
简介
TFX 是一种基于 TensorFlow 的 Google 生产级机器学习 (ML) 平台。该平台提供了一个配置框架和众多共享库,用来集成定义、启动和监控机器学习系统所需的常见组件。
TFX 1.0
我们非常高兴地宣布,TFX 1.0.0 现已推出。这是 TFX 的初始 Beta 后版本,可提供稳定的公共 API 和工件。请放心,在该 RFC 中定义的兼容性范围内进行升级后,您的未来 TFX 流水线会继续运行。
安装

![]()
pip install tfx
每夜版软件包
TFX 还通过 Google Cloud 在 https://pypi-nightly.tensorflow.org 上托管了每夜版软件包。如需安装最新的每夜版软件包,请使用以下命令:
pip install -i https://pypi-nightly.tensorflow.org/simple --pre tfx
上述命令会安装 TFX 的主要依赖项的每夜版软件包,例如 TensorFlow Model Analysis (TFMA)、TensorFlow Data Validation (TFDV)、TensorFlow Transform (TFT)、TFX Basic Shared Libraries (TFX-BSL)、ML Metadata (MLMD)。
关于 TFX
TFX 是一个在生产环境中构建和管理机器学习工作流程的平台。TFX 提供以下功能:
用于构建机器学习流水线的工具包。借助 TFX 流水线,您可以在多个平台上编排机器学习工作流,例如 Apache Airflow、Apache Beam 和 Kubeflow Pipelines 平台。
一组标准组件,可用作流水线的一部分,或用作机器学习训练脚本的一部分。TFX 标准组件提供久经考验的功能,可帮助您轻松开始构建机器学习流程。
为许多标准组件提供基本功能的库。您可以使用 TFX 库将此功能添加到自己的自定义组件中,也可以单独使用它们。
TFX 是一种基于 TensorFlow 的 Google 生产级机器学习工具包。 该平台提供了一个配置框架和众多共享库,用来集成定义、启动和监控机器学习系统所需的常见组件。
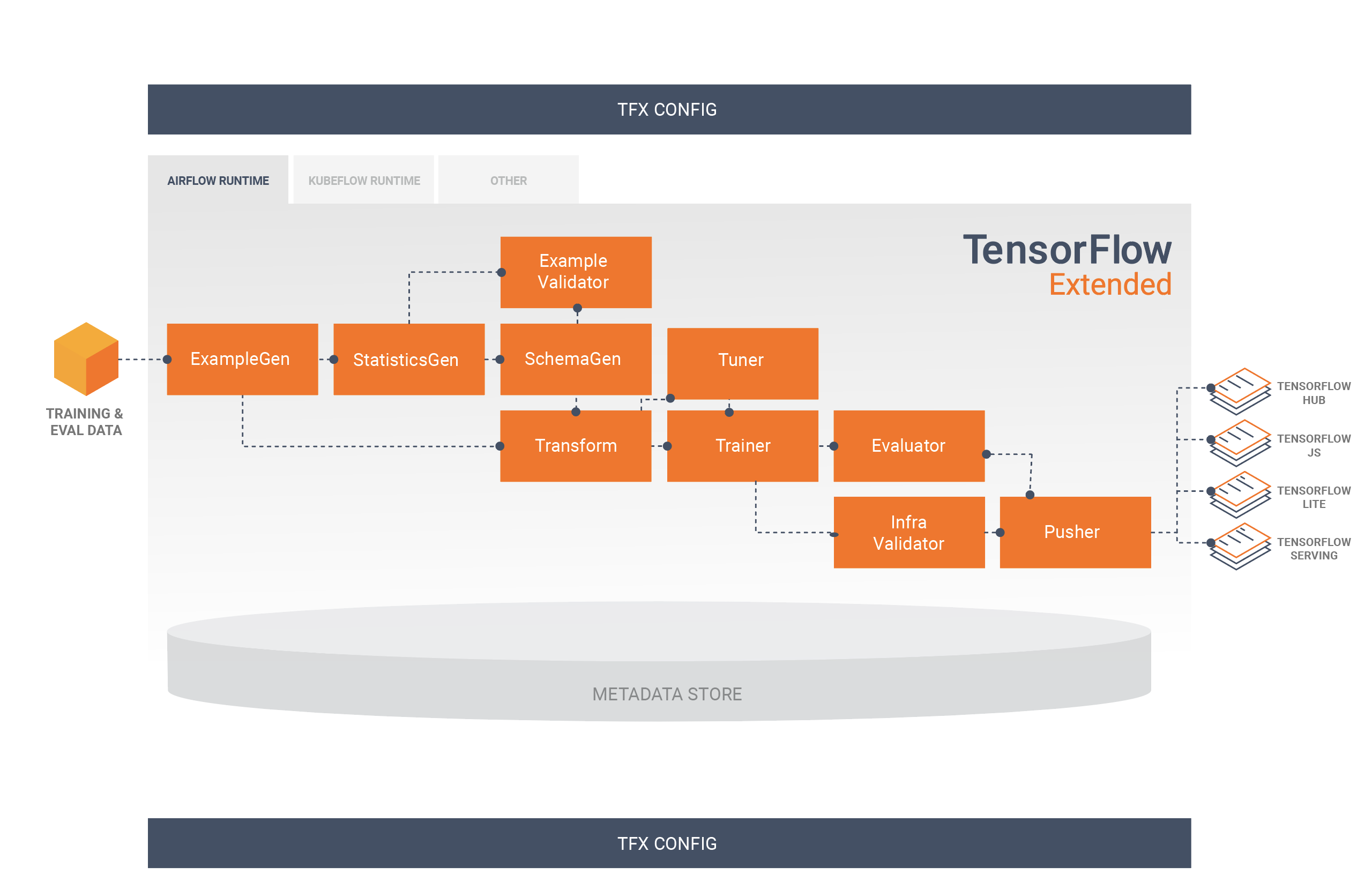
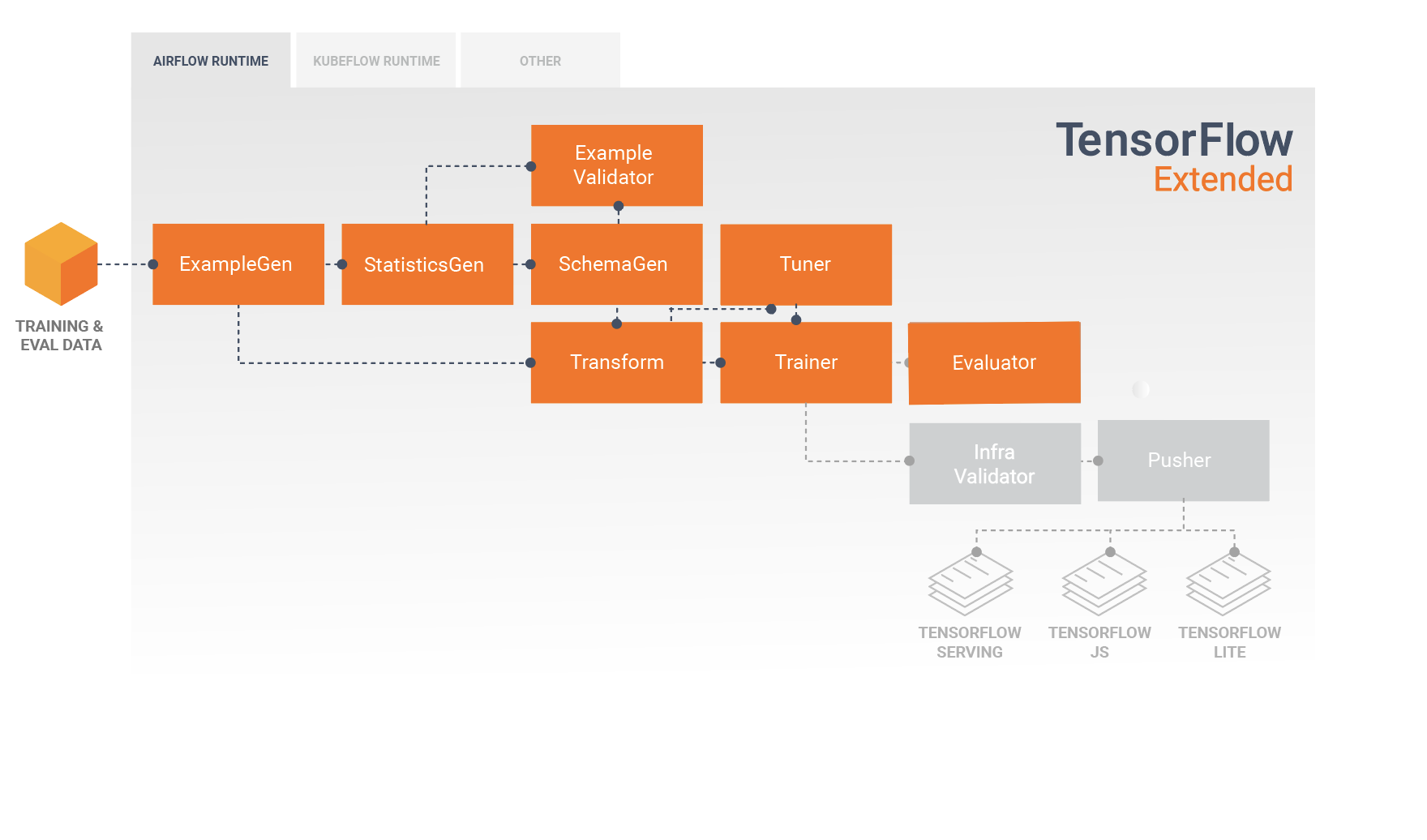
TFX 标准组件
TFX 流水线是实现机器学习流水线的一系列组件,专门用于可扩容的高性能机器学习任务。这包括针对在线、原生移动和 JavaScript 目标建模、训练、运行推断和管理部署。
TFX 流水线通常包含以下组件:
