
Contoh Komponen Utama TensorFlow Extended
 Lihat sumber di GitHub
Lihat sumber di GitHubContoh notebook colab ini menggambarkan bagaimana TensorFlow Data Validation (TFDV) dapat digunakan untuk menyelidiki dan memvisualisasikan kumpulan data Anda. Itu termasuk melihat statistik deskriptif, menyimpulkan skema, memeriksa dan memperbaiki anomali, dan memeriksa penyimpangan dan kemiringan dalam kumpulan data kami. Penting untuk memahami karakteristik set data Anda, termasuk bagaimana hal itu dapat berubah seiring waktu dalam alur produksi Anda. Penting juga untuk mencari anomali dalam data Anda, dan membandingkan set data pelatihan, evaluasi, dan penyajian Anda untuk memastikan bahwa semuanya konsisten.
Kami akan menggunakan data dari kumpulan data Taxi Trips yang dirilis oleh City of Chicago.
Baca lebih lanjut tentang kumpulan data di Google BigQuery . Jelajahi set data lengkap di UI BigQuery .
Kolom dalam kumpulan data adalah:
| pickup_community_area | tarif | trip_start_month |
| trip_start_hour | trip_start_day | trip_start_timestamp |
| pickup_latitude | pickup_longitude | dropoff_latitude |
| dropoff_longitude | trip_miles | pickup_sensus_trak |
| dropoff_sensus_trak | tipe pembayaran | perusahaan |
| perjalanan_detik | dropoff_community_area | tips |
Instal dan impor paket
Instal paket untuk Validasi Data TensorFlow.
Tingkatkan Pip
Untuk menghindari mengupgrade Pip di sistem saat berjalan secara lokal, periksa untuk memastikan bahwa kami berjalan di Colab. Sistem lokal tentu saja dapat ditingkatkan secara terpisah.
try:
import colab
!pip install --upgrade pip
except:
pass
Instal paket Validasi Data
Instal paket dan dependensi Validasi Data TensorFlow, yang membutuhkan waktu beberapa menit. Anda mungkin melihat peringatan dan kesalahan terkait versi ketergantungan yang tidak kompatibel, yang akan Anda atasi di bagian berikutnya.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
Impor TensorFlow dan muat ulang paket yang diperbarui
Langkah sebelumnya memperbarui paket default di lingkungan Gooogle Colab, jadi Anda harus memuat ulang sumber daya paket untuk menyelesaikan dependensi baru.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Periksa versi TensorFlow dan Validasi Data sebelum melanjutkan.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
Muat kumpulan data
Kami akan mengunduh kumpulan data kami dari Google Cloud Storage.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
Hitung dan visualisasikan statistik
