| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
개요
TensorBoard 임베딩 프로젝터를 사용하면 그래픽으로 높은 차원 묻어을 나타낼 수 있습니다. 이는 임베딩 레이어를 시각화, 검사 및 이해하는 데 도움이 될 수 있습니다.

이 자습서에서는 이러한 유형의 훈련된 레이어를 시각화하는 방법을 배웁니다.
설정
이 튜토리얼에서는 TensorBoard를 사용하여 영화 리뷰 데이터를 분류하기 위해 생성된 임베딩 레이어를 시각화합니다.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
IMDB 데이터
우리는 각각 감정 레이블(긍정/부정)이 있는 25,000개의 IMDB 영화 리뷰 데이터 세트를 사용할 것입니다. 각 리뷰는 사전 처리되고 일련의 단어 인덱스(정수)로 인코딩됩니다. 단순성을 위해 단어는 데이터 세트의 전체 빈도로 색인화됩니다. 예를 들어 정수 "3"은 모든 리뷰에 나타나는 세 번째로 자주 사용되는 단어를 인코딩합니다. 이를 통해 "가장 일반적인 상위 10,000개의 단어만 고려하고 상위 20개의 가장 일반적인 단어는 제거"와 같은 빠른 필터링 작업을 수행할 수 있습니다.
관례적으로 "0"은 특정 단어를 나타내는 것이 아니라 알 수 없는 단어를 인코딩하는 데 사용됩니다. 자습서의 뒷부분에서 시각화에서 "0"에 대한 행을 제거합니다.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
케라스 임베딩 레이어
Keras 매립층은 어휘의 각 단어에 대한 삽입을 훈련하는 데 사용할 수 있습니다. 각 단어(또는 이 경우 하위 단어)는 모델에 의해 훈련될 16차원 벡터(또는 임베딩)와 연결됩니다.
참조 이 튜토리얼 단어 묻어 대해 더 배우고.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
TensorBoard용 데이터 저장
TensorBoard는 tensorflow 프로젝트의 로그에서 텐서와 메타데이터를 읽습니다. 로그 디렉토리에 대한 경로로 지정 log_dir 아래. 이 튜토리얼을 위해, 우리는 사용하는 것입니다 /logs/imdb-example/ .
데이터를 Tensorboard에 로드하려면 모델의 특정 관심 계층을 시각화할 수 있는 메타데이터와 함께 교육 체크포인트를 해당 디렉터리에 저장해야 합니다.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
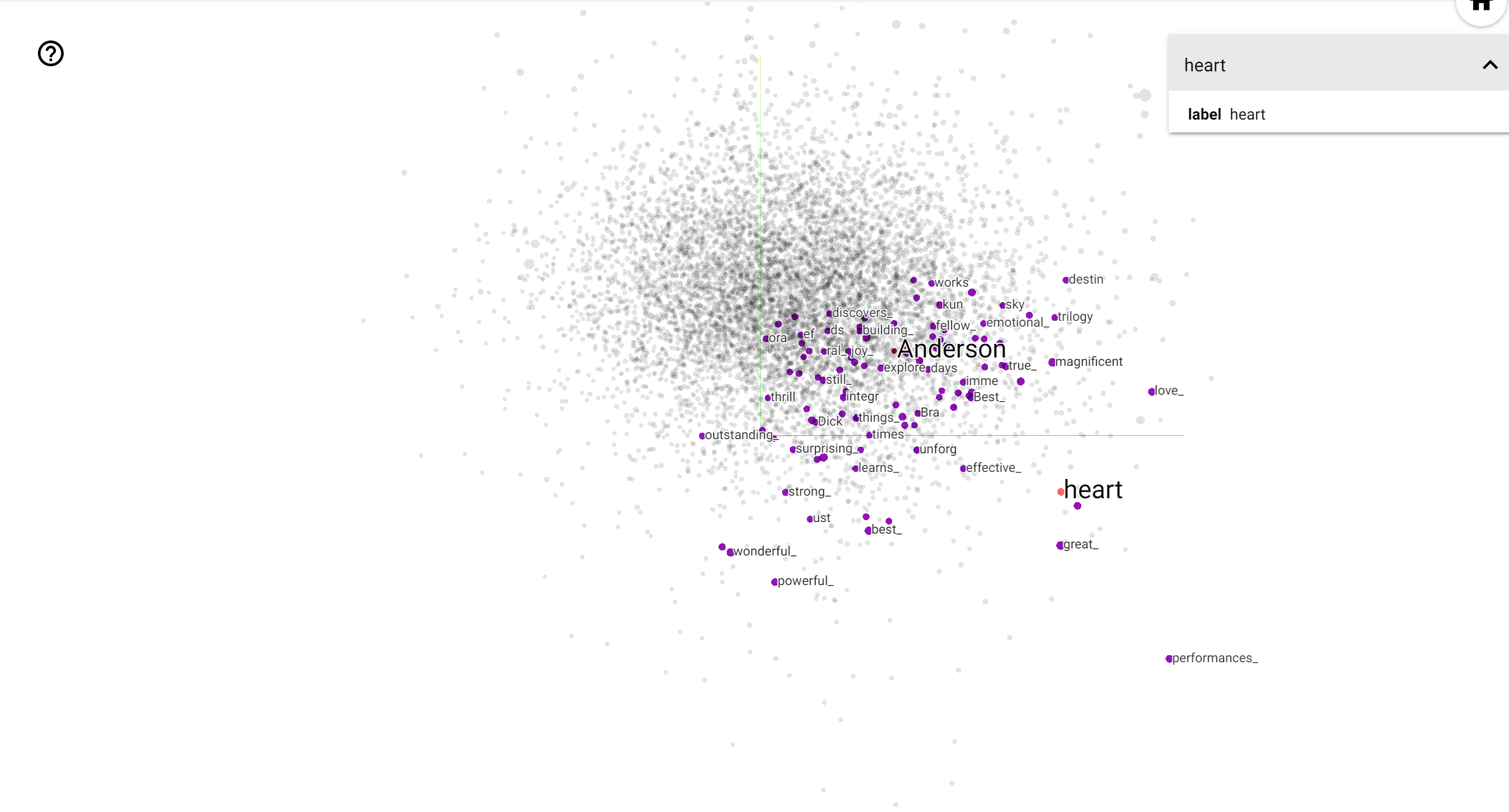
분석
TensorBoard Projector는 임베딩을 해석하고 시각화하기 위한 훌륭한 도구입니다. 대시보드를 통해 사용자는 특정 용어를 검색하고 임베딩(저차원) 공간에서 서로 인접한 단어를 강조 표시할 수 있습니다. 이 예에서 우리는 웨스 앤더슨과 알프레드 히치콕 모두 다소 중립적 인 용어입니다,하지만 서로 다른 상황에서 참조되는 것을 볼 수 있습니다.