ExampleGen:提取和拆分(可选)输入数据集的流水线的初始输入组件。
StatisticsGen:计算数据集的统计信息。
SchemaGen:检查统计信息和创建数据架构。
ExampleValidator:查找数据集中的异常情况和缺失的值。
Transform:对数据集执行特征工程。
Trainer:训练模型。
Tuner:调整模型的超参数。
Evaluator:对训练结果进行深入分析,并帮助您验证导出的模型,确保它们“效果足够好”,适合投放到生产环境。
InfraValidator:检查模型是否确实可以从基础架构提供服务,并防止投放不良模型。
Pusher:将模型部署到服务基础架构。
BulkInferrer:对存在无标签推断请求的模型执行批处理。
下图说明了这些组件之间的数据流:
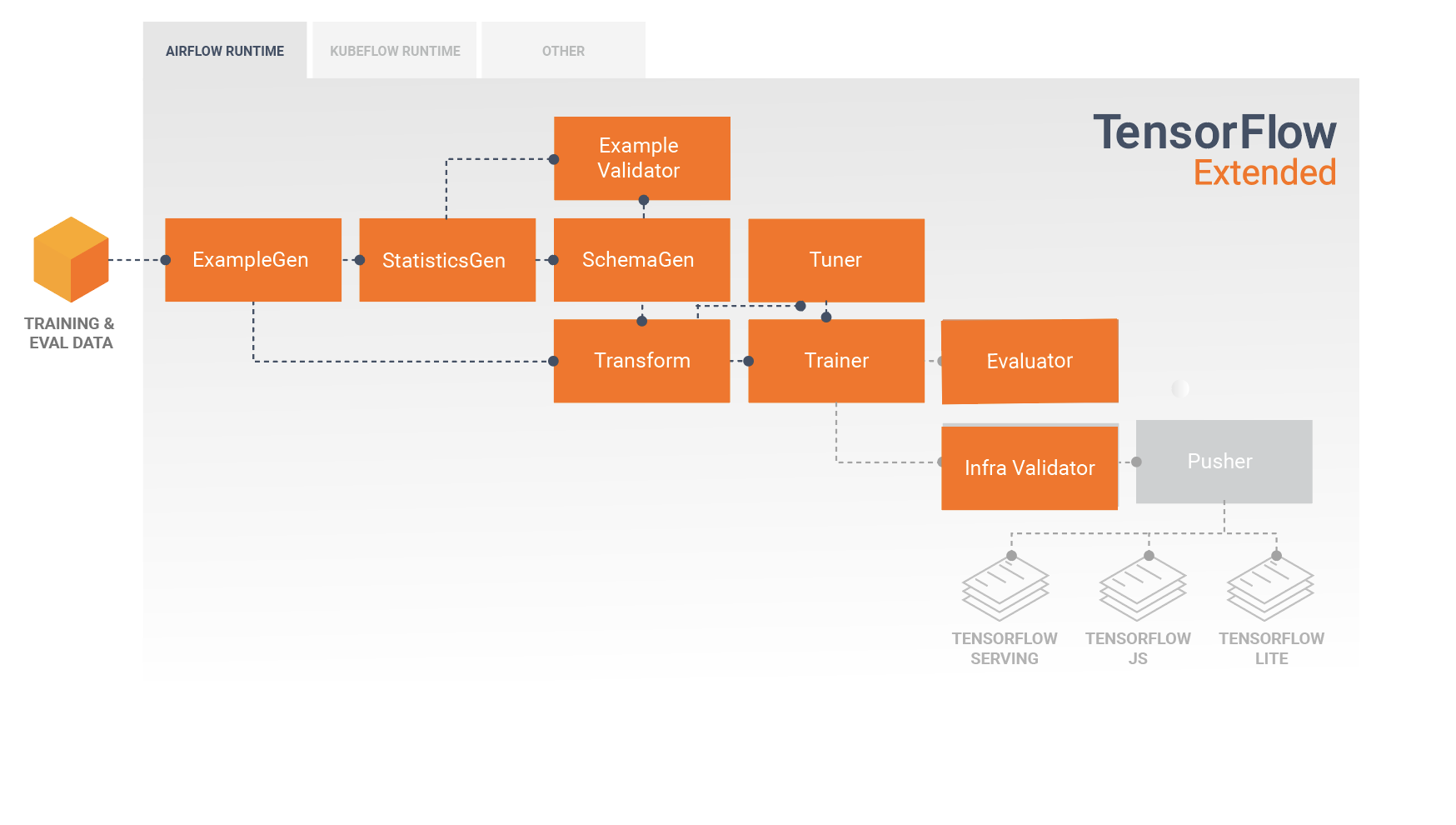
TFX 库
TFX 同时包含库和流水线组件。下图说明了 TFX 库与流水线组件之间的关系:
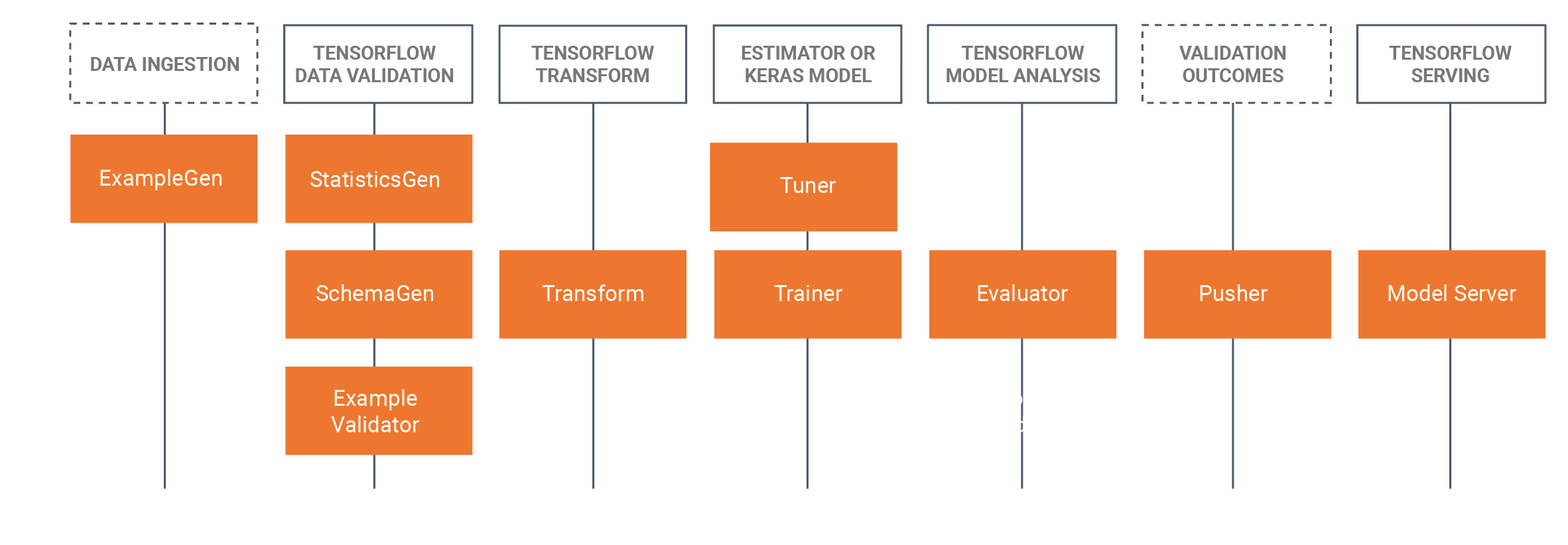
TFX 提供了几个 Python 软件包,它们是用于创建流水线组件的库。您可以使用这些库创建流水线组件,以便您的代码侧重于流水线的独特环节。
TFX 库包括:
TensorFlow Data Validation (TFDV),它是用于分析和验证机器学习数据的库。它具有很强的扩容能力,可与 TensorFlow 和 TFX 配合使用。TFDV 包括:
- 对训练和测试数据的摘要统计信息进行可扩容计算。
与数据分布和统计信息查看器集成,以及对数据集对进行分面比较 (Facet)。
自动生成数据架构,以描述对所需值、范围和词汇表等数据的预期。
架构查看器,可帮助您检查架构。
异常检测,用于识别异常情况,例如缺少特征、值超出范围或特征类型有误,等等。
异常查看器,便于您查看哪些特征存在异常,并了解详情以进行修正。
TensorFlow Transform (TFT),它是一种使用 TensorFlow 预处理数据的库。TensorFlow Transform 适用于需要全通的数据,例如:
- 按均值和标准偏差对输入值进行归一化。
- 通过生成所有输入值的词汇表,将字符串转换为整数。
- 根据观察到的数据分布对浮点数进行分桶,将浮点数转换为整数。
TensorFlow,用于使用 TFX 训练模型。它会提取训练数据和建模代码,并创建 SavedModel 结果。它还集成了由 TensorFlow Transform 创建的特征工程流水线,用于预处理输入数据。
KerasTuner,用于调整模型的超参数。
