
Ce didacticiel vous montre comment utiliser TensorFlow Transform (la bibliothèque tf.Transform ) pour implémenter le prétraitement des données pour l'apprentissage automatique (ML). La bibliothèque tf.Transform pour TensorFlow vous permet de définir des transformations de données au niveau de l'instance et en passe complète via des pipelines de prétraitement des données. Ces pipelines sont exécutés efficacement avec Apache Beam et créent comme sous-produits un graphique TensorFlow pour appliquer les mêmes transformations lors de la prédiction que lorsque le modèle est servi.
Ce didacticiel fournit un exemple de bout en bout utilisant Dataflow comme exécuteur pour Apache Beam. Cela suppose que vous connaissez BigQuery , Dataflow, Vertex AI et l'API TensorFlow Keras . Cela suppose également que vous ayez une certaine expérience de l'utilisation des notebooks Jupyter, par exemple avec Vertex AI Workbench .
Ce didacticiel suppose également que vous connaissez les concepts de types, de défis et d'options de prétraitement sur Google Cloud, comme décrit dans Prétraitement des données pour le ML : options et recommandations .
Objectifs
- Implémentez le pipeline Apache Beam à l'aide de la bibliothèque
tf.Transform. - Exécutez le pipeline dans Dataflow.
- Implémentez le modèle TensorFlow à l'aide de la bibliothèque
tf.Transform. - Entraînez-vous et utilisez le modèle pour les prédictions.
Frais
Ce tutoriel utilise les composants facturables suivants de Google Cloud :
Pour estimer le coût d'exécution de ce didacticiel, en supposant que vous utilisez chaque ressource pendant une journée entière, utilisez le calculateur de prix préconfiguré.
Avant de commencer
Dans la console Google Cloud, sur la page de sélection de projet, sélectionnez ou créez un projet Google Cloud .
Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet .
Activez les API Dataflow, Vertex AI et Notebooks. Activer les API
Carnets Jupyter pour cette solution
Les notebooks Jupyter suivants montrent l'exemple d'implémentation :
- Le cahier 1 couvre le prétraitement des données. Les détails sont fournis plus loin dans la section Implémentation du pipeline Apache Beam .
- Le cahier 2 couvre la formation des modèles. Les détails sont fournis plus loin dans la section Implémentation du modèle TensorFlow .
Dans les sections suivantes, vous clonez ces notebooks, puis vous les exécutez pour découvrir le fonctionnement de l’exemple d’implémentation.
Lancer une instance de notebooks gérés par l'utilisateur
Dans la console Google Cloud, accédez à la page Vertex AI Workbench .
Sous l'onglet Bloc-notes gérés par l'utilisateur , cliquez sur +Nouveau bloc-notes .
Sélectionnez TensorFlow Enterprise 2.8 (avec LTS) sans GPU pour le type d'instance.
Cliquez sur Créer .
Après avoir créé le notebook, attendez que le proxy de JupyterLab termine son initialisation. Lorsqu'il est prêt, Open JupyterLab s'affiche à côté du nom du notebook.
Cloner le bloc-notes
Dans l' onglet Bloc-notes gérés par l'utilisateur , à côté du nom du bloc-notes, cliquez sur Ouvrir JupyterLab . L'interface JupyterLab s'ouvre dans un nouvel onglet.
Si JupyterLab affiche une boîte de dialogue Build Recommendation , cliquez sur Cancel pour rejeter la build suggérée.
Dans l'onglet Lanceur , cliquez sur Terminal .
Dans la fenêtre du terminal, clonez le notebook :
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
Implémenter le pipeline Apache Beam
Cette section et la section suivante Exécuter le pipeline dans Dataflow fournissent une présentation et le contexte du notebook 1. Le notebook fournit un exemple pratique pour décrire comment utiliser la bibliothèque tf.Transform pour prétraiter les données. Cet exemple utilise l'ensemble de données Natality, qui est utilisé pour prédire le poids des bébés en fonction de diverses entrées. Les données sont stockées dans la table de natalité publique de BigQuery.
