
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Przegląd
Układy GPU i TPU mogą radykalnie skrócić czas potrzebny na wykonanie pojedynczego etapu uczenia. Osiągnięcie szczytowej wydajności wymaga wydajnego potoku wejściowego, który dostarcza dane do następnego kroku przed zakończeniem bieżącego kroku. Interfejs API tf.data pomaga w budowaniu elastycznych i wydajnych potoków wejściowych. W tym dokumencie pokazano, jak używać interfejsu API tf.data do tworzenia wysoce wydajnych potoków wejściowych TensorFlow.
Zanim przejdziesz dalej, zapoznaj się z przewodnikiem kompilowania potoków wejściowych TensorFlow, aby dowiedzieć się, jak korzystać z interfejsu API tf.data .
Zasoby
- Zbuduj potoki wejściowe TensorFlow
-
tf.data.DatasetAPI - Analizuj wydajność
tf.dataza pomocą TF Profiler
Ustawiać
import tensorflow as tf
import time
W tym przewodniku będziesz iterować po zbiorze danych i mierzyć wydajność. Tworzenie powtarzalnych testów wydajności może być trudne. Różne czynniki wpływające na odtwarzalność obejmują:
- Aktualne obciążenie procesora
- Ruch sieciowy
- Złożone mechanizmy, takie jak pamięć podręczna
Aby uzyskać powtarzalny test porównawczy, zbudujesz sztuczny przykład.
Zbiór danych
Zacznij od zdefiniowania klasy dziedziczącej z tf.data.Dataset o nazwie ArtificialDataset . Ten zbiór danych:
- Generuje próbki
num_samples(domyślnie 3) - Uśpiony przez jakiś czas przed pierwszym elementem, aby zasymulować otwarcie pliku
- Uśpiony przez pewien czas przed wyprodukowaniem każdego elementu w celu symulacji odczytu danych z pliku
class ArtificialDataset(tf.data.Dataset):
def _generator(num_samples):
# Opening the file
time.sleep(0.03)
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
time.sleep(0.015)
yield (sample_idx,)
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_signature = tf.TensorSpec(shape = (1,), dtype = tf.int64),
args=(num_samples,)
)
Ten zestaw danych jest podobny do zestawu tf.data.Dataset.range , dodając stałe opóźnienie na początku i pomiędzy każdą próbką.
Pętla treningowa
Następnie napisz fikcyjną pętlę treningową, która mierzy, ile czasu zajmuje iteracja zestawu danych. Symulowany jest czas treningu.
def benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
for sample in dataset:
# Performing a training step
time.sleep(0.01)
print("Execution time:", time.perf_counter() - start_time)
Optymalizacja wydajności
Aby pokazać, jak można zoptymalizować wydajność, poprawisz wydajność ArtificialDataset .
Naiwne podejście
Zacznij od naiwnego potoku bez żadnych sztuczek, iterując po zbiorze danych bez zmian.
benchmark(ArtificialDataset())
Execution time: 0.26497629899995445
Pod maską tak spędziliśmy czas egzekucji:

Z wykresu wynika, że wykonanie etapu treningu obejmuje:
- Otwieranie pliku, jeśli nie został jeszcze otwarty
- Pobieranie wpisu danych z pliku
- Wykorzystanie danych do treningu
Jednak w naiwnej implementacji synchronicznej, takiej jak tutaj, podczas gdy potok pobiera dane, model jest bezczynny. I odwrotnie, podczas gdy Twój model jest trenowany, potok wejściowy jest bezczynny. Czas kroku treningowego jest więc sumą czasów otwierania, czytania i treningu.
Następne sekcje opierają się na tym potoku wejściowym, ilustrując najlepsze praktyki projektowania wydajnych potoków wejściowych TensorFlow.
