
Les indicateurs d'équité sont conçus pour aider les équipes à évaluer et à améliorer les modèles pour des problèmes d'équité en partenariat avec la boîte à outils Tensorflow plus large. L'outil est actuellement activement utilisé en interne par bon nombre de nos produits et est désormais disponible en version BETA pour essayer vos propres cas d'utilisation.
Qu’est-ce que les indicateurs d’équité ?
Fairness Indicators est une bibliothèque qui permet de calculer facilement des mesures d'équité communément identifiées pour les classificateurs binaires et multiclasses. De nombreux outils existants pour évaluer les problèmes d’équité ne fonctionnent pas bien sur des ensembles de données et des modèles à grande échelle. Chez Google, il est important pour nous de disposer d'outils capables de fonctionner sur des systèmes comptant des milliards d'utilisateurs. Les indicateurs d’équité vous permettront d’évaluer n’importe quelle taille de cas d’utilisation.
En particulier, les indicateurs d’équité incluent la capacité de :
- Évaluer la distribution des ensembles de données
- Évaluez les performances du modèle, réparties sur des groupes d'utilisateurs définis
- Ayez confiance en vos résultats grâce à des intervalles de confiance et des évaluations à plusieurs seuils
- Plongez en profondeur dans les tranches individuelles pour explorer les causes profondes et les opportunités d'amélioration.
Le téléchargement du package pip comprend :
- Validation des données Tensorflow (TFDV)
- Analyse du modèle Tensorflow (TFMA)
- Indicateurs d'équité
- L'outil de simulation (WIT)
Utiliser des indicateurs d'équité avec des modèles Tensorflow
Données
Pour exécuter des indicateurs d'équité avec TFMA, assurez-vous que l'ensemble de données d'évaluation est étiqueté pour les fonctionnalités que vous souhaitez découper. Si vous ne disposez pas des fonctionnalités de tranche exactes pour vos problèmes d'équité, vous pouvez essayer de trouver un ensemble d'évaluation qui le fait, ou envisager des fonctionnalités proxy au sein de votre ensemble de fonctionnalités qui peuvent mettre en évidence les disparités de résultats. Pour des conseils supplémentaires, voir ici .
Modèle
Vous pouvez utiliser la classe Tensorflow Estimator pour créer votre modèle. La prise en charge des modèles Keras sera bientôt disponible sur TFMA. Si vous souhaitez exécuter TFMA sur un modèle Keras, veuillez consulter la section « TFMA indépendant du modèle » ci-dessous.
Une fois votre estimateur formé, vous devrez exporter un modèle enregistré à des fins d'évaluation. Pour en savoir plus, consultez le guide TFMA .
Configuration des tranches
Ensuite, définissez les tranches sur lesquelles vous souhaitez évaluer :
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
Si vous souhaitez évaluer des tranches intersectionnelles (par exemple, la couleur et la hauteur de la fourrure), vous pouvez définir les éléments suivants :
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
Calculer les mesures d'équité
Ajoutez un rappel d’indicateurs d’équité à la liste metrics_callback . Dans le rappel, vous pouvez définir une liste de seuils auxquels le modèle sera évalué.
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
Avant d'exécuter la configuration, déterminez si vous souhaitez ou non activer le calcul des intervalles de confiance. Les intervalles de confiance sont calculés à l'aide du bootstrap de Poisson et nécessitent un recalcul sur 20 échantillons.
