| |
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码 |
|
概述
使用 TensorBoard Embedding Projector,您能够以图形表示高维嵌入向量。这有助于呈现、检查和理解您的嵌入向量层。

在本教程中,您将了解如何呈现这种经过训练的层。
设置
在本教程中,我们将使用 TensorBoard 呈现为分类电影评论数据而生成的嵌入向量层。
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
IMDB 数据
我们将使用 25,000 条 IMDB 电影评论组成的数据集,每条评论都具有情感标签(正面/负面)。每条评论都已经过预处理,并被编码为单词索引(整数)序列。为方便起见,单词将基于在数据集中出现的总频率建立索引。因此,以整数“3”为例,它将编码在所有评论中出现频率第 3 高的单词。这样可以快速筛选运算,例如:“仅考虑前 10,000 个最常用单词,但排除前 20 个最常用单词”。
按照惯例,“0”不代表特定单词,而是用于编码任何未知的单词。在本教程的后面部分中,我们将在呈现中移除“0”对应的行。
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Keras 嵌入向量层
Keras 嵌入向量层可用于训练词汇表中每个单词的嵌入向量。每个单词(在这种情况下为子单词)将与模型将训练的 16 维向量(或嵌入向量)相关联。
请参阅本教程,详细了解单词嵌入向量。
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
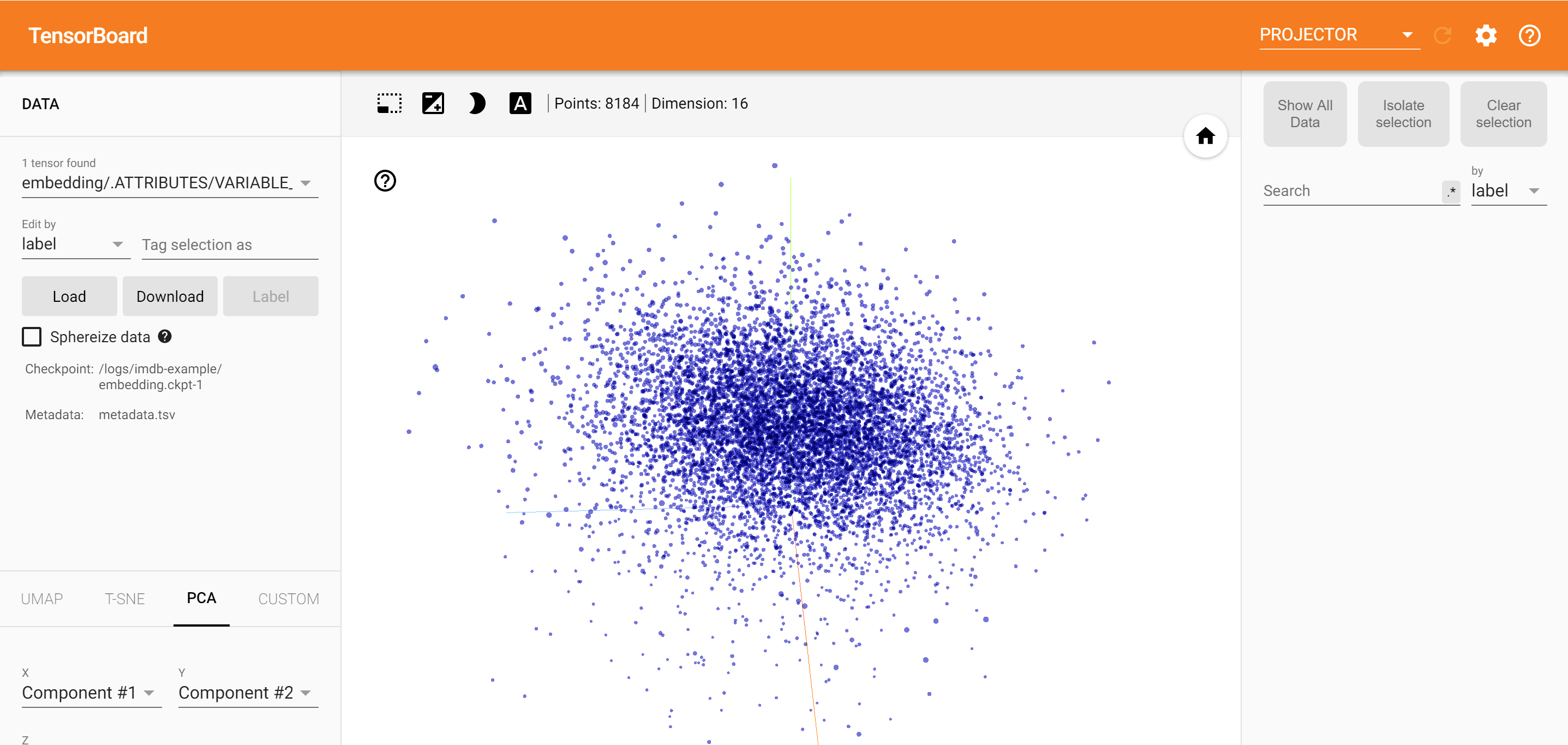
为 TensorBoard 保存数据
TensorBoard 从 TensorFlow 项目的日志中读取张量和元数据。日志目录的路径使用下面的 log_dir 指定。对于本教程,我们将使用 /logs/imdb-example/。
