
Học có cấu trúc thần kinh (NSL) tập trung vào việc đào tạo mạng lưới thần kinh sâu bằng cách tận dụng các tín hiệu có cấu trúc (nếu có) cùng với đầu vào tính năng. Theo giới thiệu của Bùi et al. (WSDM'18) , các tín hiệu có cấu trúc này được sử dụng để thường xuyên hóa việc huấn luyện mạng nơ-ron, buộc mô hình phải học các dự đoán chính xác (bằng cách giảm thiểu tổn thất được giám sát), đồng thời duy trì sự tương đồng về cấu trúc đầu vào (bằng cách giảm thiểu tổn thất lân cận , xem hình bên dưới). Kỹ thuật này là chung và có thể được áp dụng trên các kiến trúc thần kinh tùy ý (chẳng hạn như NN chuyển tiếp nguồn cấp dữ liệu, NN chuyển đổi và NN lặp lại).
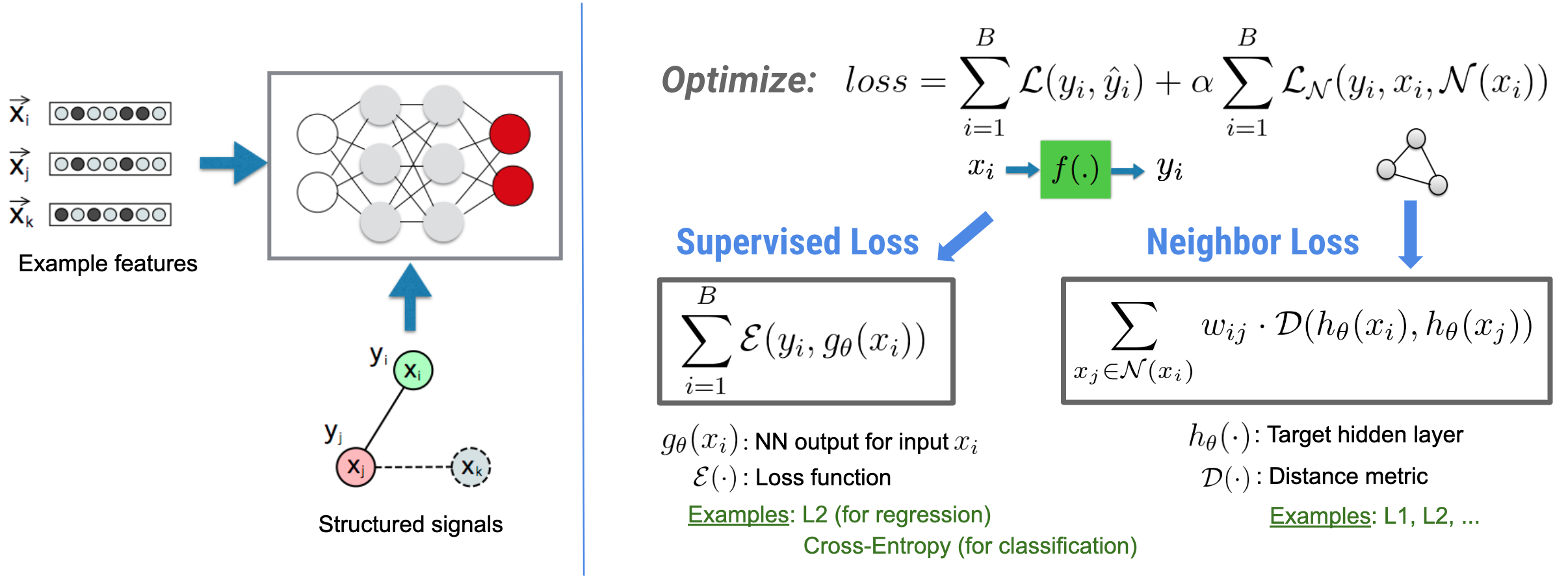
Lưu ý rằng phương trình tổn hao lân cận tổng quát rất linh hoạt và có thể có các dạng khác ngoài dạng được minh họa ở trên. Ví dụ, chúng ta cũng có thể chọn\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) là sự mất mát hàng xóm, tính toán khoảng cách giữa sự thật mặt đất \(y_i\)và lời dự đoán từ người hàng xóm \(g_\theta(x_j)\). Điều này thường được sử dụng trong học tập đối nghịch (Goodfellow và cộng sự, ICLR'15) . Do đó, NSL khái quát hóa cho Học đồ thị thần kinh nếu những người hàng xóm được biểu thị rõ ràng bằng biểu đồ và Học tập đối nghịch nếu những người hàng xóm ngầm bị gây ra bởi sự nhiễu loạn đối nghịch.