Exécuter le bloc-notes 1
Dans l'interface JupyterLab, cliquez sur Fichier > Ouvrir à partir du chemin , puis saisissez le chemin suivant :
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbCliquez sur Modifier > Effacer toutes les sorties .
Dans la section Installer les packages requis , exécutez la première cellule pour exécuter la commande
pip install apache-beam.La dernière partie du résultat est la suivante :
Successfully installed ...Vous pouvez ignorer les erreurs de dépendance dans la sortie. Vous n'avez pas encore besoin de redémarrer le noyau.
Exécutez la deuxième cellule pour exécuter la commande
pip install tensorflow-transform. La dernière partie du résultat est la suivante :Successfully installed ... Note: you may need to restart the kernel to use updated packages.Vous pouvez ignorer les erreurs de dépendance dans la sortie.
Cliquez sur Kernel > Redémarrer le noyau .
Exécutez les cellules des sections Confirmer les packages installés et Créer setup.py pour installer les packages dans les conteneurs Dataflow .
Dans la section Définir les indicateurs globaux , à côté de
PROJECTetBUCKET, remplacezyour-projectpar votre ID de projet Cloud, puis exécutez la cellule.Exécutez toutes les cellules restantes via la dernière cellule du bloc-notes. Pour plus d’informations sur les actions à effectuer dans chaque cellule, consultez les instructions du bloc-notes.
Aperçu du pipeline
Dans l'exemple de notebook, Dataflow exécute le pipeline tf.Transform à grande échelle pour préparer les données et produire les artefacts de transformation. Les sections suivantes de ce document décrivent les fonctions qui exécutent chaque étape du pipeline. Les étapes globales du pipeline sont les suivantes :
- Lisez les données d'entraînement de BigQuery.
- Analysez et transformez les données d'entraînement à l'aide de la bibliothèque
tf.Transform. - Écrivez les données d'entraînement transformées dans Cloud Storage au format TFRecord .
- Lisez les données d'évaluation de BigQuery.
- Transformez les données d'évaluation à l'aide du graphique
transform_fnproduit à l'étape 2. - Écrivez les données d'entraînement transformées dans Cloud Storage au format TFRecord.
- Écrivez des artefacts de transformation dans Cloud Storage qui seront utilisés ultérieurement pour créer et exporter le modèle.
L'exemple suivant montre le code Python pour le pipeline global. Les sections qui suivent fournissent des explications et des listes de codes pour chaque étape.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
Lire les données d'entraînement brutes de BigQuery
La première étape consiste à lire les données brutes d'entraînement de BigQuery à l'aide de la fonction read_from_bq . Cette fonction renvoie un objet raw_dataset extrait de BigQuery. Vous transmettez une valeur data_size et transmettez une valeur de step de train ou eval . La requête source BigQuery est construite à l'aide de la fonction get_source_query , comme illustré dans l'exemple suivant :
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
Avant d'effectuer le prétraitement tf.Transform , vous devrez peut-être effectuer un traitement typique basé sur Apache Beam, notamment le traitement de carte, de filtre, de groupe et de fenêtre. Dans l'exemple, le code nettoie les enregistrements lus dans BigQuery à l'aide de la méthode beam.Map(prep_bq_row) , où prep_bq_row est une fonction personnalisée. Cette fonction personnalisée convertit le code numérique d'une caractéristique catégorielle en étiquettes lisibles par l'homme.