compute_confidence_intervals = True
Exécutez le pipeline d'évaluation TFMA :
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
Indicateurs d’équité du rendu
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
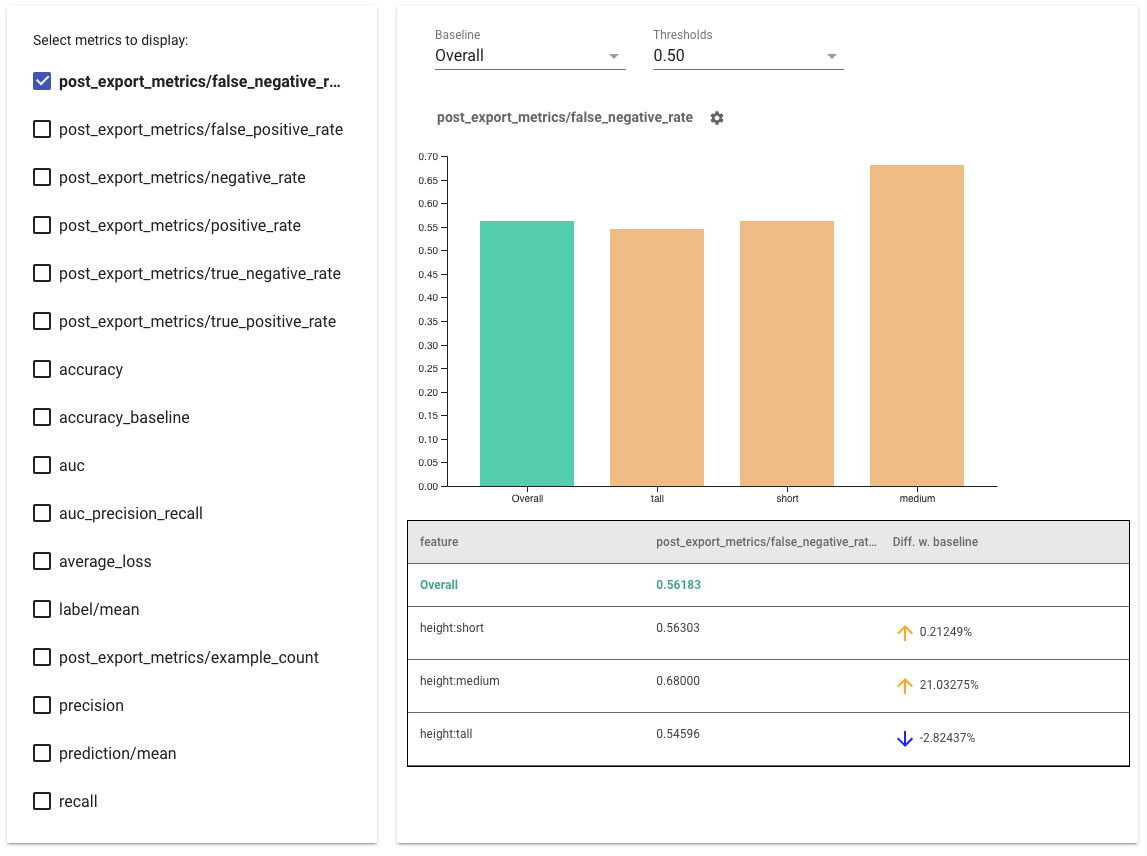
Conseils d’utilisation des indicateurs d’équité :
- Sélectionnez les métriques à afficher en cochant les cases sur le côté gauche. Des graphiques individuels pour chacune des métriques apparaîtront dans le widget, dans l'ordre.
- Modifiez la tranche de base , la première barre du graphique, à l'aide du sélecteur déroulant. Les deltas seront calculés avec cette valeur de référence.
- Sélectionnez les seuils à l’aide du sélecteur déroulant. Vous pouvez afficher plusieurs seuils sur le même graphique. Les seuils sélectionnés seront en gras et vous pouvez cliquer sur un seuil en gras pour le désélectionner.
- Passez la souris sur une barre pour voir les métriques de cette tranche.
- Identifiez les disparités avec la ligne de base à l’aide de la colonne « Diff w. baseline », qui identifie la différence en pourcentage entre la tranche actuelle et la ligne de base.
- Explorez les points de données d'une tranche en profondeur à l'aide de l' outil What-If . Voir ici pour un exemple.