Pertama kita akan menggunakan tfdv.generate_statistics_from_csv untuk menghitung statistik untuk data pelatihan kita. (abaikan peringatan tajam)
TFDV dapat menghitung statistik deskriptif yang memberikan gambaran singkat tentang data dalam hal fitur yang ada dan bentuk distribusi nilainya.
Secara internal, TFDV menggunakan kerangka kerja pemrosesan paralel data Apache Beam untuk menskalakan komputasi statistik pada kumpulan data yang besar. Untuk aplikasi yang ingin berintegrasi lebih dalam dengan TFDV (misalnya, melampirkan pembuatan statistik di akhir jalur pembuatan data), API juga menampilkan Beam PTransform untuk pembuatan statistik.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
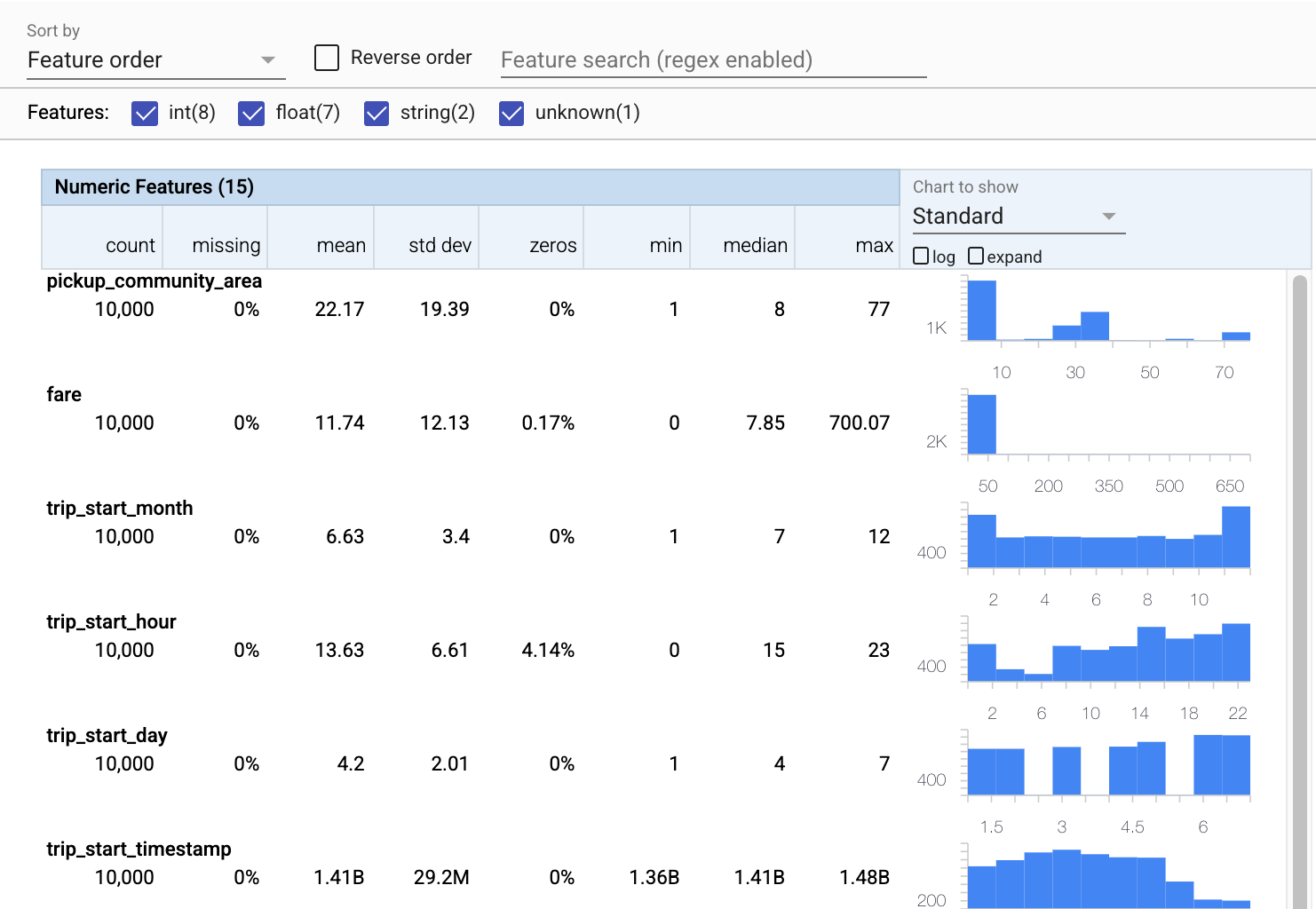
Sekarang mari kita gunakan tfdv.visualize_statistics , yang menggunakan Facets untuk membuat visualisasi ringkas dari data pelatihan kita:
- Perhatikan bahwa fitur numerik dan fitur kategoris divisualisasikan secara terpisah, dan grafik yang ditampilkan menunjukkan distribusi untuk setiap fitur.
- Perhatikan bahwa fitur dengan nilai yang hilang atau nol menampilkan persentase dalam warna merah sebagai indikator visual bahwa mungkin ada masalah dengan contoh dalam fitur tersebut. Persentase adalah persentase contoh yang memiliki nilai yang hilang atau nol untuk fitur tersebut.
- Perhatikan bahwa tidak ada contoh dengan nilai untuk
pickup_census_tract. Ini adalah kesempatan untuk pengurangan dimensi! - Coba klik "luaskan" di atas grafik untuk mengubah tampilan
- Coba arahkan kursor ke batang di bagan untuk menampilkan rentang dan jumlah keranjang
- Coba beralih antara skala log dan linier, dan perhatikan bagaimana skala log mengungkapkan lebih banyak detail tentang fitur kategori
payment_type - Coba pilih "kuantil" dari menu "Bagan untuk ditampilkan", dan arahkan kursor ke penanda untuk menampilkan persentase kuantil
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
Menyimpulkan skema
Sekarang mari kita gunakan tfdv.infer_schema untuk membuat skema untuk data kita. Skema mendefinisikan batasan untuk data yang relevan untuk ML. Contoh kendala termasuk tipe data dari setiap fitur, apakah itu numerik atau kategorikal, atau frekuensi kehadirannya dalam data. Untuk fitur kategoris skema juga mendefinisikan domain - daftar nilai yang dapat diterima. Karena menulis skema bisa menjadi tugas yang membosankan, terutama untuk kumpulan data dengan banyak fitur, TFDV menyediakan metode untuk menghasilkan versi awal skema berdasarkan statistik deskriptif.