De plus, pour utiliser la bibliothèque tf.Transform pour analyser et transformer l'objet raw_data extrait de BigQuery, vous devez créer un objet raw_dataset , qui est un tuple d'objets raw_data et raw_metadata . L'objet raw_metadata est créé à l'aide de la fonction create_raw_metadata , comme suit :
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
Lorsque vous exécutez la cellule du notebook qui suit immédiatement la cellule qui définit cette méthode, le contenu de l'objet raw_metadata.schema s'affiche. Il comprend les colonnes suivantes :
-
gestation_weeks(type :FLOAT) -
is_male(tapez :BYTES) -
mother_age(type :FLOAT) -
mother_race(tapez :BYTES) -
plurality(type :FLOAT) -
weight_pounds(type :FLOAT)
Transformez les données d'entraînement brutes
Imaginez que vous souhaitiez appliquer des transformations de prétraitement typiques aux caractéristiques brutes d'entrée des données d'entraînement afin de les préparer au ML. Ces transformations incluent à la fois des opérations complètes et au niveau de l'instance, comme indiqué dans le tableau suivant :
| Fonctionnalité d'entrée | Transformation | Statistiques nécessaires | Taper | Fonctionnalité de sortie |
|---|---|---|---|---|
weight_pound | Aucun | Aucun | N / A | weight_pound |
mother_age | Normaliser | signifier, var | Pass complet | mother_age_normalized |
mother_age | Compartiment de taille égale | quantile | Pass complet | mother_age_bucketized |
mother_age | Calculer le journal | Aucun | Au niveau de l'instance | mother_age_log |
plurality | Indiquez s'il s'agit d'un seul ou de plusieurs bébés | Aucun | Au niveau de l'instance | is_multiple |
is_multiple | Convertir les valeurs nominales en index numérique | vocabulaire | Pass complet | is_multiple_index |
gestation_weeks | Échelle entre 0 et 1 | minimum, maximum | Pass complet | gestation_weeks_scaled |
mother_race | Convertir les valeurs nominales en index numérique | vocabulaire | Pass complet | mother_race_index |
is_male | Convertir les valeurs nominales en index numérique | vocabulaire | Pass complet | is_male_index |
Ces transformations sont implémentées dans une fonction preprocess_fn , qui attend un dictionnaire de tenseurs ( input_features ) et renvoie un dictionnaire de fonctionnalités traitées ( output_features ).
Le code suivant montre l'implémentation de la fonction preprocess_fn , à l'aide des API de transformation passe complète tf.Transform (préfixées par tft. ) et TensorFlow (préfixées par tf. ) au niveau de l'instance :
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
Le framework tf.Transform comporte plusieurs autres transformations en plus de celles de l'exemple précédent, notamment celles répertoriées dans le tableau suivant :
| Transformation | S'applique à | Description |
|---|---|---|
scale_by_min_max | Fonctionnalités numériques | Met à l'échelle une colonne numérique dans la plage [ output_min , output_max ] |
scale_to_0_1 | Fonctionnalités numériques | Renvoie une colonne qui est la colonne d'entrée mise à l'échelle pour avoir une plage [ 0 , 1 ] |
scale_to_z_score | Fonctionnalités numériques | Renvoie une colonne standardisée avec une moyenne de 0 et une variance de 1 |
tfidf | Caractéristiques du texte | Mappe les termes dans x à leur fréquence de terme * fréquence inverse du document |
compute_and_apply_vocabulary | Caractéristiques catégorielles | Génère un vocabulaire pour une caractéristique catégorielle et le mappe à un entier avec ce vocabulaire |
ngrams | Caractéristiques du texte | Crée un SparseTensor de n-grammes |
hash_strings | Caractéristiques catégorielles | Hache les chaînes dans des compartiments |
pca | Fonctionnalités numériques | Calcule la PCA sur l'ensemble de données en utilisant une covariance biaisée |
bucketize | Fonctionnalités numériques | Renvoie une colonne compartimentée de taille égale (basée sur des quantiles), avec un index de compartiment attribué à chaque entrée |
Afin d'appliquer les transformations implémentées dans la fonction preprocess_fn à l'objet raw_train_dataset produit à l'étape précédente du pipeline, vous utilisez la méthode AnalyzeAndTransformDataset . Cette méthode attend l'objet raw_dataset en entrée, applique la fonction preprocess_fn et produit l'objet transformed_dataset et le graphique transform_fn . Le code suivant illustre ce traitement :
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
Les transformations sont appliquées sur les données brutes en deux phases : la phase d'analyse et la phase de transformation. La figure 3 plus loin dans ce document montre comment la méthode AnalyzeAndTransformDataset est décomposée en méthode AnalyzeDataset et en méthode TransformDataset .
