
ลิขสิทธิ์ 2021 The TF-Agents Authors.
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
บทนำ
ตัวอย่างนี้แสดงให้เห็นว่าการฝึกอบรม นักแสดงนักวิจารณ์ซอฟท์ ตัวแทนใน Minitaur สภาพแวดล้อม
ถ้าคุณได้ทำงานผ่าน DQN Colab นี้ควรจะรู้สึกคุ้นเคยมาก การเปลี่ยนแปลงที่โดดเด่น ได้แก่ :
- การเปลี่ยนเอเจนต์จาก DQN เป็น SAC
- การฝึกอบรมเกี่ยวกับ Minitaur ซึ่งเป็นสภาพแวดล้อมที่ซับซ้อนกว่า CartPole สภาพแวดล้อม Minitaur มีจุดมุ่งหมายเพื่อฝึกหุ่นยนต์สี่ขาให้ก้าวไปข้างหน้า
- การใช้ TF-Agents Actor-Learner API สำหรับการเรียนรู้การเสริมแรงแบบกระจาย
API สนับสนุนทั้งการรวบรวมข้อมูลแบบกระจายโดยใช้บัฟเฟอร์การเล่นซ้ำของประสบการณ์และคอนเทนเนอร์ตัวแปร (เซิร์ฟเวอร์พารามิเตอร์) และการฝึกอบรมแบบกระจายในอุปกรณ์หลายเครื่อง API ได้รับการออกแบบมาให้เรียบง่ายและเป็นแบบแยกส่วน เราใช้ พัดโบก สำหรับทั้งกันชนรีเพลย์และภาชนะตัวแปรและ TF DistributionStrategy API สำหรับการฝึกอบรมที่จัดจำหน่ายใน GPUs และ TPUs
หากคุณไม่ได้ติดตั้งการพึ่งพาต่อไปนี้ ให้เรียกใช้:
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
ติดตั้ง
ก่อนอื่นเราจะนำเข้าเครื่องมือต่างๆ ที่เราต้องการ
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
ไฮเปอร์พารามิเตอร์
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
สิ่งแวดล้อม
สภาพแวดล้อมใน RL แสดงถึงงานหรือปัญหาที่เราพยายามแก้ไข สภาพแวดล้อมมาตรฐานที่สามารถสร้างขึ้นได้อย่างง่ายดายใน TF-ตัวแทนโดยใช้ suites เรามีที่แตกต่างกัน suites สำหรับสภาพแวดล้อมการโหลดจากแหล่งที่มาเช่น OpenAI ยิม, Atari, DM ควบคุม ฯลฯ ได้รับชื่อสภาพแวดล้อมสตริง
ตอนนี้ มาโหลดสภาพแวดล้อม Minituar จากชุด Pybullet
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

ในสภาพแวดล้อมนี้ เป้าหมายคือให้ตัวแทนฝึกนโยบายที่จะควบคุมหุ่นยนต์ Minitaur และให้หุ่นยนต์เคลื่อนที่ไปข้างหน้าโดยเร็วที่สุด ตอน 1000 ขั้นสุดท้ายและการกลับมาจะเป็นผลรวมของรางวัลตลอดทั้งตอน
ดู Let 's ที่ข้อมูลสภาพแวดล้อมให้เป็น observation ซึ่งนโยบายจะใช้ในการสร้าง actions
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
การสังเกตค่อนข้างซับซ้อน เราได้รับ 28 ค่าที่แสดงมุม ความเร็ว และแรงบิดสำหรับมอเตอร์ทั้งหมด ในทางกลับกันสภาพแวดล้อมที่คาดว่า 8 ค่าสำหรับการดำเนินการระหว่าง [-1, 1] นี่คือมุมมอเตอร์ที่ต้องการ
โดยปกติเราจะสร้างสองสภาพแวดล้อม: หนึ่งสำหรับการรวบรวมข้อมูลระหว่างการฝึกอบรมและอีกส่วนหนึ่งสำหรับการประเมิน สภาพแวดล้อมเขียนด้วยไพ ธ อนบริสุทธิ์และใช้อาร์เรย์ numpy ซึ่ง Actor Learner API ใช้โดยตรง
