
| |
Wstęp
Duże modele językowe (LLM) to klasa modeli uczenia maszynowego, które są przeszkolone do generowania tekstu na podstawie dużych zbiorów danych. Można ich używać do zadań związanych z przetwarzaniem języka naturalnego (NLP), w tym do generowania tekstu, odpowiadania na pytania i tłumaczenia maszynowego. Opierają się na architekturze Transformera i są szkolone na ogromnych ilościach danych tekstowych, często obejmujących miliardy słów. Nawet LLM na mniejszą skalę, takie jak GPT-2, mogą działać imponująco. Konwersja modeli TensorFlow na lżejszy, szybszy i zużywający mniej energii model pozwala nam uruchamiać generatywne modele AI na urządzeniu, co zapewnia większe bezpieczeństwo użytkownika, ponieważ dane nigdy nie opuszczą Twojego urządzenia.
W tym elemencie Runbook pokazano, jak utworzyć aplikację dla systemu Android za pomocą TensorFlow Lite w celu uruchomienia Keras LLM i przedstawiono sugestie dotyczące optymalizacji modelu przy użyciu technik kwantyzacji, które w przeciwnym razie wymagałyby znacznie większej ilości pamięci i większej mocy obliczeniowej do działania.
Mamy platformę aplikacji na Androida o otwartym kodzie źródłowym, do której można podłączyć dowolne kompatybilne TFLite LLM. Oto dwa dema:
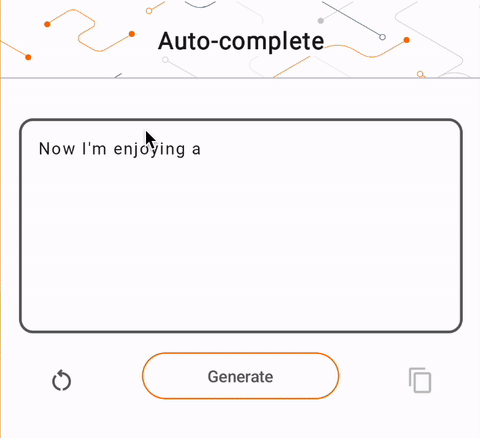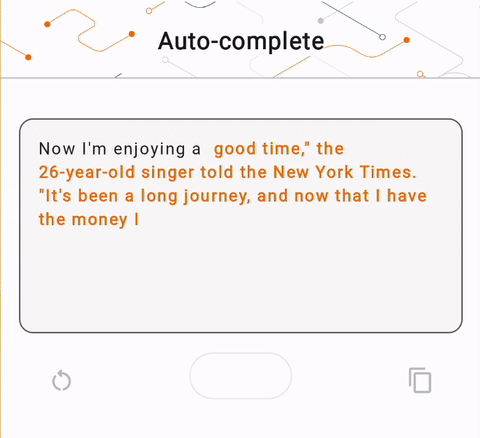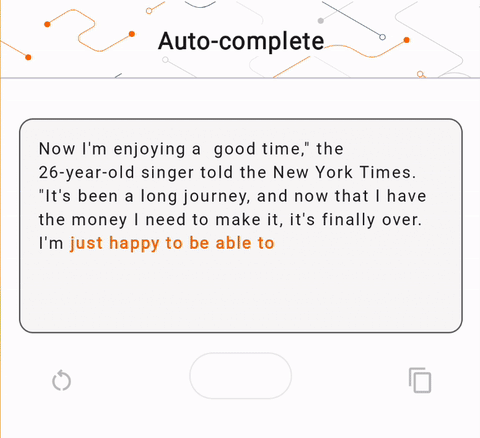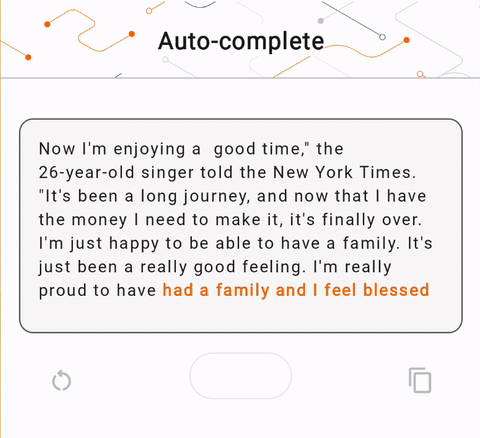