Pobieranie z wyprzedzeniem
Pobieranie wstępne nakłada się na przetwarzanie wstępne i wykonanie modelu etapu uczenia. Podczas gdy model wykonuje kroki uczenia s , potok wejściowy odczytuje dane dla kroku s+1 . Spowoduje to skrócenie czasu kroku do maksimum (w przeciwieństwie do sumy) szkolenia i czasu potrzebnego na wyodrębnienie danych.
Interfejs API tf.data udostępnia transformację tf.data.Dataset.prefetch . Może służyć do oddzielenia czasu generowania danych od czasu, w którym dane są zużywane. W szczególności transformacja wykorzystuje wątek działający w tle i wewnętrzny bufor do wstępnego pobierania elementów z wejściowego zestawu danych przed zażądaniem ich. Liczba elementów do pobrania z wyprzedzeniem powinna być równa (lub być może większa niż) liczbie partii zużywanych przez pojedynczy krok uczenia. Można albo ręcznie dostroić tę wartość, albo ustawić ją na tf.data.AUTOTUNE , co spowoduje, że środowisko wykonawcze tf.data będzie dostroić wartość dynamicznie w czasie wykonywania.
Należy zauważyć, że transformacja pobierania z wyprzedzeniem zapewnia korzyści za każdym razem, gdy istnieje możliwość nałożenia pracy „producenta” z pracą „konsumenta”.
benchmark(
ArtificialDataset()
.prefetch(tf.data.AUTOTUNE)
)
Execution time: 0.21731788600027357

Teraz, jak pokazuje wykres czasu wykonania danych, podczas gdy krok uczenia jest uruchomiony dla próbki 0, potok wejściowy odczytuje dane dla próbki 1 i tak dalej.
Równoległa ekstrakcja danych
W warunkach rzeczywistych dane wejściowe mogą być przechowywane zdalnie (na przykład w Google Cloud Storage lub HDFS). Potok zestawu danych, który działa dobrze podczas lokalnego odczytu danych, może powodować wąskie gardło we/wy podczas zdalnego odczytu danych z powodu następujących różnic między magazynem lokalnym i zdalnym:
- Czas do pierwszego bajtu : odczytanie pierwszego bajtu pliku z pamięci zdalnej może trwać o rząd wielkości dłużej niż z pamięci lokalnej.
- Przepustowość odczytu : chociaż magazyn zdalny zazwyczaj oferuje dużą łączną przepustowość, odczyt pojedynczego pliku może być w stanie wykorzystać tylko niewielką część tej przepustowości.
Ponadto po załadowaniu surowych bajtów do pamięci może być również konieczna deserializacja i/lub odszyfrowanie danych (np. protobuf ), co wymaga dodatkowych obliczeń. Ten narzut jest obecny niezależnie od tego, czy dane są przechowywane lokalnie czy zdalnie, ale może być gorszy w przypadku zdalnym, jeśli dane nie są skutecznie pobierane z wyprzedzeniem.
Aby złagodzić wpływ różnych kosztów ogólnych ekstrakcji danych, można użyć transformacji tf.data.Dataset.interleave do zrównoleglenia etapu ładowania danych, przeplatając zawartość innych zestawów danych (takich jak czytniki plików danych). Liczbę zestawów danych, które mają się nakładać, można określić za pomocą argumentu cycle_length , natomiast poziom równoległości można określić za pomocą argumentu num_parallel_calls . Podobnie jak w przypadku transformacji prefetch , transformacja z interleave obsługuje funkcję tf.data.AUTOTUNE , która deleguje decyzję o tym, jaki poziom równoległości ma być używany do środowiska uruchomieniowego tf.data .
Przeplatanie sekwencyjne
Domyślne argumenty transformacji tf.data.Dataset.interleave sprawiają, że przeplata ona kolejno pojedyncze próbki z dwóch zestawów danych.
benchmark(
tf.data.Dataset.range(2)
.interleave(lambda _: ArtificialDataset())
)
Execution time: 0.4987426460002098

Ten wykres czasu wykonania danych pozwala pokazać zachowanie transformacji z interleave , pobierając próbki alternatywnie z dwóch dostępnych zestawów danych. Jednak nie jest to związane z poprawą wydajności.
