
حق چاپ 2021 نویسندگان TF-Agents.
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
معرفی
این مثال نشان می دهد که چگونه برای آموزش بازیگر نقش اول مرد منتقد نرم عامل در Minitaur محیط زیست است.
اگر شما را از طریق کار کرده ام DQN COLAB این باید بسیار آشنا احساس می کنم. تغییرات قابل توجه عبارتند از:
- تغییر عامل از DQN به SAC.
- آموزش مینیاتور که محیطی بسیار پیچیده تر از CartPole است. هدف محیط Minitaur آموزش یک ربات چهارپا برای حرکت به جلو است.
- استفاده از TF-Agents Actor-Learner API برای یادگیری تقویتی توزیع شده.
API از جمع آوری داده های توزیع شده با استفاده از بافر بازپخش تجربه و محفظه متغیر (سرور پارامتر) و آموزش توزیع شده در چندین دستگاه پشتیبانی می کند. API بسیار ساده و ماژولار طراحی شده است. ما استفاده از Reverb استفاده برای هر دو بافر پخش و ظرف متغیر و API TF DistributionStrategy برای آموزش توزیع شده در GPU ها و TPU ها.
اگر وابستگی های زیر را نصب نکرده اید، اجرا کنید:
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
برپایی
ابتدا ابزارهای مختلفی را که نیاز داریم وارد می کنیم.
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
فراپارامترها
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
محیط
محیطها در RL نشاندهنده وظیفه یا مشکلی است که ما سعی در حل آن داریم. محیط های استاندارد را می توان به راحتی در TF-نمایندگی با استفاده از ایجاد suites . ما مختلف suites برای بارگذاری محیط از منابع مانند OpenAI بدنسازی، آتاری، DM کنترل، و غیره، با توجه به نام محیط زیست رشته.
حال بیایید محیط Minituar را از مجموعه Pybullet بارگذاری کنیم.
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

در این محیط، هدف این است که مامور سیاستی را آموزش دهد که ربات Minitaur را کنترل کند و آن را با بیشترین سرعت ممکن به جلو برساند. اپیزودها 1000 مرحله طول می کشند و بازگشت مجموع پاداش ها در طول قسمت خواهد بود.
نگاه اجازه دهید در اطلاعات محیط زیست به عنوان یک فراهم می کند observation که سیاست استفاده خواهد کرد برای تولید actions .
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
مشاهده نسبتاً پیچیده است. ما 28 مقدار دریافت می کنیم که زاویه، سرعت و گشتاور را برای همه موتورها نشان می دهد. در عوض محیط زیست انتظار 8 ارزش برای اقدامات بین [-1, 1] . اینها زوایای موتور مورد نظر هستند.
معمولا ما دو محیط ایجاد می کنیم: یکی برای جمع آوری داده ها در طول آموزش و دیگری برای ارزیابی. محیطها با پایتون خالص نوشته شدهاند و از آرایههای numpy استفاده میکنند، که Actor Learner API مستقیماً آنها را مصرف میکند.
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
استراتژی توزیع
ما از DistributionStrategy API برای فعال کردن اجرای محاسبات گام قطار در چندین دستگاه مانند چندین GPU یا TPU با استفاده از موازی سازی داده ها استفاده می کنیم. پله قطار:
- دسته ای از داده های آموزشی را دریافت می کند
- آن را در بین دستگاه ها تقسیم می کند
- گام رو به جلو را محاسبه می کند
- میانگین ضرر را جمع آوری و محاسبه می کند
- گام به عقب را محاسبه می کند و یک به روز رسانی متغیر گرادیان را انجام می دهد
با TF-Agents Learner API و DistributionStrategy API بسیار آسان است که بین اجرای مرحله قطار روی GPU (با استفاده از MirroredStrategy) به TPU (با استفاده از TPUStrategy) بدون تغییر هیچ یک از منطق آموزشی زیر سوئیچ کنید.