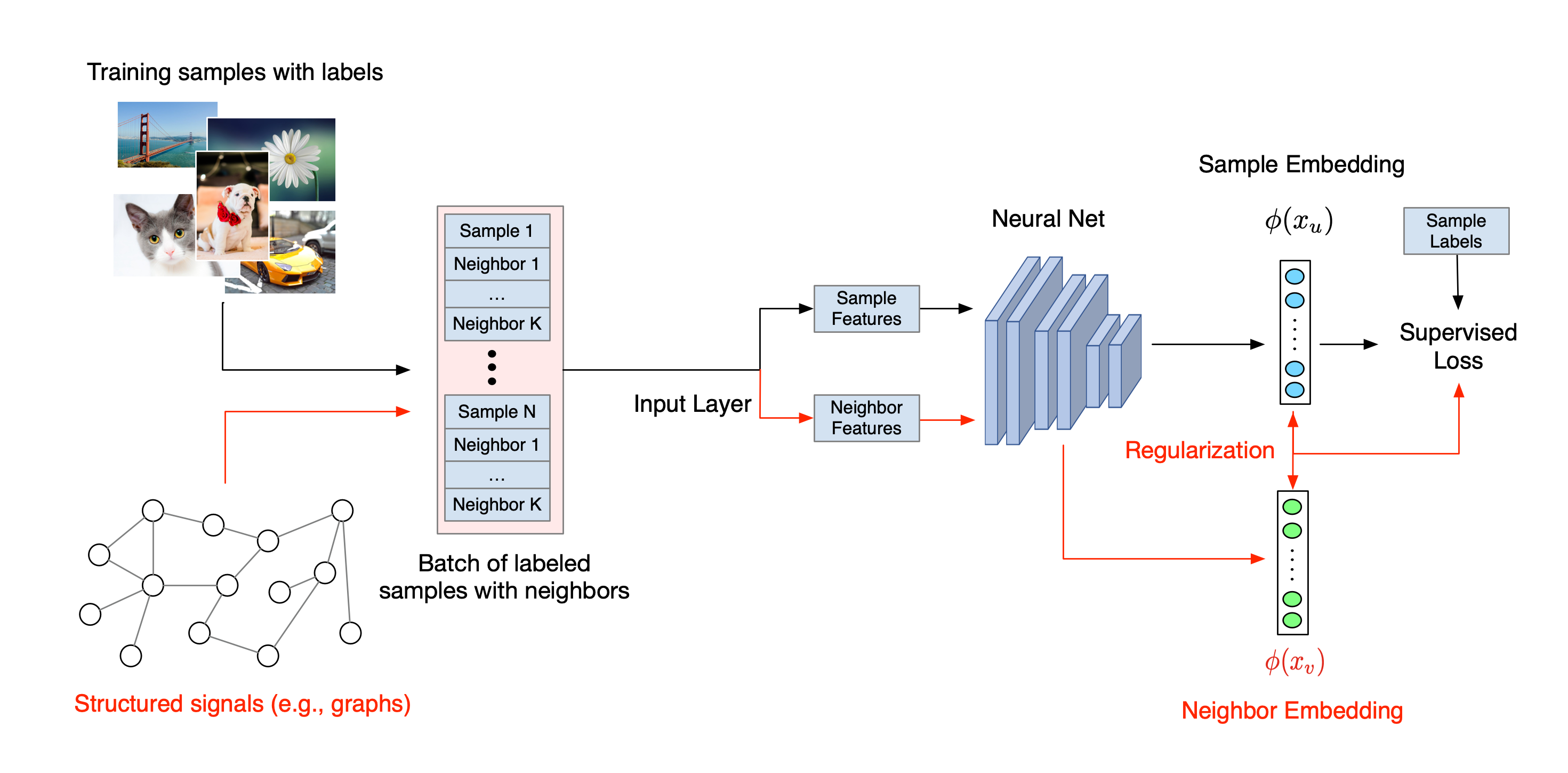
Quy trình làm việc tổng thể cho Học tập có cấu trúc thần kinh được minh họa dưới đây. Mũi tên đen thể hiện quy trình đào tạo thông thường và mũi tên màu đỏ thể hiện quy trình làm việc mới được NSL giới thiệu để tận dụng các tín hiệu có cấu trúc. Đầu tiên, các mẫu huấn luyện được tăng cường để bao gồm các tín hiệu có cấu trúc. Khi các tín hiệu có cấu trúc không được cung cấp rõ ràng, chúng có thể được tạo ra hoặc được tạo ra (điều này áp dụng cho việc học đối nghịch). Tiếp theo, các mẫu đào tạo tăng cường (bao gồm cả mẫu gốc và mẫu lân cận tương ứng của chúng) được đưa vào mạng nơ-ron để tính toán mức nhúng của chúng. Khoảng cách giữa phần nhúng của mẫu và phần nhúng của mẫu lân cận được tính toán và sử dụng làm tổn thất lân cận, được coi như một thuật ngữ chính quy hóa và được cộng vào tổn thất cuối cùng. Để chính quy hóa dựa trên hàng xóm rõ ràng, chúng tôi thường tính toán tổn thất hàng xóm là khoảng cách giữa phần nhúng của mẫu và phần nhúng của hàng xóm. Tuy nhiên, bất kỳ lớp nào của mạng nơron đều có thể được sử dụng để tính toán tổn thất lân cận. Mặt khác, đối