
Introduction
TFX est une plate-forme d'apprentissage automatique (ML) à l'échelle de la production de Google basée sur TensorFlow. Il fournit un cadre de configuration et des bibliothèques partagées pour intégrer les composants communs nécessaires à la définition, au lancement et à la surveillance de votre système d'apprentissage automatique.
TFX1.0
Nous sommes heureux d'annoncer la disponibilité du TFX 1.0.0 . Il s'agit de la première version post-bêta de TFX, qui fournit des API et des artefacts publics stables. Vous pouvez être assuré que vos futurs pipelines TFX continueront de fonctionner après une mise à niveau dans le cadre de compatibilité défini dans cette RFC .
Installation

![]()
pip install tfx
Forfaits de nuit
TFX héberge également des packages nocturnes sur https://pypi-nightly.tensorflow.org sur Google Cloud. Pour installer le dernier package nocturne, veuillez utiliser la commande suivante :
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
Cela installera les packages nocturnes pour les principales dépendances de TFX telles que TensorFlow Model Analysis (TFMA), TensorFlow Data Validation (TFDV), TensorFlow Transform (TFT), TFX Basic Shared Libraries (TFX-BSL), ML Metadata (MLMD).
À propos de TFX
TFX est une plateforme permettant de créer et de gérer des workflows ML dans un environnement de production. TFX fournit les éléments suivants :
Une boîte à outils pour créer des pipelines ML. Les pipelines TFX vous permettent d'orchestrer votre flux de travail ML sur plusieurs plates-formes, telles que : Apache Airflow, Apache Beam et Kubeflow Pipelines.
Un ensemble de composants standard que vous pouvez utiliser dans le cadre d'un pipeline ou dans le cadre de votre script de formation ML. Les composants standard TFX offrent des fonctionnalités éprouvées pour vous aider à démarrer facilement la création d'un processus ML.
Bibliothèques qui fournissent les fonctionnalités de base pour de nombreux composants standard. Vous pouvez utiliser les bibliothèques TFX pour ajouter cette fonctionnalité à vos propres composants personnalisés ou les utiliser séparément.
TFX est une boîte à outils d'apprentissage automatique à l'échelle de la production Google basée sur TensorFlow. Il fournit un cadre de configuration et des bibliothèques partagées pour intégrer les composants communs nécessaires à la définition, au lancement et à la surveillance de votre système d'apprentissage automatique.
Composants standards TFX
Un pipeline TFX est une séquence de composants qui implémentent un pipeline ML spécialement conçu pour les tâches d'apprentissage automatique évolutives et hautes performances. Cela inclut la modélisation, la formation, la diffusion d'inférences et la gestion des déploiements vers des cibles en ligne, mobiles natives et JavaScript.
Un pipeline TFX comprend généralement les composants suivants :
ExempleGen est le composant d'entrée initial d'un pipeline qui ingère et divise éventuellement l'ensemble de données d'entrée.
StatisticsGen calcule les statistiques pour l'ensemble de données.
SchemaGen examine les statistiques et crée un schéma de données.
SampleValidator recherche les anomalies et les valeurs manquantes dans l'ensemble de données.