TensorFlow Model Analysis (TFMA),一个用于评估 TensorFlow 模型的库。它与 TensorFlow 一起用来创建 EvalSavedModel,后者将成为其分析依据。它允许用户使用其 Trainer 中定义的相同指标,以分布式方式针对大量数据评估模型。可以针对不同的数据切片计算这些指标,并在 Jupyter 笔记本中可视化它们。
TensorFlow Metadata (TFMD),可提供元数据的标准表示法,在使用 TensorFlow 训练机器学习模型时,这些表示法非常有用。元数据可以在输入数据分析过程中手动生成或自动生成,并且可用于数据验证、探索和转换。元数据序列化格式包括:
- 描述表式数据的架构(例如,tf.Examples)。
- 此类数据集的摘要统计信息集合。
ML Metadata (MLMD),它是一个库,用于记录和检索与机器学习开发者和数据科学家工作流相关的元数据。元数据通常使用 TFMD 表示法。MLMD 使用 SQL-Lite、MySQL 以及其他类似的数据存储区来管理持久性。
支持性技术
必需
- Apache Beam 是一种统一的开源模型,用于定义批次数据和流式数据的并行处理流水线。TFX 使用 Apache Beam 实现数据并行流水线。然后,流水线将由 Beam 支持的某个分布式处理后端执行,这些后端包括 Apache Flink、Apache Spark、Google Cloud Dataflow 等。
可选
Apache Airflow 和 Kubeflow 等 Orchestrator 可以简化机器学习流水线的配置、操作、监控和维护。
Apache Airflow 是一个程序化地编写、安排和监控工作流的平台。TFX 使用 Airflow 将工作流编写为任务的有向无环图 (DAG)。Airflow 调度器会在跟踪指定依赖项的同时,在一组工作器上执行任务。借助丰富的命令行实用程序,对 DAG 进行复杂的更改变得轻而易举。丰富的界面让您很容易可视化在生产模式下运行的流水线,监控进度并根据需要排查问题。如果将工作流定义为代码,它们就会变得更易于维护、控制版本、测试和协同处理。
Kubeflow 旨在让您可以在 Kubernetes 上以可移植、可扩容的方式轻松部署机器学习工作流。Kubeflow 的目标并非重新造轮子,而是让大家能以一种简单直接的方法将机器学习领域的同类最佳开源系统部署到各种基础架构中。Kubeflow Pipelines 让您可以在 Kubeflow 上组合和执行可重现的工作流,并将基于实验和笔记本的体验融入其中。Kubernetes 上的 Kubeflow Pipelines 服务包括托管式元数据存储区、基于容器的编排引擎、笔记本服务器和界面,可帮助用户大规模开发、运行和管理复杂的机器学习流水线。Kubeflow Pipelines SDK 支持程序化地创建和共享流水线组件和组合。
