
Tổng quan
Đường ống Phân tích mô hình TensorFlow (TFMA) được mô tả như sau:
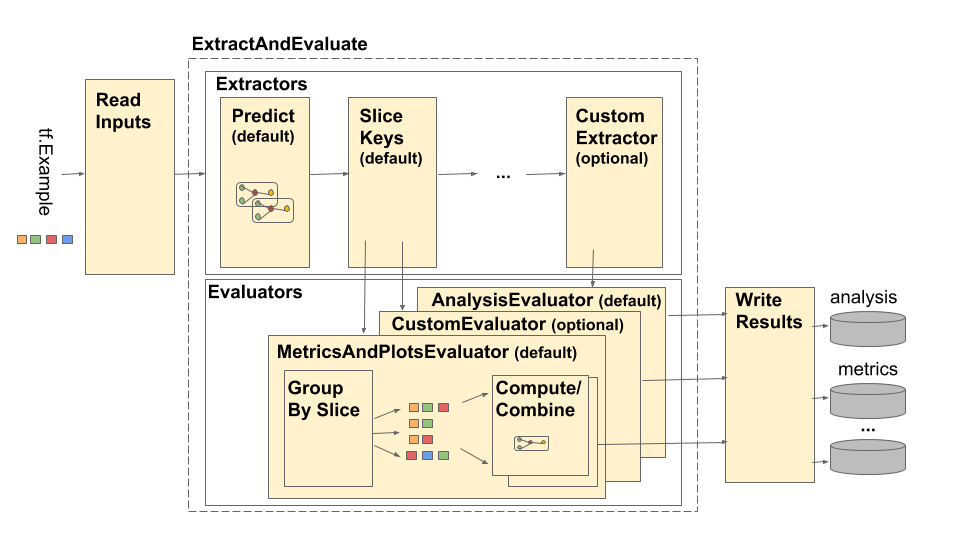
Đường ống được tạo thành từ bốn thành phần chính:
- Đọc đầu vào
- khai thác
- Sự đánh giá
- Viết kết quả
Các thành phần này sử dụng hai loại chính: tfma.Extracts và tfma.evaluators.Evaluation . Loại tfma.Extracts biểu thị dữ liệu được trích xuất trong quá trình xử lý đường ống và có thể tương ứng với một hoặc nhiều ví dụ cho mô hình. tfma.evaluators.Evaluation thể hiện đầu ra từ việc đánh giá các phần trích xuất tại các điểm khác nhau trong quá trình trích xuất. Để cung cấp API linh hoạt, các loại này chỉ là các lệnh trong đó các khóa được xác định (dành riêng để sử dụng) bằng các cách triển khai khác nhau. Các loại được định nghĩa như sau:
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
Lưu ý rằng tfma.Extracts không bao giờ được viết ra trực tiếp mà chúng phải luôn thông qua người đánh giá để tạo ra tfma.evaluators.Evaluation sau đó được viết ra. Cũng lưu ý rằng tfma.Extracts là các dict được lưu trữ trong beam.pvalue.PCollection (tức là beam.PTransform s lấy làm đầu vào beam.pvalue.PCollection[tfma.Extracts] ) trong khi tfma.evaluators.Evaluation là một dict có giá trị là beam.pvalue.PCollection s (tức là beam.PTransform s lấy chính dict làm đối số cho đầu vào beam.value.PCollection ). Nói cách khác, tfma.evaluators.Evaluation được sử dụng tại thời điểm xây dựng đường ống, nhưng tfma.Extracts được sử dụng trong thời gian chạy đường ống.
Đọc đầu vào
Giai đoạn ReadInputs được tạo thành từ một phép biến đổi lấy đầu vào thô (tf.train.Example, CSV, ...) và chuyển đổi chúng thành các bản trích xuất. Ngày nay, các trích xuất được biểu diễn dưới dạng byte đầu vào thô được lưu trữ trong tfma.INPUT_KEY , tuy nhiên, các trích xuất có thể ở bất kỳ dạng nào tương thích với quy trình trích xuất - nghĩa là nó tạo ra tfma.Extracts làm đầu ra và các trích xuất đó tương thích với hạ lưu máy chiết. Tùy thuộc vào các trình trích xuất khác nhau để ghi lại rõ ràng những gì họ yêu cầu.