Transform effectue l'ingénierie des fonctionnalités sur l'ensemble de données.
Le formateur forme le modèle.
Tuner ajuste les hyperparamètres du modèle.
Evaluator effectue une analyse approfondie des résultats de la formation et vous aide à valider vos modèles exportés, en garantissant qu'ils sont « suffisamment bons » pour être mis en production.
InfraValidator vérifie que le modèle est réellement utilisable à partir de l'infrastructure et empêche la diffusion d'un mauvais modèle.
Pusher déploie le modèle sur une infrastructure de service.
BulkInferrer effectue un traitement par lots sur un modèle avec des demandes d'inférence non étiquetées.
Ce diagramme illustre le flux de données entre ces composants :
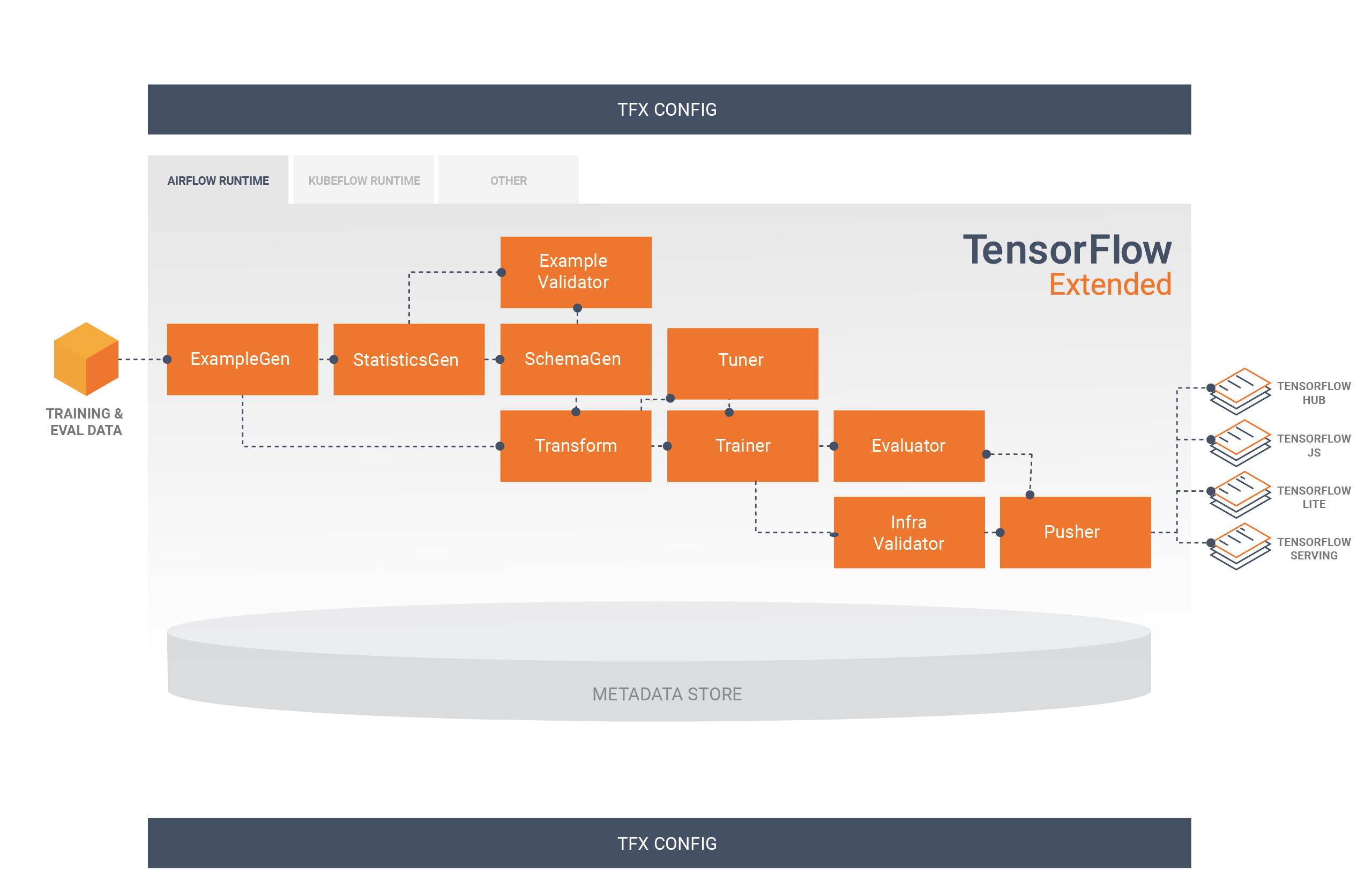
Bibliothèques TFX
TFX comprend à la fois des bibliothèques et des composants de pipeline. Ce diagramme illustre les relations entre les bibliothèques TFX et les composants du pipeline :
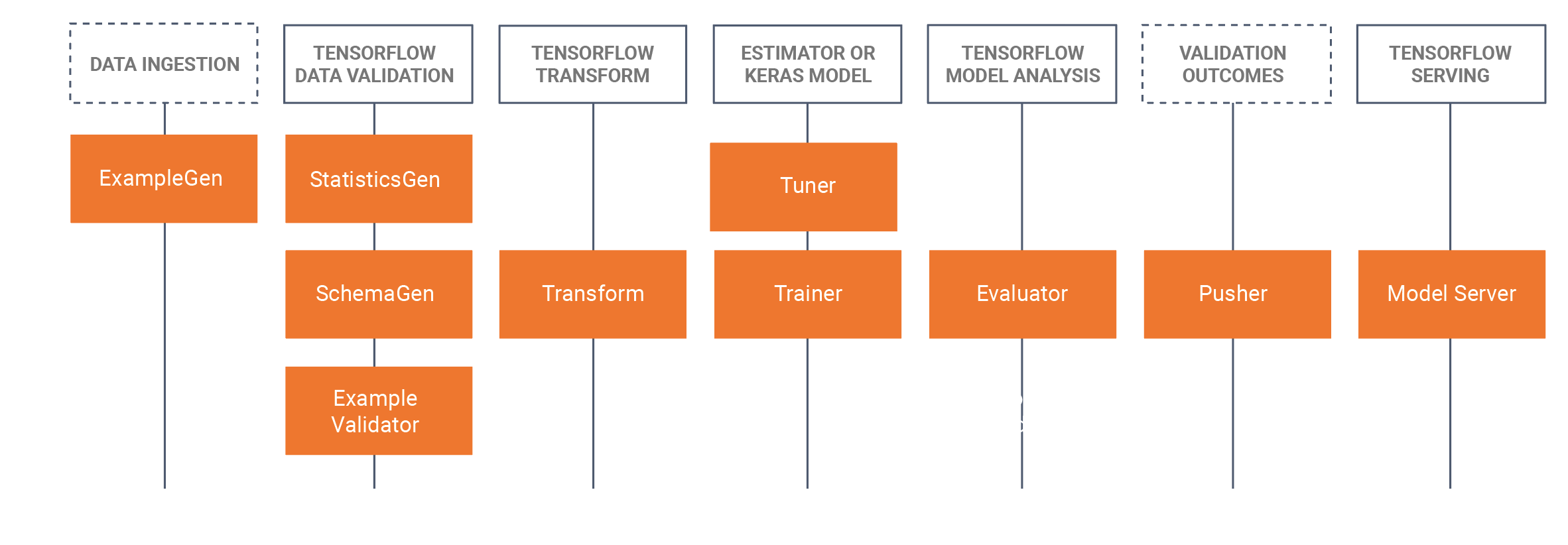
TFX fournit plusieurs packages Python qui sont les bibliothèques utilisées pour créer des composants de pipeline. Vous utiliserez ces bibliothèques pour créer les composants de vos pipelines afin que votre code puisse se concentrer sur les aspects uniques de votre pipeline.
Les bibliothèques TFX incluent :
TensorFlow Data Validation (TFDV) est une bibliothèque permettant d'analyser et de valider les données d'apprentissage automatique. Il est conçu pour être hautement évolutif et pour bien fonctionner avec TensorFlow et TFX. TFDV comprend :
- Calcul évolutif de statistiques récapitulatives des données de formation et de test.
- Intégration avec une visionneuse pour les distributions de données et les statistiques, ainsi que comparaison à facettes de paires d'ensembles de données (Facets).
- Génération automatisée de schémas de données pour décrire les attentes concernant les données telles que les valeurs requises, les plages et les vocabulaires.
- Un visualiseur de schéma pour vous aider à inspecter le schéma.
- Détection d'anomalies pour identifier les anomalies, telles que des fonctionnalités manquantes, des valeurs hors plage ou des types de fonctionnalités incorrects, pour n'en nommer que quelques-unes.
- Un visualiseur d'anomalies pour que vous puissiez voir quelles fonctionnalités présentent des anomalies et en savoir plus afin de les corriger.
TensorFlow Transform (TFT) est une bibliothèque de prétraitement des données avec TensorFlow. TensorFlow Transform est utile pour les données qui nécessitent un passage complet, telles que :
- Normalisez une valeur d’entrée par moyenne et écart type.
- Convertissez des chaînes en entiers en générant un vocabulaire sur toutes les valeurs d'entrée.
- Convertissez les flottants en entiers en les attribuant à des compartiments en fonction de la distribution des données observée.
TensorFlow est utilisé pour entraîner des modèles avec TFX. Il ingère les données de formation et le code de modélisation et crée un résultat SavedModel. Il intègre également un pipeline d'ingénierie de fonctionnalités créé par TensorFlow Transform pour le prétraitement des données d'entrée.
KerasTuner est utilisé pour régler les hyperparamètres du modèle.