La phase d'analyse
Lors de la phase d'analyse, les données brutes d'entraînement sont analysées dans le cadre d'un processus complet pour calculer les statistiques nécessaires aux transformations. Cela inclut le calcul de la moyenne, de la variance, du minimum, du maximum, des quantiles et du vocabulaire. Le processus d'analyse attend un ensemble de données brutes (données brutes plus métadonnées brutes) et produit deux sorties :
-
transform_fn: un graphique TensorFlow qui contient les statistiques calculées à partir de la phase d'analyse et la logique de transformation (qui utilise les statistiques) en tant qu'opérations au niveau de l'instance. Comme indiqué plus loin dans Enregistrer le graphique , le graphiquetransform_fnest enregistré pour être attaché à la fonction modelserving_fn. Cela permet d'appliquer la même transformation aux points de données de prédiction en ligne. -
transform_metadata: un objet qui décrit le schéma attendu des données après transformation.
La phase d'analyse est illustrée dans le schéma suivant, figure 1 :

tf.Transform . Les analyseurs tf.Transform incluent min , max , sum , size , mean , var , covariance , quantiles , vocabulary et pca .
La phase de transformation
Dans la phase de transformation, le graphique transform_fn produit par la phase d'analyse est utilisé pour transformer les données d'entraînement brutes dans un processus au niveau de l'instance afin de produire les données d'entraînement transformées. Les données d'entraînement transformées sont associées aux métadonnées transformées (produites par la phase d'analyse) pour produire l'ensemble de données transformed_train_dataset .
La phase de transformation est illustrée dans le schéma suivant, figure 2 :

tf.Transform . Pour prétraiter les fonctionnalités, vous appelez les transformations tensorflow_transform requises (importées au format tft dans le code) dans votre implémentation de la fonction preprocess_fn . Par exemple, lorsque vous appelez les opérations tft.scale_to_z_score , la bibliothèque tf.Transform traduit cet appel de fonction en analyseurs de moyenne et de variance, calcule les statistiques dans la phase d'analyse, puis applique ces statistiques pour normaliser la caractéristique numérique dans la phase de transformation. Tout cela se fait automatiquement en appelant la méthode AnalyzeAndTransformDataset(preprocess_fn) .
L'entité transformed_metadata.schema produite par cet appel comprend les colonnes suivantes :
-
gestation_weeks_scaled(type :FLOAT) -
is_male_index(type :INT, is_categorical :True) -
is_multiple_index(type :INT, is_categorical :True) -
mother_age_bucketized(type :INT, is_categorical :True) -
mother_age_log(tapez :FLOAT) -
mother_age_normalized(type :FLOAT) -
mother_race_index(type :INT, is_categorical :True) -
weight_pounds(type :FLOAT)
Comme expliqué dans Opérations de prétraitement dans la première partie de cette série, la transformation de caractéristiques convertit les caractéristiques catégorielles en représentation numérique. Après la transformation, les caractéristiques catégorielles sont représentées par des valeurs entières. Dans l'entité transformed_metadata.schema , l'indicateur is_categorical pour les colonnes de type INT indique si la colonne représente une fonctionnalité catégorielle ou une véritable fonctionnalité numérique.
Écrire des données d'entraînement transformées
Une fois les données d'entraînement prétraitées avec la fonction preprocess_fn via les phases d'analyse et de transformation, vous pouvez écrire les données dans un récepteur à utiliser pour entraîner le modèle TensorFlow. Lorsque vous exécutez le pipeline Apache Beam à l'aide de Dataflow, le récepteur est Cloud Storage. Sinon, le récepteur est le disque local. Bien que vous puissiez écrire les données sous forme de fichier CSV composé de fichiers au format de largeur fixe, le format de fichier recommandé pour les ensembles de données TensorFlow est le format TFRecord. Il s'agit d'un format binaire simple orienté enregistrement qui se compose de messages de tampon de protocole tf.train.Example .