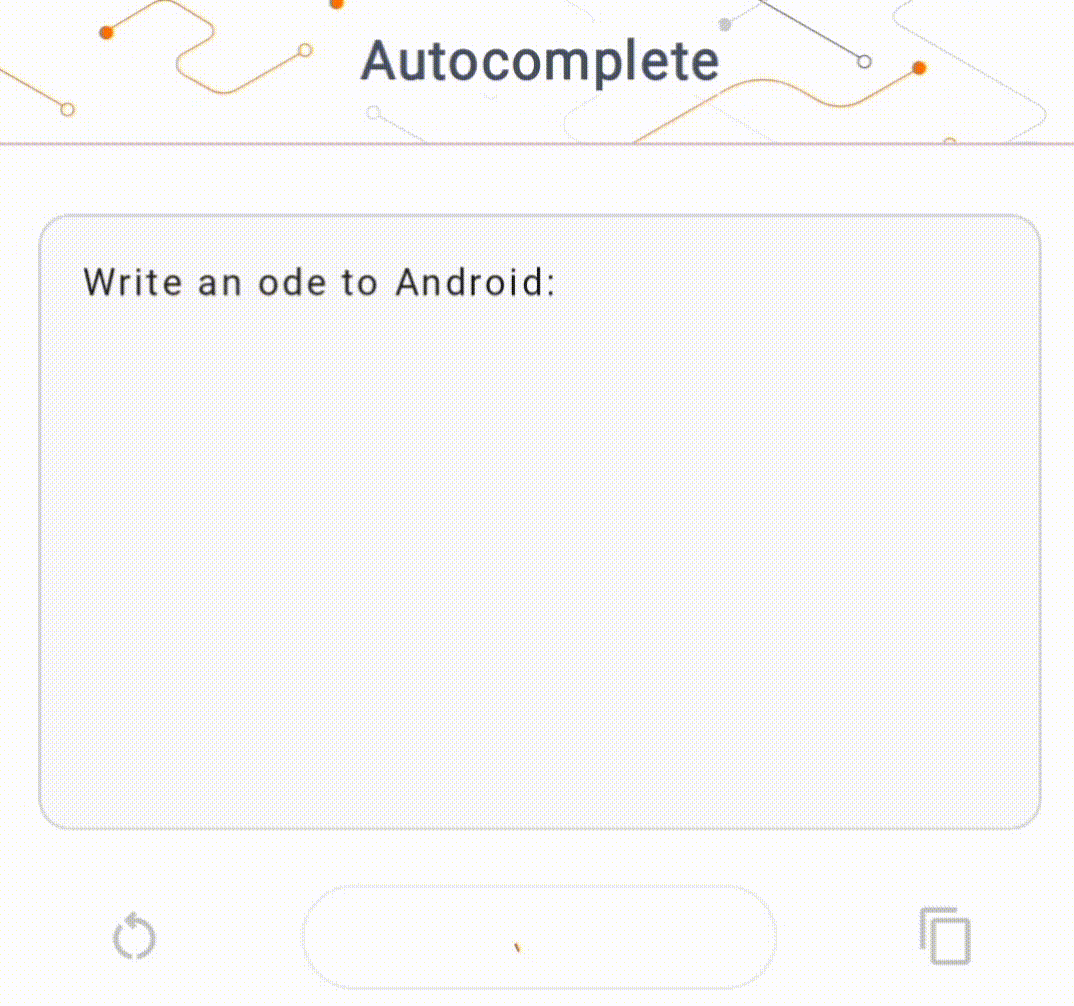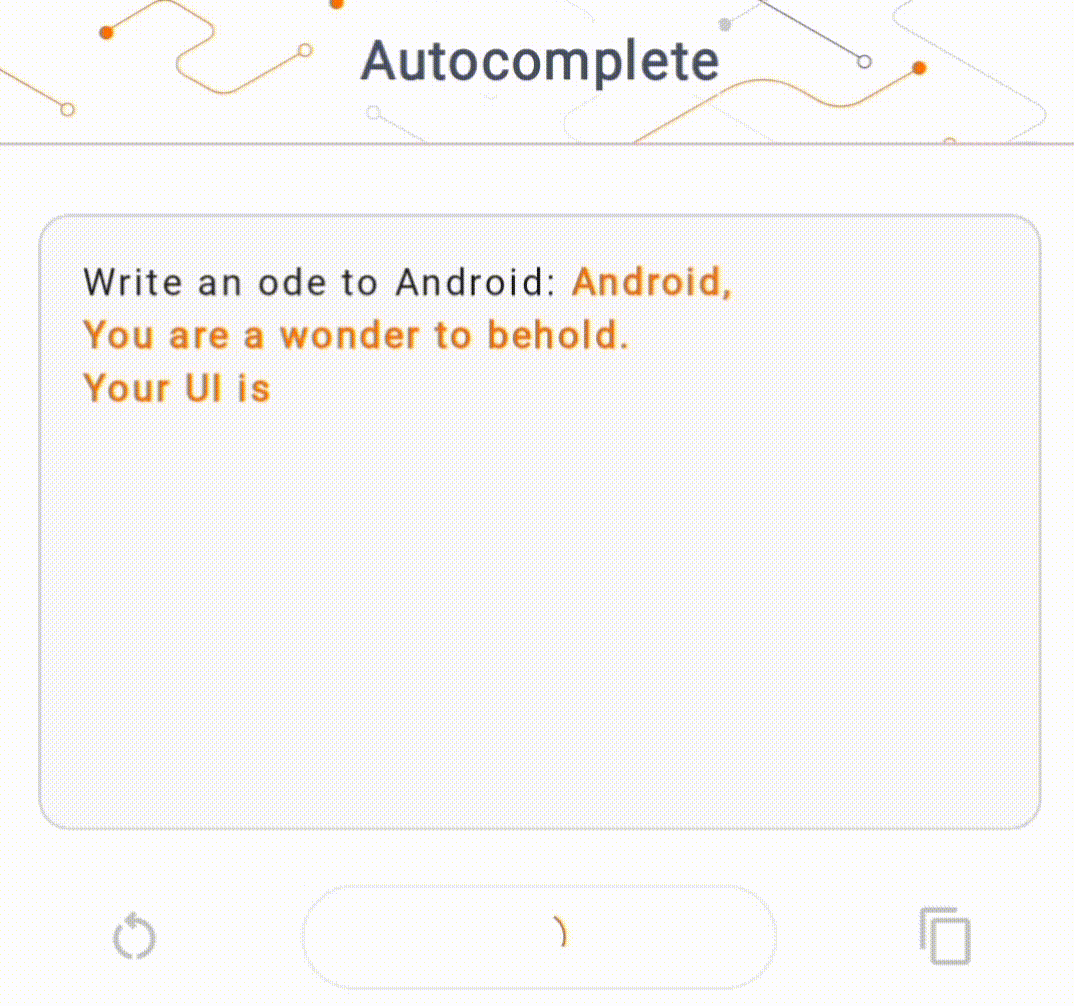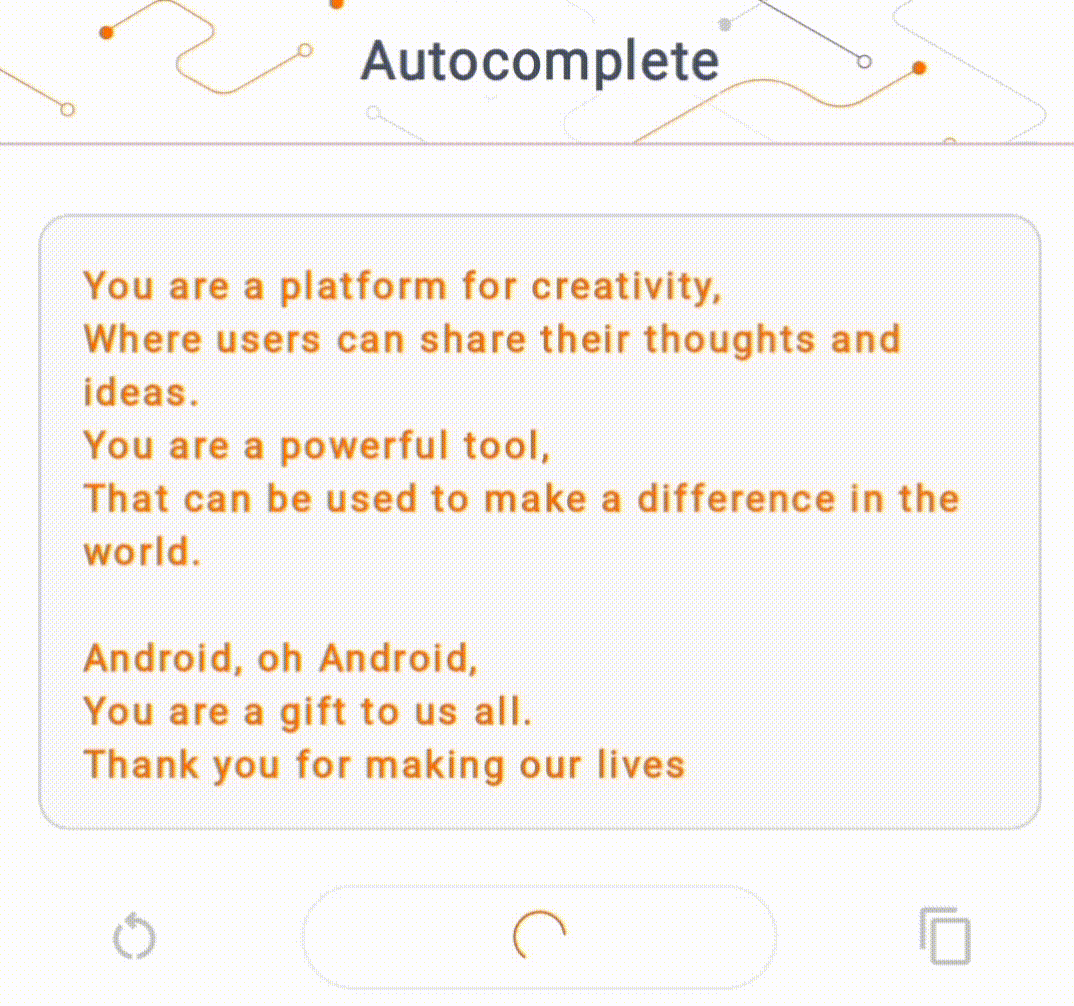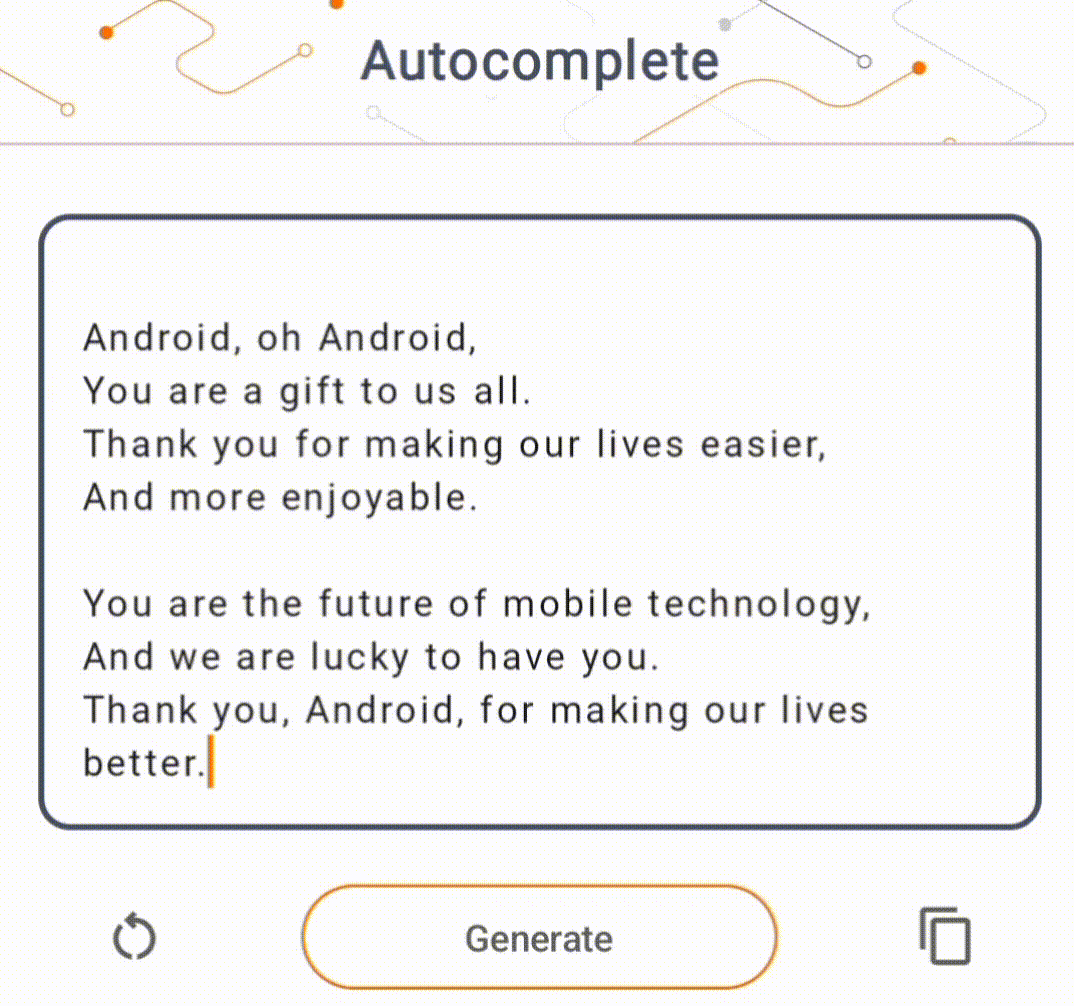
- Na rysunku 1 użyliśmy modelu Keras GPT-2 do wykonywania zadań uzupełniania tekstu na urządzeniu.
- Na rysunku 2 przekonwertowaliśmy wersję modelu PaLM dostosowanego do instrukcji (1,5 miliarda parametrów) na TFLite i wykonaliśmy ją w środowisku wykonawczym TFLite.