TensorFlow Model Analysis (TFMA) est une bibliothèque permettant d'évaluer les modèles TensorFlow. Il est utilisé avec TensorFlow pour créer un EvalSavedModel, qui devient la base de son analyse. Il permet aux utilisateurs d'évaluer leurs modèles sur de grandes quantités de données de manière distribuée, en utilisant les mêmes métriques définies dans leur entraîneur. Ces métriques peuvent être calculées sur différentes tranches de données et visualisées dans les notebooks Jupyter.
TensorFlow Metadata (TFMD) fournit des représentations standard pour les métadonnées qui sont utiles lors de la formation de modèles de machine learning avec TensorFlow. Les métadonnées peuvent être produites manuellement ou automatiquement lors de l'analyse des données d'entrée, et peuvent être consommées pour la validation, l'exploration et la transformation des données. Les formats de sérialisation des métadonnées incluent :
- Un schéma décrivant des données tabulaires (par exemple, tf.Examples).
- Une collection de statistiques récapitulatives sur ces ensembles de données.
ML Metadata (MLMD) est une bibliothèque permettant d'enregistrer et de récupérer des métadonnées associées aux flux de travail des développeurs ML et des data scientists. Le plus souvent, les métadonnées utilisent des représentations TFMD. MLMD gère la persistance à l'aide de SQL-Lite , MySQL et d'autres magasins de données similaires.
Technologies de support
Requis
- Apache Beam est un modèle unifié open source permettant de définir des pipelines de traitement parallèle de données par lots et par flux. TFX utilise Apache Beam pour implémenter des pipelines de données parallèles. Le pipeline est ensuite exécuté par l'un des back-ends de traitement distribué pris en charge par Beam, qui incluent Apache Flink, Apache Spark, Google Cloud Dataflow et d'autres.
Facultatif
Les orchestrateurs tels qu'Apache Airflow et Kubeflow facilitent la configuration, l'exploitation, la surveillance et la maintenance d'un pipeline ML.
Apache Airflow est une plate-forme permettant de créer, planifier et surveiller des flux de travail par programmation. TFX utilise Airflow pour créer des flux de travail sous forme de graphiques acycliques dirigés (DAG) de tâches. Le planificateur Airflow exécute des tâches sur un ensemble de nœuds de calcul tout en suivant les dépendances spécifiées. De riches utilitaires de ligne de commande facilitent la réalisation d'interventions chirurgicales complexes sur les DAG. L'interface utilisateur riche facilite la visualisation des pipelines exécutés en production, le suivi de la progression et le dépannage des problèmes en cas de besoin. Lorsque les flux de travail sont définis sous forme de code, ils deviennent plus maintenables, versionnables, testables et collaboratifs.
Kubeflow se consacre à rendre les déploiements de workflows d'apprentissage automatique (ML) sur Kubernetes simples, portables et évolutifs. L'objectif de Kubeflow n'est pas de recréer d'autres services, mais de fournir un moyen simple de déployer les meilleurs systèmes open source pour le ML sur diverses infrastructures. Les pipelines Kubeflow permettent la composition et l'exécution de flux de travail reproductibles sur Kubeflow, intégrés à des expériences basées sur des expérimentations et des notebooks. Les services Kubeflow Pipelines sur Kubernetes incluent le magasin de métadonnées hébergé, le moteur d'orchestration basé sur des conteneurs, le serveur de notebooks et l'interface utilisateur pour aider les utilisateurs à développer, exécuter et gérer des pipelines ML complexes à grande échelle. Le SDK Kubeflow Pipelines permet la création et le partage de composants et la composition de pipelines par programmation.
Portabilité et interopérabilité
TFX est conçu pour être portable sur plusieurs environnements et frameworks d'orchestration, notamment Apache Airflow , Apache Beam et Kubeflow . Il est également portable sur différentes plates-formes informatiques, y compris sur site, et sur des plates-formes cloud telles que Google Cloud Platform (GCP) . En particulier, TFX interagit avec plusieurs services GCP gérés, tels que Cloud AI Platform for Training and Prediction et Cloud Dataflow pour le traitement distribué des données pour plusieurs autres aspects du cycle de vie du ML.
Modèle vs modèle enregistré
Modèle
Un modèle est le résultat du processus de formation. Il s'agit de l'enregistrement sérialisé des poids appris au cours du processus de formation. Ces poids peuvent ensuite être utilisés pour calculer des prédictions pour de nouveaux exemples d’entrée. Pour TFX et TensorFlow, « modèle » fait référence aux points de contrôle contenant les poids appris jusqu'à ce point.
Notez que « modèle » peut également faire référence à la définition du graphe de calcul TensorFlow (c'est-à-dire un fichier Python) qui exprime la manière dont une prédiction sera calculée. Les deux sens peuvent être utilisés de manière interchangeable en fonction du contexte.
Modèle enregistré
- Qu'est-ce qu'un SavedModel : une sérialisation universelle, neutre en termes de langage, hermétique et récupérable d'un modèle TensorFlow.
- Pourquoi est-ce important : cela permet aux systèmes de niveau supérieur de produire, transformer et consommer des modèles TensorFlow en utilisant une seule abstraction.
SavedModel est le format de sérialisation recommandé pour servir un modèle TensorFlow en production ou pour exporter un modèle entraîné pour une application mobile ou JavaScript native. Par exemple, pour transformer un modèle en service REST afin d'effectuer des prédictions, vous pouvez sérialiser le modèle en tant que SavedModel et le servir à l'aide de TensorFlow Serving. Voir Servir un modèle TensorFlow pour plus d'informations.
Schéma
Certains composants TFX utilisent une description de vos données d'entrée appelée schéma . Le schéma est une instance de schema.proto . Les schémas sont un type de tampon de protocole , plus généralement connu sous le nom de « protobuf ». Le schéma peut spécifier des types de données pour les valeurs de caractéristiques, si une caractéristique doit être présente dans tous les exemples, des plages de valeurs autorisées et d'autres propriétés. L'un des avantages de l'utilisation de TensorFlow Data Validation (TFDV) est qu'elle génère automatiquement un schéma en déduisant les types, les catégories et les plages à partir des données d'entraînement.
Voici un extrait d'un schéma protobuf :
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
Les composants suivants utilisent le schéma :
- Validation des données TensorFlow
- Transformation TensorFlow
Dans un pipeline TFX typique, TensorFlow Data Validation génère un schéma qui est consommé par les autres composants.