Memperbaiki skema itu penting karena sisa jalur produksi kami akan mengandalkan skema yang dihasilkan TFDV agar benar. Skema ini juga menyediakan dokumentasi untuk data, sehingga berguna ketika pengembang yang berbeda mengerjakan data yang sama. Mari kita gunakan tfdv.display_schema untuk menampilkan skema yang disimpulkan sehingga kita dapat meninjaunya.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Periksa data evaluasi untuk kesalahan
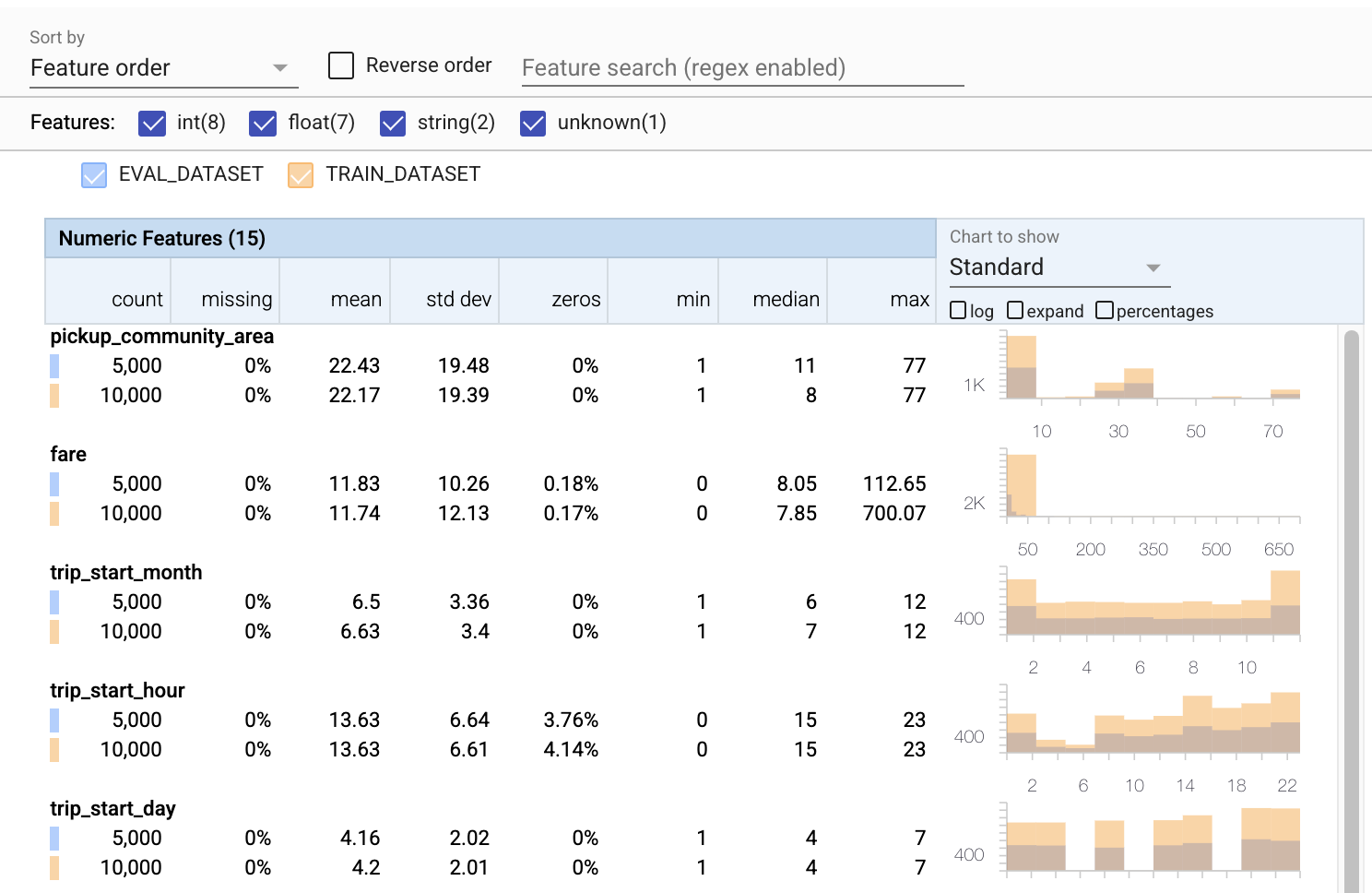
Sejauh ini kami hanya melihat data pelatihan. Penting bahwa data evaluasi kami konsisten dengan data pelatihan kami, termasuk menggunakan skema yang sama. Penting juga bahwa data evaluasi menyertakan contoh kisaran nilai yang kira-kira sama untuk fitur numerik kami sebagai data pelatihan kami, sehingga cakupan permukaan kerugian kami selama evaluasi kira-kira sama dengan selama pelatihan. Hal yang sama berlaku untuk fitur kategoris. Jika tidak, kami mungkin memiliki masalah pelatihan yang tidak teridentifikasi selama evaluasi, karena kami tidak mengevaluasi bagian dari permukaan kerugian kami.