Chaque enregistrement tf.train.Example contient une ou plusieurs fonctionnalités. Ceux-ci sont convertis en tenseurs lorsqu'ils sont transmis au modèle pour l'entraînement. Le code suivant écrit l'ensemble de données transformé dans les fichiers TFRecord à l'emplacement spécifié :
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
Lire, transformer et écrire des données d'évaluation
Après avoir transformé les données d'entraînement et produit le graphique transform_fn , vous pouvez l'utiliser pour transformer les données d'évaluation. Tout d'abord, vous lisez et nettoyez les données d'évaluation de BigQuery à l'aide de la fonction read_from_bq décrite précédemment dans Lire les données d'entraînement brutes de BigQuery et en transmettant une valeur eval pour le paramètre step . Ensuite, vous utilisez le code suivant pour transformer l'ensemble de données d'évaluation brute ( raw_dataset ) au format transformé attendu ( transformed_dataset ) :
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
Lorsque vous transformez les données d'évaluation, seules les opérations au niveau de l'instance s'appliquent, en utilisant à la fois la logique du graphique transform_fn et les statistiques calculées à partir de la phase d'analyse dans les données d'entraînement. En d’autres termes, vous n’analysez pas les données d’évaluation de manière complète pour calculer de nouvelles statistiques, comme la moyenne et la variance pour la normalisation du score z des caractéristiques numériques dans les données d’évaluation. Au lieu de cela, vous utilisez les statistiques calculées à partir des données d’entraînement pour transformer les données d’évaluation au niveau de l’instance.
Par conséquent, vous utilisez la méthode AnalyzeAndTransform dans le contexte des données d’entraînement pour calculer les statistiques et transformer les données. Parallèlement, vous utilisez la méthode TransformDataset dans le contexte de la transformation des données d'évaluation pour transformer les données uniquement à l'aide des statistiques calculées sur les données d'entraînement.
Vous écrivez ensuite les données sur un récepteur (Cloud Storage ou disque local, selon l'exécuteur) au format TFRecord pour évaluer le modèle TensorFlow pendant le processus de formation. Pour ce faire, vous utilisez la fonction write_tfrecords décrite dans Écrire des données d'entraînement transformées . Le diagramme suivant, figure 3, montre comment le graphique transform_fn produit lors de la phase d'analyse des données d'entraînement est utilisé pour transformer les données d'évaluation.

transform_fn .Enregistrez le graphique
Une dernière étape du pipeline de prétraitement tf.Transform consiste à stocker les artefacts, qui incluent le graphique transform_fn produit par la phase d'analyse sur les données d'entraînement. Le code de stockage des artefacts est affiché dans la fonction write_transform_artefacts suivante :
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
Ces artefacts seront utilisés ultérieurement pour la formation du modèle et l'exportation pour la diffusion. Les artefacts suivants sont également produits, comme le montre la section suivante :
-
saved_model.pb: représente le graphe TensorFlow qui inclut la logique de transformation (le graphetransform_fn), qui doit être attaché à l'interface de service de modèle pour transformer les points de données brutes au format transformé. -
variables: inclut les statistiques calculées lors de la phase d'analyse des données d'entraînement et est utilisée dans la logique de transformation dans l'artefactsaved_model.pb. -
assets: comprend des fichiers de vocabulaire, un pour chaque caractéristique catégorielle traitée avec la méthodecompute_and_apply_vocabulary, à utiliser lors de la diffusion pour convertir une valeur nominale brute d'entrée en un index numérique. -
transformed_metadata: un répertoire qui contient le fichierschema.jsonqui décrit le schéma des données transformées.
Exécuter le pipeline dans Dataflow
Après avoir défini le pipeline tf.Transform , vous exécutez le pipeline à l'aide de Dataflow. Le diagramme suivant, figure 4, montre le graphique d'exécution Dataflow du pipeline tf.Transform décrit dans l'exemple.