Développer avec TFX
TFX fournit une plate-forme puissante pour chaque phase d'un projet d'apprentissage automatique, depuis la recherche, l'expérimentation et le développement sur votre machine locale jusqu'au déploiement. Afin d'éviter la duplication de code et d'éliminer le potentiel de biais de formation/diffusion, il est fortement recommandé de mettre en œuvre votre pipeline TFX pour la formation de modèles et le déploiement de modèles formés, et d'utiliser des composants Transform qui exploitent la bibliothèque TensorFlow Transform pour la formation et l'inférence. Ce faisant, vous utiliserez le même code de prétraitement et d'analyse de manière cohérente, éviterez les différences entre les données utilisées pour la formation et les données fournies à vos modèles entraînés en production, tout en bénéficiant de l'écriture de ce code une seule fois.
Exploration, visualisation et nettoyage des données
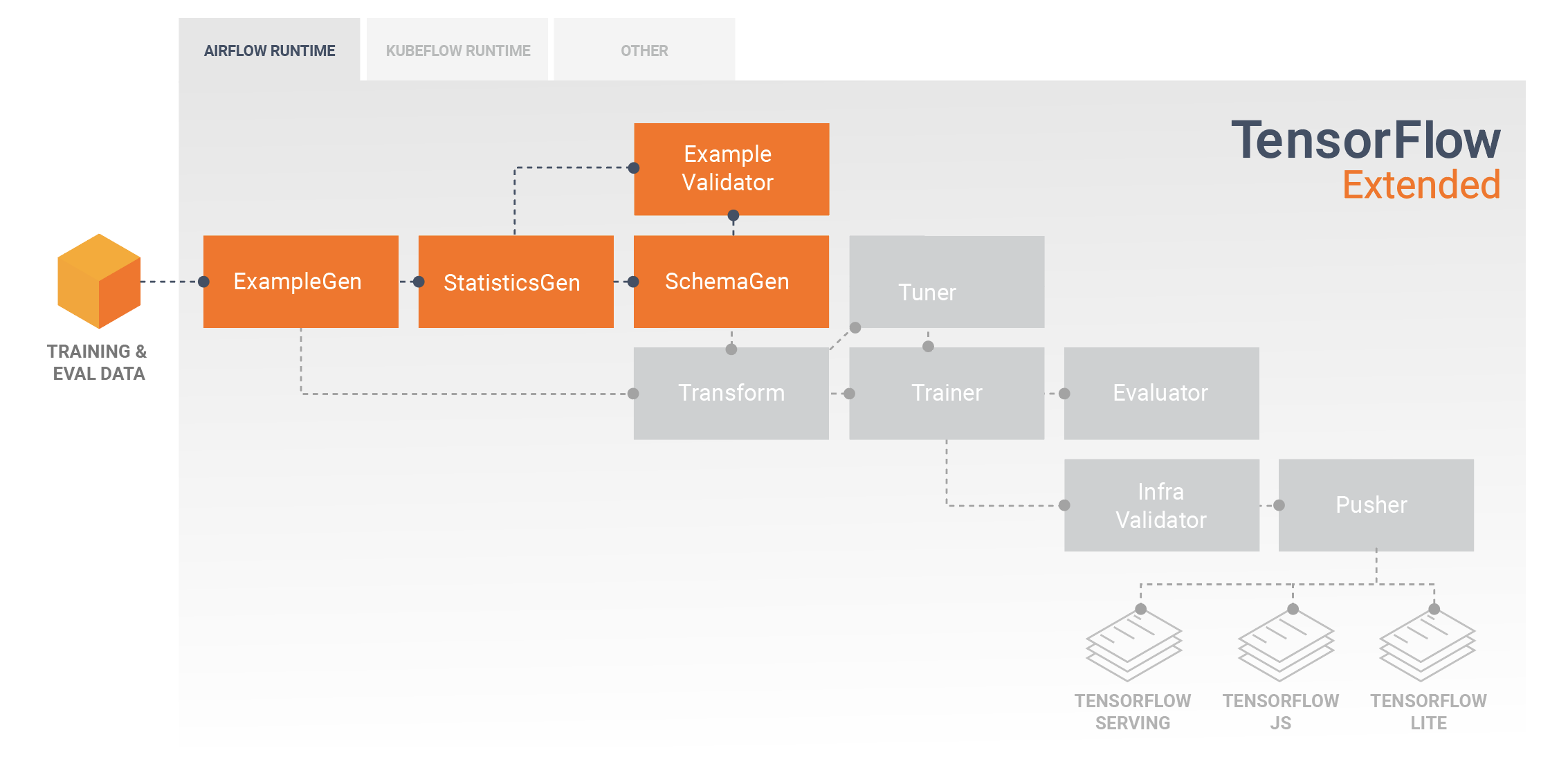
Les pipelines TFX commencent généralement par un composant SampleGen , qui accepte les données d'entrée et les formate en tant que tf.Examples. Cela est souvent effectué après que les données ont été divisées en ensembles de données de formation et d'évaluation, de sorte qu'il existe en réalité deux copies des composants SampleGen, une pour la formation et une pour l'évaluation. Ceci est généralement suivi d'un composant StatisticsGen et d'un composant SchemaGen , qui examineront vos données et en déduiront un schéma de données et des statistiques. Le schéma et les statistiques seront consommés par un composant SampleValidator , qui recherchera les anomalies, les valeurs manquantes et les types de données incorrects dans vos données. Tous ces composants exploitent les capacités de la bibliothèque TensorFlow Data Validation .
TensorFlow Data Validation (TFDV) est un outil précieux lors de l'exploration, de la visualisation et du nettoyage initial de votre ensemble de données. TFDV examine vos données et en déduit les types, catégories et plages de données, puis aide automatiquement à identifier les anomalies et les valeurs manquantes. Il fournit également des outils de visualisation qui peuvent vous aider à examiner et à comprendre votre ensemble de données. Une fois votre pipeline terminé, vous pouvez lire les métadonnées de MLMD et utiliser les outils de visualisation de TFDV dans un notebook Jupyter pour analyser vos données.
Après la formation et le déploiement initial de votre modèle, TFDV peut être utilisé pour surveiller les nouvelles données provenant des demandes d'inférence vers vos modèles déployés et rechercher des anomalies et/ou des dérives. Ceci est particulièrement utile pour les données de séries chronologiques qui changent au fil du temps en raison d'une tendance ou d'une saisonnalité, et peut aider à savoir quand il y a des problèmes de données ou quand les modèles doivent être recyclés sur de nouvelles données.