可移植性和互操作性
TFX 可以移植到多种环境和编排框架,包括 Apache Airflow、Apache Beam 和 Kubeflow。它还可以移植到不同的计算平台(包括本地和云端平台),例如 Google Cloud Platform (GCP)。具体而言,TFX 可与多种托管式 GCP 服务互操作,例如使用 Cloud AI Platform 进行训练和预测,以及使用 Cloud Dataflow 进行分布式数据处理,进而实现机器学习生命周期的其他诸多方面。
模型与 SavedModel
模型
模型是训练过程的输出结果。它是训练过程中学到的权重的序列化记录。这些权重随后可用于计算新输入样本的预测值。对于 TFX 和 TensorFlow,“模型”是指包含在此之前学到的权重的检查点。
请注意,“模型”也可能是指对表示如何计算预测的 TensorFlow 计算图的定义(即 Python 文件)。这两种含义可以根据情境互换使用。
SavedModel
- 什么是 SavedModel:它是一种通用、独立于语言、封闭且可恢复的 TensorFlow 模型序列化格式。
- 为什么它如此重要:它可让较高级别的系统使用单一抽象层创建、转换和使用 TensorFlow 模型。
SavedModel 是在生产环境中应用 TensorFlow 模型或为原生移动应用或 JavaScript 应用导出经过训练的模型时推荐使用的序列化格式。例如,如需将模型转换为 REST 服务以进行预测,您可以将该模型序列化为 SavedModel,并使用 TensorFlow Serving 应用该模型。如需了解详情,请参阅应用 TensorFlow 模型。
架构
一些 TFX 组件会使用称为“架构”的输入数据说明。架构是 schema.proto 的实例。架构是一种协议缓冲区,通常称为“protobuf”。架构可以指定特征值的数据类型、是否必须在所有样本中出现某种特征、允许的值范围以及其他属性。使用 TensorFlow Data Validation (TFDV) 的好处之一是,它会通过从训练数据中推断出类型、类别和范围来自动生成架构。
下面是来自架构 protobuf 的摘录:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
以下组件使用了架构:
- TensorFlow Data Validation