Przewodniki
Autorstwo modelu
W tej demonstracji użyjemy KerasNLP, aby uzyskać model GPT-2. KerasNLP to biblioteka zawierająca najnowocześniejsze, wstępnie wytrenowane modele do zadań przetwarzania języka naturalnego i mogąca wspierać użytkowników przez cały cykl programowania. Listę modeli dostępnych w repozytorium KerasNLP możesz zobaczyć. Przepływy pracy są zbudowane z modułowych komponentów, które mają najnowocześniejsze, wstępnie ustawione wagi i architektury, gdy są używane od razu po wyjęciu z pudełka, i można je łatwo dostosować, gdy potrzebna jest większa kontrola. Tworzenie modelu GPT-2 można wykonać w następujących krokach:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
Jedną wspólną cechą tych trzech linii kodu jest metoda from_preset() , która utworzy instancję części API Keras na podstawie wstępnie ustawionej architektury i/lub wag, ładując w ten sposób wstępnie wytrenowany model. Z tego fragmentu kodu zauważysz także trzy modułowe komponenty:
Tokenizer : konwertuje surowy ciąg wejściowy na identyfikatory tokenów w postaci liczb całkowitych odpowiednie dla warstwy Keras Embedding. GPT-2 używa w szczególności tokenizera kodowania par bajtów (BPE).
Preprocesor : warstwa do tokenizacji i pakowania danych wejściowych, które mają zostać wprowadzone do modelu Keras. W tym przypadku preprocesor po tokenizacji dopełni tensor identyfikatorów tokenów do określonej długości (256).
Szkielet : model Keras zgodny z architekturą szkieletu transformatora SoTA i ma wstępnie ustawione wagi.
Dodatkowo możesz sprawdzić pełną implementację modelu GPT-2 na GitHub .
Konwersja modelu
TensorFlow Lite to mobilna biblioteka do wdrażania metod na urządzeniach mobilnych, mikrokontrolerach i innych urządzeniach brzegowych. Pierwszym krokiem jest konwersja modelu Keras do bardziej kompaktowego formatu TensorFlow Lite przy użyciu konwertera TensorFlow Lite, a następnie użycie konwertera TensorFlow Lite, który jest wysoce zoptymalizowany pod kątem urządzeń mobilnych, do uruchomienia skonwertowanego modelu.
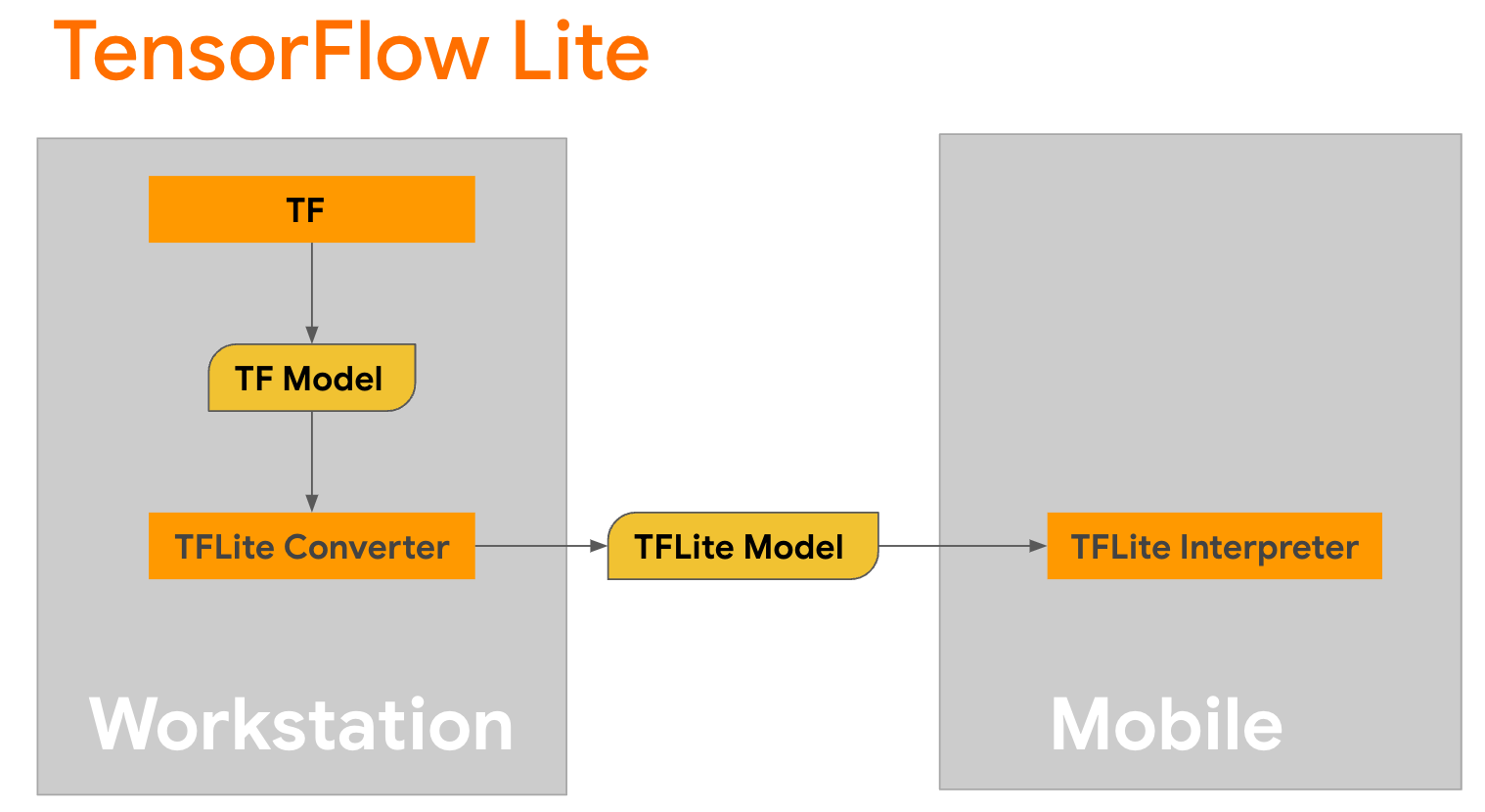 Zacznij od funkcji
Zacznij od funkcji generate() z GPT2CausalLM , która wykonuje konwersję. Zawiń funkcję generate() , aby utworzyć konkretną funkcję TensorFlow:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
Pamiętaj, że w celu przeprowadzenia konwersji możesz także użyć from_keras_model() z TFLiteConverter .