要将数据加载到 TensorBoard 中,我们需要将训练检查点连同可以呈现模型中所关注特定层的元数据保存到该目录中。
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
分析
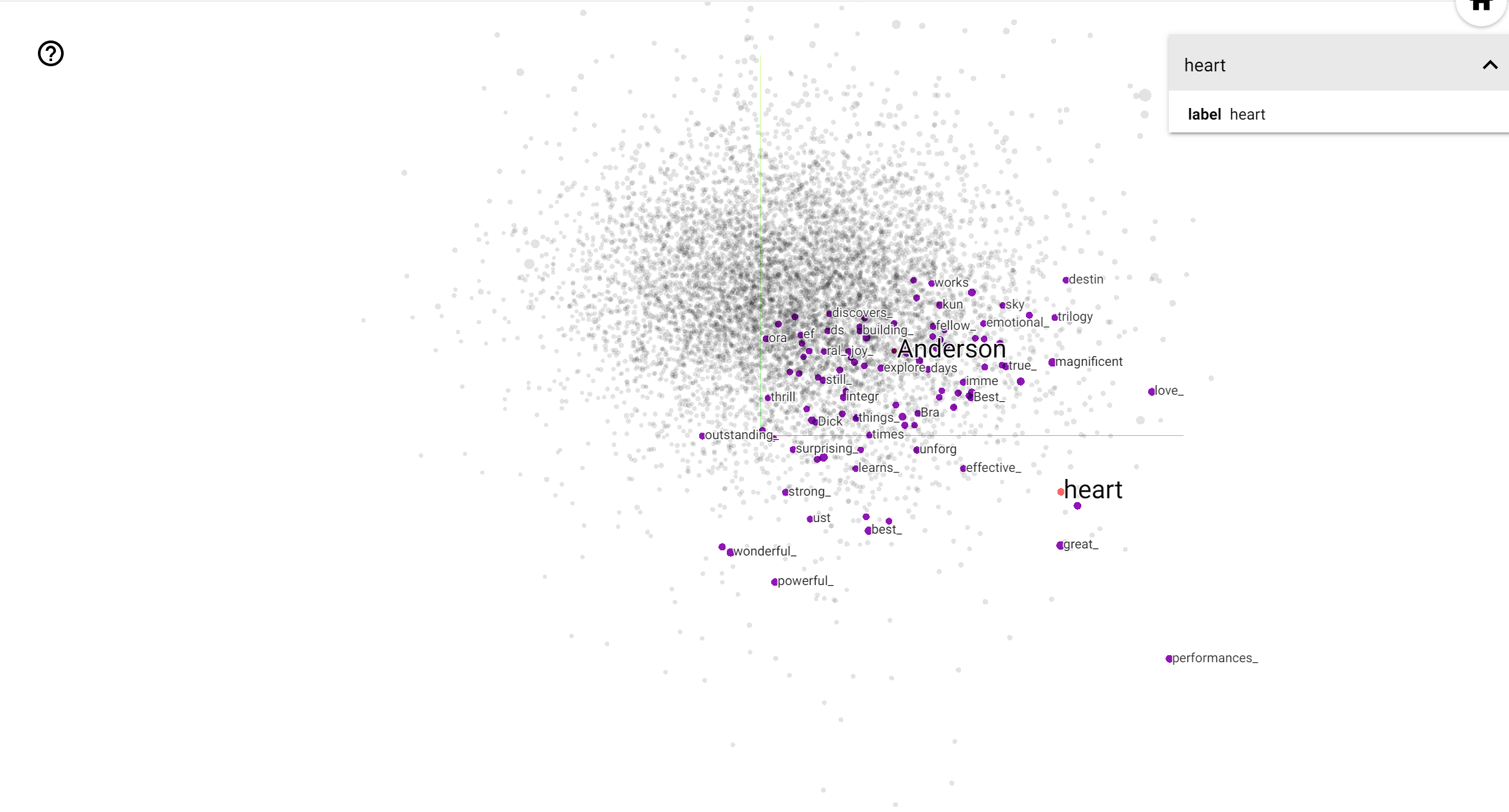
TensorBoard Projector 是一个用于解释和呈现嵌入向量的出色工具。信息中心允许用户搜索特定术语,并突出显示嵌入向量(低维)空间中彼此相邻的单词。从本例中我们可以看到, Wes Anderson 和 Alfred Hitchcock 都是较为中性的术语,但它们在不同的上下文中被引用。
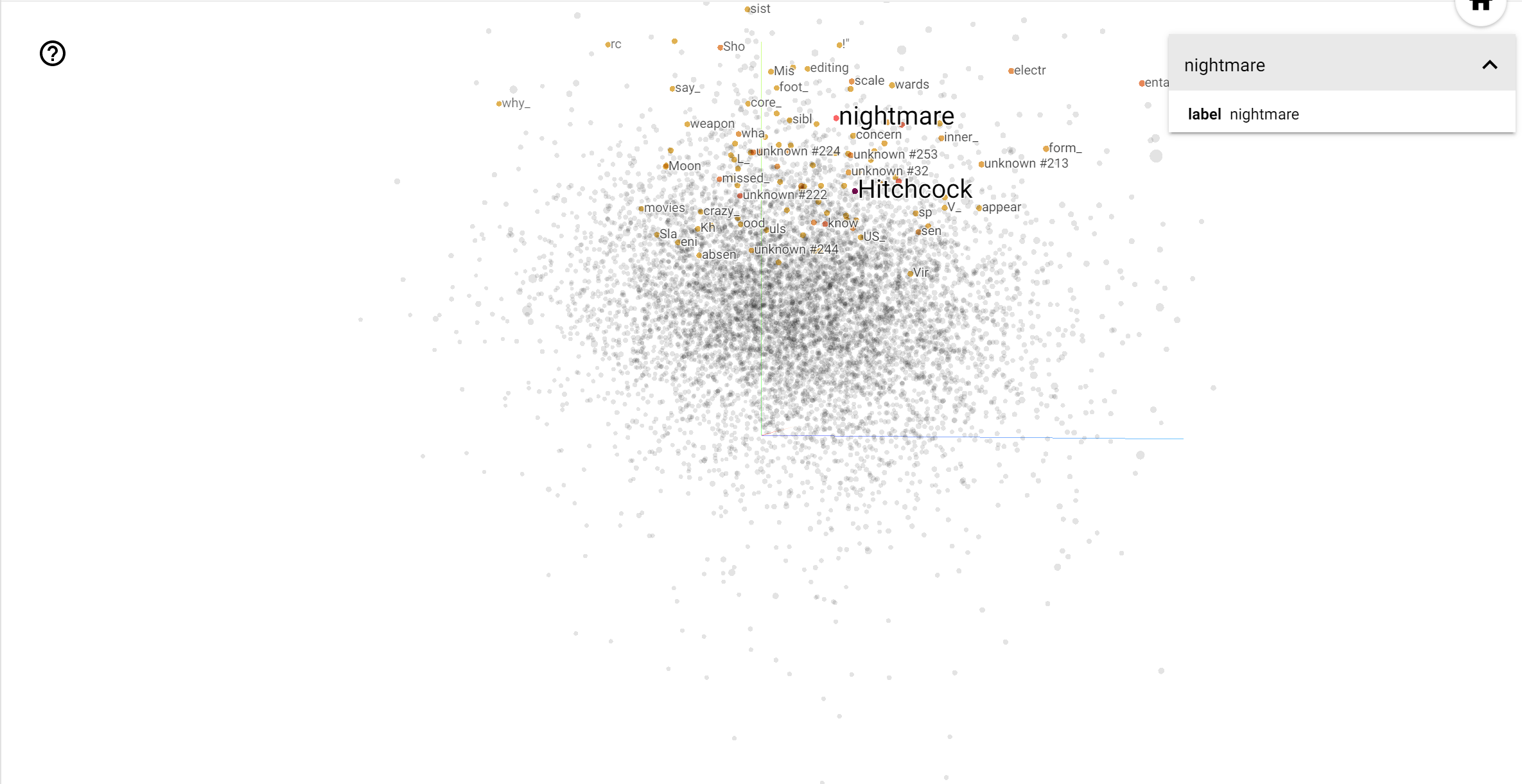
在此空间中,Hitchcock 更接近于 nightmare 之类的单词,这可能是因为他被称为“悬念大师”,而 Anderson 更接近于 heart 这个单词,这与他无比细致和温暖的风格相吻合。