
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Di dalam featurization tutorial kita dimasukkan beberapa fitur dalam model kami, tetapi model hanya terdiri dari lapisan embedding. Kita dapat menambahkan lapisan yang lebih padat ke model kita untuk meningkatkan kekuatan ekspresifnya.
Secara umum, model yang lebih dalam mampu mempelajari pola yang lebih kompleks daripada model yang lebih dangkal. Sebagai contoh, kami model pengguna menggabungkan user id dan cap waktu untuk preferensi pengguna model pada titik waktu. Model yang dangkal (misalnya, satu lapisan penyematan) mungkin hanya dapat mempelajari hubungan paling sederhana antara fitur-fitur tersebut dan film: film tertentu paling populer di sekitar waktu peluncurannya, dan pengguna tertentu umumnya lebih menyukai film horor daripada komedi. Untuk menangkap hubungan yang lebih kompleks, seperti preferensi pengguna yang berkembang dari waktu ke waktu, kita mungkin memerlukan model yang lebih dalam dengan beberapa lapisan padat bertumpuk.
Tentu saja, model yang kompleks juga memiliki kekurangan. Yang pertama adalah biaya komputasi, karena model yang lebih besar membutuhkan lebih banyak memori dan lebih banyak komputasi untuk menyesuaikan dan melayani. Yang kedua adalah persyaratan untuk lebih banyak data: secara umum, lebih banyak data pelatihan diperlukan untuk memanfaatkan model yang lebih dalam. Dengan lebih banyak parameter, model dalam mungkin terlalu pas atau bahkan sekadar menghafal contoh pelatihan alih-alih mempelajari fungsi yang dapat digeneralisasi. Akhirnya, melatih model yang lebih dalam mungkin lebih sulit, dan perlu lebih berhati-hati dalam memilih pengaturan seperti regularisasi dan kecepatan belajar.
Menemukan arsitektur yang baik untuk sistem recommender dunia nyata adalah seni yang kompleks, yang membutuhkan intuisi yang baik dan hati-hati tala hyperparameter . Misalnya, faktor-faktor seperti kedalaman dan lebar model, fungsi aktivasi, kecepatan pembelajaran, dan pengoptimal dapat mengubah performa model secara radikal. Pilihan pemodelan semakin diperumit oleh fakta bahwa metrik evaluasi offline yang baik mungkin tidak sesuai dengan kinerja online yang baik, dan bahwa pilihan tentang apa yang akan dioptimalkan seringkali lebih penting daripada pilihan model itu sendiri.
Namun demikian, upaya yang dilakukan untuk membangun dan menyempurnakan model yang lebih besar sering kali membuahkan hasil. Dalam tutorial ini, kami akan mengilustrasikan cara membangun model pengambilan mendalam menggunakan Rekomendasi TensorFlow. Kami akan melakukan ini dengan membangun model yang semakin kompleks untuk melihat bagaimana hal ini memengaruhi kinerja model.
Persiapan
Kami pertama-tama mengimpor paket yang diperlukan.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
Dalam tutorial ini kita akan menggunakan model dari tutorial featurization untuk menghasilkan embeddings. Karenanya kami hanya akan menggunakan fitur id pengguna, stempel waktu, dan judul film.
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Kami juga melakukan beberapa housekeeping untuk menyiapkan kosakata fitur.
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
Definisi model
Model kueri
Kita mulai dengan model yang ditetapkan pengguna di dalam featurization tutorial sebagai lapisan pertama dari model kami, bertugas mengkonversi contoh masukan mentah menjadi embeddings fitur.
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
Mendefinisikan model yang lebih dalam akan mengharuskan kita untuk menumpuk lapisan mode di atas input pertama ini. Tumpukan lapisan yang semakin sempit, dipisahkan oleh fungsi aktivasi, adalah pola umum:
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
Karena kekuatan ekspresif model linier dalam tidak lebih besar dari model linier dangkal, kami menggunakan aktivasi ReLU untuk semua kecuali lapisan tersembunyi terakhir. Lapisan tersembunyi terakhir tidak menggunakan fungsi aktivasi apa pun: menggunakan fungsi aktivasi akan membatasi ruang keluaran dari penyematan akhir dan mungkin berdampak negatif pada kinerja model. Misalnya, jika ReLU digunakan di lapisan proyeksi, semua komponen dalam penyematan keluaran akan menjadi non-negatif.
Kami akan mencoba sesuatu yang serupa di sini. Untuk mempermudah eksperimen dengan kedalaman yang berbeda, mari kita definisikan model yang kedalamannya (dan lebarnya) ditentukan oleh seperangkat parameter konstruktor.