Teraz zdefiniuj funkcję pomocniczą, która będzie uruchamiać wnioskowanie na podstawie danych wejściowych i modelu TFLite. Operacje tekstowe TensorFlow nie są wbudowanymi operacjami w środowisku wykonawczym TFLite, dlatego będziesz musiał dodać te niestandardowe operacje, aby interpreter mógł wyciągnąć wnioski na temat tego modelu. Ta funkcja pomocnicza przyjmuje dane wejściowe i funkcję, która wykonuje konwersję, a mianowicie zdefiniowaną powyżej funkcję generator() .
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
Możesz teraz przekonwertować model:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
Kwantyzacja
TensorFlow Lite wdrożył technikę optymalizacji zwaną kwantyzacją , która może zmniejszyć rozmiar modelu i przyspieszyć wnioskowanie. W procesie kwantyzacji 32-bitowe liczby zmiennoprzecinkowe są mapowane na mniejsze 8-bitowe liczby całkowite, zmniejszając w ten sposób rozmiar modelu czterokrotnie, co zapewnia bardziej wydajne wykonanie na nowoczesnym sprzęcie. Istnieje kilka sposobów kwantyzacji w TensorFlow. Aby uzyskać więcej informacji, możesz odwiedzić strony Optymalizacja modelu TFLite i Zestaw narzędzi do optymalizacji modelu TensorFlow . Rodzaje kwantyzacji wyjaśniono pokrótce poniżej.
Tutaj użyjesz kwantyzacji zakresu dynamicznego po treningu w modelu GPT-2, ustawiając flagę optymalizacji konwertera na tf.lite.Optimize.DEFAULT , a reszta procesu konwersji będzie taka sama, jak opisano wcześniej. Przetestowaliśmy, że przy tej technice kwantyzacji opóźnienie wynosi około 6,7 sekundy na Pixelu 7 przy maksymalnej długości wyjściowej ustawionej na 100.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
Zakres dynamiczny
Kwantyzacja zakresu dynamicznego jest zalecanym punktem wyjścia do optymalizacji modeli na urządzeniu. Może osiągnąć około 4-krotne zmniejszenie rozmiaru modelu i jest zalecanym punktem wyjścia, ponieważ zapewnia mniejsze zużycie pamięci i szybsze obliczenia bez konieczności dostarczania reprezentatywnego zbioru danych do kalibracji. Ten typ kwantyzacji statycznie kwantyzuje w czasie konwersji tylko wagi od zmiennoprzecinkowej do 8-bitowej liczby całkowitej.
FP16
Modele zmiennoprzecinkowe można również optymalizować poprzez kwantyzację wag do typu float16. Zaletami kwantyzacji float16 jest zmniejszenie rozmiaru modelu nawet o połowę (ponieważ wszystkie wagi zmniejszają się o połowę), co powoduje minimalną utratę dokładności i obsługę delegatów GPU, które mogą działać bezpośrednio na danych float16 (co skutkuje szybszymi obliczeniami niż w przypadku float32 dane). Model przekonwertowany na wagi float16 może nadal działać na procesorze bez dodatkowych modyfikacji. Wagi float16 są próbkowane do float32 przed pierwszym wnioskowaniem, co pozwala na zmniejszenie rozmiaru modelu w zamian za minimalny wpływ na opóźnienia i dokładność.