khai thác
Quá trình trích xuất là một danh sách các beam.PTransform được chạy nối tiếp. Trình trích xuất lấy tfma.Extracts làm đầu vào và trả về tfma.Extracts làm đầu ra. Trình trích xuất điển hình ban đầu là tfma.extractors.PredictExtractor sử dụng trích xuất đầu vào được tạo ra bởi biến đổi đầu vào đọc và chạy nó thông qua một mô hình để tạo ra các trích xuất dự đoán. Trình trích xuất tùy chỉnh có thể được chèn vào bất kỳ điểm nào miễn là các biến đổi của chúng tuân thủ API tfma.Extracts in và tfma.Extracts out. Một máy trích xuất được định nghĩa như sau:
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
Trình trích xuất đầu vào
tfma.extractors.InputExtractor được sử dụng để trích xuất các tính năng thô, nhãn thô và trọng số mẫu thô từ các bản ghi tf.train.Example để sử dụng trong việc cắt và tính toán số liệu. Theo mặc định, các giá trị được lưu trữ dưới các khóa trích xuất features , labels và example_weights tương ứng. Nhãn mô hình một đầu ra và trọng số mẫu được lưu trữ trực tiếp dưới dạng giá trị np.ndarray . Nhãn mô hình nhiều đầu ra và trọng số mẫu được lưu trữ dưới dạng ký tự của các giá trị np.ndarray (được khóa theo tên đầu ra). Nếu việc đánh giá đa mô hình được thực hiện, các nhãn và trọng số mẫu sẽ được nhúng thêm vào một lệnh khác (được khóa theo tên mô hình).
Dự đoánExtractor
tfma.extractors.PredictExtractor chạy các dự đoán mô hình và lưu trữ chúng theo predictions chính trong lệnh tfma.Extracts . Các dự đoán của mô hình một đầu ra được lưu trữ trực tiếp dưới dạng các giá trị đầu ra được dự đoán. Dự đoán mô hình nhiều đầu ra được lưu trữ dưới dạng lệnh của các giá trị đầu ra (được khóa theo tên đầu ra). Nếu việc đánh giá đa mô hình được thực hiện thì dự đoán sẽ được nhúng sâu hơn vào một lệnh khác (được khóa theo tên mô hình). Giá trị đầu ra thực tế được sử dụng tùy thuộc vào mô hình (ví dụ: đầu ra trả về của công cụ ước tính TF ở dạng lệnh trong khi máy ảnh trả về giá trị np.ndarray ).
SliceKeyExtractor
tfma.extractors.SliceKeyExtractor sử dụng thông số cắt để xác định những lát cắt nào áp dụng cho từng đầu vào mẫu dựa trên các tính năng được trích xuất và thêm các giá trị cắt lõi tương ứng vào các phần trích xuất để người đánh giá sử dụng sau này.
Sự đánh giá
Đánh giá là quá trình lấy một trích đoạn và đánh giá nó. Mặc dù người ta thường thực hiện đánh giá ở cuối quy trình trích xuất, nhưng có những trường hợp sử dụng yêu cầu đánh giá sớm hơn trong quá trình trích xuất. Vì các bộ đánh giá như vậy được liên kết với các bộ trích xuất có đầu ra mà chúng cần được đánh giá dựa vào. Một người đánh giá được định nghĩa như sau:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
Lưu ý rằng bộ đánh giá là một beam.PTransform lấy tfma.Extracts làm đầu vào. Không có gì ngăn cản việc triển khai thực hiện các chuyển đổi bổ sung trên các phần trích xuất như một phần của quy trình đánh giá. Không giống như các trình trích xuất phải trả về một lệnh tfma.Extracts , không có hạn chế nào về loại kết quả đầu ra mà người đánh giá có thể tạo ra mặc dù hầu hết các người đánh giá cũng trả về một lệnh (ví dụ: tên và giá trị số liệu).
Công cụ đánh giá MetricsAndPlots
tfma.evaluators.MetricsAndPlotsEvaluator lấy features , labels và predictions làm đầu vào, chạy chúng thông qua tfma.slicer.FanoutSlices để nhóm chúng theo các lát, sau đó thực hiện các phép tính số liệu và biểu đồ. Nó tạo ra các kết quả đầu ra dưới dạng từ điển các số liệu, các khóa và giá trị biểu đồ (sau này chúng được chuyển đổi thành các giao thức được tuần tự hóa cho đầu ra bởi tfma.writers.MetricsAndPlotsWriter ).
