
После развертывания TensorFlow Serving и отправки запросов от вашего клиента вы можете заметить, что запросы выполняются дольше, чем вы ожидали, или вы не достигаете желаемой пропускной способности.
В этом руководстве мы будем использовать профилировщик TensorBoard, который вы, возможно, уже используете для профилирования обучения модели , для отслеживания запросов на вывод, чтобы помочь нам отладить и улучшить производительность вывода.
Вам следует использовать это руководство в сочетании с рекомендациями, указанными в Руководстве по производительности , для оптимизации вашей модели, запросов и экземпляра обслуживания TensorFlow.
Обзор
На высоком уровне мы направим инструмент профилирования TensorBoard на gRPC-сервер TensorFlow Serving. Когда мы отправляем запрос на вывод в Tensorflow Serving, мы также одновременно используем пользовательский интерфейс TensorBoard, чтобы попросить его зафиксировать следы этого запроса. За кулисами TensorBoard свяжется с TensorFlow Serving через gRPC и попросит его предоставить подробную трассировку времени жизни запроса на вывод. Затем TensorBoard будет визуализировать активность каждого потока на каждом вычислительном устройстве (выполняющий код, интегрированный с profiler::TraceMe ) в течение всего времени существования запроса в пользовательском интерфейсе TensorBoard, чтобы мы могли его использовать.
Предварительные условия
-
Tensorflow>=2.0.0 - TensorBoard (должен быть установлен, если TF был установлен через
pip) - Docker (который мы будем использовать для загрузки и запуска образа TF serving>=2.1.0)
Развертывание модели с помощью TensorFlow Serving
В этом примере мы будем использовать Docker, рекомендуемый способ развертывания Tensorflow Serving, для размещения игрушечной модели, вычисляющей f(x) = x / 2 + 2 найденной в репозитории Tensorflow Serving на Github .
Загрузите исходный код TensorFlow Serving.
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
Запустите TensorFlow Serving через Docker и разверните модель half_plus_two.
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
В другом терминале запросите модель, чтобы убедиться, что модель развернута правильно.
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
Настройте профилировщик TensorBoard
В другом терминале запустите инструмент TensorBoard на своем компьютере, предоставив каталог для сохранения событий трассировки вывода:
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
Перейдите по адресу http://localhost:6006/, чтобы просмотреть пользовательский интерфейс TensorBoard. Используйте раскрывающееся меню вверху, чтобы перейти на вкладку «Профиль». Нажмите «Захватить профиль» и укажите адрес gRPC-сервера Tensorflow Serving.
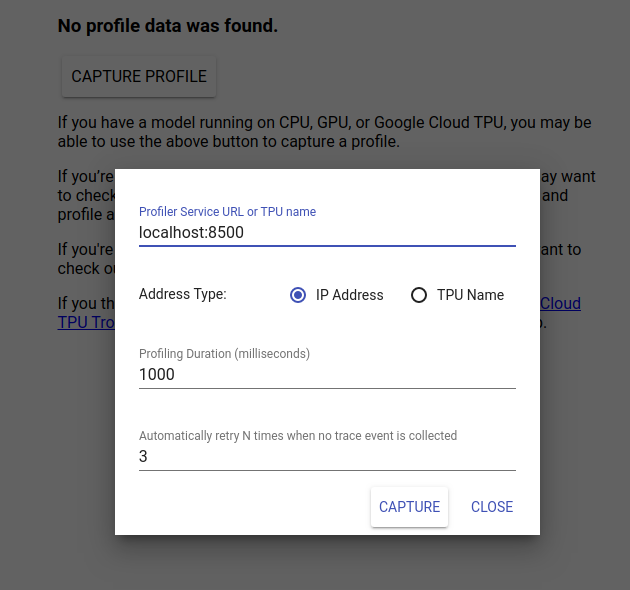
Как только вы нажмете «Захватить», TensorBoard начнет отправлять запросы профиля на сервер модели. В диалоговом окне выше вы можете установить как крайний срок для каждого запроса, так и общее количество повторных попыток Tensorboard, если события трассировки не собираются. Если вы профилируете дорогостоящую модель, вы можете увеличить срок, чтобы гарантировать, что время запроса профиля не истечет до завершения запроса на вывод.
Отправьте и профилируйте запрос на вывод
Нажмите Capture в пользовательском интерфейсе TensorBoard и после этого быстро отправьте запрос на вывод в TF Serving.
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
Вы должны увидеть сообщение «Захватить профиль успешно. Обновите». тост появится в нижней части экрана. Это означает, что TensorBoard смог получить события трассировки из TensorFlow Serving и сохранить их в вашем logdir . Обновите страницу, чтобы визуализировать запрос вывода с помощью средства просмотра трассировки Profiler, как показано в следующем разделе.
Анализ трассировки запроса на вывод

Теперь вы можете легко увидеть, какие вычисления происходят в результате вашего запроса на вывод. Вы можете увеличить масштаб и щелкнуть любой прямоугольник (отслеживание событий), чтобы получить дополнительную информацию, например точное время начала и продолжительность стены.
На высоком уровне мы видим два потока, принадлежащие среде выполнения TensorFlow, и третий, принадлежащий серверу REST, обрабатывающий получение HTTP-запроса и создающий сеанс TensorFlow.
Мы можем увеличить масштаб, чтобы увидеть, что происходит внутри SessionRun.

Во втором потоке мы видим начальный вызов ExecutorState::Process, в котором не выполняются операции TensorFlow, но выполняются шаги инициализации.
В первом потоке мы видим вызов для чтения первой переменной, и как только вторая переменная также станет доступной, мы выполняем умножение и последовательное сложение ядер. Наконец, Executor сигнализирует, что его вычисления завершены, вызывая DoneCallback, и сеанс можно закрыть.
Следующие шаги
Хотя это простой пример, вы можете использовать тот же процесс для профилирования гораздо более сложных моделей, что позволит вам выявлять медленные операции или узкие места в архитектуре вашей модели и повышать ее производительность.
Пожалуйста, обратитесь к Руководству по профилированию TensorBoard для получения более полного руководства по функциям профилировщика TensorBoard и Руководство по производительности обслуживания TensorFlow, чтобы узнать больше об оптимизации производительности вывода.