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
กลยุทธ์การจัดจำหน่าย
เราใช้ DistributionStrategy API เพื่อเปิดใช้งานการคำนวณขั้นตอนการฝึกในอุปกรณ์ต่างๆ เช่น GPU หลายตัวหรือ TPU โดยใช้ข้อมูลแบบคู่ขนาน ขั้นตอนรถไฟ:
- รับชุดข้อมูลการฝึก
- แบ่งตามอุปกรณ์
- คำนวณก้าวไปข้างหน้า
- รวมและคำนวณค่าเฉลี่ยของการสูญเสีย
- คำนวณขั้นตอนย้อนกลับและดำเนินการอัปเดตตัวแปรการไล่ระดับสี
ด้วย TF-Agents Learner API และ DistributionStrategy API ทำให้ง่ายต่อการสลับระหว่างการรันขั้นตอนการฝึกบน GPU (โดยใช้ MirroredStrategy) เป็น TPU (โดยใช้ TPUStrategy) โดยไม่ต้องเปลี่ยนตรรกะการฝึกด้านล่าง
การเปิดใช้งาน GPU
หากคุณต้องการลองใช้ GPU ก่อนอื่นคุณต้องเปิดใช้งาน GPU สำหรับโน้ตบุ๊ก:
- ไปที่แก้ไข→การตั้งค่าโน้ตบุ๊ก
- เลือก GPU จากดรอปดาวน์ตัวเร่งฮาร์ดแวร์
การเลือกกลยุทธ์
ใช้ strategy_utils ในการสร้างกลยุทธ์ ภายใต้ประทุนส่งพารามิเตอร์:
-
use_gpu = Falseผลตอบแทนtf.distribute.get_strategy()ซึ่งใช้ซีพียู -
use_gpu = Trueผลตอบแทนtf.distribute.MirroredStrategy()ซึ่งใช้ GPUs ทั้งหมดที่สามารถมองเห็นได้ TensorFlow ในหนึ่งเครื่อง
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
ตัวแปรและตัวแทนทั้งหมดจะต้องมีการสร้างขึ้นภายใต้ strategy.scope() เป็นคุณจะดูด้านล่าง
ตัวแทน
ในการสร้างตัวแทน SAC ก่อนอื่นเราต้องสร้างเครือข่ายที่จะฝึก SAC เป็นตัวแทนนักวิจารณ์ ดังนั้นเราต้องการสองเครือข่าย
นักวิจารณ์จะทำให้เรามีค่าประมาณสำหรับ Q(s,a) กล่าวคือจะได้รับจากการสังเกตและการดำเนินการป้อนเข้าและจะให้ค่าประมาณว่าการกระทำนั้นดีเพียงใดสำหรับสถานะที่กำหนด
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
เราจะใช้นักวิจารณ์นี้เพื่อฝึก actor เครือข่ายที่จะช่วยให้เราสามารถสร้างการกระทำที่ได้รับการสังเกต
ActorNetwork จะทำนายพารามิเตอร์สำหรับ tanh-แบน MultivariateNormalDiag กระจาย การกระจายนี้จะถูกสุ่มตัวอย่าง กำหนดเงื่อนไขจากการสังเกตปัจจุบัน เมื่อใดก็ตามที่เราต้องการสร้างการดำเนินการ
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
ด้วยเครือข่ายเหล่านี้ เราสามารถสร้างตัวอย่างตัวแทนได้แล้ว
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
รีเพลย์บัฟเฟอร์
เพื่อที่จะติดตามข้อมูลที่รวบรวมจากสภาพแวดล้อมที่เราจะใช้ พัดโบก , ที่มีประสิทธิภาพ, ขยายและง่ายต่อการใช้งานระบบการเล่นใหม่โดย Deepmind มันเก็บข้อมูลประสบการณ์ที่รวบรวมโดยนักแสดงและใช้งานโดยผู้เรียนในระหว่างการฝึกอบรม