- TensorFlow Transform
在典型的 TFX 流水线中,TensorFlow Data Validation 会生成供其他组件使用的架构。
使用 TFX 进行开发
从在本地机器上进行研究、实验和开发一直到部署,TFX 为机器学习项目的每个阶段都提供功能强大的平台。为了避免代码重复和消除潜在的训练/应用偏差,我们强烈建议您实现 TFX 流水线,以便训练模型和部署经过训练的模型,并使用 Transform 组件进行训练和推断,此类组件利用了 TensorFlow Transform 库。这样,您就可以始终如一地使用相同的预处理和分析代码,避免训练用到的数据与在生产环境中提供给经训练模型的数据之间存在差异,并且只需编写该代码一次。
数据探索、可视化和清理
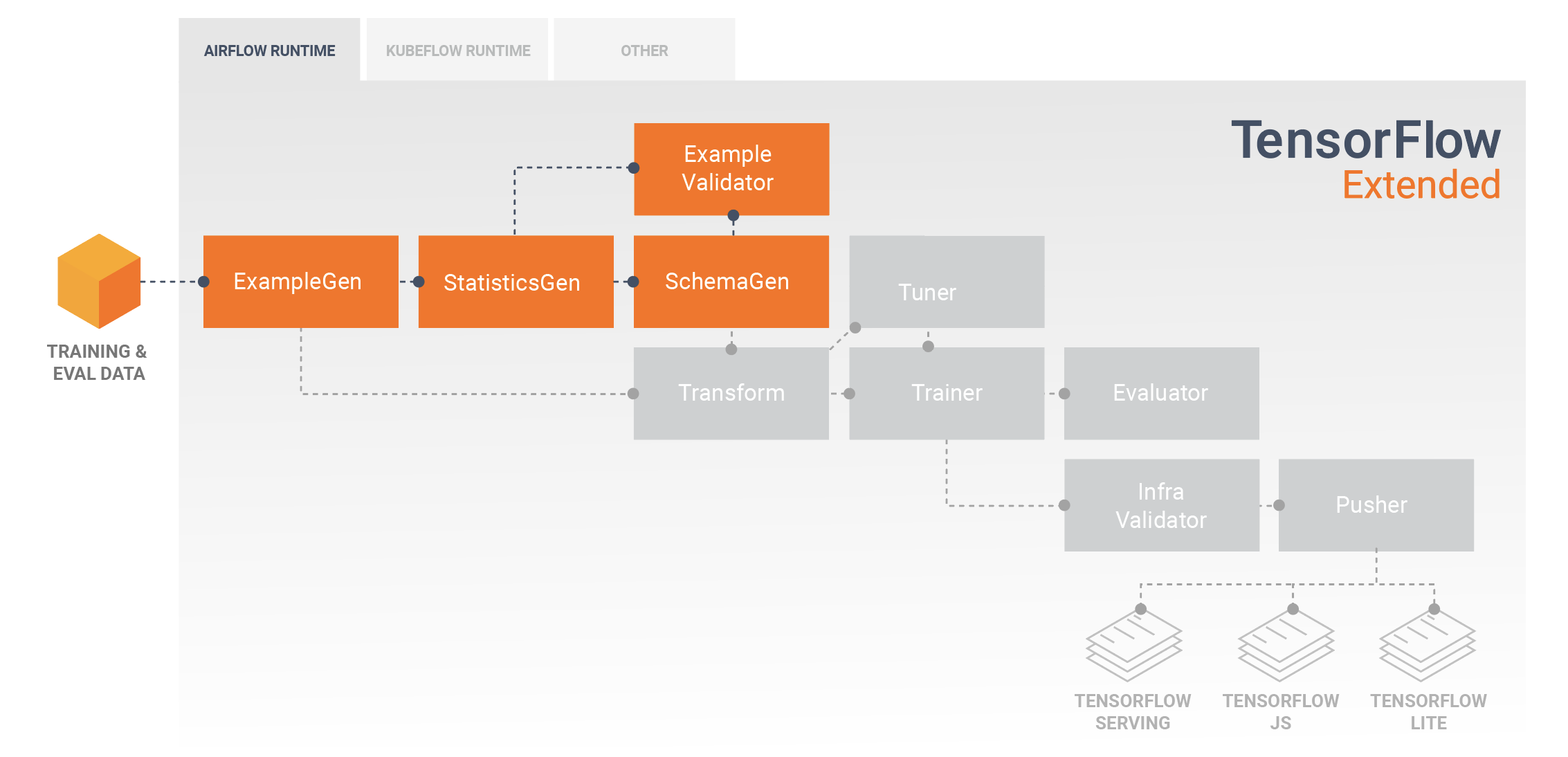
TFX 流水线通常从 ExampleGen 组件开始,该组件会接受输入数据并将其格式化为 tf.Example。这通常是在将数据拆分成训练数据集和评估数据集之后进行的,因此实际上有两份 ExampleGen 组件,分别用于训练和评估。 StatisticsGen 组件和 SchemaGen 组件通常紧跟其后,这两个组件会检查您的数据并推断出数据架构和统计信息。架构和统计信息将供 ExampleValidator 组件使用,该组件会查找数据中的异常情况、缺失的值和不正确的数据类型。所有这些组件均会利用 TensorFlow Data Validation 库的功能。
TensorFlow Data Validation (TFDV) 是一种初步探索、可视化和清理数据集的重要工具。TFDV 会检查您的数据并推断数据类型、类别和范围,然后自动帮助您识别异常情况和缺失的值。它还提供了可视化工具,可以帮助您检查和了解数据集。流水线完成后,您可以从 MLMD 中读取元数据,并在 Jupyter 笔记本中使用 TFDV 的可视化工具分析数据。
在初始模型训练和部署之后,TFDV 可用于监控从向已部署模型发送的推断请求获得的新数据,并查找异常和/或偏移情况。这对于因趋势或季节性因素而随时间变化的时间序列数据尤其有用,并且有助于判断数据是否有问题或是否需要针对新数据重新训练模型。
数据可视化
通过流水线中使用 TFDV 的部分(通常为 StatisticsGen、SchemaGen 和 ExampleValidator)完成首次数据运行之后,您可以在 Jupyter 笔记本中可视化结果。对于后续运行作业,您可以一边做出调整一边比较这些结果,直到模型和应用获得最佳数据为止。