với việc chính quy hóa dựa trên hàng xóm cảm ứng (đối nghịch), chúng tôi tính tổn thất lân cận là khoảng cách giữa dự đoán đầu ra của hàng xóm đối lập cảm ứng và nhãn chân lý cơ bản.
Tại sao nên sử dụng NSL?
NSL mang lại những ưu điểm sau:
- Độ chính xác cao hơn : (các) tín hiệu có cấu trúc giữa các mẫu có thể cung cấp thông tin không phải lúc nào cũng có sẵn trong đầu vào tính năng; do đó, phương pháp đào tạo chung (với cả tín hiệu và tính năng có cấu trúc) đã được chứng minh là vượt trội hơn nhiều phương pháp hiện có (chỉ dựa vào đào tạo với các tính năng) trên nhiều nhiệm vụ, chẳng hạn như phân loại tài liệu và phân loại mục đích ngữ nghĩa ( Bui et al ., WSDM'18 & Kipf và cộng sự, ICLR'17 ).
- Tính mạnh mẽ : các mô hình được đào tạo bằng các ví dụ đối nghịch đã được chứng minh là có khả năng chống lại các nhiễu loạn đối nghịch được thiết kế nhằm gây hiểu lầm cho dự đoán hoặc phân loại của mô hình ( Goodfellow và cộng sự, ICLR'15 & Miyato và cộng sự, ICLR'16 ). Khi số lượng mẫu huấn luyện ít, việc huấn luyện với các ví dụ đối nghịch cũng giúp cải thiện độ chính xác của mô hình ( Tsipras et al., ICLR'19 ).