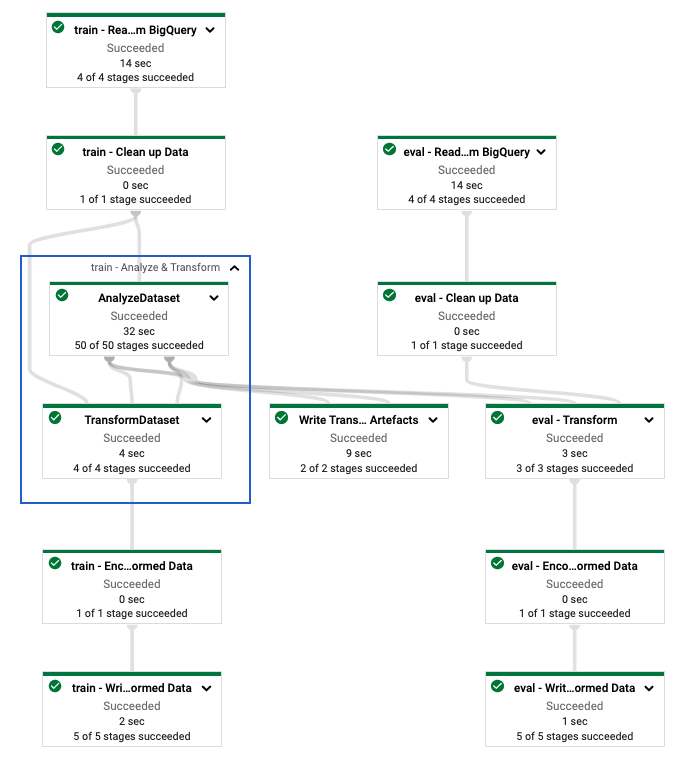
tf.Transform . Après avoir exécuté le pipeline Dataflow pour prétraiter les données d'entraînement et d'évaluation, vous pouvez explorer les objets produits dans Cloud Storage en exécutant la dernière cellule du notebook. Les extraits de code de cette section affichent les résultats, où YOUR_BUCKET_NAME est le nom de votre bucket Cloud Storage.
Les données de formation et d'évaluation transformées au format TFRecord sont stockées à l'emplacement suivant :
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
Les artefacts de transformation sont produits à l'emplacement suivant :
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
La liste suivante est la sortie du pipeline, montrant les objets de données et les artefacts produits :
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
Implémenter le modèle TensorFlow
Cette section et la section suivante, Entraîner et utiliser le modèle pour les prédictions , fournissent une présentation et un contexte pour le cahier 2. Le cahier fournit un exemple de modèle ML pour prédire le poids des bébés. Dans cet exemple, un modèle TensorFlow est implémenté à l'aide de l'API Keras. Le modèle utilise les données et les artefacts produits par le pipeline de prétraitement tf.Transform expliqué précédemment.
Exécuter le bloc-notes 2
Dans l'interface JupyterLab, cliquez sur Fichier > Ouvrir à partir du chemin , puis saisissez le chemin suivant :
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbCliquez sur Modifier > Effacer toutes les sorties .
Dans la section Installer les packages requis , exécutez la première cellule pour exécuter la commande
pip install tensorflow-transform.La dernière partie du résultat est la suivante :
Successfully installed ... Note: you may need to restart the kernel to use updated packages.Vous pouvez ignorer les erreurs de dépendance dans la sortie.
Dans le menu Kernel , sélectionnez Redémarrer le noyau .
Exécutez les cellules des sections Confirmer les packages installés et Créer setup.py pour installer les packages dans les conteneurs Dataflow .
Dans la section Définir les indicateurs globaux , à côté de
PROJECTetBUCKET, remplacezyour-projectpar votre ID de projet Cloud, puis exécutez la cellule.Exécutez toutes les cellules restantes via la dernière cellule du bloc-notes. Pour plus d’informations sur les actions à effectuer dans chaque cellule, consultez les instructions du bloc-notes.
Aperçu de la création du modèle
Les étapes de création du modèle sont les suivantes :
- Créez des colonnes de fonctionnalités à l'aide des informations de schéma stockées dans le répertoire
transformed_metadata. - Créez le modèle large et profond avec l'API Keras en utilisant les colonnes de fonctionnalités comme entrée du modèle.