Visualisation des données
Après avoir terminé votre première exécution de vos données via la section de votre pipeline qui utilise TFDV (généralement StatisticsGen, SchemaGen et SampleValidator), vous pouvez visualiser les résultats dans un bloc-notes de style Jupyter. Pour des exécutions supplémentaires, vous pouvez comparer ces résultats au fur et à mesure que vous effectuez des ajustements, jusqu'à ce que vos données soient optimales pour votre modèle et votre application.
Vous allez d’abord interroger ML Metadata (MLMD) pour localiser les résultats de ces exécutions de ces composants, puis utiliser l’API de prise en charge de visualisation dans TFDV pour créer les visualisations dans votre bloc-notes. Cela inclut tfdv.load_statistics() et tfdv.visualize_statistics(). En utilisant cette visualisation, vous pouvez mieux comprendre les caractéristiques de votre ensemble de données et, si nécessaire, les modifier si nécessaire.
Développement et formation de modèles
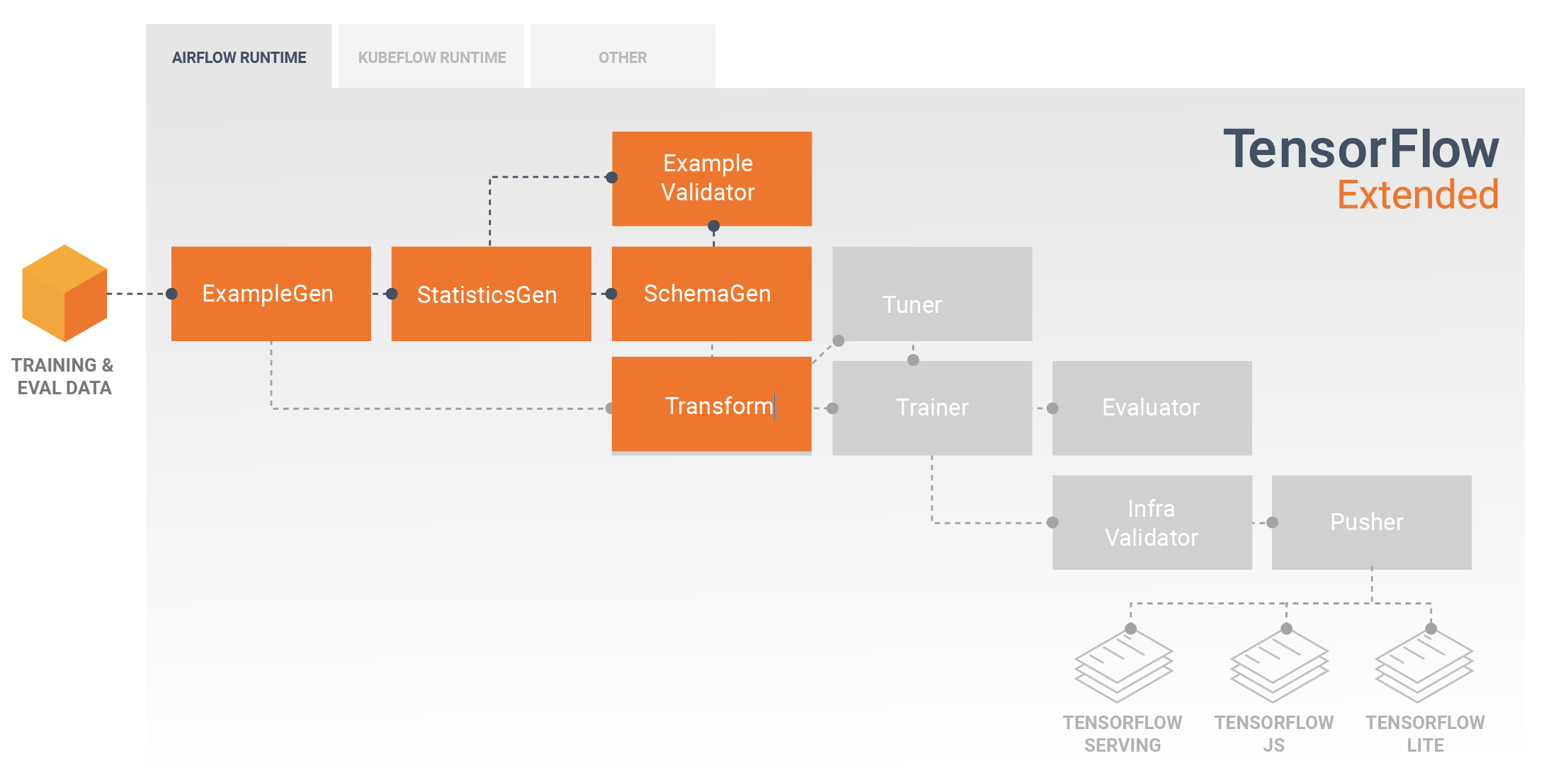
Un pipeline TFX typique comprendra un composant Transform , qui effectuera l'ingénierie des fonctionnalités en exploitant les capacités de la bibliothèque TensorFlow Transform (TFT) . Un composant Transform consomme le schéma créé par un composant SchemaGen et applique des transformations de données pour créer, combiner et transformer les fonctionnalités qui seront utilisées pour entraîner votre modèle. Le nettoyage des valeurs manquantes et la conversion des types doivent également être effectués dans le composant Transform s'il existe une possibilité que celles-ci soient également présentes dans les données envoyées pour les demandes d'inférence. Il y a quelques considérations importantes lors de la conception du code TensorFlow pour la formation dans TFX.