ในการกวดวิชานี้เป็นความสำคัญน้อยกว่า max_size - แต่ในการตั้งค่าการกระจายที่มีคอลเลกชัน async และการฝึกอบรมคุณอาจจะต้องการที่จะทดสอบกับ rate_limiters.SampleToInsertRatio ใช้บาง samples_per_insert ระหว่าง 2 และ 1000 ตัวอย่างเช่น:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
บัฟเฟอร์ replay ถูกสร้างโดยใช้รายละเอียดอธิบายเทนเซอร์ที่จะถูกเก็บไว้ซึ่งสามารถได้รับจากตัวแทนโดยใช้ tf_agent.collect_data_spec
ตั้งแต่ตัวแทน SAC ความต้องการทั้งในปัจจุบันและการสังเกตต่อไปในการคำนวณการสูญเสียเราตั้ง sequence_length=2 2
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
ตอนนี้เราสร้างชุดข้อมูล TensorFlow จากบัฟเฟอร์ Replay Replay เราจะส่งต่อให้ผู้เรียนได้เรียนรู้ประสบการณ์การฝึกอบรม
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
นโยบาย
ในตัวแทน TF, นโยบายการเป็นตัวแทนของความคิดมาตรฐานของนโยบายใน RL: รับ time_step ผลิตการกระทำหรือการกระจายมากกว่าการกระทำ วิธีการหลักคือ policy_step = policy.step(time_step) ที่ policy_step เป็น tuple ชื่อ PolicyStep(action, state, info) policy_step.action คือ action ที่จะนำไปใช้กับสภาพแวดล้อมที่ state เป็นตัวแทนของรัฐในการ stateful (RNN) นโยบายและ info อาจมีข้อมูลเสริมเช่นความน่าจะล็อกการทำงาน
ตัวแทนประกอบด้วยสองนโยบาย:
-
agent.policy- นโยบายหลักที่จะใช้สำหรับการประเมินผลและการใช้งาน -
agent.collect_policy- นโยบายที่สองที่จะใช้ในการเก็บรวบรวมข้อมูล
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
สามารถสร้างนโยบายได้โดยอิสระจากตัวแทน ตัวอย่างเช่นใช้ tf_agents.policies.random_py_policy ในการสร้างนโยบายที่จะสุ่มเลือกการดำเนินการสำหรับแต่ละ time_step
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
นักแสดง
นักแสดงจัดการปฏิสัมพันธ์ระหว่างนโยบายกับสิ่งแวดล้อม
- ส่วนประกอบนักแสดงที่มีอินสแตนซ์ของสภาพแวดล้อม (ตาม
py_environment) และสำเนาตัวแปรนโยบาย - ผู้ปฏิบัติงานนักแสดงแต่ละคนรันลำดับของขั้นตอนการรวบรวมข้อมูลโดยให้ค่าท้องถิ่นของตัวแปรนโยบาย
- การปรับปรุงตัวแปรจะทำอย่างชัดเจนโดยใช้อินสแตนซ์ของลูกค้าภาชนะตัวแปรในสคริปต์การฝึกอบรมก่อนที่จะเรียก
actor.run() - ประสบการณ์ที่สังเกตได้จะถูกเขียนลงในบัฟเฟอร์การเล่นซ้ำในแต่ละขั้นตอนการรวบรวมข้อมูล
ขณะที่นักแสดงดำเนินการขั้นตอนการรวบรวมข้อมูล พวกเขาส่งวิถีของ (สถานะ การกระทำ รางวัล) ไปยังผู้สังเกตการณ์ ซึ่งจะแคชและเขียนข้อมูลเหล่านั้นไปยังระบบเล่นซ้ำของพัดโบก