Przeplatanie równoległe
Teraz użyj argumentu num_parallel_calls transformacji z interleave . To ładuje wiele zestawów danych równolegle, skracając czas oczekiwania na otwarcie plików.
benchmark(
tf.data.Dataset.range(2)
.interleave(
lambda _: ArtificialDataset(),
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.283668874000341

Tym razem, jak pokazuje wykres czasu wykonania danych, odczyt dwóch zestawów danych jest zrównoleglony, co skraca globalny czas przetwarzania danych.
Równoległa transformacja danych
Podczas przygotowywania danych elementy wejściowe mogą wymagać wstępnego przetworzenia. W tym celu interfejs API tf.data oferuje transformację tf.data.Dataset.map , która stosuje funkcję zdefiniowaną przez użytkownika do każdego elementu wejściowego zestawu danych. Ponieważ elementy wejściowe są niezależne od siebie, wstępne przetwarzanie może być zrównoleglone w wielu rdzeniach procesora. Aby było to możliwe, podobnie do przekształceń prefetch i interleave , transformacja map dostarcza argument num_parallel_calls do określenia poziomu równoległości.
Wybór najlepszej wartości dla argumentu num_parallel_calls zależy od sprzętu, właściwości danych treningowych (takich jak rozmiar i kształt), kosztu funkcji mapy i innych procesów przetwarzania, które w tym samym czasie są wykonywane na procesorze. Prosta heurystyka polega na wykorzystaniu liczby dostępnych rdzeni procesora. Jednak, jeśli chodzi o transformację prefetch z wyprzedzeniem i interleave , transformacja map obsługuje funkcję tf.data.AUTOTUNE , która deleguje decyzję o tym, jakiego poziomu równoległości użyć do środowiska wykonawczego tf.data .
def mapped_function(s):
# Do some hard pre-processing
tf.py_function(lambda: time.sleep(0.03), [], ())
return s
Mapowanie sekwencyjne
Zacznij od użycia transformacji map bez równoległości jako przykładu bazowego.
benchmark(
ArtificialDataset()
.map(mapped_function)
)
Execution time: 0.4505277170001136

Jeśli chodzi o naiwne podejście , tutaj, jak pokazuje wykres, czas spędzony na otwieraniu, czytaniu, wstępnym przetwarzaniu (mapowaniu) i krokach szkoleniowych sumuje się w jednej iteracji.
Mapowanie równoległe
Teraz użyj tej samej funkcji przetwarzania wstępnego, ale zastosuj ją równolegle do wielu próbek.
benchmark(
ArtificialDataset()
.map(
mapped_function,
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.2839677860001757

Jak pokazuje wykres danych, etapy przetwarzania wstępnego nakładają się, co skraca całkowity czas pojedynczej iteracji.
Buforowanie
Transformacja tf.data.Dataset.cache może buforować zestaw danych w pamięci lub w magazynie lokalnym. Pozwoli to zaoszczędzić niektóre operacje (takie jak otwieranie plików i odczytywanie danych) przed wykonaniem w każdej epoce.
benchmark(
ArtificialDataset()
.map( # Apply time consuming operations before cache
mapped_function
).cache(
),
5
)
Execution time: 0.3848854380003104

Tutaj wykres czasu wykonania danych pokazuje, że podczas buforowania zestawu danych przekształcenia przed cache (takie jak otwieranie pliku i odczyt danych) są wykonywane tylko w pierwszej epoce. Kolejne epoki będą ponownie wykorzystywać dane z pamięci podręcznej przez transformację cache .