- Yêu cầu ít dữ liệu được gắn nhãn hơn : NSL cho phép các mạng thần kinh khai thác cả dữ liệu được gắn nhãn và không được gắn nhãn, điều này mở rộng mô hình học tập sang học tập bán giám sát . Cụ thể, NSL cho phép mạng huấn luyện bằng cách sử dụng dữ liệu được gắn nhãn như trong cài đặt được giám sát, đồng thời thúc đẩy mạng tìm hiểu các biểu diễn ẩn tương tự cho "các mẫu lân cận" có thể có hoặc không có nhãn. Kỹ thuật này đã cho thấy nhiều hứa hẹn trong việc cải thiện độ chính xác của mô hình khi lượng dữ liệu được dán nhãn tương đối nhỏ ( Bui và cộng sự, WSDM'18 & Miyato và cộng sự, ICLR'16 ).
Hướng dẫn từng bước
Để có được trải nghiệm thực tế về Học tập theo cấu trúc thần kinh, chúng tôi có các hướng dẫn bao gồm nhiều tình huống khác nhau trong đó các tín hiệu có cấu trúc có thể được đưa ra, xây dựng hoặc tạo ra một cách rõ ràng. Dưới đây là một số:
Chính quy hóa biểu đồ để phân loại tài liệu bằng biểu đồ tự nhiên . Trong hướng dẫn này, chúng ta khám phá cách sử dụng tính năng chính quy hóa biểu đồ để phân loại các tài liệu tạo thành biểu đồ tự nhiên (hữu cơ).
Chính quy hóa biểu đồ để phân loại tình cảm bằng cách sử dụng biểu đồ tổng hợp . Trong hướng dẫn này, chúng tôi trình bày cách sử dụng chính quy hóa biểu đồ để phân loại cảm xúc đánh giá phim bằng cách xây dựng (tổng hợp) các tín hiệu có cấu trúc.
Học đối nghịch để phân loại hình ảnh . Trong hướng dẫn này, chúng ta khám phá cách sử dụng phương pháp học đối nghịch (nơi tạo ra các tín hiệu có cấu trúc) để phân loại hình ảnh có chứa các chữ số.
Bạn có thể tìm thấy nhiều ví dụ và hướng dẫn khác trong thư mục ví dụ trên kho lưu trữ GitHub của chúng tôi.
,Học có cấu trúc thần kinh (NSL) tập trung vào việc đào tạo mạng lưới thần kinh sâu bằng cách tận dụng các tín hiệu có cấu trúc (nếu có) cùng với đầu vào tính năng. Theo giới thiệu của Bùi et al. (WSDM'18) , các tín hiệu có cấu trúc này được sử dụng để thường xuyên hóa việc huấn luyện mạng nơ-ron, buộc mô hình phải học các dự đoán chính xác (bằng cách giảm thiểu tổn thất được giám sát), đồng thời duy trì sự tương đồng về cấu trúc đầu vào (bằng cách giảm thiểu tổn thất lân cận , xem hình bên dưới). Kỹ thuật này là chung và có thể được áp dụng trên các kiến trúc thần kinh tùy ý (chẳng hạn như NN chuyển tiếp nguồn cấp dữ liệu, NN chuyển đổi và NN lặp lại).
Lưu ý rằng phương trình tổn hao lân cận tổng quát rất linh hoạt và có thể có các dạng khác ngoài dạng được minh họa ở trên. Ví dụ, chúng ta cũng có thể chọn\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) là sự mất mát hàng xóm, tính toán khoảng cách giữa sự thật mặt đất \(y_i\)và lời dự đoán từ người hàng xóm \(g_\theta(x_j)\). Điều này thường được sử dụng trong học tập đối nghịch (Goodfellow và cộng sự, ICLR'15) . Do đó, NSL khái quát hóa cho Học đồ thị thần kinh nếu các hàng xóm được biểu thị rõ ràng bằng biểu đồ và cho Học tập đối nghịch nếu các hàng xóm ngầm bị gây ra bởi nhiễu loạn đối nghịch.
