
データが TFX パイプラインに入ると、TFX コンポーネントを使用してデータを分析および変換できます。これらのツールは、モデルをトレーニングする前でも使用できます。
データを分析して変換する理由はたくさんあります。
- データの問題を見つけるため。一般的な問題には次のようなものがあります。
- 値が空のフィーチャなど、データが欠落しています。
- ラベルは特徴として扱われるため、モデルはトレーニング中に正しい答えを覗くことができます。
- 予想範囲外の値を持つ特徴。
- データの異常。
- 学習済みモデルの転送には、トレーニング データと一致しない前処理があります。
- より効果的な機能セットを設計するため。たとえば、次のことを識別できます。
- 特に有益な機能。
- 冗長な機能。
- 機能の規模が大きく異なるため、学習が遅くなる可能性があります。
- 固有の予測情報がほとんど、またはまったくない特徴。
TFX ツールは、データのバグの発見と特徴エンジニアリングの両方に役立ちます。
TensorFlow データの検証
概要
TensorFlow Data Validation は、データのトレーニングと提供における異常を特定し、データを検査することでスキーマを自動的に作成できます。このコンポーネントは、データ内のさまざまなクラスの異常を検出するように構成できます。できる
- データ統計をユーザーの期待を成文化したスキーマと比較することにより、妥当性チェックを実行します。
- トレーニング データとサービング データの例を比較することで、トレーニングとサービングのスキューを検出します。
- 一連のデータを調べてデータ ドリフトを検出します。
これらの各機能を個別に文書化します。
スキーマベースの例の検証
TensorFlow データ検証は、データ統計をスキーマと比較することにより、入力データ内の異常を特定します。スキーマは、データ型やカテゴリ値など、入力データが満たすことが期待されるプロパティを体系化しており、ユーザーが変更または置き換えることができます。
Tensorflow データ検証は通常、TFX パイプラインのコンテキスト内で複数回呼び出されます: (i) ExampleGen から取得されたすべての分割に対して、(ii) Transform によって使用されるすべての変換前データに対して、(iii) によって生成されたすべての変換後データに対して変身。 Transform (ii-iii) のコンテキストで呼び出すと、 stats_options_updater_fnを定義することで統計オプションとスキーマベースの制約を設定できます。これは、非構造化データ (テキスト特徴など) を検証する場合に特に役立ちます。例については、ユーザー コードを参照してください。
高度なスキーマ機能
このセクションでは、特別なセットアップに役立つ、より高度なスキーマ構成について説明します。
まばらな特徴
例で疎な特徴をエンコードすると、通常、すべての例で同じ価数を持つことが期待される複数の特徴が導入されます。たとえば、スパース機能の場合は次のようになります。