- Perhatikan bahwa setiap fitur sekarang menyertakan statistik untuk set data pelatihan dan evaluasi.
- Perhatikan bahwa bagan sekarang memiliki kumpulan data pelatihan dan evaluasi yang dilapis, sehingga mudah untuk membandingkannya.
- Perhatikan bahwa bagan sekarang menyertakan tampilan persentase, yang dapat digabungkan dengan log atau skala linier default.
- Perhatikan bahwa mean dan median untuk
trip_milesberbeda untuk set data pelatihan versus evaluasi. Apakah itu akan menimbulkan masalah? - Wow,
tipsmaks sangat berbeda untuk pelatihan versus kumpulan data evaluasi. Apakah itu akan menimbulkan masalah? - Klik perluas pada bagan Fitur Numerik, dan pilih skala log. Tinjau fitur
trip_seconds, dan perhatikan perbedaan dalam maks. Akankah evaluasi kehilangan bagian dari permukaan yang hilang?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
Periksa anomali evaluasi
Apakah dataset evaluasi kami cocok dengan skema dari dataset pelatihan kami? Ini sangat penting untuk fitur kategoris, di mana kami ingin mengidentifikasi rentang nilai yang dapat diterima.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
Perbaiki anomali evaluasi dalam skema
Ups! Sepertinya kami memiliki beberapa nilai baru untuk company dalam data evaluasi kami, yang tidak kami miliki dalam data pelatihan kami. Kami juga memiliki nilai baru untuk payment_type . Ini harus dianggap sebagai anomali, tetapi apa yang kami putuskan untuk dilakukan bergantung pada pengetahuan domain kami tentang data. Jika anomali benar-benar menunjukkan kesalahan data, maka data yang mendasarinya harus diperbaiki. Jika tidak, kita cukup memperbarui skema untuk memasukkan nilai dalam set data evaluasi.
Kecuali kami mengubah dataset evaluasi kami, kami tidak dapat memperbaiki semuanya, tetapi kami dapat memperbaiki hal-hal dalam skema yang kami terima dengan nyaman. Itu termasuk melonggarkan pandangan kami tentang apa yang ada dan apa yang bukan anomali untuk fitur tertentu, serta memperbarui skema kami untuk memasukkan nilai yang hilang untuk fitur kategoris. TFDV telah memungkinkan kami menemukan apa yang perlu kami perbaiki.
Mari lakukan perbaikan itu sekarang, lalu tinjau sekali lagi.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
Hei, lihat itu! Kami memverifikasi bahwa data pelatihan dan evaluasi sekarang konsisten! Terima kasih TFDV ;)
Lingkungan Skema
Kami juga memisahkan kumpulan data 'menyajikan' untuk contoh ini, jadi kami juga harus memeriksanya. Secara default, semua set data dalam pipeline harus menggunakan skema yang sama, tetapi sering kali ada pengecualian. Misalnya, dalam pembelajaran terawasi kita perlu memasukkan label dalam kumpulan data kita, tetapi ketika kita menyajikan model untuk inferensi, label tidak akan disertakan. Dalam beberapa kasus memperkenalkan sedikit variasi skema diperlukan.
Lingkungan dapat digunakan untuk mengekspresikan persyaratan tersebut. Secara khusus, fitur dalam skema dapat dikaitkan dengan sekumpulan lingkungan menggunakan default_environment , in_environment dan not_in_environment .