Quy trình làm việc tổng thể cho Học tập có cấu trúc thần kinh được minh họa dưới đây. Mũi tên đen thể hiện quy trình đào tạo thông thường và mũi tên màu đỏ thể hiện quy trình làm việc mới được NSL giới thiệu để tận dụng các tín hiệu có cấu trúc. Đầu tiên, các mẫu huấn luyện được tăng cường để bao gồm các tín hiệu có cấu trúc. Khi các tín hiệu có cấu trúc không được cung cấp rõ ràng, chúng có thể được tạo ra hoặc được tạo ra (điều này áp dụng cho việc học đối nghịch). Tiếp theo, các mẫu đào tạo tăng cường (bao gồm cả mẫu gốc và mẫu lân cận tương ứng của chúng) được đưa vào mạng nơ-ron để tính toán mức nhúng của chúng. Khoảng cách giữa phần nhúng của mẫu và phần nhúng của mẫu lân cận được tính toán và sử dụng làm tổn thất lân cận, được coi như một thuật ngữ chính quy hóa và được cộng vào tổn thất cuối cùng. Để chính quy hóa dựa trên hàng xóm rõ ràng, chúng tôi thường tính toán tổn thất hàng xóm là khoảng cách giữa phần nhúng của mẫu và phần nhúng của hàng xóm. Tuy nhiên, bất kỳ lớp nào của mạng nơron đều có thể được sử dụng để tính toán tổn thất lân cận. Mặt khác, đối với việc chính quy hóa dựa trên hàng xóm cảm ứng (đối nghịch), chúng tôi tính tổn thất lân cận là khoảng cách giữa dự đoán đầu ra của hàng xóm đối lập cảm ứng và nhãn chân lý cơ bản.
Tại sao nên sử dụng NSL?
NSL mang lại những ưu điểm sau:
- Độ chính xác cao hơn : (các) tín hiệu có cấu trúc giữa các mẫu có thể cung cấp thông tin không phải lúc nào cũng có sẵn trong đầu vào tính năng; do đó, phương pháp đào tạo chung (với cả tín hiệu và tính năng có cấu trúc) đã được chứng minh là vượt trội hơn nhiều phương pháp hiện có (chỉ dựa vào đào tạo với các tính năng) trên nhiều nhiệm vụ, chẳng hạn như phân loại tài liệu và phân loại mục đích ngữ nghĩa ( Bui et al ., WSDM'18 & Kipf và cộng sự, ICLR'17 ).
- Tính mạnh mẽ : các mô hình được đào tạo bằng các ví dụ đối nghịch đã được chứng minh là có khả năng chống lại các nhiễu loạn đối nghịch được thiết kế nhằm gây hiểu lầm cho dự đoán hoặc phân loại của mô hình ( Goodfellow và cộng sự, ICLR'15 & Miyato và cộng sự, ICLR'16 ). Khi số lượng mẫu huấn luyện ít, việc huấn luyện với các ví dụ đối nghịch cũng giúp cải thiện độ chính xác của mô hình ( Tsipras et al., ICLR'19 ).
- Yêu cầu ít dữ liệu được gắn nhãn hơn : NSL cho phép các mạng thần kinh khai thác cả dữ liệu được gắn nhãn và không được gắn nhãn, điều này mở rộng mô hình học tập sang học tập bán giám sát . Cụ thể, NSL cho phép mạng huấn luyện bằng cách sử dụng dữ liệu được gắn nhãn như trong cài đặt được giám sát, đồng thời thúc đẩy mạng tìm hiểu các biểu diễn ẩn tương tự cho "các mẫu lân cận" có thể có hoặc không có nhãn. Kỹ thuật này đã cho thấy nhiều hứa hẹn trong việc cải thiện độ chính xác của mô hình khi lượng dữ liệu được dán nhãn tương đối nhỏ ( Bui và cộng sự, WSDM'18 & Miyato và cộng sự, ICLR'16 ).
Hướng dẫn từng bước
Để có được trải nghiệm thực tế về Học tập theo cấu trúc thần kinh, chúng tôi có các hướng dẫn bao gồm nhiều tình huống khác nhau trong đó các tín hiệu có cấu trúc có thể được đưa ra, xây dựng hoặc tạo ra một cách rõ ràng. Dưới đây là một số:
Chính quy hóa biểu đồ để phân loại tài liệu bằng biểu đồ tự nhiên . Trong hướng dẫn này, chúng ta khám phá cách sử dụng tính năng chính quy hóa biểu đồ để phân loại các tài liệu tạo thành biểu đồ tự nhiên (hữu cơ).