Jeśli funkcja zdefiniowana przez użytkownika przekazana do transformacji map jest kosztowna, zastosuj transformację cache po transformacji map , o ile wynikowy zestaw danych nadal mieści się w pamięci lub magazynie lokalnym. Jeśli funkcja zdefiniowana przez użytkownika zwiększa przestrzeń wymaganą do przechowywania zestawu danych poza pojemność pamięci podręcznej, zastosuj ją po transformacji cache lub rozważ wstępne przetworzenie danych przed zadaniem treningowym, aby zmniejszyć zużycie zasobów.
Mapowanie wektoryzujące
Wywołanie funkcji zdefiniowanej przez użytkownika przekazanej do transformacji map wiąże się z narzutem związanym z planowaniem i wykonywaniem funkcji zdefiniowanej przez użytkownika. Zwektoryzuj funkcję zdefiniowaną przez użytkownika (to znaczy, aby działała na partii danych wejściowych jednocześnie) i zastosuj transformację batch przed transformacją map .
Aby zilustrować tę dobrą praktykę, Twój sztuczny zbiór danych nie jest odpowiedni. Opóźnienie planowania wynosi około 10 mikrosekund (10e-6 sekund), znacznie mniej niż dziesiątki milisekund używanych w zestawie ArtificialDataset , a zatem jego wpływ jest trudny do zauważenia.
W tym przykładzie użyj podstawowej funkcji tf.data.Dataset.range i uprość pętlę treningową do najprostszej postaci.
fast_dataset = tf.data.Dataset.range(10000)
def fast_benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for _ in tf.data.Dataset.range(num_epochs):
for _ in dataset:
pass
tf.print("Execution time:", time.perf_counter() - start_time)
def increment(x):
return x+1
Mapowanie skalarne
fast_benchmark(
fast_dataset
# Apply function one item at a time
.map(increment)
# Batch
.batch(256)
)
Execution time: 0.2712608739998359

Powyższy wykres ilustruje, co się dzieje (przy mniejszej liczbie próbek) przy użyciu metody mapowania skalarnego. Pokazuje, że mapowana funkcja jest stosowana dla każdej próbki. Chociaż ta funkcja jest bardzo szybka, ma pewne narzuty, które wpływają na wydajność czasu.
Mapowanie wektorowe
fast_benchmark(
fast_dataset
.batch(256)
# Apply function on a batch of items
# The tf.Tensor.__add__ method already handle batches
.map(increment)
)
Execution time: 0.02737950600021577

Tym razem mapowana funkcja jest wywoływana raz i dotyczy partii próbki. Jak pokazuje wykres czasu wykonania danych, chociaż wykonanie funkcji może zająć więcej czasu, narzut pojawia się tylko raz, poprawiając ogólną wydajność czasu.
Zmniejszenie zużycia pamięci
Szereg przekształceń, w tym interleave , prefetch i shuffle , utrzymuje wewnętrzny bufor elementów. Jeśli funkcja zdefiniowana przez użytkownika przekazana do transformacji map zmienia rozmiar elementów, kolejność transformacji mapy i przekształcenia elementów buforujących wpływają na użycie pamięci. Ogólnie rzecz biorąc, wybierz kolejność, która skutkuje mniejszym zużyciem pamięci, chyba że inna kolejność jest pożądana ze względu na wydajność.
Buforowanie częściowych obliczeń
Zaleca się buforowanie zestawu danych po transformacji map , chyba że ta transformacja powoduje, że dane są zbyt duże, aby zmieściły się w pamięci. Kompromis można osiągnąć, jeśli mapowaną funkcję można podzielić na dwie części: część pochłaniającą czas i część pochłaniającą pamięć. W takim przypadku możesz połączyć swoje transformacje jak poniżej:
dataset.map(time_consuming_mapping).cache().map(memory_consuming_mapping)
W ten sposób część czasochłonna jest wykonywana tylko w pierwszej epoce i unikasz używania zbyt dużej ilości pamięci podręcznej.