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
スパース機能定義には、スキーマ内に存在する機能を参照する 1 つ以上のインデックスと 1 つの値機能が必要です。スパース特徴を明示的に定義すると、TFDV は参照されるすべての特徴の結合価が一致することを確認できます。
一部のユースケースでは、フィーチャ間に同様の結合価制限が導入されますが、必ずしもスパースなフィーチャをエンコードするわけではありません。スパース機能を使用するとブロックは解除されますが、理想的ではありません。
スキーマ環境
デフォルトの検証では、パイプライン内のすべてのサンプルが単一のスキーマに準拠していると想定されます。場合によっては、わずかなスキーマの変更を導入する必要があります。たとえば、ラベルとして使用される特徴はトレーニング中に必要ですが (検証する必要があります)、提供中には欠落します。環境、特に、 default_environment() 、 in_environment() 、 not_in_environment()などの要件を表現するために使用できます。
たとえば、「LABEL」という名前の特徴がトレーニングには必要だが、提供されないことが予想されるとします。これは次のように表現できます。
- スキーマ内に 2 つの異なる環境 ["SERVING"、"TRAINING"] を定義し、'LABEL' を環境 "TRAINING" にのみ関連付けます。
- トレーニング データを環境「TRAINING」に関連付け、サービング データを環境「SERVING」に関連付けます。
スキーマの生成
入力データ スキーマは TensorFlow Schemaのインスタンスとして指定されます。
開発者は、スキーマを最初から手動で構築する代わりに、TensorFlow Data Validation の自動スキーマ構築を利用できます。具体的には、TensorFlow Data Validation は、パイプラインで利用可能なトレーニング データに対して計算された統計に基づいて、初期スキーマを自動的に構築します。ユーザーは、この自動生成されたスキーマを確認し、必要に応じて変更し、バージョン管理システムにチェックインして、さらに検証するためにパイプラインに明示的にプッシュするだけです。
TFDV には、スキーマを自動的に生成するinfer_schema()が含まれています。例えば:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
これにより、次のルールに基づいてスキーマの自動生成がトリガーされます。
スキーマがすでに自動生成されている場合は、そのまま使用されます。
それ以外の場合、TensorFlow Data Validation は利用可能なデータ統計を調べ、データに適したスキーマを計算します。
注: 自動生成されたスキーマはベストエフォート型であり、データの基本的なプロパティの推論のみを試みます。ユーザーが必要に応じてレビューし、変更することが期待されます。