Chính quy hóa biểu đồ để phân loại tình cảm bằng cách sử dụng biểu đồ tổng hợp . Trong hướng dẫn này, chúng tôi trình bày cách sử dụng chính quy hóa biểu đồ để phân loại cảm xúc đánh giá phim bằng cách xây dựng (tổng hợp) các tín hiệu có cấu trúc.
Học đối nghịch để phân loại hình ảnh . Trong hướng dẫn này, chúng ta khám phá cách sử dụng phương pháp học đối nghịch (nơi tạo ra các tín hiệu có cấu trúc) để phân loại hình ảnh có chứa các chữ số.
Bạn có thể tìm thấy nhiều ví dụ và hướng dẫn khác trong thư mục ví dụ trên kho lưu trữ GitHub của chúng tôi.
,Học có cấu trúc thần kinh (NSL) tập trung vào việc đào tạo mạng lưới thần kinh sâu bằng cách tận dụng các tín hiệu có cấu trúc (nếu có) cùng với đầu vào tính năng. Theo giới thiệu của Bùi et al. (WSDM'18) , các tín hiệu có cấu trúc này được sử dụng để thường xuyên hóa việc huấn luyện mạng nơ-ron, buộc mô hình phải học các dự đoán chính xác (bằng cách giảm thiểu tổn thất được giám sát), đồng thời duy trì sự tương đồng về cấu trúc đầu vào (bằng cách giảm thiểu tổn thất lân cận , xem hình bên dưới). Kỹ thuật này là chung và có thể được áp dụng trên các kiến trúc thần kinh tùy ý (chẳng hạn như NN chuyển tiếp nguồn cấp dữ liệu, NN chuyển đổi và NN lặp lại).
Lưu ý rằng phương trình tổn hao lân cận tổng quát rất linh hoạt và có thể có các dạng khác ngoài dạng được minh họa ở trên. Ví dụ, chúng ta cũng có thể chọn\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) là sự mất mát hàng xóm, tính toán khoảng cách giữa sự thật mặt đất \(y_i\)và lời dự đoán từ người hàng xóm \(g_\theta(x_j)\). Điều này thường được sử dụng trong học tập đối nghịch (Goodfellow và cộng sự, ICLR'15) . Do đó, NSL khái quát hóa cho Học đồ thị thần kinh nếu các hàng xóm được biểu thị rõ ràng bằng biểu đồ và cho Học tập đối nghịch nếu các hàng xóm ngầm bị gây ra bởi nhiễu loạn đối nghịch.
Quy trình làm việc tổng thể cho Học tập có cấu trúc thần kinh được minh họa dưới đây. Mũi tên đen thể hiện quy trình đào tạo thông thường và mũi tên màu đỏ thể hiện quy trình làm việc mới được NSL giới thiệu để tận dụng các tín hiệu có cấu trúc. Đầu tiên, các mẫu huấn luyện được tăng cường để bao gồm các tín hiệu có cấu trúc. Khi các tín hiệu có cấu trúc không được cung cấp rõ ràng, chúng có thể được tạo ra hoặc được tạo ra (điều này áp dụng cho việc học đối nghịch). Tiếp theo, các mẫu đào tạo tăng cường (bao gồm cả mẫu gốc và mẫu lân cận tương ứng của chúng) được đưa vào mạng nơ-ron để tính toán mức nhúng của chúng. Khoảng cách giữa phần nhúng của mẫu và phần nhúng của mẫu lân cận được tính toán và sử dụng làm tổn thất lân cận, được coi như một thuật ngữ chính quy hóa và được cộng vào tổn thất cuối cùng. Để chính quy hóa dựa trên hàng xóm rõ ràng, chúng tôi thường tính toán tổn thất hàng xóm là khoảng cách giữa phần nhúng của mẫu và phần nhúng của hàng xóm. Tuy nhiên, bất kỳ lớp nào của mạng nơron đều có thể được sử dụng để tính toán tổn thất lân cận. Mặt khác, đối với việc chính quy hóa dựa trên hàng xóm cảm ứng (đối nghịch), chúng tôi tính tổn thất lân cận là khoảng cách giữa dự đoán đầu ra của hàng xóm đối lập cảm ứng và nhãn chân lý cơ bản.