Viết kết quả
Giai đoạn WriteResults là nơi kết quả đánh giá được ghi ra đĩa. WriteResults sử dụng người viết để ghi dữ liệu dựa trên các phím đầu ra. Ví dụ: tfma.evaluators.Evaluation có thể chứa các khóa cho metrics và plots . Sau đó, chúng sẽ được liên kết với các từ điển số liệu và biểu đồ được gọi là 'số liệu' và 'sơ đồ'. Người viết chỉ rõ cách ghi ra từng file:
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsNhà văn
Chúng tôi cung cấp tfma.writers.MetricsAndPlotsWriter để chuyển đổi các số liệu và biểu đồ từ điển thành các proto được tuần tự hóa và ghi chúng vào đĩa.
Nếu bạn muốn sử dụng một định dạng tuần tự hóa khác, bạn có thể tạo một trình soạn thảo tùy chỉnh và sử dụng định dạng đó thay thế. Vì tfma.evaluators.Evaluation được chuyển cho người viết chứa kết quả đầu ra cho tất cả người đánh giá được kết hợp, nên một biến đổi trợ giúp tfma.writers.Write được cung cấp để người viết có thể sử dụng trong quá trình triển khai ptransform của họ để chọn beam.PCollection thích hợp. PCollection dựa trên một phím đầu ra (xem ví dụ bên dưới).
Tùy chỉnh
Phương thức tfma.run_model_analysis lấy các đối số của extractors , evaluators và writers để tùy chỉnh trình trích xuất, trình đánh giá và trình ghi được sử dụng bởi đường dẫn. Nếu không có đối số nào được cung cấp thì tfma.default_extractors , tfma.default_evaluators và tfma.default_writers được sử dụng theo mặc định.
Trình trích xuất tùy chỉnh
Để tạo một trình trích xuất tùy chỉnh, hãy tạo loại tfma.extractors.Extractor bao bọc một beam.PTransform lấy tfma.Extracts làm đầu vào và trả về tfma.Extracts làm đầu ra. Ví dụ về trình trích xuất có sẵn trong tfma.extractors .
Người đánh giá tùy chỉnh
Để tạo một bộ đánh giá tùy chỉnh, hãy tạo loại tfma.evaluators.Evaluator bao bọc một beam.PTransform lấy tfma.Extracts làm đầu vào và trả về tfma.evaluators.Evaluation làm đầu ra. Một người đánh giá rất cơ bản có thể chỉ lấy tfma.Extracts đến và xuất chúng để lưu trữ trong bảng. Đây chính xác là những gì tfma.evaluators.AnalysisTableEvaluator thực hiện. Người đánh giá phức tạp hơn có thể thực hiện xử lý bổ sung và tổng hợp dữ liệu. Xem tfma.evaluators.MetricsAndPlotsEvaluator làm ví dụ.
Lưu ý rằng bản thân tfma.evaluators.MetricsAndPlotsEvaluator có thể được tùy chỉnh để hỗ trợ các số liệu tùy chỉnh (xem số liệu để biết thêm chi tiết).
Người viết tùy chỉnh
Để tạo trình ghi tùy chỉnh, hãy tạo loại tfma.writers.Writer bao bọc một beam.PTransform lấy tfma.evaluators.Evaluation làm đầu vào và trả về beam.pvalue.PDone làm đầu ra. Sau đây là ví dụ cơ bản về người viết để viết ra TFRecords chứa số liệu:
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
Đầu vào của người viết phụ thuộc vào đầu ra của người đánh giá liên quan. Đối với ví dụ trên, đầu ra là một proto được tuần tự hóa được tạo bởi tfma.evaluators.MetricsAndPlotsEvaluator . Người viết tfma.evaluators.AnalysisTableEvaluator sẽ chịu trách nhiệm viết ra beam.pvalue.PCollection của tfma.Extracts .
Lưu ý rằng trình ghi được liên kết với đầu ra của bộ đánh giá thông qua khóa đầu ra được sử dụng (ví dụ: tfma.METRICS_KEY , tfma.ANALYSIS_KEY , v.v.).
Ví dụ từng bước
Sau đây là ví dụ về các bước liên quan đến quy trình trích xuất và đánh giá khi sử dụng cả tfma.evaluators.MetricsAndPlotsEvaluator và tfma.evaluators.AnalysisTableEvaluator :
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(run_after:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(run_after:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files