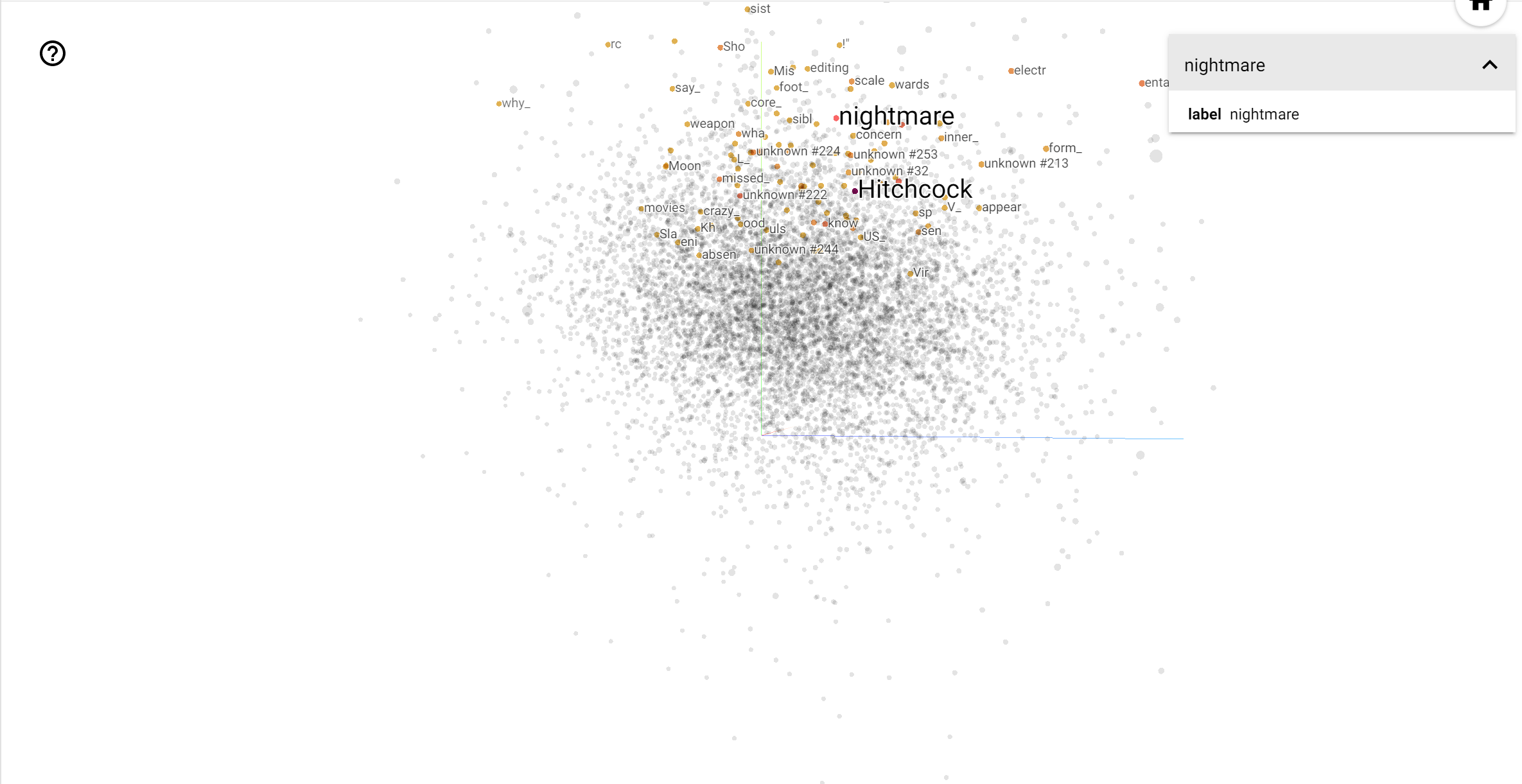
이 공간에서, 히치콕 가까이 같은 단어입니다 nightmare 앤더슨 가까이 단어에 반면, 때문에 그가 "서스펜스의 마스터"로 알려져 있다는 사실 가능성이 heart 그의 가차 설명하고 훈훈한 스타일과 일치, .