
Esta guía muestra cómo utilizar las herramientas disponibles con TensorFlow Profiler para realizar un seguimiento del rendimiento de sus modelos de TensorFlow. Aprenderá a comprender cómo funciona su modelo en el host (CPU), el dispositivo (GPU) o en una combinación de host y dispositivo(s).
La creación de perfiles ayuda a comprender el consumo de recursos de hardware (tiempo y memoria) de las diversas operaciones (ops) de TensorFlow en su modelo y resolver cuellos de botella de rendimiento y, en última instancia, hacer que el modelo se ejecute más rápido.
Esta guía le explicará cómo instalar Profiler, las diversas herramientas disponibles, los diferentes modos en los que Profiler recopila datos de rendimiento y algunas prácticas recomendadas para optimizar el rendimiento del modelo.
Si desea perfilar el rendimiento de su modelo en Cloud TPU, consulte la guía Cloud TPU .
Instale los requisitos previos de Profiler y GPU
Instale el complemento Profiler para TensorBoard con pip. Tenga en cuenta que Profiler requiere las últimas versiones de TensorFlow y TensorBoard (>=2.2).
pip install -U tensorboard_plugin_profile
Para crear un perfil en la GPU, debes:
- Cumpla con los controladores de GPU NVIDIA® y los requisitos del kit de herramientas CUDA® enumerados en Requisitos del software de soporte de GPU TensorFlow .
Asegúrese de que la interfaz de herramientas de creación de perfiles NVIDIA® CUDA® (CUPTI) exista en la ruta:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
Si no tiene CUPTI en la ruta, anteponga su directorio de instalación a la variable de entorno $LD_LIBRARY_PATH ejecutando:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
Luego, ejecute nuevamente el comando ldconfig anterior para verificar que se encuentre la biblioteca CUPTI.
Resolver problemas de privilegios
Cuando ejecuta la creación de perfiles con CUDA® Toolkit en un entorno Docker o en Linux, puede encontrar problemas relacionados con privilegios CUPTI insuficientes ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ). Vaya a los documentos para desarrolladores de NVIDIA para obtener más información sobre cómo resolver estos problemas en Linux.
Para resolver problemas de privilegios de CUPTI en un entorno Docker, ejecute
docker run option '--privileged=true'
Herramientas de perfilado
Acceda al Profiler desde la pestaña Perfil en TensorBoard, que aparece solo después de haber capturado algunos datos del modelo.
Profiler tiene una selección de herramientas para ayudar con el análisis de rendimiento:
- Página de descripción general
- Analizador de canalización de entrada
- Estadísticas de TensorFlow
- Visor de seguimiento
- Estadísticas del núcleo de la GPU
- Herramienta de perfil de memoria
- Visor de pods
Página de descripción general
La página de descripción general proporciona una vista de nivel superior de cómo se desempeñó su modelo durante una ejecución de perfil. La página le muestra una página de descripción general agregada para su host y todos los dispositivos, y algunas recomendaciones para mejorar el rendimiento del entrenamiento de su modelo. También puede seleccionar hosts individuales en el menú desplegable Host.
La página de descripción general muestra los datos de la siguiente manera:
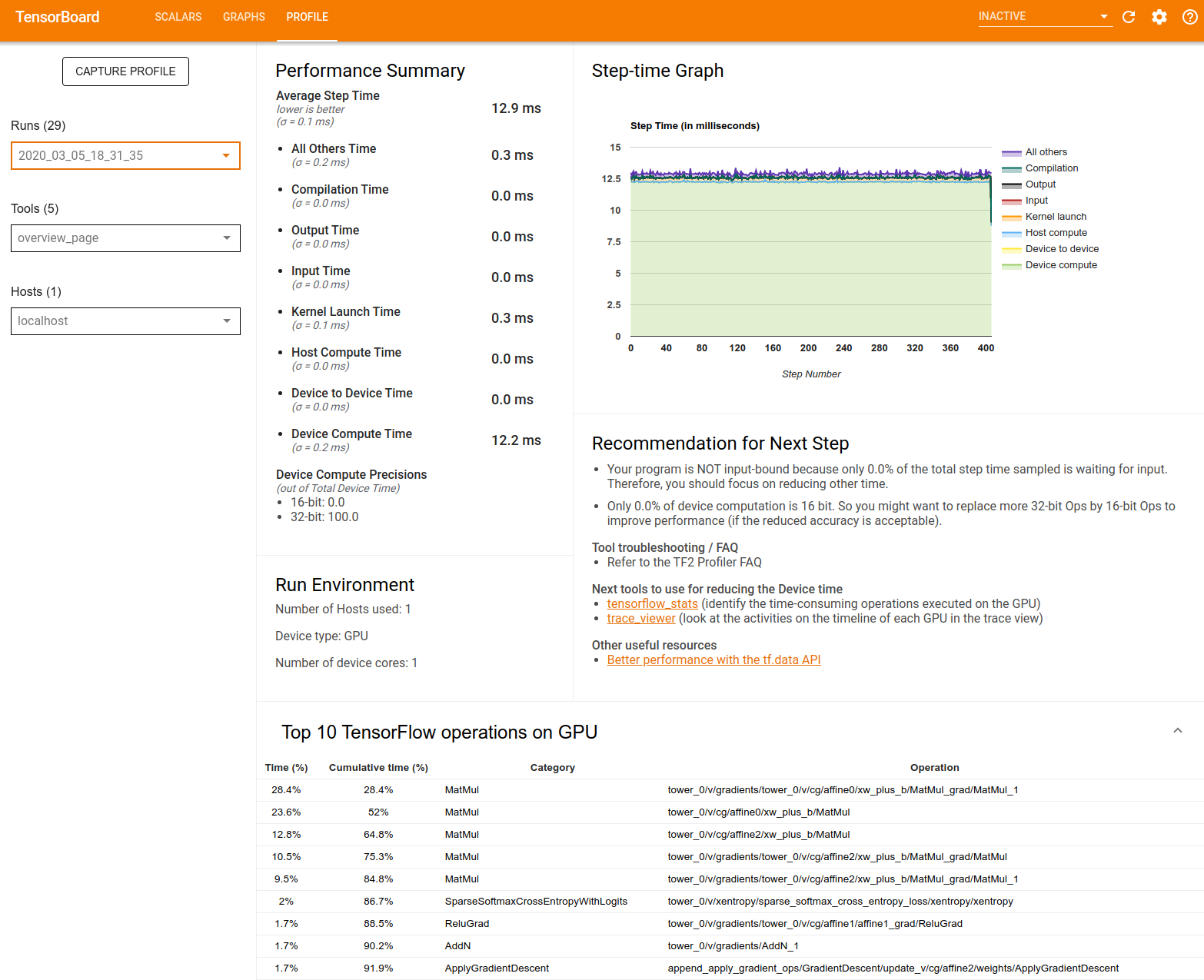