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
The layer_sizes parameter memberi kita kedalaman dan lebar model. Kita dapat memvariasikannya untuk bereksperimen dengan model yang lebih dangkal atau lebih dalam.
Calon model
Kita dapat mengadopsi pendekatan yang sama untuk model film. Sekali lagi, kita mulai dengan MovieModel dari featurization tutorial:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
Dan perluas dengan lapisan tersembunyi:
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
Model gabungan
Dengan kedua QueryModel dan CandidateModel didefinisikan, kita bisa menyatukan model gabungan dan menerapkan kami kehilangan dan metrik logika. Untuk mempermudah, kami akan menerapkan bahwa struktur model sama di seluruh model kueri dan kandidat.
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
Melatih model
Siapkan datanya
Kami pertama-tama membagi data menjadi satu set pelatihan dan satu set pengujian.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
Model dangkal
Kami siap untuk mencoba model pertama kami yang dangkal!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
Ini memberi kami akurasi 100 teratas sekitar 0,27. Kita dapat menggunakan ini sebagai titik referensi untuk mengevaluasi model yang lebih dalam.
Model yang lebih dalam
Bagaimana dengan model yang lebih dalam dengan dua lapisan?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
Akurasi di sini adalah 0,29, sedikit lebih baik daripada model dangkal.
Kita dapat memplot kurva akurasi validasi untuk menggambarkan hal ini:
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
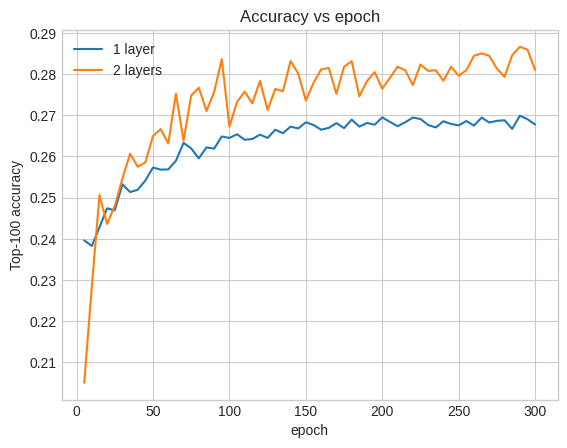
Bahkan di awal pelatihan, model yang lebih besar memiliki keunggulan yang jelas dan stabil atas model yang dangkal, menunjukkan bahwa menambahkan kedalaman membantu model menangkap hubungan yang lebih bernuansa dalam data.
Namun, bahkan model yang lebih dalam belum tentu lebih baik. Model berikut memperluas kedalaman menjadi tiga lapisan:
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
Faktanya, kami tidak melihat peningkatan dari model dangkal:
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
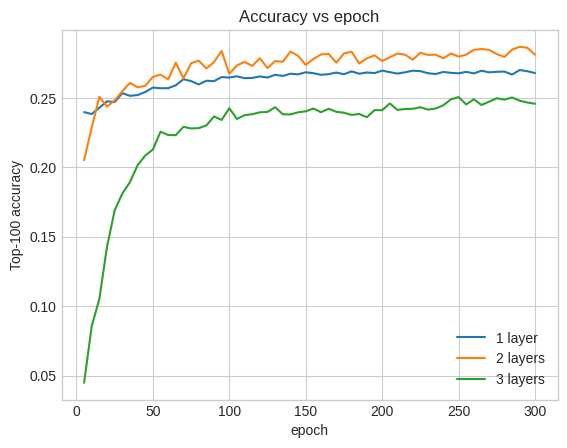
Ini adalah ilustrasi yang baik tentang fakta bahwa model yang lebih dalam dan lebih besar, meskipun mampu menghasilkan kinerja yang unggul, sering kali memerlukan penyetelan yang sangat hati-hati. Misalnya, di sepanjang tutorial ini kami menggunakan tingkat pembelajaran tunggal yang tetap. Pilihan alternatif mungkin memberikan hasil yang sangat berbeda dan perlu ditelusuri.
Dengan penyetelan yang tepat dan data yang memadai, upaya yang dilakukan untuk membangun model yang lebih besar dan lebih dalam dalam banyak kasus sangat berharga: model yang lebih besar dapat menghasilkan peningkatan substansial dalam akurasi prediksi.
Langkah selanjutnya
Dalam tutorial ini kami memperluas model pengambilan kami dengan lapisan padat dan fungsi aktivasi. Untuk melihat bagaimana untuk membuat model yang dapat melakukan tidak hanya tugas pengambilan tetapi juga rating tugas, lihatlah tutorial multitask .