- Créez la fonction
tfrecords_input_fnpour lire et analyser les données de formation et d'évaluation à l'aide des artefacts de transformation. - Former et évaluer le modèle.
- Exportez le modèle entraîné en définissant une fonction
serving_fnà laquelle est attaché le graphiquetransform_fn. - Inspectez le modèle exporté à l'aide de l'outil
saved_model_cli. - Utilisez le modèle exporté pour la prédiction.
Ce document n'explique pas comment créer le modèle, il n'explique donc pas en détail comment le modèle a été construit ou entraîné. Cependant, les sections suivantes montrent comment les informations stockées dans le répertoire transform_metadata , produit par le processus tf.Transform , sont utilisées pour créer les colonnes de fonctionnalités du modèle. Le document montre également comment le graphique transform_fn , également produit par le processus tf.Transform , est utilisé dans la fonction serving_fn lorsque le modèle est exporté pour être servi.
Utiliser les artefacts de transformation générés dans la formation du modèle
Lorsque vous entraînez le modèle TensorFlow, vous utilisez les objets train et eval transformés produits lors de l'étape de traitement des données précédente. Ces objets sont stockés sous forme de fichiers fragmentés au format TFRecord. Les informations de schéma dans le répertoire transformed_metadata générées à l'étape précédente peuvent être utiles pour analyser les données (objets tf.train.Example ) afin d'alimenter le modèle pour la formation et l'évaluation.
Analyser les données
Étant donné que vous lisez des fichiers au format TFRecord pour alimenter le modèle avec des données de formation et d'évaluation, vous devez analyser chaque objet tf.train.Example dans les fichiers pour créer un dictionnaire de fonctionnalités (tenseurs). Cela garantit que les fonctionnalités sont mappées à la couche d'entrée du modèle à l'aide des colonnes de fonctionnalités, qui servent d'interface de formation et d'évaluation du modèle. Pour analyser les données, vous utilisez l'objet TFTransformOutput créé à partir des artefacts générés à l'étape précédente :
Créez un objet
TFTransformOutputà partir des artefacts générés et enregistrés lors de l'étape de prétraitement précédente, comme décrit dans la section Enregistrer le graphique :tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Extrayez un objet
feature_specde l'objetTFTransformOutput:tf_transform_output.transformed_feature_spec()Utilisez l'objet
feature_specpour spécifier les fonctionnalités contenues dans l'objettf.train.Examplecomme dans la fonctiontfrecords_input_fn:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
Créer les colonnes de fonctionnalités
Le pipeline produit les informations de schéma dans le répertoire transformed_metadata qui décrit le schéma des données transformées attendues par le modèle pour la formation et l'évaluation. Le schéma contient le nom de la fonctionnalité et le type de données, tels que les suivants :
-
gestation_weeks_scaled(type :FLOAT) -
is_male_index(type :INT, is_categorical :True) -
is_multiple_index(type :INT, is_categorical :True) -
mother_age_bucketized(type :INT, is_categorical :True) -
mother_age_log(type :FLOAT) -
mother_age_normalized(type :FLOAT) -
mother_race_index(type :INT, is_categorical :True) -
weight_pounds(type :FLOAT)
Pour voir ces informations, utilisez les commandes suivantes :
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
Le code suivant montre comment utiliser le nom de fonctionnalité pour créer des colonnes de fonctionnalités :
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
Le code crée une colonne tf.feature_column.numeric_column pour les fonctionnalités numériques et une colonne tf.feature_column.categorical_column_with_identity pour les fonctionnalités catégorielles.
Vous pouvez également créer des colonnes de fonctionnalités étendues, comme décrit dans Option C : TensorFlow dans la première partie de cette série. Dans l'exemple utilisé pour cette série, une nouvelle fonctionnalité est créée, mother_race_X_mother_age_bucketized , en croisant les fonctionnalités mother_race et mother_age_bucketized à l'aide de la colonne de fonctionnalités tf.feature_column.crossed_column . Une représentation dense et de faible dimension de cette fonctionnalité croisée est créée à l'aide de la colonne de fonctionnalités tf.feature_column.embedding_column .