فعال کردن GPU
اگر میخواهید روی یک GPU اجرا کنید، ابتدا باید GPU را برای نوت بوک فعال کنید:
- به قسمت ویرایش → تنظیمات نوت بوک بروید
- GPU را از منوی کشویی Hardware Accelerator انتخاب کنید
انتخاب یک استراتژی
استفاده از strategy_utils برای تولید یک استراتژی. زیر کاپوت، عبور پارامتر:
-
use_gpu = Falseبازدهtf.distribute.get_strategy()، که با استفاده از پردازنده -
use_gpu = Trueبازدهtf.distribute.MirroredStrategy()، که با استفاده از تمام پردازنده های گرافیکی که قابل مشاهده هستند به TensorFlow در یک دستگاه
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
همه متغیرها و عوامل نیاز به زیر ایجاد شود strategy.scope() ، شما به عنوان زیر خواهید دید.
عامل
برای ایجاد SAC Agent، ابتدا باید شبکه هایی را ایجاد کنیم که آن را آموزش خواهد داد. SAC یک عامل منتقد بازیگر است، بنابراین ما به دو شبکه نیاز خواهیم داشت.
منتقد ما را برآورد ارزش برای دادن Q(s,a) . یعنی یک مشاهده و یک اقدام را به عنوان ورودی دریافت میکند و به ما تخمینی میدهد که آن عمل چقدر برای حالت داده شده خوب بوده است.
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
ما این منتقد برای آموزش استفاده می actor شبکه است که به ما اجازه خواهد تولید اقدامات با توجه به مشاهدات.
ActorNetwork خواهد پارامترها برای یک tanh له پیش بینی MultivariateNormalDiag توزیع. سپس این توزیع، مشروط به مشاهدات فعلی، هر زمان که نیاز به ایجاد اقدامات داشته باشیم، نمونه برداری می شود.
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
با در دست داشتن این شبکهها، اکنون میتوانیم عامل را نمونهسازی کنیم.
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
پخش مجدد بافر
به منظور پیگیری از داده های جمع آوری شده از محیط زیست، ما استفاده ی Reverb ، یک سیستم پخش کارآمد، توسعه، و آسان برای استفاده توسط Deepmind. دادههای تجربی جمعآوریشده توسط بازیگران و مصرفشده توسط یادگیرنده در طول آموزش را ذخیره میکند.
در این آموزش، این است از اهمیت کمتری max_size - اما در یک محیط توزیع شده با مجموعه ای async و آموزش، شما احتمالا می خواهید به آزمایش با rate_limiters.SampleToInsertRatio ، با استفاده از یک جایی samples_per_insert بین 2 و 1000. به عنوان مثال:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
بافر پخش با استفاده از مشخصات توصیف تانسورها که به ذخیره می شود، که می تواند از عامل با استفاده از به دست آمده ساخته شده است tf_agent.collect_data_spec .
از آنجا که عامل SAC نیاز هر دو در حال حاضر و مشاهدات بعدی برای محاسبه از دست دادن، ما مجموعه sequence_length=2 .
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
اکنون یک مجموعه داده TensorFlow از بافر Reverb Replay ایجاد می کنیم. ما این را به یادگیرنده منتقل می کنیم تا تجربیات خود را برای آموزش نمونه برداری کند.
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
سیاست های
در TF-عوامل، سیاست های نشان دهنده مفهوم استاندارد از سیاست در RL: با توجه به time_step تولید یک عمل یا یک توزیع بیش از اقدامات. روش اصلی است policy_step = policy.step(time_step) که در آن policy_step یک تاپل به نام PolicyStep(action, state, info) . policy_step.action است action به به محیط زیست استفاده شود، state نشان دهنده دولت برای stateful به (RNN) سیاست ها و info ممکن است مانند احتمال ورود به سیستم از اقدامات حاوی اطلاعات کمکی.
نمایندگان شامل دو خط مشی هستند:
-
agent.policy- سیاست اصلی است که برای ارزیابی و به کارگیری استفاده می شود. -
agent.collect_policy- یک سیاست دوم است که برای جمع آوری داده ها استفاده می شود.
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
سیاست ها را می توان مستقل از عوامل ایجاد کرد. به عنوان مثال، استفاده از tf_agents.policies.random_py_policy برای ایجاد یک سیاست که به طور تصادفی یک عمل برای هر time_step را انتخاب کنید.
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
بازیگران
کنشگر تعاملات بین یک سیاست و یک محیط را مدیریت می کند.
- اجزای بازیگر نقش اول مرد حاوی یک نمونه از محیط زیست (به عنوان
py_environment) و یک کپی از متغیر سیاست. - هر کارگر Actor با توجه به مقادیر محلی متغیرهای خط مشی، دنباله ای از مراحل جمع آوری داده ها را اجرا می کند.