您首先需要查询 ML Metadata (MLMD),找到这些组件的执行结果,然后使用 TFDV 中的可视化支持 API 在笔记本中创建可视化效果。其中包括 tfdv.load_statistics() 和 tfdv.visualize_statistics()。这种可视化效果可以让您更好地了解数据集的特性,并根据需要进行修改。
开发和训练模型
![]()
典型的 TFX 流水线包含一个 Transform 组件,该组件将利用 TensorFlow Transform (TFT) 库的功能执行特征工程。Transform 组件会使用由 SchemaGen 组件创建的架构,并应用数据转换来创建、合并和转换将用于训练模型的特征。如果为推断请求发送的数据中也有可能存在缺失的值和类型转换,还应该在 Transform 组件中清除这些内容。在 TFX 中设计 TensorFlow 训练代码时,需要考虑一些重要事项。
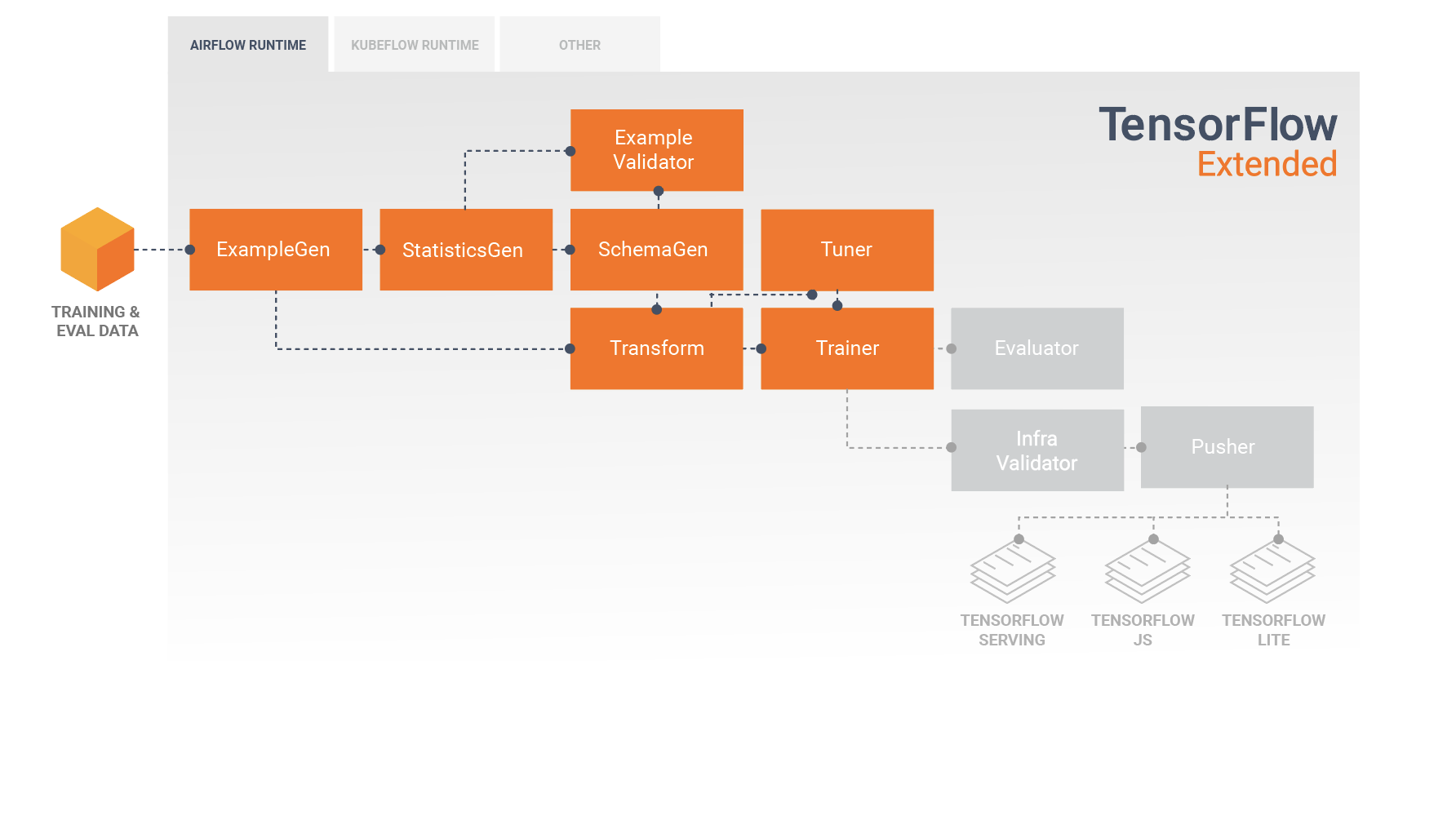
Transform 组件将生成 SavedModel,SavedModel 将在 Trainer 组件执行期间被导入,并用于 TensorFlow 中的建模代码。SavedModel 包含已在 Transform 组件中创建的所有数据工程转换,这样就可以在训练和推断过程中使用完全相同的代码执行相同的转换。借助建模代码(包括 Transform 组件中的 SavedModel),您可以使用训练和评估数据来训练模型。
在使用基于 Estimator 的模型时,建模代码的最后一部分应将模型同时另存为 SavedModel 和 EvalSavedModel。另存为 EvalSavedModel 可以确保在训练时使用的指标在评估时也可用(注意,对于基于 Keras 的模型来说,并非必须这样)。保存 EvalSavedModel 时,您必须在 Trainer 组件中导入 TensorFlow Model Analysis (TFMA) 库。
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
可在 Trainer 之前添加一个可选的 Tuner 组件,用于调整模型的超参数(例如层数)。对于特定的模型和超参数的搜索空间,调整算法可以根据目标找到最佳超参数。
分析和了解模型效果
在进行初始模型开发和训练之后,分析并真正了解模型的效果非常重要。典型的 TFX 流水线包含一个 Evaluator 组件,该组件会利用 TensorFlow Model Analysis (TFMA) 库所提供的强大工具包完成这一开发阶段。Evaluator 组件会使用您在上面导出的模型,并允许您指定可在可视化和分析模型效果时使用的 tfma.SlicingSpec 列表。每个 SlicingSpec 都会定义您要检查的训练数据切片,例如分类特征的特定类别或数字特征的特定范围。
