
概要
TensorFlow Model Analysis (TFMA) は、モデル評価を実行するためのライブラリです。
- 対象: 機械学習エンジニアまたはデータ サイエンティスト
- 誰: TensorFlow モデルを分析して理解したい人
- それは、スタンドアロンのライブラリまたは TFX パイプラインのコンポーネントです。
- それは、トレーニングで定義された同じメトリクスに基づいて、分散された方法で大量のデータのモデルを評価します。これらのメトリクスはデータのスライスにわたって比較され、Jupyter または Colab ノートブックで視覚化されます。
- 異なるもの: モデル イントロスペクションを提供する tensorboard などの一部のモデル イントロスペクション ツール
TFMA は、Apache Beamを使用して大量のデータに対して分散方式で計算を実行します。次のセクションでは、基本的な TFMA 評価パイプラインをセットアップする方法について説明します。基礎となる実装のアーキテクチャの詳細を参照してください。
すぐに始めたい場合は、 colabノートブックをチェックしてください。
このページはtensorflow.orgからも参照できます。
サポートされているモデルタイプ
TFMA は、tensorflow ベースのモデルをサポートするように設計されていますが、他のフレームワークもサポートするように簡単に拡張できます。従来、TFMA では、TFMA を使用するにはEvalSavedModelを作成する必要がありましたが、TFMA の最新バージョンでは、ユーザーのニーズに応じて複数のタイプのモデルがサポートされています。 EvalSavedModel の設定は、 tf.estimatorベースのモデルが使用され、カスタム トレーニング時間メトリクスが必要な場合にのみ必要です。
TFMA はサービング モデルに基づいて実行されるようになったため、TFMA はトレーニング時に追加されたメトリクスを自動的に評価しなくなることに注意してください。この場合の例外は、keras モデルが使用される場合です。これは、keras が保存されたモデルと一緒に使用されるメトリクスを保存するためです。ただし、これが厳しい要件である場合でも、最新の TFMA には下位互換性があり、 EvalSavedModel TFMA パイプラインで引き続き実行できます。
次の表は、デフォルトでサポートされるモデルをまとめたものです。
| モデルタイプ | トレーニング時間の測定基準 | トレーニング後のメトリクス |
|---|---|---|
| TF2 (ケラス) | や* | Y |
| TF2(汎用) | 該当なし | Y |
| EvalSavedModel (推定器) | Y | Y |
| なし (pd.DataFrame など) | 該当なし | Y |
- トレーニング時間メトリクスは、トレーニング時に定義され、モデル (TFMA EvalSavedModel または keras 保存モデル) とともに保存されたメトリクスを指します。トレーニング後のメトリクスは、
tfma.MetricConfigによって追加されたメトリクスを指します。 - 汎用 TF2 モデルは、推論に使用できる署名をエクスポートするカスタム モデルであり、keras や推定器のいずれにも基づいていません。
これらのさまざまなモデル タイプのセットアップおよび構成方法の詳細については、 FAQ を参照してください。
設定
評価を実行する前に、少量のセットアップが必要です。まず、評価されるモデル、メトリック、スライスの仕様を提供するtfma.EvalConfigオブジェクトを定義する必要があります。次に、評価中に使用される実際のモデル (複数可) を指すtfma.EvalSharedModelを作成する必要があります。これらを定義したら、適切なデータセットを使用してtfma.run_model_analysisを呼び出すことによって評価が実行されます。詳細については、セットアップガイドを参照してください。
TFX パイプライン内で実行する場合、TFX Evaluatorコンポーネントとして実行するように TFMA を構成する方法については、TFXガイドを参照してください。
例
単一モデルの評価
以下では、 tfma.run_model_analysisを使用して、サービング モデルの評価を実行します。必要なさまざまな設定の説明については、セットアップガイドを参照してください。
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
分散評価の場合は、分散ランナーを使用してApache Beamパイプラインを構築します。パイプラインでは、 tfma.ExtractEvaluateAndWriteResultsを使用して評価し、結果を書き込みます。結果は、 tfma.load_eval_resultを使用して視覚化のためにロードできます。
例えば:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
モデルの検証
候補およびベースラインに対してモデル検証を実行するには、構成を更新してしきい値設定を含め、2 つのモデルをtfma.run_model_analysisに渡します。
例えば:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
視覚化
TFMA の評価結果は、TFMA に含まれるフロントエンド コンポーネントを使用して Jupyter ノートブックで視覚化できます。例えば:
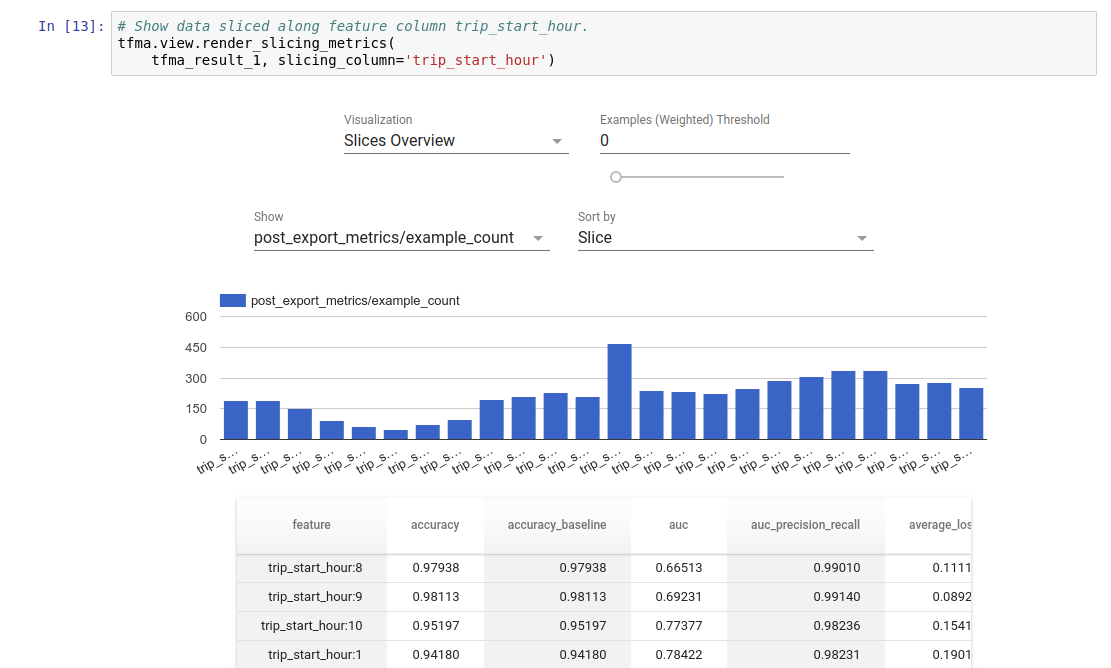 。
。