Le diagramme suivant, figure 5, montre les données transformées et comment les métadonnées transformées sont utilisées pour définir et entraîner le modèle TensorFlow :

Exporter le modèle pour diffuser la prédiction
Après avoir entraîné le modèle TensorFlow avec l'API Keras, vous exportez le modèle entraîné en tant qu'objet SavedModel, afin qu'il puisse servir de nouveaux points de données à des fins de prédiction. Lorsque vous exportez le modèle, vous devez définir son interface, c'est-à-dire le schéma des fonctionnalités d'entrée attendu lors de la diffusion. Ce schéma de fonctionnalités d'entrée est défini dans la fonction serving_fn , comme indiqué dans le code suivant :
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
Lors de la diffusion, le modèle attend les points de données sous leur forme brute (c'est-à-dire les caractéristiques brutes avant les transformations). Par conséquent, la fonction serving_fn reçoit les fonctionnalités brutes et les stocke dans un objet features en tant que dictionnaire Python. Cependant, comme indiqué précédemment, le modèle entraîné attend les points de données dans le schéma transformé. Pour convertir les fonctionnalités brutes en objets transformed_features attendus par l'interface du modèle, vous appliquez le graphique transform_fn enregistré à l'objet features en procédant comme suit :
Créez l'objet
TFTransformOutputà partir des artefacts générés et enregistrés lors de l'étape de prétraitement précédente :tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Créez un objet
TransformFeaturesLayerà partir de l'objetTFTransformOutput:model.tft_layer = tf_transform_output.transform_features_layer()Appliquez le graphique
transform_fnà l'aide de l'objetTransformFeaturesLayer:transformed_features = model.tft_layer(features)
Le diagramme suivant, figure 6, illustre la dernière étape de l'exportation d'un modèle à des fins de diffusion :

transform_fn joint. Entraîner et utiliser le modèle pour les prédictions
Vous pouvez entraîner le modèle localement en exécutant les cellules du notebook. Pour obtenir des exemples sur la manière de regrouper le code et d'entraîner votre modèle à grande échelle à l'aide de Vertex AI Training, consultez les exemples et les guides dans le dépôt GitHub de Google Cloud cloudml-samples .
Lorsque vous inspectez l'objet SavedModel exporté à l'aide de l'outil saved_model_cli , vous constatez que les éléments inputs de la définition de signature signature_def incluent les fonctionnalités brutes, comme indiqué dans l'exemple suivant :
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
Les cellules restantes du notebook vous montrent comment utiliser le modèle exporté pour une prédiction locale et comment déployer le modèle en tant que microservice à l'aide de Vertex AI Prediction. Il est important de souligner que le point de données d’entrée (échantillon) se trouve dans le schéma brut dans les deux cas.
Nettoyer
Pour éviter d'encourir des frais supplémentaires sur votre compte Google Cloud pour les ressources utilisées dans ce didacticiel, supprimez le projet qui contient les ressources.
Supprimer le projet
Dans la console Google Cloud, accédez à la page Gérer les ressources .
Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer .
Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Quelle est la prochaine étape
- Pour en savoir plus sur les concepts, les défis et les options du prétraitement des données pour le machine learning sur Google Cloud, consultez le premier article de cette série, Prétraitement des données pour le ML : options et recommandations .
- Pour plus d'informations sur la façon d'implémenter, de packager et d'exécuter un pipeline tf.Transform sur Dataflow, consultez l'exemple Prédire les revenus avec un ensemble de données de recensement .
- Suivez la spécialisation Coursera sur le ML avec TensorFlow sur Google Cloud .
- Découvrez les meilleures pratiques en matière d'ingénierie ML dans Rules of ML .
- Pour plus d'architectures de référence, de diagrammes et de bonnes pratiques, explorez le Cloud Architecture Center .