Podsumowanie najlepszych praktyk
Oto podsumowanie najlepszych praktyk projektowania wydajnych potoków wejściowych TensorFlow:
- Użyj transformacji
prefetch, aby nakładać się na pracę producenta i konsumenta - Zrównolegnij transformację odczytu danych za pomocą transformacji
interleave - Zrównolegnij transformację
map, ustawiając argumentnum_parallel_calls - Użyj transformacji
cache, aby buforować dane w pamięci podczas pierwszej epoki - Wektoryzuj funkcje zdefiniowane przez użytkownika przekazane do transformacji
map - Zmniejsz zużycie pamięci podczas stosowania przekształceń
interleave,prefetchz wyprzedzeniem i odtwarzaniashuffle
Odwzorowanie postaci
Aby głębiej zrozumieć interfejs API tf.data.Dataset , możesz pobawić się własnymi potokami. Poniżej znajduje się kod użyty do wykreślenia obrazów z tego przewodnika. Może to być dobry punkt wyjścia, pokazujący niektóre obejścia typowych problemów, takich jak:
- Odtwarzalność czasu wykonania
- Mapowane funkcje chętne do wykonania
- wywoływalna transformacja z
interleave
import itertools
from collections import defaultdict
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
Zbiór danych
Podobnie jak w przypadku ArtificialDataset , możesz zbudować zestaw danych zwracający czas spędzony na każdym kroku.
class TimeMeasuredDataset(tf.data.Dataset):
# OUTPUT: (steps, timings, counters)
OUTPUT_TYPES = (tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32)
OUTPUT_SHAPES = ((2, 1), (2, 2), (2, 3))
_INSTANCES_COUNTER = itertools.count() # Number of datasets generated
_EPOCHS_COUNTER = defaultdict(itertools.count) # Number of epochs done for each dataset
def _generator(instance_idx, num_samples):
epoch_idx = next(TimeMeasuredDataset._EPOCHS_COUNTER[instance_idx])
# Opening the file
open_enter = time.perf_counter()
time.sleep(0.03)
open_elapsed = time.perf_counter() - open_enter
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
read_enter = time.perf_counter()
time.sleep(0.015)
read_elapsed = time.perf_counter() - read_enter
yield (
[("Open",), ("Read",)],
[(open_enter, open_elapsed), (read_enter, read_elapsed)],
[(instance_idx, epoch_idx, -1), (instance_idx, epoch_idx, sample_idx)]
)
open_enter, open_elapsed = -1., -1. # Negative values will be filtered
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_types=cls.OUTPUT_TYPES,
output_shapes=cls.OUTPUT_SHAPES,
args=(next(cls._INSTANCES_COUNTER), num_samples)
)
Ten zestaw danych zawiera próbki o kształcie [[2, 1], [2, 2], [2, 3]] i typu [tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32] . Każda próbka to:
(
[("Open"), ("Read")],
[(t0, d), (t0, d)],
[(i, e, -1), (i, e, s)]
)
Gdzie:
-
OpeniReadto identyfikatory kroków -
t0to sygnatura czasowa rozpoczęcia odpowiedniego kroku -
dto czas spędzony w odpowiednim kroku -
ijest indeksem instancji -
eto indeks epoki (liczba iteracji zbioru danych) -
sjest indeksem próbki
Pętla iteracyjna
Spraw, aby pętla iteracji była nieco bardziej skomplikowana, aby agregować wszystkie czasy. Będzie to działać tylko z zestawami danych generującymi próbki, jak opisano powyżej.