トレーニングとサービングのスキュー検出
概要
TensorFlow Data Validation は、トレーニング データと提供データの間の分散スキューを検出できます。分布の偏りは、トレーニング データの特徴量の分布が提供データと大きく異なる場合に発生します。分布の偏りの主な原因の 1 つは、目的のコーパス内の初期データの不足を克服するために、トレーニング データの生成にまったく異なるコーパスを使用することです。もう 1 つの理由は、トレーニングの対象となるサービス データのサブサンプルのみを選択するサンプリング メカニズムに欠陥があることです。
シナリオ例
トレーニングとサービングのスキュー検出の構成については、「TensorFlow Data Validation スタート ガイド」を参照してください。
ドリフト検出
ドリフト検出は、異なる日のトレーニング データ間など、データの連続するスパン間 (つまり、スパン N とスパン N+1 の間) でサポートされます。カテゴリ特徴量の場合はL 無限距離の観点からドリフトを表現し、数値特徴量の場合は近似ジェンセン-シャノン発散度で表現します。ドリフトが許容範囲を超えた場合に警告を受け取るように、しきい値距離を設定できます。正しい距離を設定するには、通常、ドメインの知識と実験が必要な反復プロセスが必要です。
ドリフト検出の構成については、 「TensorFlow Data Validation スタート ガイド」を参照してください。
ビジュアライゼーションを使用してデータを確認する
TensorFlow Data Validation は、特徴値の分布を視覚化するためのツールを提供します。ファセットを使用して Jupyter ノートブックでこれらの分布を調べることにより、データに関する一般的な問題を見つけることができます。
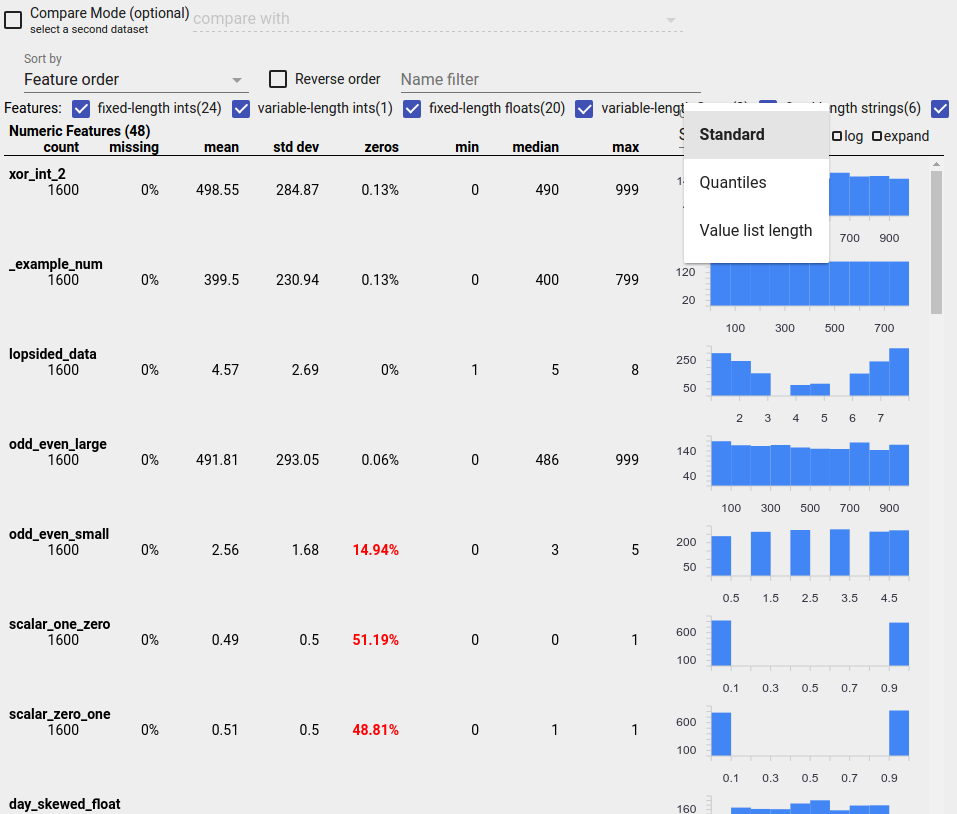
不審な配布の特定
ファセット概要表示を使用して特徴値の疑わしい分布を探すことにより、データ内の一般的なバグを特定できます。
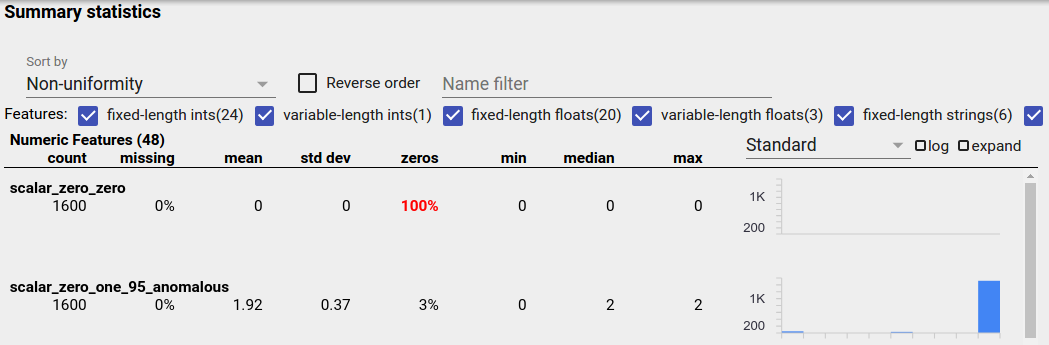
不均衡なデータ
アンバランスなフィーチャとは、1 つの値が優勢なフィーチャです。アンバランスな特徴は自然に発生する可能性がありますが、特徴が常に同じ値を持つ場合は、データ バグが発生している可能性があります。ファセット概要で不均衡な特徴を検出するには、「並べ替え基準」ドロップダウンから「不均一性」を選択します。
最もアンバランスな機能が、各機能タイプのリストの先頭にリストされます。たとえば、次のスクリーンショットは、「数値特徴」リストの上部にあるすべて 0 の 1 つの特徴と、非常に不均衡な 2 つ目の特徴を示しています。
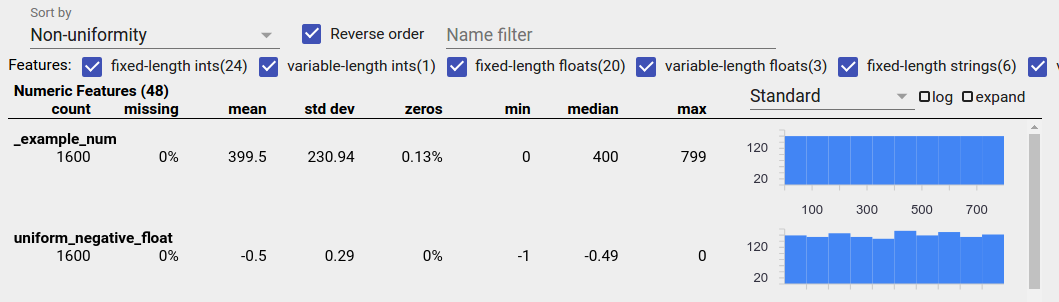
均一に分散されたデータ