เรากำลังจัดเก็บไบร์ทสำหรับเฟรม [(t0, T1) (T1, T2) (T2, T3) ... ] เพราะ stride_length=1 1
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
เราสร้างนักแสดงด้วยนโยบายแบบสุ่มและรวบรวมประสบการณ์เพื่อสร้างบัฟเฟอร์การเล่นซ้ำ
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
ยกตัวอย่างนักแสดงด้วยนโยบายการรวบรวมเพื่อรวบรวมประสบการณ์เพิ่มเติมระหว่างการฝึกอบรม
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
สร้างนักแสดงที่จะใช้ประเมินนโยบายระหว่างการฝึกอบรม เราผ่านใน actor.eval_metrics(num_eval_episodes) เข้าสู่ระบบเมตริกในภายหลัง
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
ผู้เรียน
คอมโพเนนต์ของผู้เรียนประกอบด้วยเอเจนต์และดำเนินการอัปเดตขั้นตอนการไล่ระดับให้กับตัวแปรนโยบายโดยใช้ข้อมูลประสบการณ์จากบัฟเฟอร์การเล่นซ้ำ หลังจากหนึ่งขั้นตอนการฝึกอบรมขึ้นไป ผู้เรียนสามารถพุชชุดค่าตัวแปรใหม่ไปยังคอนเทนเนอร์ตัวแปรได้
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
ตัวชี้วัดและการประเมินผล
เรา instantiated นักแสดง EVAL กับ actor.eval_metrics ข้างต้นซึ่งจะสร้างตัวชี้วัดที่ใช้กันมากที่สุดในระหว่างการประเมินผลนโยบาย
- ผลตอบแทนเฉลี่ย การคืนคือผลรวมของรางวัลที่ได้รับขณะดำเนินนโยบายในสภาพแวดล้อมสำหรับตอนหนึ่งๆ และโดยปกติแล้วเราจะเฉลี่ยสิ่งนี้ในช่วงสองสามตอน
- ความยาวตอนเฉลี่ย
เราเรียกใช้ตัวแสดงเพื่อสร้างเมตริกเหล่านี้
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
ตรวจสอบ โมดูลตัวชี้วัด สำหรับการใช้มาตรฐานอื่น ๆ ของตัวชี้วัดที่แตกต่างกัน
อบรมตัวแทน
วงการฝึกอบรมเกี่ยวข้องกับทั้งการรวบรวมข้อมูลจากสภาพแวดล้อมและการเพิ่มประสิทธิภาพเครือข่ายของตัวแทน ในระหว่างนี้ เราจะประเมินนโยบายของตัวแทนเป็นครั้งคราวเพื่อดูว่าเราเป็นอย่างไร
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
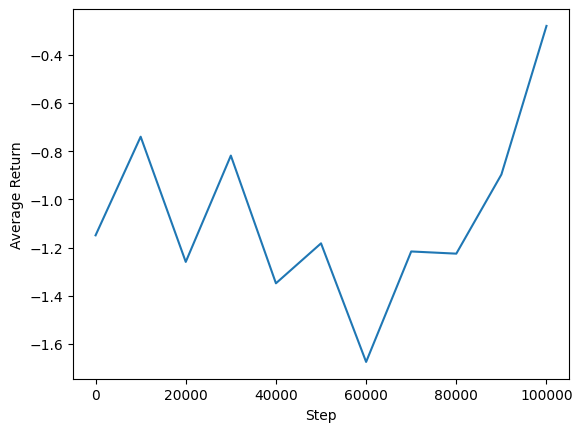
การสร้างภาพ
พล็อต
เราสามารถพล็อตผลตอบแทนเฉลี่ยเทียบกับขั้นตอนทั่วโลกเพื่อดูประสิทธิภาพของตัวแทนของเรา ใน Minitaur ฟังก์ชั่นได้รับรางวัลจะขึ้นอยู่กับวิธีการห่างไกล minitaur เดิน 1000 ขั้นตอนและค่าใช้จ่ายบอลพลังงาน
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
วิดีโอ
เป็นประโยชน์ในการแสดงภาพประสิทธิภาพของเอเจนต์ด้วยการแสดงสภาพแวดล้อมในแต่ละขั้นตอน ก่อนที่เราจะทำอย่างนั้น ให้เราสร้างฟังก์ชันเพื่อฝังวิดีโอใน colab นี้ก่อน
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
โค้ดต่อไปนี้แสดงภาพนโยบายของเอเจนต์สำหรับบางตอน:
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)