def timelined_benchmark(dataset, num_epochs=2):
# Initialize accumulators
steps_acc = tf.zeros([0, 1], dtype=tf.dtypes.string)
times_acc = tf.zeros([0, 2], dtype=tf.dtypes.float32)
values_acc = tf.zeros([0, 3], dtype=tf.dtypes.int32)
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
epoch_enter = time.perf_counter()
for (steps, times, values) in dataset:
# Record dataset preparation informations
steps_acc = tf.concat((steps_acc, steps), axis=0)
times_acc = tf.concat((times_acc, times), axis=0)
values_acc = tf.concat((values_acc, values), axis=0)
# Simulate training time
train_enter = time.perf_counter()
time.sleep(0.01)
train_elapsed = time.perf_counter() - train_enter
# Record training informations
steps_acc = tf.concat((steps_acc, [["Train"]]), axis=0)
times_acc = tf.concat((times_acc, [(train_enter, train_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [values[-1]]), axis=0)
epoch_elapsed = time.perf_counter() - epoch_enter
# Record epoch informations
steps_acc = tf.concat((steps_acc, [["Epoch"]]), axis=0)
times_acc = tf.concat((times_acc, [(epoch_enter, epoch_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [[-1, epoch_num, -1]]), axis=0)
time.sleep(0.001)
tf.print("Execution time:", time.perf_counter() - start_time)
return {"steps": steps_acc, "times": times_acc, "values": values_acc}
Metoda kreślenia
Na koniec zdefiniuj funkcję zdolną do wykreślenia osi czasu na podstawie wartości zwracanych przez funkcję timelined_benchmark .
def draw_timeline(timeline, title, width=0.5, annotate=False, save=False):
# Remove invalid entries (negative times, or empty steps) from the timelines
invalid_mask = np.logical_and(timeline['times'] > 0, timeline['steps'] != b'')[:,0]
steps = timeline['steps'][invalid_mask].numpy()
times = timeline['times'][invalid_mask].numpy()
values = timeline['values'][invalid_mask].numpy()
# Get a set of different steps, ordered by the first time they are encountered
step_ids, indices = np.stack(np.unique(steps, return_index=True))
step_ids = step_ids[np.argsort(indices)]
# Shift the starting time to 0 and compute the maximal time value
min_time = times[:,0].min()
times[:,0] = (times[:,0] - min_time)
end = max(width, (times[:,0]+times[:,1]).max() + 0.01)
cmap = mpl.cm.get_cmap("plasma")
plt.close()
fig, axs = plt.subplots(len(step_ids), sharex=True, gridspec_kw={'hspace': 0})
fig.suptitle(title)
fig.set_size_inches(17.0, len(step_ids))
plt.xlim(-0.01, end)
for i, step in enumerate(step_ids):
step_name = step.decode()
ax = axs[i]
ax.set_ylabel(step_name)
ax.set_ylim(0, 1)
ax.set_yticks([])
ax.set_xlabel("time (s)")
ax.set_xticklabels([])
ax.grid(which="both", axis="x", color="k", linestyle=":")
# Get timings and annotation for the given step
entries_mask = np.squeeze(steps==step)
serie = np.unique(times[entries_mask], axis=0)
annotations = values[entries_mask]
ax.broken_barh(serie, (0, 1), color=cmap(i / len(step_ids)), linewidth=1, alpha=0.66)
if annotate:
for j, (start, width) in enumerate(serie):
annotation = "\n".join([f"{l}: {v}" for l,v in zip(("i", "e", "s"), annotations[j])])
ax.text(start + 0.001 + (0.001 * (j % 2)), 0.55 - (0.1 * (j % 2)), annotation,
horizontalalignment='left', verticalalignment='center')
if save:
plt.savefig(title.lower().translate(str.maketrans(" ", "_")) + ".svg")
Użyj wrapperów dla funkcji mapowanej
Aby uruchomić mapowaną funkcję w gorliwym kontekście, musisz umieścić je wewnątrz wywołania tf.py_function .
