFlow si impegna a contribuire a compiere progressi nello sviluppo responsabile dell'intelligenza artificiale condividendo una raccolta di risorse e strumenti con la comunità ML.

Cos’è l’IA responsabile?
Lo sviluppo dell’intelligenza artificiale sta creando nuove opportunità per risolvere problemi impegnativi del mondo reale. Sta inoltre sollevando nuove domande sul modo migliore per costruire sistemi di intelligenza artificiale a vantaggio di tutti.

Best practice consigliate per l'intelligenza artificiale
La progettazione di sistemi di intelligenza artificiale dovrebbe seguire le migliori pratiche di sviluppo software adottando un approccio incentrato sull’uomo
approccio al machine learning

Equità
Poiché l’impatto dell’IA aumenta in tutti i settori e nelle società, è fondamentale lavorare verso sistemi equi e inclusivi per tutti

Interpretabilità
Comprendere e avere fiducia nei sistemi di intelligenza artificiale è importante per garantire che funzionino come previsto

Privacy
I modelli di formazione basati su dati sensibili necessitano di salvaguardie che preservino la privacy

Sicurezza
Identificare potenziali minacce può aiutare a mantenere i sistemi di intelligenza artificiale sicuri e protetti
IA responsabile nel tuo flusso di lavoro ML
Pratiche di intelligenza artificiale responsabili possono essere integrate in ogni fase del flusso di lavoro ML. Ecco alcune domande chiave da considerare in ogni fase.
A chi è rivolto il mio sistema ML?
Il modo in cui gli utenti reali sperimentano il tuo sistema è essenziale per valutare il reale impatto delle sue previsioni, raccomandazioni e decisioni. Assicurati di ricevere input da un gruppo diversificato di utenti nelle prime fasi del processo di sviluppo.
Sto utilizzando un set di dati rappresentativo?
I tuoi dati campionati sono rappresentativi dei tuoi utenti (ad esempio, verranno utilizzati per tutte le età, ma hai solo dati di formazione degli anziani) e dell'ambiente reale (ad esempio, verranno utilizzati tutto l'anno, ma hai solo dati di formazione) dati dell'estate)?
Sono presenti pregiudizi tra mondo reale e uomo nei miei dati?
I pregiudizi sottostanti nei dati possono contribuire a complessi cicli di feedback che rafforzano gli stereotipi esistenti.
Quali metodi dovrei utilizzare per addestrare il mio modello?
Utilizzare metodi di formazione che integrino equità, interpretabilità, privacy e sicurezza nel modello.
Come si comporta il mio modello?
Valuta l'esperienza dell'utente in scenari reali attraverso un ampio spettro di utenti, casi d'uso e contesti d'uso. Testare e ripetere prima la versione sperimentale, quindi continuare i test dopo il lancio.
Esistono cicli di feedback complessi?
Anche se tutto nella progettazione complessiva del sistema è realizzato con cura, i modelli basati su ML raramente funzionano con la perfezione al 100% se applicati a dati reali e in tempo reale. Quando si verifica un problema in un prodotto attivo, valuta se è in linea con eventuali svantaggi sociali esistenti e in che modo sarà influenzato dalle soluzioni a breve e lungo termine.
Strumenti di intelligenza artificiale responsabile per TensorFlow
L'ecosistema TensorFlow dispone di una suite di strumenti e risorse per aiutare ad affrontare alcune delle domande di cui sopra.
Definire il problema
Utilizza le seguenti risorse per progettare modelli pensando all'intelligenza artificiale responsabile.

Scopri di più sul processo di sviluppo dell'intelligenza artificiale e sulle considerazioni chiave.

Esplora, tramite visualizzazioni interattive, domande e concetti chiave nel campo dell'intelligenza artificiale responsabile.
Costruire e preparare i dati
Utilizzare i seguenti strumenti per esaminare i dati per individuare potenziali distorsioni.

Esamina in modo interattivo il tuo set di dati per migliorare la qualità dei dati e mitigare i problemi di equità e parzialità.

Analizza e trasforma i dati per rilevare problemi e progettare set di funzionalità più efficaci.


Una scala di tonalità della pelle più inclusiva, con licenza aperta, per rendere le tue esigenze di raccolta dati e creazione di modelli più solide e inclusive.
Costruisci e addestra il modello
Utilizza gli strumenti seguenti per addestrare modelli utilizzando tecniche di tutela della privacy, interpretabili e altro ancora.

Addestrare modelli di machine learning per promuovere risultati più equi.


Addestra modelli di machine learning utilizzando tecniche di apprendimento federato.


Implementare modelli basati su reticolo flessibili, controllati e interpretabili.
Valutare il modello
Eseguire il debug, valutare e visualizzare le prestazioni del modello utilizzando i seguenti strumenti.

Valutare le metriche di equità comunemente identificate per i classificatori binari e multiclasse.

Valuta i modelli in modo distribuito ed effettua calcoli su diverse sezioni di dati.


Visualizzare e comprendere i modelli di PNL.


Valutare le proprietà di privacy dei modelli di classificazione.

Distribuisci e monitora
Utilizza i seguenti strumenti per monitorare e comunicare il contesto e i dettagli del modello.
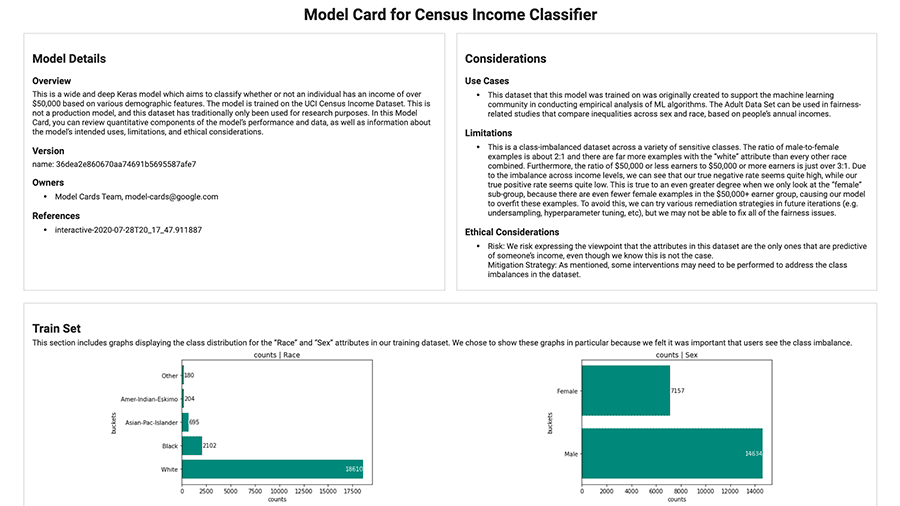
Genera facilmente schede modello utilizzando il toolkit Scheda modello.

Registra e recupera i metadati associati ai flussi di lavoro degli sviluppatori ML e dei data scientist.

Organizzare i fatti essenziali dell'apprendimento automatico in modo strutturato.
Risorse comunitarie
Scopri cosa sta facendo la comunità ed esplora i modi per essere coinvolta.

Aiuta i prodotti Google a diventare più inclusivi e rappresentativi della tua lingua, regione e cultura.

Abbiamo chiesto ai partecipanti di utilizzare TensorFlow 2.2 per creare un modello o un'applicazione tenendo presenti i principi dell'intelligenza artificiale responsabile. Dai un'occhiata alla gallery per vedere i vincitori e altri fantastici progetti.

Presentazione di un quadro per pensare al riciclaggio, all'equità e alla privacy.