Resumen de rendimiento : muestra un resumen de alto nivel del rendimiento de su modelo. El resumen de desempeño tiene dos partes:
Desglose del tiempo de paso: desglosa el tiempo promedio de paso en múltiples categorías de dónde se gasta el tiempo:
- Compilación: tiempo dedicado a compilar kernels.
- Entrada: tiempo dedicado a leer los datos de entrada.
- Salida: tiempo dedicado a leer los datos de salida.
- Lanzamiento del kernel: tiempo que dedica el host a lanzar los kernels
- Tiempo de cálculo del host.
- Tiempo de comunicación de dispositivo a dispositivo.
- Tiempo de cálculo en el dispositivo.
- Todos los demás, incluida la sobrecarga de Python.
Precisiones de cálculo del dispositivo: informa el porcentaje de tiempo de cálculo del dispositivo que utiliza cálculos de 16 y 32 bits.
Gráfico de tiempo de paso : muestra un gráfico del tiempo de paso del dispositivo (en milisegundos) sobre todos los pasos muestreados. Cada paso se divide en múltiples categorías (con diferentes colores) de dónde se dedica el tiempo. El área roja corresponde a la parte del tiempo que los dispositivos estuvieron inactivos esperando datos de entrada del host. El área verde muestra cuánto tiempo estuvo funcionando realmente el dispositivo.
Las 10 operaciones principales de TensorFlow en el dispositivo (por ejemplo, GPU) : muestra las operaciones en el dispositivo que se ejecutaron por más tiempo.
Cada fila muestra el tiempo propio de una operación (como el porcentaje de tiempo empleado por todas las operaciones), el tiempo acumulado, la categoría y el nombre.
Entorno de ejecución : muestra un resumen de alto nivel del entorno de ejecución del modelo que incluye:
- Número de hosts utilizados.
- Tipo de dispositivo (GPU/TPU).
- Número de núcleos del dispositivo.
Recomendación para el siguiente paso : informa cuando un modelo está vinculado a la entrada y recomienda herramientas que puede utilizar para localizar y resolver cuellos de botella en el rendimiento del modelo.
Analizador de tuberías de entrada
Cuando un programa TensorFlow lee datos de un archivo, comienza en la parte superior del gráfico de TensorFlow de forma canalizada. El proceso de lectura se divide en múltiples etapas de procesamiento de datos conectadas en serie, donde la salida de una etapa es la entrada de la siguiente. Este sistema de lectura de datos se llama canalización de entrada .
Una canalización típica para leer registros de archivos tiene las siguientes etapas:
- Lectura de archivos.
- Preprocesamiento de archivos (opcional).
- Transferencia de archivos desde el host al dispositivo.
Una canalización de entrada ineficiente puede ralentizar gravemente su aplicación. Una aplicación se considera vinculada a la entrada cuando pasa una parte importante del tiempo en la canalización de entrada. Utilice los conocimientos obtenidos del analizador de canalización de entrada para comprender dónde es ineficiente la canalización de entrada.
El analizador de canalización de entrada le indica inmediatamente si su programa está vinculado a la entrada y lo guía a través del análisis del lado del dispositivo y del host para depurar cuellos de botella de rendimiento en cualquier etapa del canal de entrada.
Consulte la guía sobre el rendimiento de la canalización de entrada para conocer las mejores prácticas recomendadas para optimizar sus canalizaciones de entrada de datos.