def map_decorator(func):
def wrapper(steps, times, values):
# Use a tf.py_function to prevent auto-graph from compiling the method
return tf.py_function(
func,
inp=(steps, times, values),
Tout=(steps.dtype, times.dtype, values.dtype)
)
return wrapper
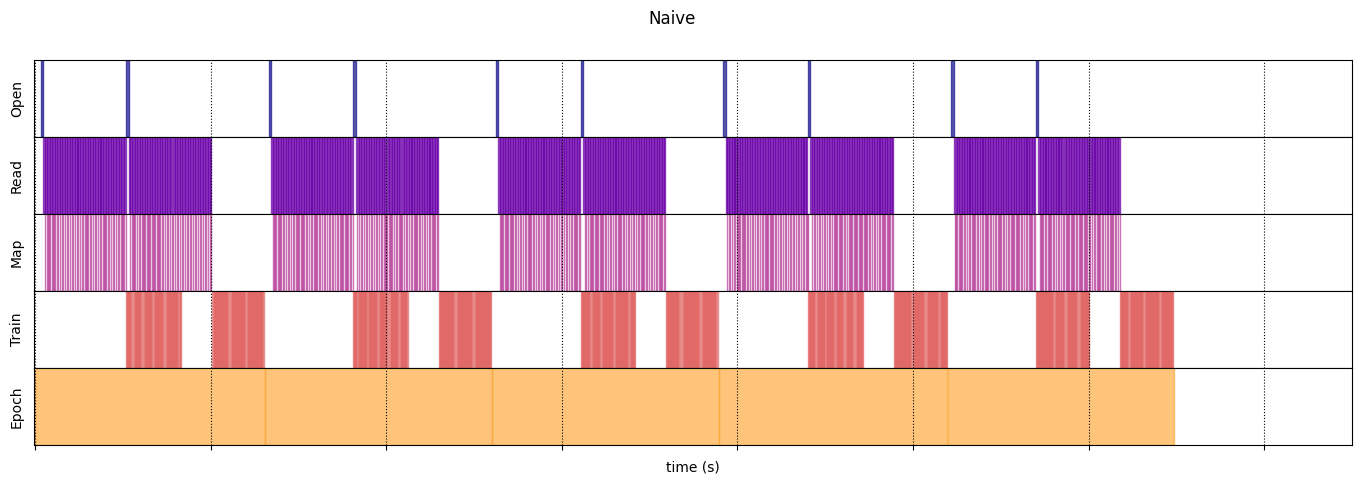
Porównanie rurociągów
_batch_map_num_items = 50
def dataset_generator_fun(*args):
return TimeMeasuredDataset(num_samples=_batch_map_num_items)
Naiwny
@map_decorator
def naive_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001) # Time consuming step
time.sleep(0.0001) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, [["Map"]]), axis=0),
tf.concat((times, [[map_enter, map_elapsed]]), axis=0),
tf.concat((values, [values[-1]]), axis=0)
)
naive_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.flat_map(dataset_generator_fun)
.map(naive_map)
.batch(_batch_map_num_items, drop_remainder=True)
.unbatch(),
5
)
WARNING:tensorflow:From /tmp/ipykernel_23983/64197174.py:36: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_types is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead WARNING:tensorflow:From /tmp/ipykernel_23983/64197174.py:36: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_shapes is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead Execution time: 13.13538893499981
Zoptymalizowany
@map_decorator
def time_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001 * values.shape[0]) # Time consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, tf.tile([[["1st map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
@map_decorator
def memory_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.0001 * values.shape[0]) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
# Use tf.tile to handle batch dimension
return (
tf.concat((steps, tf.tile([[["2nd map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
optimized_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.interleave( # Parallelize data reading
dataset_generator_fun,
num_parallel_calls=tf.data.AUTOTUNE
)
.batch( # Vectorize your mapped function
_batch_map_num_items,
drop_remainder=True)
.map( # Parallelize map transformation
time_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.cache() # Cache data
.map( # Reduce memory usage
memory_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.prefetch( # Overlap producer and consumer works
tf.data.AUTOTUNE
)
.unbatch(),
5
)
Execution time: 6.723691489999965
draw_timeline(naive_timeline, "Naive", 15)
draw_timeline(optimized_timeline, "Optimized", 15)