均一に分散された特徴とは、すべての可能な値がほぼ同じ頻度で現れる特徴です。不均衡なデータと同様、この分布は自然に発生する場合もありますが、データのバグによって発生する場合もあります。
ファセット概要で均一に分散された特徴を検出するには、「並べ替え基準」ドロップダウンから「不均一性」を選択し、「順序を逆にする」チェックボックスをオンにします。
文字列データは、一意の値が 20 個以下の場合は棒グラフを使用して表され、一意の値が 20 個を超える場合は累積分布グラフとして表されます。したがって、文字列データの場合、一様分布は、上記のような平坦な棒グラフまたは以下のような直線のいずれかとして表示されます。

均一に分散されたデータを生成する可能性のあるバグ
以下に、均一に分散されたデータを生成する可能性のある一般的なバグをいくつか示します。
文字列を使用して日付などの非文字列データ型を表現します。たとえば、日時特徴には、「2017-03-01-11-45-03」のような表現を持つ固有の値が多数存在します。固有の値は均一に分散されます。
「行番号」などのインデックスを特徴として含めます。ここにも多くのユニークな値があります。
欠落データ
特徴量に値が完全に欠落しているかどうかを確認するには、次のようにします。
- 「並べ替え基準」ドロップダウンから「欠損金額/ゼロ」を選択します。
- 「逆順」チェックボックスにチェックを入れます。
- 「欠損」列を参照して、機能の欠損値を持つインスタンスの割合を確認します。
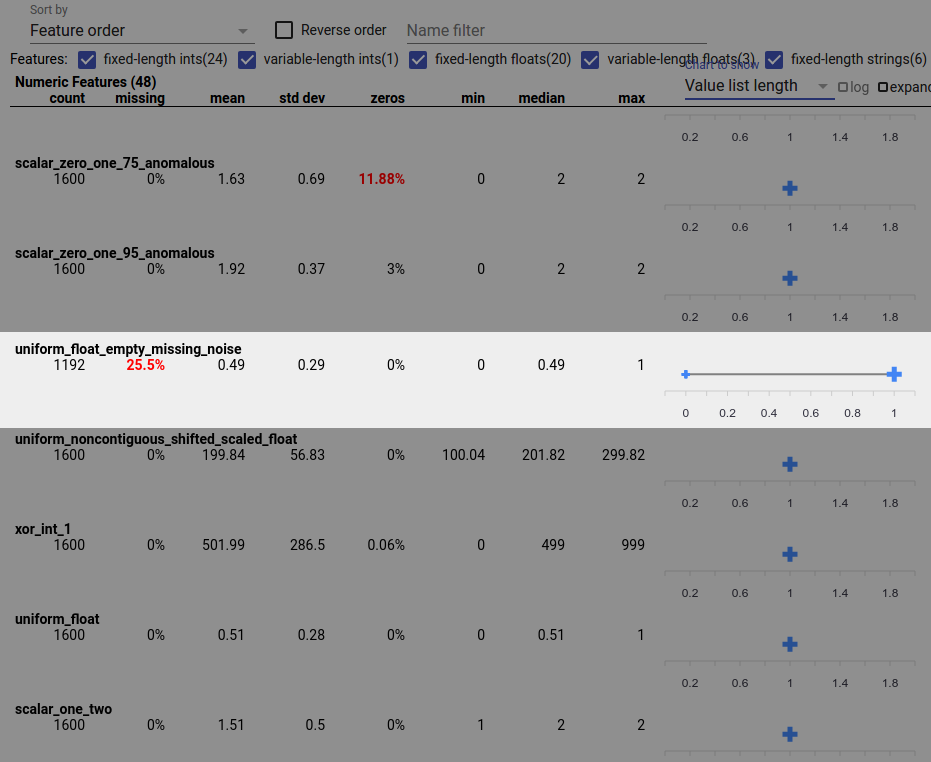
データのバグにより、特徴値が不完全になる可能性もあります。たとえば、機能の値リストには常に 3 つの要素があると予想していましたが、場合によっては 1 つしか要素がないことが判明する場合があります。不完全な値、または特徴値リストに予期される数の要素がない場合を確認するには、次のようにします。
右側の「表示するグラフ」ドロップダウン メニューから「値リストの長さ」を選択します。
各機能行の右側にあるグラフを見てください。このグラフは、機能の値リストの長さの範囲を示しています。たとえば、以下のスクリーンショットで強調表示されている行は、長さ 0 の値リストがいくつかあるフィーチャーを示しています。
フィーチャ間のスケールの大きな違い
特徴の規模が大きく異なる場合、モデルの学習が困難になる可能性があります。たとえば、ある特徴が 0 から 1 まで変化し、他の特徴が 0 から 1,000,000,000 まで変化する場合、スケールに大きな違いが生じます。特徴全体の「最大」列と「最小」列を比較して、大きく異なるスケールを見つけます。
このような大きな変動を減らすために、特徴値を正規化することを検討してください。
無効なラベルを含むラベル
TensorFlow の Estimator には、ラベルとして受け入れるデータのタイプに制限があります。たとえば、バイナリ分類子は通常、{0, 1} ラベルでのみ機能します。
ファセットの概要でラベルの値を確認し、それらがEstimators の要件に準拠していることを確認します。