Rendu des indicateurs d'équité pour plusieurs modèles
Les indicateurs d’équité peuvent également être utilisés pour comparer des modèles. Au lieu de transmettre un seul eval_result, transmettez un objet multi_eval_results, qui est un dictionnaire mappant deux noms de modèle aux objets eval_result.
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
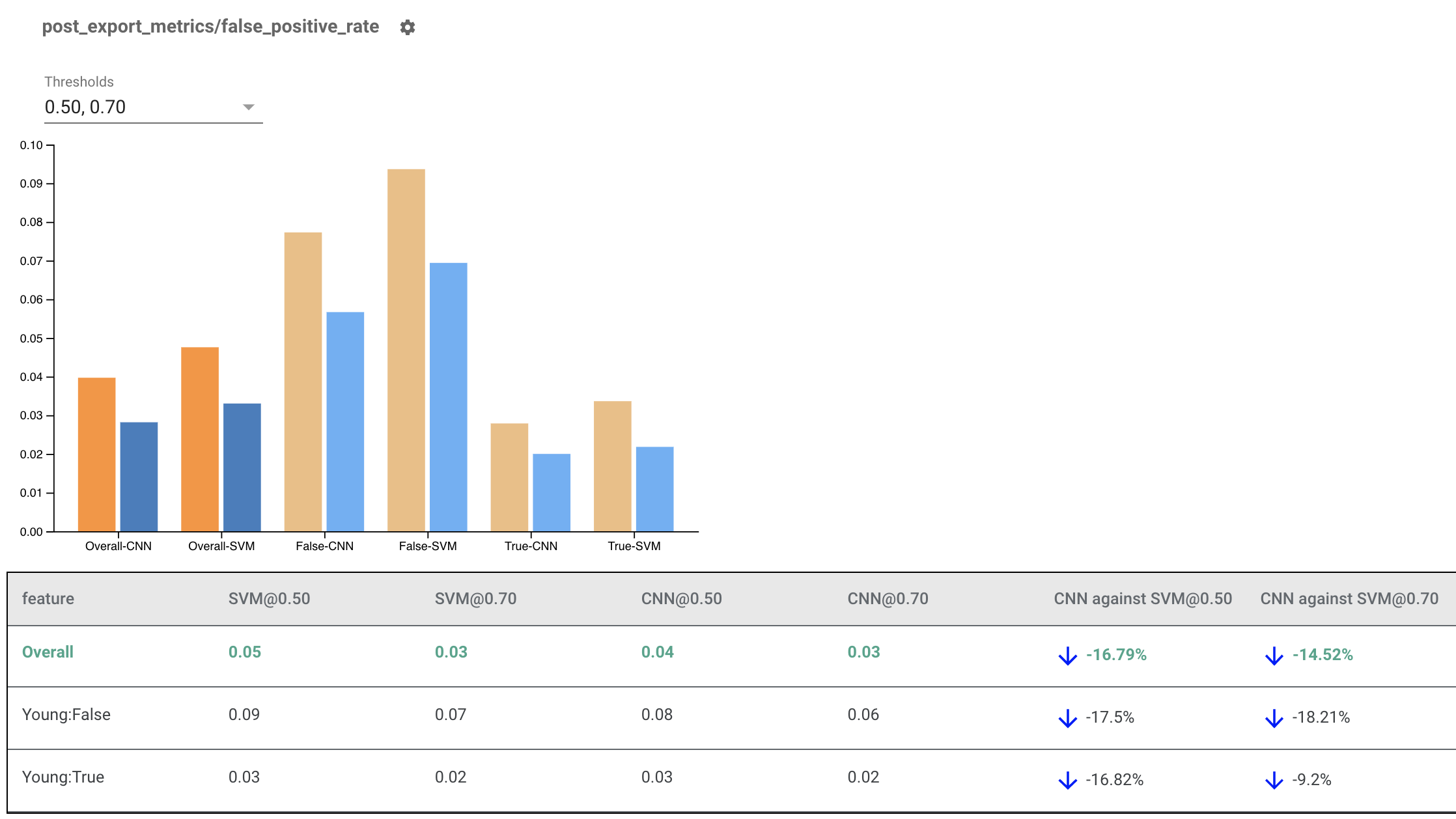
La comparaison de modèles peut être utilisée parallèlement à la comparaison de seuils. Par exemple, vous pouvez comparer deux modèles à deux ensembles de seuils pour trouver la combinaison optimale pour vos mesures d'équité.