例如,如果您想了解模型对于不同客户群体的效果,这么做就很重要;客户群体可以按年购买量、地理位置数据、年龄段或性别划分。这对于长尾数据集尤为重要,因为在这种数据集中,即使重要但规模较小的群组的表现不可接受,也可能会被主流群组的表现掩盖。例如,您的模型可能在普通员工中效果良好,但在主管人员中的效果却很差,那么您需要知道这一点。
模型分析和可视化
通过训练模型并针对训练结果运行 Evaluator 组件(该组件会利用 TFMA)完成首次数据运行之后,您可以在 Jupyter 笔记本中可视化结果。对于后续运行作业,您可以一边做出调整一边比较这些结果,直到模型和应用获得最佳结果为止。
您首先需要查询 ML Metadata (MLMD),找到这些组件的执行结果,然后使用 TFMA 中的可视化支持 API 在笔记本中创建可视化效果。其中包括 tfma.load_eval_results 和 tfma.view.render_slicing_metrics。这种可视化效果可以让您更好地了解模型的特性,并根据需要进行修改。
验证模型性能
在分析模型性能时,您可能需要对照基准(例如当前应用的模型)验证模型的效果。若要验证模型,请将要验证的模型和基准模型添加到 Evaluator 组件中。Evaluator 会计算要验证的模型和基准模型的各项指标(例如 ROC 曲线下面积、损失)以及一组对应的差异指标。然后应用阈值,并将达到门槛的模型推送到生产环境。
验证模型是否可以提供服务
在部署经过训练的模型之前,您可能需要验证模型是否在服务基础架构中确实可以提供服务。这对在生产环境中确保新发布的模型不会阻止系统提供预测尤为重要。InfraValidator 组件会在沙盒环境中对您的模型执行 Canary 部署,并可选择发送实际请求以检查模型是否正常运行。
部署目标
在开发并训练模型后,如果您对模型感到满意,可以将其部署到一个或多个部署目标,并在其中接收推断请求。TFX 支持部署到三类部署目标。以 SavedModel 格式导出的经训练模型可以部署到这些部署目标中的任意一个,也可以部署到所有这些部署目标。
推断:TensorFlow Serving
TensorFlow Serving (TFS) 是适用于机器学习模型的灵活、高效服务系统,专为生产环境而设计。它会使用 SavedModel,并通过 REST 或 gRPC 接口接受推断请求。它作为一组进程在一个或多个网络服务器上运行,并使用一个高级架构处理同步和分布式计算。如需详细了解如何开发和部署 TFS 解决方案,请参阅 TFS 文档。