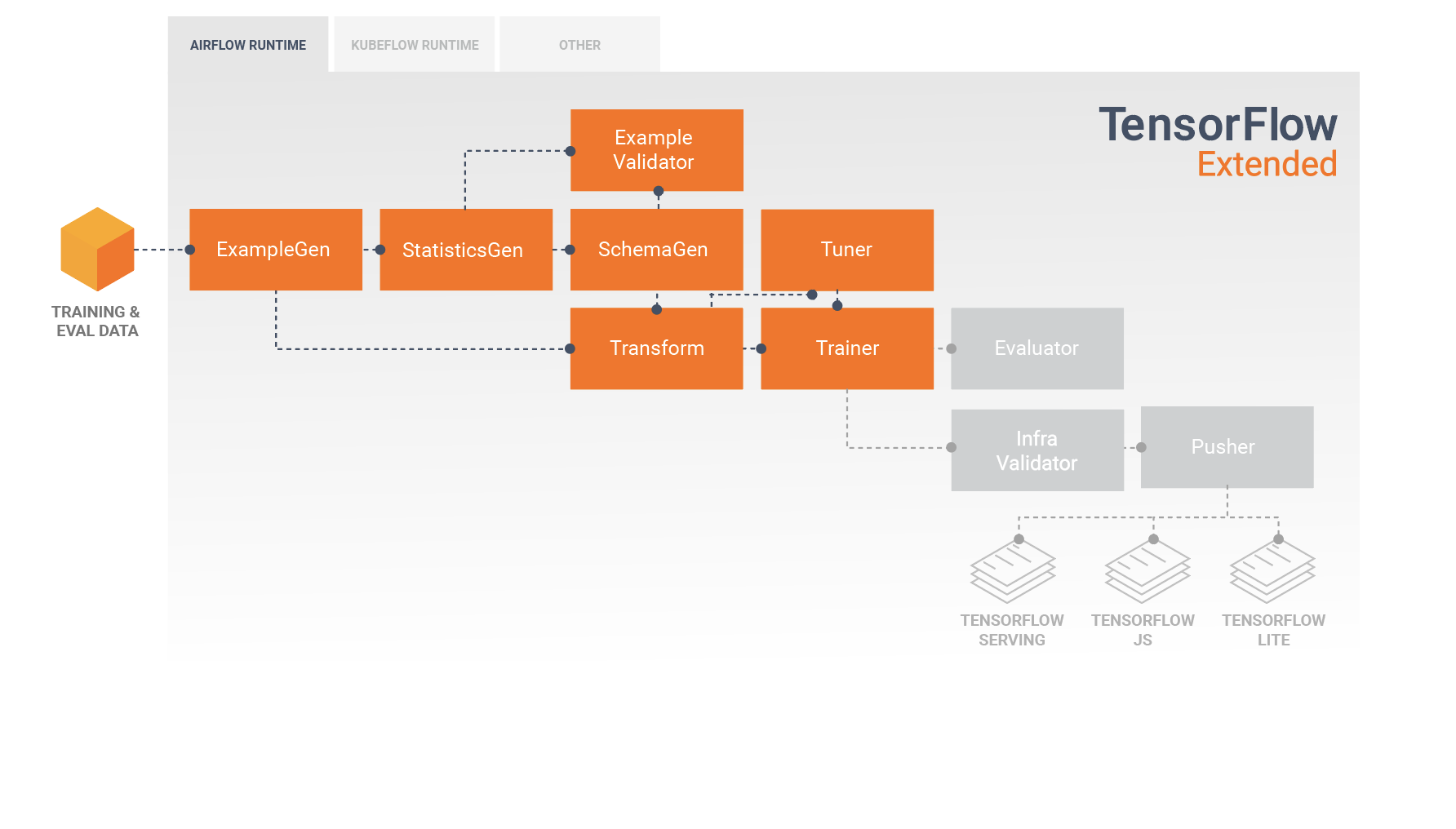
Le résultat d'un composant Transform est un SavedModel qui sera importé et utilisé dans votre code de modélisation dans TensorFlow, lors d'un composant Trainer . Ce SavedModel inclut toutes les transformations d'ingénierie de données qui ont été créées dans le composant Transform, de sorte que les transformations identiques soient effectuées en utilisant exactement le même code pendant la formation et l'inférence. À l’aide du code de modélisation, y compris le SavedModel du composant Transform, vous pouvez utiliser vos données de formation et d’évaluation et entraîner votre modèle.
Lorsque vous travaillez avec des modèles basés sur un estimateur, la dernière section de votre code de modélisation doit enregistrer votre modèle à la fois en tant que SavedModel et EvalSavedModel. L'enregistrement en tant que EvalSavedModel garantit que les métriques utilisées au moment de la formation sont également disponibles pendant l'évaluation (notez que cela n'est pas requis pour les modèles basés sur Keras). L'enregistrement d'un EvalSavedModel nécessite que vous importiez la bibliothèque TensorFlow Model Analysis (TFMA) dans votre composant Trainer.
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
Un composant Tuner facultatif peut être ajouté avant Trainer pour ajuster les hyperparamètres (par exemple, le nombre de couches) du modèle. Avec le modèle donné et l'espace de recherche des hyperparamètres, l'algorithme de réglage trouvera les meilleurs hyperparamètres en fonction de l'objectif.