Tại sao nên sử dụng NSL?
NSL mang lại những ưu điểm sau:
- Độ chính xác cao hơn : (các) tín hiệu có cấu trúc giữa các mẫu có thể cung cấp thông tin không phải lúc nào cũng có sẵn trong đầu vào tính năng; do đó, phương pháp đào tạo chung (với cả tín hiệu và tính năng có cấu trúc) đã được chứng minh là vượt trội hơn nhiều phương pháp hiện có (chỉ dựa vào đào tạo với các tính năng) trên nhiều nhiệm vụ, chẳng hạn như phân loại tài liệu và phân loại mục đích ngữ nghĩa ( Bui et al ., WSDM'18 & Kipf và cộng sự, ICLR'17 ).
- Tính mạnh mẽ : các mô hình được đào tạo bằng các ví dụ đối nghịch đã được chứng minh là có khả năng chống lại các nhiễu loạn đối nghịch được thiết kế nhằm gây hiểu lầm cho dự đoán hoặc phân loại của mô hình ( Goodfellow và cộng sự, ICLR'15 & Miyato và cộng sự, ICLR'16 ). Khi số lượng mẫu huấn luyện ít, việc huấn luyện với các ví dụ đối nghịch cũng giúp cải thiện độ chính xác của mô hình ( Tsipras et al., ICLR'19 ).
- Yêu cầu ít dữ liệu được gắn nhãn hơn : NSL cho phép các mạng thần kinh khai thác cả dữ liệu được gắn nhãn và không được gắn nhãn, điều này mở rộng mô hình học tập sang học tập bán giám sát . Cụ thể, NSL cho phép mạng huấn luyện bằng cách sử dụng dữ liệu được gắn nhãn như trong cài đặt được giám sát, đồng thời thúc đẩy mạng tìm hiểu các biểu diễn ẩn tương tự cho "các mẫu lân cận" có thể có hoặc không có nhãn. Kỹ thuật này đã cho thấy nhiều hứa hẹn trong việc cải thiện độ chính xác của mô hình khi lượng dữ liệu được dán nhãn tương đối nhỏ ( Bui và cộng sự, WSDM'18 & Miyato và cộng sự, ICLR'16 ).
Hướng dẫn từng bước
Để có được trải nghiệm thực tế về Học tập theo cấu trúc thần kinh, chúng tôi có các hướng dẫn bao gồm nhiều tình huống khác nhau trong đó các tín hiệu có cấu trúc có thể được đưa ra, xây dựng hoặc tạo ra một cách rõ ràng. Dưới đây là một số:
Chính quy hóa biểu đồ để phân loại tài liệu bằng biểu đồ tự nhiên . Trong hướng dẫn này, chúng ta khám phá cách sử dụng tính năng chính quy hóa biểu đồ để phân loại các tài liệu tạo thành biểu đồ tự nhiên (hữu cơ).
Chính quy hóa biểu đồ để phân loại tình cảm bằng cách sử dụng biểu đồ tổng hợp . Trong hướng dẫn này, chúng tôi trình bày cách sử dụng chính quy hóa biểu đồ để phân loại cảm xúc đánh giá phim bằng cách xây dựng (tổng hợp) các tín hiệu có cấu trúc.
Học đối nghịch để phân loại hình ảnh . Trong hướng dẫn này, chúng ta khám phá cách sử dụng phương pháp học đối nghịch (nơi tạo ra các tín hiệu có cấu trúc) để phân loại hình ảnh có chứa các chữ số.
Bạn có thể tìm thấy nhiều ví dụ và hướng dẫn khác trong thư mục ví dụ trên kho lưu trữ GitHub của chúng tôi.