Pełna kwantyzacja całkowita
Pełna kwantyzacja liczb całkowitych konwertuje 32-bitowe liczby zmiennoprzecinkowe, w tym wagi i aktywacje, na najbliższe 8-bitowe liczby całkowite. Efektem tego typu kwantyzacji jest mniejszy model o zwiększonej szybkości wnioskowania, co jest niezwykle cenne w przypadku stosowania mikrokontrolerów. Ten tryb jest zalecany, gdy aktywacje są wrażliwe na kwantyzację.
Integracja aplikacji na Androida
Możesz skorzystać z tego przykładu Androida , aby zintegrować swój model TFLite z aplikacją na Androida.
Warunki wstępne
Jeśli jeszcze tego nie zrobiłeś, zainstaluj Android Studio , postępując zgodnie z instrukcjami na stronie.
- Android Studio 2022.2.1 lub nowszy.
- Urządzenie z Androidem lub emulator Androida z pamięcią większą niż 4G
Tworzenie i uruchamianie w Android Studio
- Otwórz Android Studio i na ekranie powitalnym wybierz Otwórz istniejący projekt Android Studio .
- W wyświetlonym oknie Otwórz plik lub projekt przejdź i wybierz katalog
lite/examples/generative_ai/androidz miejsca, w którym sklonowałeś przykładowe repozytorium GitHub TensorFlow Lite. - W zależności od komunikatów o błędach może być również konieczne zainstalowanie różnych platform i narzędzi.
- Zmień nazwę przekonwertowanego modelu .tflite na
autocomplete.tflitei skopiuj go do folderuapp/src/main/assets/. - Wybierz menu Kompiluj -> Utwórz projekt, aby zbudować aplikację. (Ctrl+F9, w zależności od wersji).
- Kliknij menu Uruchom -> Uruchom „aplikację” . (Shift+F10, w zależności od wersji)
Alternatywnie możesz także użyć opakowania gradle , aby zbudować je w wierszu poleceń. Więcej informacji można znaleźć w dokumentacji Gradle .
(Opcjonalnie) Tworzenie pliku .aar
Domyślnie aplikacja automatycznie pobiera potrzebne pliki .aar . Ale jeśli chcesz zbudować własny, przejdź do folderu app/libs/build_aar/ run ./build_aar.sh . Ten skrypt pobierze niezbędne operacje z TensorFlow Text i zbuduje aar dla operatorów Select TF.
Po kompilacji generowany jest nowy plik tftext_tflite_flex.aar . Zastąp plik .aar w folderze app/libs/ i ponownie zbuduj aplikację.
Pamiętaj, że nadal musisz dołączyć standardowy aar tensorflow-lite do pliku gradle.
Rozmiar okna kontekstowego
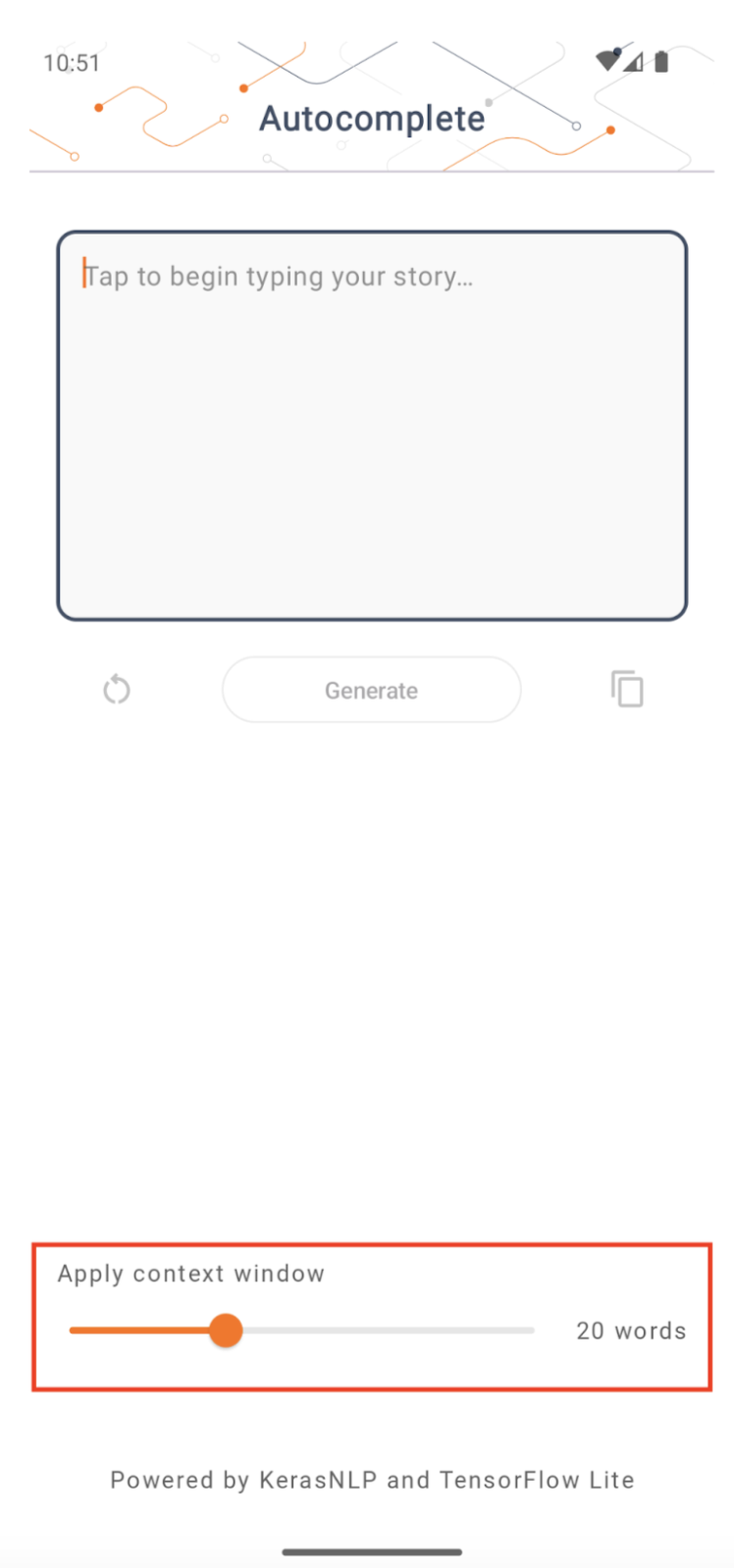