Analyser et comprendre les performances du modèle
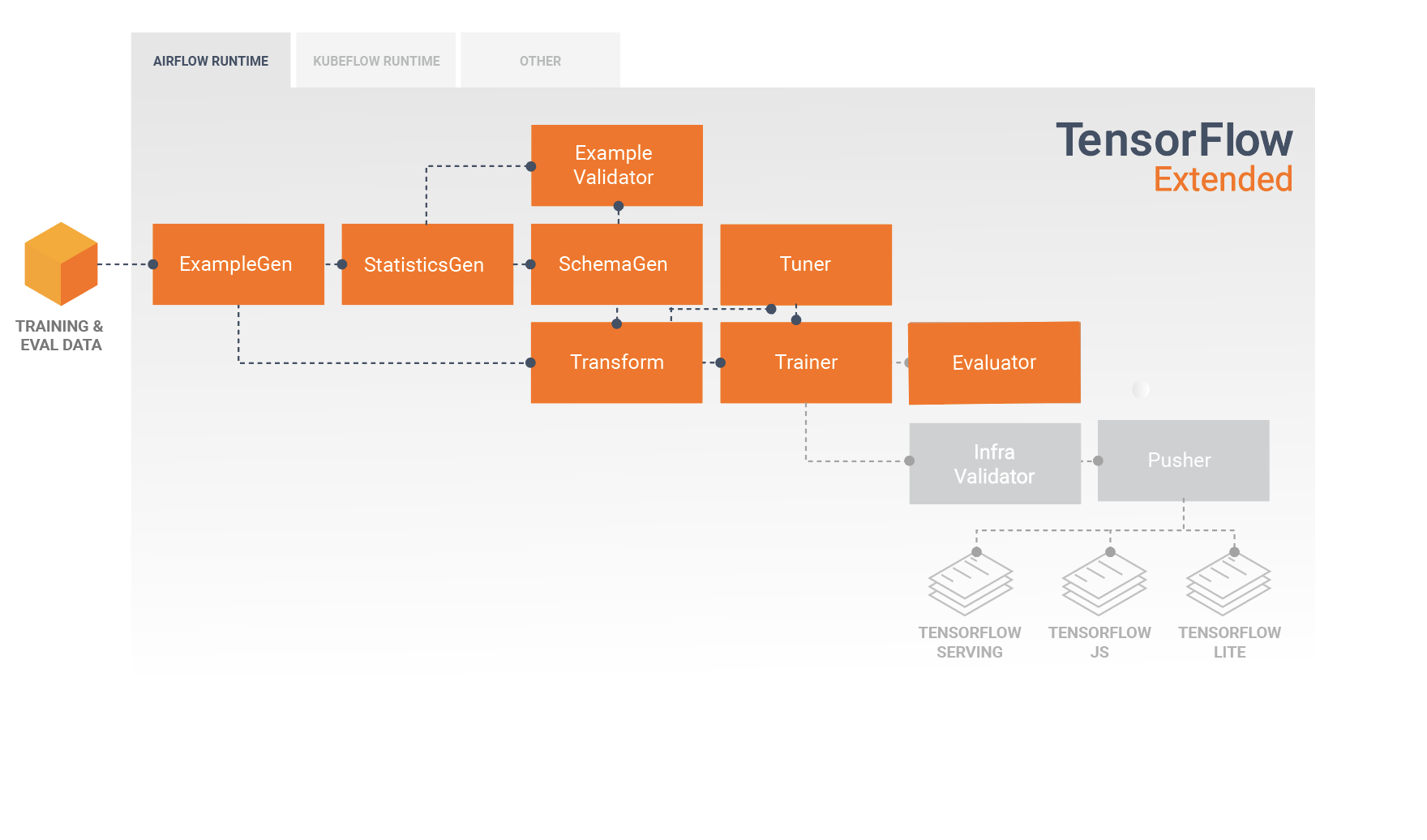
Après le développement et la formation initiale du modèle, il est important d'analyser et de vraiment comprendre les performances de votre modèle. Un pipeline TFX typique comprendra un composant Evaluator , qui exploite les capacités de la bibliothèque TensorFlow Model Analysis (TFMA) , qui fournit un ensemble d'outils puissants pour cette phase de développement. Un composant Evaluator consomme le modèle que vous avez exporté ci-dessus et vous permet de spécifier une liste de tfma.SlicingSpec que vous pouvez utiliser lors de la visualisation et de l'analyse des performances de votre modèle. Chaque SlicingSpec définit une tranche de vos données d'entraînement que vous souhaitez examiner, comme des catégories particulières pour les fonctionnalités catégorielles ou des plages particulières pour les fonctionnalités numériques.
Par exemple, cela serait important pour essayer de comprendre les performances de votre modèle pour différents segments de vos clients, qui pourraient être segmentés par achats annuels, données géographiques, tranche d'âge ou sexe. Cela peut être particulièrement important pour les ensembles de données à longue traîne, où les performances d’un groupe dominant peuvent masquer des performances inacceptables pour des groupes importants mais plus petits. Par exemple, votre modèle peut donner de bons résultats pour les employés moyens mais échouer lamentablement pour les cadres, et il peut être important pour vous de le savoir.
Analyse et visualisation du modèle
Après avoir terminé votre première exécution de vos données en entraînant votre modèle et en exécutant le composant Evaluator (qui exploite TFMA ) sur les résultats de la formation, vous pouvez visualiser les résultats dans un bloc-notes de style Jupyter. Pour des exécutions supplémentaires, vous pouvez comparer ces résultats au fur et à mesure que vous effectuez des ajustements, jusqu'à ce que vos résultats soient optimaux pour votre modèle et votre application.
Vous allez d’abord interroger ML Metadata (MLMD) pour localiser les résultats de ces exécutions de ces composants, puis utiliser l’API de prise en charge de visualisation dans TFMA pour créer les visualisations dans votre bloc-notes. Cela inclut tfma.load_eval_results et tfma.view.render_slicing_metrics. Grâce à cette visualisation, vous pouvez mieux comprendre les caractéristiques de votre modèle et, si nécessaire, le modifier si nécessaire.
Validation des performances du modèle
Dans le cadre de l'analyse des performances d'un modèle, vous souhaiterez peut-être valider les performances par rapport à une référence (telle que le modèle actuellement utilisé). La validation du modèle est effectuée en transmettant à la fois un modèle candidat et un modèle de référence au composant Évaluateur . L'évaluateur calcule des métriques (par exemple AUC, perte) pour le candidat et la ligne de base ainsi qu'un ensemble correspondant de métriques de différence. Des seuils peuvent ensuite être appliqués et utilisés pour pousser vos modèles en production.
