
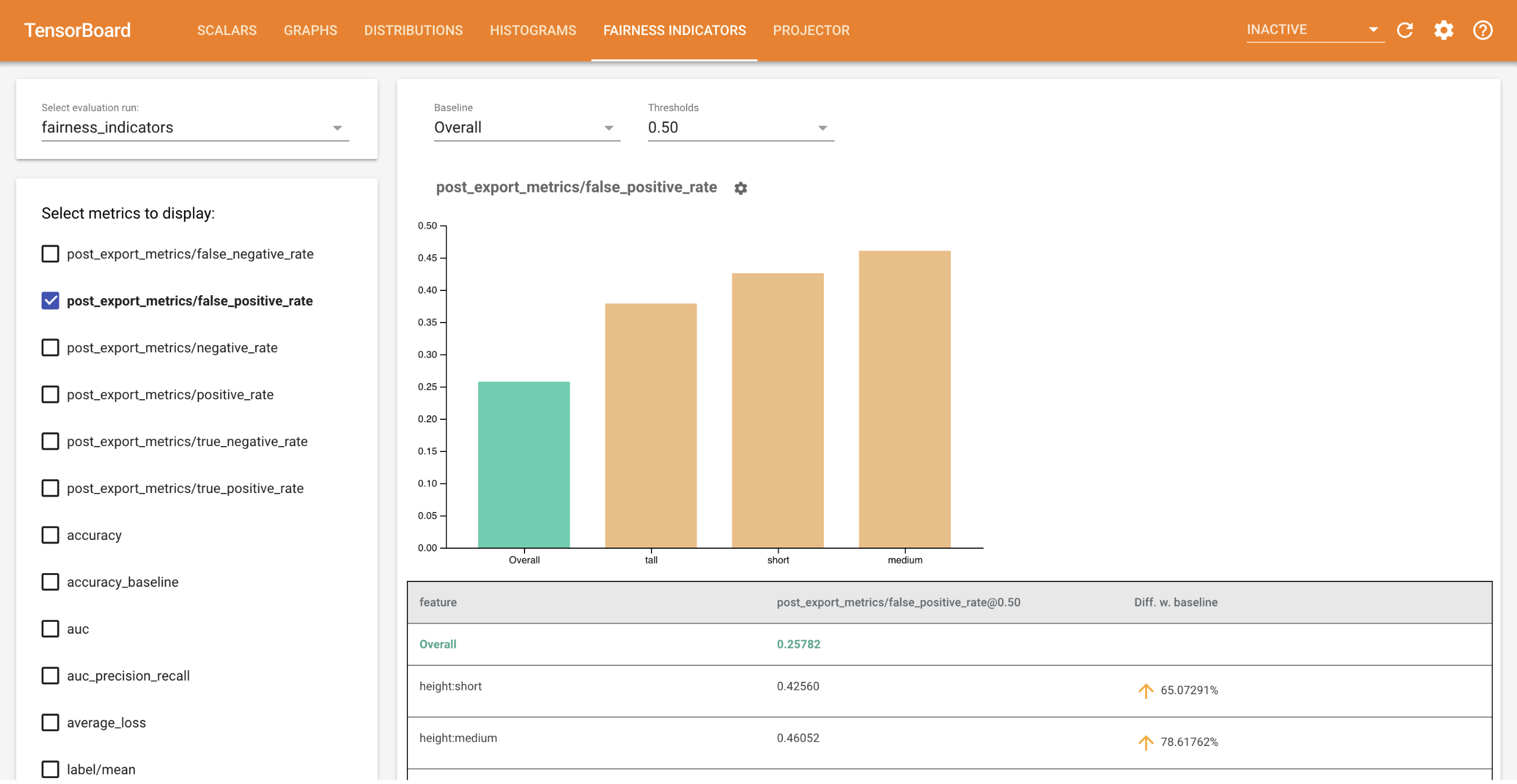
利用 Fairness Indicators for TensorBoard,用户可以轻松计算二元和多类分类器的常见公平性指标。使用该插件,您可以可视化运行的公平性评估结果,并轻松比较各个组之间的性能。
特别是,Fairness Indicators for TensorBoard 可用于评估和可视化跨定义用户组切片的模型性能。利用置信区间和多阈值评估,您将对结果充满信心。
许多现有的公平性问题评估工具在大规模数据集和模型上效果不佳。对于 Google 而言,拥有能够在十亿级用户量的系统上运行的工具十分重要。Fairness Indicators 使您可以在 TensorBoard 环境或 Colab 中评估各种规模的用例。
要求
要安装 Fairness Indicators for TensorBoard,请运行:
python3 -m virtualenv ~/tensorboard_demo
source ~/tensorboard_demo/bin/activate
pip install --upgrade pip
pip install fairness_indicators
pip install tensorboard-plugin-fairness-indicators
演示
如果想要在 TensorBoard 中测试 Fairness Indicators,您可以使用以下命令从 Google Cloud Platform(此处)下载 TensorFlow Model Analysis 评估结果示例(eval_config.json、指标和图文件)以及 demo.py 实用工具。
pip install gsutil
gsutil cp -r gs://tensorboard_plugin_fairness_indicators/ .
导航到包含已下载文件的目录。
cd tensorboard_plugin_fairness_indicators
此评估数据基于 Civil Comments 数据集,使用 Tensorflow Model Analysis 的 model_eval_lib 库计算。其中还包含 TensorBoard 摘要数据示例文件,供您参考。
demo.py 实用工具可写入 TensorBoard 摘要数据文件,供 TensorBoard 读取以呈现 Fairness Indicators 信息中心(有关摘要数据文件的更多信息,请参阅 TensorBoard 教程)。
要与 demo.py 实用工具结合使用的标记:
--logdir:TensorBoard 写入摘要的目录--eval_result_output_dir:包含由 TFMA 评估的评估结果(在上一步中下载)的目录
运行 demo.py 实用工具,将摘要结果写入日志目录:
python demo.py --logdir=. --eval_result_output_dir=.
运行 TensorBoard:
注:对于此演示,请从包含所有下载文件的目录运行 TensorBoard。
tensorboard --logdir=.
这将启动一个本地实例。在本地实例启动后,将向终端显示一个链接。在浏览器中打开该链接即可查看 Fairness Indicators 信息中心。
演示 Colab
Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb 包含训练和评估模型并在 TensorBoard 中可视化公平性评估结果的端到端演示。
使用方法
要将 Fairness Indicators 与您自己的数据和评估结合使用,请执行以下操作:
训练新模型并使用 model_eval_lib 中的
tensorflow_model_analysis.run_model_analysis或tensorflow_model_analysis.ExtractEvaluateAndWriteResultAPI 进行评估。有关如何实现的代码段,请参见此处的 Fairness Indicators Colab。使用
tensorboard_plugin_fairness_indicators.summary_v2API 写入 Fairness Indicators 摘要。writer = tf.summary.create_file_writer(<logdir>) with writer.as_default(): summary_v2.FairnessIndicators(<eval_result_dir>, step=1) writer.close()运行 TensorBoard
tensorboard --logdir=<logdir>- 使用信息中心左侧的下拉菜单选择新的评估运行,以可视化结果。