Aplikacja ma zmienny parametr „rozmiar okna kontekstowego”, który jest potrzebny, ponieważ dzisiejsze LLM mają zazwyczaj stały rozmiar kontekstu, który ogranicza liczbę słów/tokenów, które można wprowadzić do modelu jako „podpowiedź” (należy pamiętać, że „słowo” niekoniecznie jest w tym przypadku odpowiednik „tokenu” ze względu na różne metody tokenizacji). Liczba ta jest ważna, ponieważ:
- Ustawienie go na zbyt mały spowoduje, że model nie będzie miał wystarczającego kontekstu, aby wygenerować znaczące dane wyjściowe
- Ustawienie go na zbyt duży spowoduje, że model nie będzie miał wystarczająco dużo miejsca do pracy (ponieważ sekwencja wyjściowa zawiera monit)
Możesz z tym eksperymentować, ale dobrym początkiem będzie ustawienie go na ~50% długości sekwencji wyjściowej.
Bezpieczeństwo i odpowiedzialna sztuczna inteligencja
Jak zauważono w pierwotnym ogłoszeniu OpenAI GPT-2 , model GPT-2 ma istotne zastrzeżenia i ograniczenia . W rzeczywistości dzisiejsze LLM generalnie wiążą się z pewnymi dobrze znanymi wyzwaniami, takimi jak halucynacje, uczciwość i uprzedzenia; Dzieje się tak dlatego, że modele te są szkolone na danych ze świata rzeczywistego, dzięki czemu odzwierciedlają problemy ze świata rzeczywistego.
To ćwiczenie z programowania zostało stworzone wyłącznie w celu zademonstrowania, jak utworzyć aplikację obsługiwaną przez LLM za pomocą narzędzi TensorFlow. Model stworzony w tym laboratorium kodowania służy wyłącznie celom edukacyjnym i nie jest przeznaczony do użytku produkcyjnego.
Wykorzystanie produkcji LLM wymaga przemyślanego wyboru zbiorów danych szkoleniowych i kompleksowych środków ograniczających bezpieczeństwo. Jedną z takich funkcji oferowanych w tej aplikacji na Androida jest filtr wulgaryzmów, który odrzuca nieprawidłowe dane wejściowe użytkownika lub dane wyjściowe modelu. Jeśli wykryty zostanie nieodpowiedni język, aplikacja w odpowiedzi odrzuci tę czynność. Aby dowiedzieć się więcej na temat odpowiedzialnej sztucznej inteligencji w kontekście LLM, obejrzyj sesję techniczną dotyczącą bezpiecznego i odpowiedzialnego rozwoju z generatywnymi modelami językowymi podczas Google I/O 2023 i zapoznaj się z zestawem narzędzi Odpowiedzialna sztuczna inteligencja .