- به روز رسانی متغیر به صراحت با استفاده از متغیر نمونه مشتری ظرف در اسکریپت آموزش قبل از تماس انجام
actor.run(). - تجربه مشاهده شده در هر مرحله جمع آوری داده در بافر پخش مجدد نوشته می شود.
همانطور که Actors مراحل جمع آوری داده ها را انجام می دهند، مسیرهای (وضعیت، اقدام، پاداش) را به ناظر منتقل می کنند، که آنها را در حافظه پنهان ذخیره می کند و در سیستم پخش مجدد Reverb می نویسد.
ما در حال ذخیره سازی مدار برای فریم [(T0، T1) (T1، T2) (T2، T3)، ...] به دلیل stride_length=1 .
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
ما یک Actor با خطمشی تصادفی ایجاد میکنیم و تجربیاتی را جمعآوری میکنیم تا بافر پخش مجدد را بکار ببریم.
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
برای جمع آوری تجربیات بیشتر در طول آموزش، یک بازیگر را با خط مشی جمع آوری نمونه کنید.
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
یک بازیگر ایجاد کنید که برای ارزیابی خط مشی در طول آموزش استفاده می شود. ما در عبور actor.eval_metrics(num_eval_episodes) برای ورود معیارهای بعد.
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
فراگیران
مؤلفه Learner حاوی عامل است و بهروزرسانیهای مرحله گرادیان متغیرهای خط مشی را با استفاده از دادههای تجربه از بافر پخش مجدد انجام میدهد. پس از یک یا چند مرحله آموزشی، یادگیرنده می تواند مجموعه جدیدی از مقادیر متغیر را به ظرف متغیر فشار دهد.
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
معیارها و ارزیابی
ما نمونه بازیگر نقش اول مرد از تابع eval با actor.eval_metrics بالا، که ایجاد در طول ارزیابی سیاست معیارهای معمول استفاده می شود:
- بازده متوسط. بازده مجموع پاداشهایی است که هنگام اجرای یک سیاست در یک محیط برای یک قسمت به دست میآید، و معمولاً این مقدار را در چند قسمت به طور میانگین میگیریم.
- میانگین طول اپیزود.
ما Actor را برای تولید این معیارها اجرا می کنیم.
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
اتمام ماژول معیارهای برای پیاده سازی دیگر استاندارد از معیارهای متفاوت است.
آموزش عامل
حلقه آموزشی هم شامل جمع آوری داده ها از محیط و هم بهینه سازی شبکه های عامل است. در طول مسیر، ما گاهی اوقات خط مشی نماینده را ارزیابی می کنیم تا ببینیم که چگونه کار می کنیم.
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
تجسم
توطئه ها
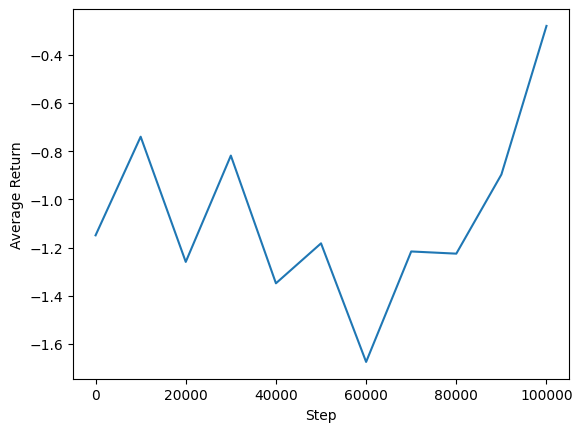
ما میتوانیم میانگین بازدهی را در مقابل مراحل جهانی ترسیم کنیم تا عملکرد نماینده خود را ببینیم. در Minitaur ، تابع پاداش است که تا چه حد minitaur پیاده روی در 1000 مراحل و جریمه مصرف انرژی است.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
فیلم های
تجسم عملکرد یک عامل با رندر کردن محیط در هر مرحله مفید است. قبل از انجام این کار، اجازه دهید ابتدا یک تابع برای جاسازی ویدیوها در این colab ایجاد کنیم.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
کد زیر خط مشی عامل را برای چند قسمت به تصویر می کشد:
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)