Misalnya, dalam kumpulan data ini, fitur tips disertakan sebagai label untuk pelatihan, tetapi tidak ada dalam data penyajian. Tanpa lingkungan yang ditentukan, itu akan muncul sebagai anomali.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Kami akan menangani fitur tips di bawah ini. Kami juga memiliki nilai INT dalam detik perjalanan kami, di mana skema kami mengharapkan FLOAT. Dengan membuat kami menyadari perbedaan itu, TFDV membantu mengungkap inkonsistensi dalam cara data dihasilkan untuk pelatihan dan penyajian. Sangat mudah untuk tidak menyadari masalah seperti itu sampai kinerja model menurun, terkadang menjadi bencana besar. Ini mungkin atau mungkin bukan masalah yang signifikan, tetapi bagaimanapun juga ini harus menjadi alasan untuk penyelidikan lebih lanjut.
Dalam hal ini, kami dapat dengan aman mengonversi nilai INT ke FLOAT, jadi kami ingin memberi tahu TFDV untuk menggunakan skema kami untuk menyimpulkan tipenya. Ayo lakukan itu sekarang.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Sekarang kami hanya memiliki fitur tips (yang merupakan label kami) yang muncul sebagai anomali ('Kolom dijatuhkan'). Tentu saja kami tidak berharap memiliki label dalam data penyajian kami, jadi mari beri tahu TFDV untuk mengabaikannya.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
Periksa drift dan skew
Selain memeriksa apakah kumpulan data sesuai dengan harapan yang ditetapkan dalam skema, TFDV juga menyediakan fungsionalitas untuk mendeteksi penyimpangan dan kemiringan. TFDV melakukan pemeriksaan ini dengan membandingkan statistik dari kumpulan data yang berbeda berdasarkan pembanding drift/skew yang ditentukan dalam skema.
Melayang
Deteksi drift didukung untuk fitur kategorikal dan antara rentang data berurutan (yaitu, antara rentang N dan rentang N+1), seperti antara hari data pelatihan yang berbeda. Kami menyatakan drift dalam hal jarak L-infinity , dan Anda dapat mengatur jarak ambang sehingga Anda menerima peringatan saat drift lebih tinggi dari yang dapat diterima. Mengatur jarak yang benar biasanya merupakan proses berulang yang membutuhkan pengetahuan domain dan eksperimen.
Condong
TFDV dapat mendeteksi tiga jenis skew yang berbeda dalam data Anda - skew skema, skew fitur, dan skew distribusi.
Skema Skew
Skema skew terjadi ketika data pelatihan dan penyajian tidak sesuai dengan skema yang sama. Baik data pelatihan maupun penyajian diharapkan mengikuti skema yang sama. Setiap penyimpangan yang diharapkan antara keduanya (seperti fitur label yang hanya ada dalam data pelatihan tetapi tidak dalam penyajian) harus ditentukan melalui bidang lingkungan dalam skema.
Fitur Kemiringan
Kemiringan fitur terjadi saat nilai fitur yang dilatih model berbeda dari nilai fitur yang dilihatnya pada waktu penayangan. Misalnya, ini dapat terjadi ketika:
- Sumber data yang menyediakan beberapa nilai fitur dimodifikasi antara waktu pelatihan dan penayangan
- Ada logika yang berbeda untuk menghasilkan fitur antara pelatihan dan penyajian. Misalnya, jika Anda menerapkan beberapa transformasi hanya di salah satu dari dua jalur kode.
Distribusi Kemiringan
Kemiringan distribusi terjadi ketika distribusi set data pelatihan berbeda secara signifikan dari distribusi set data penyajian. Salah satu penyebab utama kecondongan distribusi adalah menggunakan kode yang berbeda atau sumber data yang berbeda untuk menghasilkan set data pelatihan. Alasan lainnya adalah mekanisme pengambilan sampel yang salah yang memilih subsampel non-representatif dari data penyajian untuk dilatih.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
Dalam contoh ini kita memang melihat beberapa penyimpangan, tetapi jauh di bawah ambang batas yang telah kita tetapkan.
Bekukan skema
Sekarang skema telah ditinjau dan dikuratori, kami akan menyimpannya dalam file untuk mencerminkan status "beku".
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
Kapan menggunakan TFDV
Sangat mudah untuk menganggap TFDV hanya berlaku untuk awal jalur pelatihan Anda, seperti yang kami lakukan di sini, tetapi sebenarnya ini memiliki banyak kegunaan. Berikut beberapa lagi:
- Memvalidasi data baru untuk inferensi guna memastikan bahwa kami tidak tiba-tiba mulai menerima fitur yang buruk
- Memvalidasi data baru untuk inferensi guna memastikan bahwa model kami telah dilatih pada bagian permukaan keputusan itu
- Memvalidasi data kami setelah kami mengubahnya dan melakukan rekayasa fitur (mungkin menggunakan TensorFlow Transform ) untuk memastikan kami tidak melakukan kesalahan