在典型的流水线中,在 Trainer 组件中训练过的 SavedModel 将首先在 InfraValidator 组件中接受基础架构验证。InfraValidator 启动 Canary TFS 模型服务器,以便实际应用 SavedModel。如果通过验证,则 Pusher 组件最终会将 SavedModel 部署到您的 TFS 基础架构。这包括处理多个版本和模型更新。
在原生移动应用和 IoT 应用中推断:TensorFlow Lite
TensorFlow Lite 是一套工具,旨在帮助开发者在原生移动应用和 IoT 应用中使用经过训练的 TensorFlow 模型。它与 TensorFlow Serving 使用一样的 SavedModel,并应用量化和剪枝等优化措施来优化生成的模型的大小和效果,以应对在移动设备和 IoT 设备上运行时面临的难题。如需详细了解如何使用 TensorFlow Lite,请参阅 TensorFlow Lite 文档。
使用 JavaScript 推断:TensorFlow JS
TensorFlow JS 是一个 JavaScript 库,用于在浏览器和 Node.js 上训练和部署机器学习模型。它与 TensorFlow Serving 和 TensorFlow Lite 使用一样的 SavedModel,并将它们转换为 TensorFlow.js Web 格式。如需详细了解如何使用 TensorFlow JS,请参阅 TensorFlow JS 文档。
使用 Airflow 创建 TFX 流水线
如需了解详情,请查看 Airflow 研讨会
使用 Kubeflow 创建 TFX 流水线
设置
Kubeflow 需要使用 Kubernetes 聚类大规模运行流水线。请参阅 Kubeflow 部署指南,了解部署 Kubeflow 集群的选项。
配置并运行 TFX 流水线
请按照“Cloud AI Platform Pipeline 上的 TFX”教程中的说明在 Kubeflow 上运行 TFX 示例流水线。TFX 组件已经过容器化,可以编写 Kubeflow 流水线;此示例演示了配置流水线以读取大型公共数据集并在云端大规模执行训练和数据处理步骤的功能。
执行流水线操作的命令行界面
TFX 提供统一 CLI,可帮助您在 Apache Airflow、Apache Beam 和 Kubeflow 等各种 Orchestrator 上执行众多流水线操作,例如创建、更新、运行、列出和删除流水线。如需了解详情,请参阅这些说明。