
借助 TFX 流水线,您可以使用诸如 Apache Airflow、Apache Beam 和 Kubeflow Pipelines 之类的编排器来编排机器学习 (ML) 工作流。流水线可将您的工作流组织成一系列组件,其中的每个组件均执行 ML 工作流中的一个步骤。TFX 标准组件提供了经过验证的功能,可帮助您轻松地着手构建 ML 工作流。您还可以在工作流中添加自定义组件。自定义组件可通过以下方式帮助您扩展 ML 工作流:
- 构建为满足您的需求(例如从专有系统中提取数据)而量身定制的组件。
- 应用数据扩充、上采样或降采样。
- 基于置信区间或自动编码器重现误差执行异常检测。
- 连接外部系统(例如帮助中心)以实现报警和监控。
- 对无标签样本应用标签。
- 将使用 Python 以外的语言构建的工具集成到 ML 工作流中,例如使用 R 语言执行数据分析。
通过将标准组件和自定义组件搭配使用,您可以构建满足自身需求的 ML 工作流,同时充分利用 TFX 标准组件中内置的最佳做法。
本指南介绍理解 TFX 自定义组件所需的概念,以及构建自定义组件的不同方式。
TFX 组件剖析
本部分简要地概述了 TFX 组件的组成。如果您对 TFX 流水线尚不熟悉,请阅读帮助理解 TFX 流水线的指南以学习核心概念。
TFX 组件由组件规范和执行器类组成,二者包装在组件接口类中。
组件规范定义组件的输入和输出协定。此协定指定组件的输入和输出工件,以及用于组件执行的参数。
组件的执行器类为组件执行的工作提供实现。
组件接口类将组件规范与执行器组合在一起,用作 TFX 流水线中的组件。
运行时 TFX 组件
当流水线运行 TFX 组件时,该组件将分三个阶段执行:
- 首先,驱动器会使用组件规范从 Metadata Store 中检索所需的工件,并将其传递到组件中。
- 接下来,执行器将执行组件的工作。
- 然后,发布器将使用组件规范和执行器所生成的结果,将组件的输出存储在 Metadata Store 中。
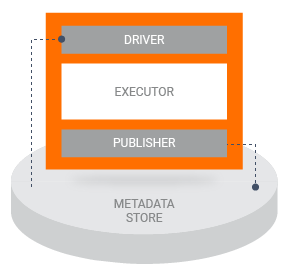
大多数自定义组件的实现都不需要您自定义驱动器或发布器。通常,只有在您想要更改流水线的组件与 Metadata Store 之间的交互方式时,才需要对驱动器和发布器进行修改。如果您只想更改组件的输入、输出或参数,只需修改组件规范即可。
自定义组件的类型
有三种类型的自定义组件:基于 Python 函数的组件、基于容器的组件和完全自定义组件。以下各部分介绍了不同类型的组件以及每种方式适用的用例。
基于 Python 函数的组件
与基于容器的组件或完全自定义组件相比,基于 Python 函数的组件更易于构建。组件规范在 Python 函数的参数中使用类型注解进行定义,类型注解描述了参数是输入工件、输出工件还是参数。函数体定义组件的执行器。组件接口通过在函数中添加 @component 装饰器进行定义。
使用 @component 装饰器装饰函数并使用类型注解定义函数参数即可创建组件,无需执行构建组件规范、执行器和组件接口的复杂工作。
了解如何构建基于 Python 函数的组件。
基于容器的组件
基于容器的组件可将以任何语言编写的代码灵活地集成到您的流水线中,只要您可以在 Docker 容器中执行该代码即可。要创建基于容器的组件,您必须构建一个包含组件的可执行代码的 Docker 容器镜像。然后,您必须调用 create_container_component 函数来定义以下各项:
- 组件规范的输入、输出和参数。
- 组件执行器运行的容器镜像和命令。
此函数返回可包含在流水线定义中的组件实例。
这种方式与构建基于 Python 函数的组件相比要复杂得多,因为它需要将您的代码打包为容器镜像。这种方式最适用于在流水线中包含非 Python 代码,或者用于构建具有复杂运行时环境或依赖项的 Python 组件。
了解如何构建基于容器的组件。
完全自定义组件
借助完全自定义组件,您可以通过定义组件规范、执行器和组件接口类来构建组件。您可以通过这种方式重用和扩展标准组件以满足您的需求。
如果您开发的自定义组件与定义现有组件所用的输入和输出相同,则只需重写现有组件的执行器类即可。这意味着您可以重用组件规范并实现派生自现有组件的新执行器。这样,您可以重用现有组件中内置的功能,并仅实现所需的功能。
不过,如果新组件的输入和输出是唯一的,您可以定义全新的组件规范。
这种方式最适合重用现有组件规范和执行器。
了解如何构建完全自定义组件。