Utiliser des indicateurs d'équité avec des modèles non TensorFlow
Pour mieux prendre en charge les clients qui ont différents modèles et flux de travail, nous avons développé une bibliothèque d'évaluation indépendante du modèle évalué.
Toute personne souhaitant évaluer son système d'apprentissage automatique peut l'utiliser, surtout si vous disposez de modèles non basés sur TensorFlow. À l'aide du SDK Apache Beam Python, vous pouvez créer un binaire d'évaluation TFMA autonome, puis l'exécuter pour analyser votre modèle.
Données
Cette étape consiste à fournir l’ensemble de données sur lequel vous souhaitez que les évaluations soient exécutées. Il doit être au format tf.Example proto comportant des étiquettes, des prédictions et d'autres fonctionnalités sur lesquelles vous pourriez vouloir découper.
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
Modèle
Au lieu de spécifier un modèle, vous créez une configuration d'évaluation et un extracteur indépendants du modèle pour analyser et fournir les données dont TFMA a besoin pour calculer les métriques. La spécification ModelAgnosticConfig définit les fonctionnalités, les prédictions et les étiquettes à utiliser à partir des exemples d'entrée.
Pour cela, créez une carte de fonctionnalités avec des clés représentant toutes les fonctionnalités, y compris des clés d'étiquette et de prédiction et des valeurs représentant le type de données de la fonctionnalité.
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
Créez une configuration indépendante du modèle à l'aide de clés d'étiquette, de clés de prédiction et de la carte des fonctionnalités.
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
Configurer un extracteur indépendant du modèle
L'extracteur est utilisé pour extraire les fonctionnalités, les étiquettes et les prédictions de l'entrée à l'aide d'une configuration indépendante du modèle. Et si vous souhaitez découper vos données, vous devez également définir la spécification de la clé de tranche , contenant des informations sur les colonnes sur lesquelles vous souhaitez découper.
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
Calculer les mesures d'équité
Dans le cadre de EvalSharedModel , vous pouvez fournir toutes les métriques sur lesquelles vous souhaitez que votre modèle soit évalué. Les métriques sont fournies sous la forme de rappels de métriques comme ceux définis dans post_export_metrics ou fairness_indicators .
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
Il intègre également un construct_fn qui est utilisé pour créer un graphe tensorflow pour effectuer l'évaluation.
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
Une fois que tout est configuré, utilisez l'une des fonctions ExtractEvaluate ou ExtractEvaluateAndWriteResults fournies par model_eval_lib pour évaluer le modèle.
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
Enfin, restituez les indicateurs d'équité en suivant les instructions de la section « Rendu des indicateurs d'équité » ci-dessus.
Plus d'exemples
Le répertoire d’exemples d’indicateurs d’équité contient plusieurs exemples :
- Fairness_Indicators_Example_Colab.ipynb donne un aperçu des indicateurs d'équité dans l'analyse du modèle TensorFlow et comment les utiliser avec un ensemble de données réel. Ce bloc-notes passe également en revue TensorFlow Data Validation et What-If Tool , deux outils d'analyse des modèles TensorFlow fournis avec des indicateurs d'équité.
- Fairness_Indicators_on_TF_Hub.ipynb montre comment utiliser les indicateurs d'équité pour comparer des modèles formés sur différentes intégrations de texte . Ce notebook utilise des intégrations de texte de TensorFlow Hub , la bibliothèque de TensorFlow pour publier, découvrir et réutiliser les composants du modèle.
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb montre comment visualiser les indicateurs d'équité dans TensorBoard.