Valider qu'un modèle peut être servi
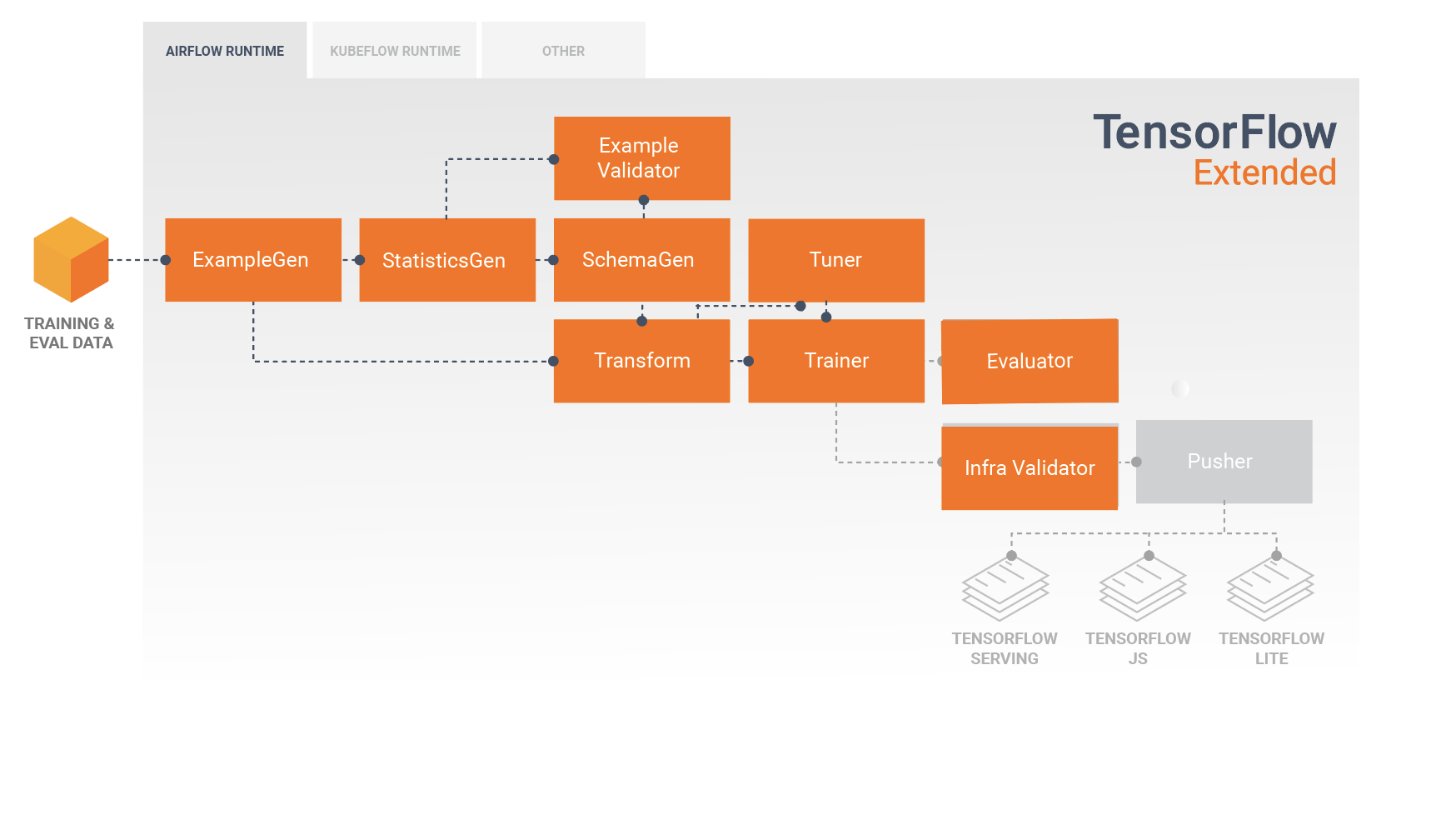
Avant de déployer le modèle entraîné, vous souhaiterez peut-être vérifier si le modèle est réellement utilisable dans l'infrastructure de diffusion. Ceci est particulièrement important dans les environnements de production pour garantir que le modèle nouvellement publié n'empêche pas le système de fournir des prédictions. Le composant InfraValidator effectuera un déploiement Canary de votre modèle dans un environnement sandbox, et enverra éventuellement de vraies requêtes pour vérifier que votre modèle fonctionne correctement.
Cibles de déploiement
Une fois que vous avez développé et formé un modèle qui vous convient, il est maintenant temps de le déployer sur une ou plusieurs cibles de déploiement où il recevra des demandes d'inférence. TFX prend en charge le déploiement sur trois classes de cibles de déploiement. Les modèles entraînés qui ont été exportés en tant que SavedModels peuvent être déployés sur l’une ou l’ensemble de ces cibles de déploiement.
Inférence : diffusion TensorFlow
TensorFlow Serving (TFS) est un système de service flexible et hautes performances pour les modèles d'apprentissage automatique, conçu pour les environnements de production. Il consomme un SavedModel et acceptera les demandes d'inférence sur les interfaces REST ou gRPC. Il s'exécute comme un ensemble de processus sur un ou plusieurs serveurs réseau, utilisant l'une des nombreuses architectures avancées pour gérer la synchronisation et le calcul distribué. Consultez la documentation TFS pour plus d'informations sur le développement et le déploiement de solutions TFS.
Dans un pipeline typique, un SavedModel qui a été formé dans un composant Trainer serait d'abord infra-validé dans un composant InfraValidator . InfraValidator lance un serveur de modèle Canary TFS pour servir réellement le SavedModel. Si la validation est réussie, un composant Pusher déploiera enfin le SavedModel sur votre infrastructure TFS. Cela inclut la gestion de plusieurs versions et mises à jour de modèles.
Inférence dans les applications mobiles et IoT natives : TensorFlow Lite
TensorFlow Lite est une suite d'outils dédiée à aider les développeurs à utiliser leurs modèles TensorFlow formés dans des applications mobiles et IoT natives. Il consomme les mêmes SavedModels que TensorFlow Serving et applique des optimisations telles que la quantification et l'élagage pour optimiser la taille et les performances des modèles résultants pour les défis de l'exécution sur les appareils mobiles et IoT. Consultez la documentation TensorFlow Lite pour plus d'informations sur l'utilisation de TensorFlow Lite.
Inférence en JavaScript : TensorFlow JS
TensorFlow JS est une bibliothèque JavaScript permettant de former et de déployer des modèles ML dans le navigateur et sur Node.js. Il consomme les mêmes SavedModels que TensorFlow Serving et TensorFlow Lite et les convertit au format Web TensorFlow.js. Consultez la documentation TensorFlow JS pour plus de détails sur l'utilisation de TensorFlow JS.
Création d'un pipeline TFX avec Airflow
Consultez l'atelier de circulation d'air pour plus de détails
Créer un pipeline TFX avec Kubeflow
Installation
Kubeflow nécessite un cluster Kubernetes pour exécuter les pipelines à grande échelle. Consultez les directives de déploiement Kubeflow qui guident les options de déploiement du cluster Kubeflow.
Configurer et exécuter le pipeline TFX
Veuillez suivre le didacticiel TFX sur Cloud AI Platform Pipeline pour exécuter l'exemple de pipeline TFX sur Kubeflow. Les composants TFX ont été conteneurisés pour composer le pipeline Kubeflow et l'exemple illustre la possibilité de configurer le pipeline pour lire un grand ensemble de données publiques et exécuter des étapes de formation et de traitement des données à grande échelle dans le cloud.
Interface de ligne de commande pour les actions de pipeline
TFX fournit une CLI unifiée qui permet d'effectuer une gamme complète d'actions de pipeline telles que la création, la mise à jour, l'exécution, la liste et la suppression de pipelines sur divers orchestrateurs, notamment Apache Airflow, Apache Beam et Kubeflow. Pour plus de détails, veuillez suivre ces instructions .