Panel de control de canalización de entrada
Para abrir el analizador de canalización de entrada, seleccione Perfil y luego seleccione input_pipeline_analyzer en el menú desplegable Herramientas .
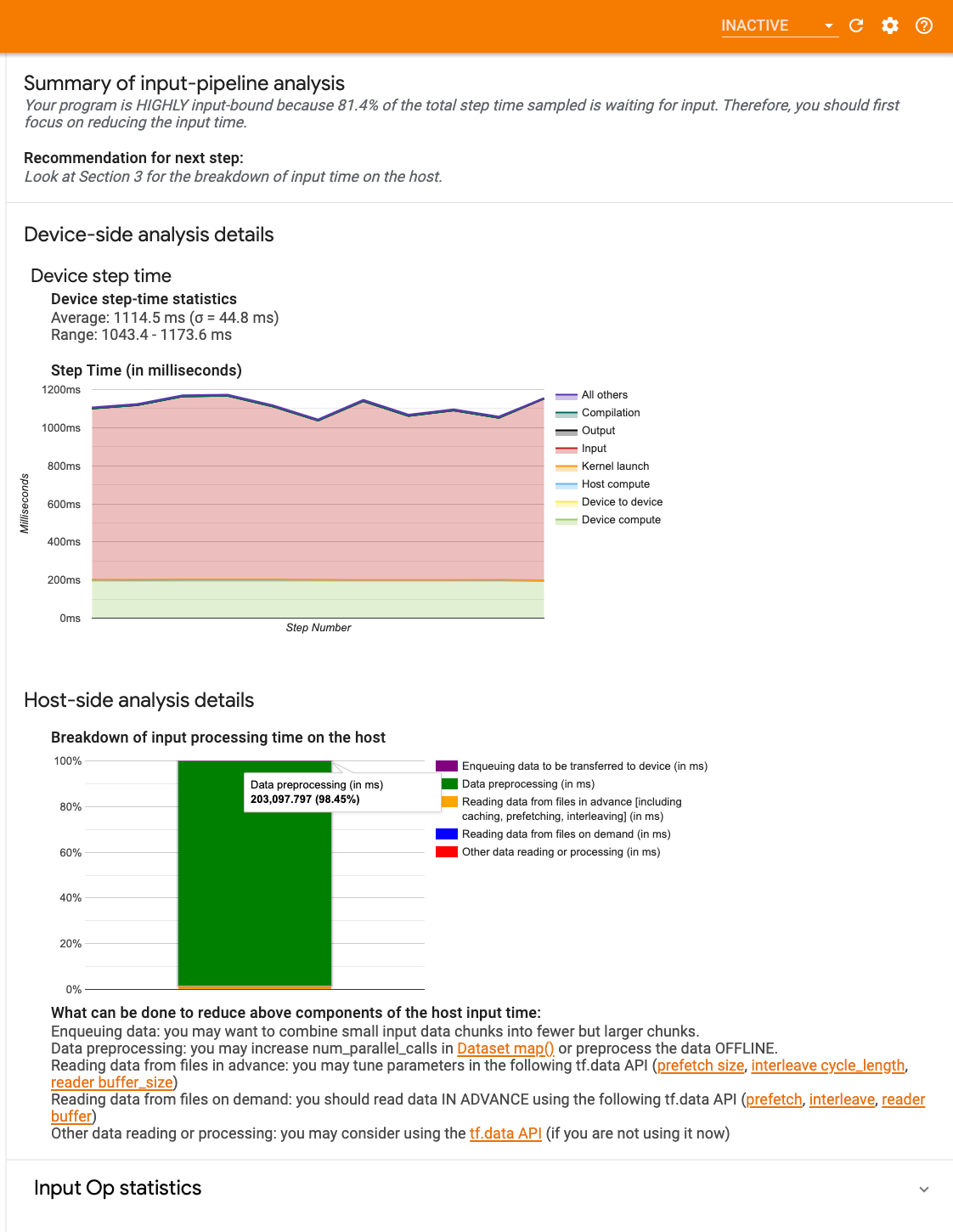
El panel contiene tres secciones:
- Resumen : resume el proceso de entrada general con información sobre si su aplicación está vinculada a la entrada y, de ser así, en qué medida.
- Análisis del lado del dispositivo : muestra resultados detallados del análisis del lado del dispositivo, incluido el tiempo de paso del dispositivo y el rango de tiempo que el dispositivo pasa esperando datos de entrada en todos los núcleos en cada paso.
- Análisis del lado del host : muestra un análisis detallado del lado del host, incluido un desglose del tiempo de procesamiento de entrada en el host.
Resumen de canalización de entrada
El Resumen informa si su programa está vinculado a la entrada presentando el porcentaje de tiempo del dispositivo dedicado a esperar la entrada del host. Si está utilizando una canalización de entrada estándar que ha sido instrumentada, la herramienta informa dónde se gasta la mayor parte del tiempo de procesamiento de entrada.
Análisis del lado del dispositivo
El análisis del lado del dispositivo proporciona información sobre el tiempo invertido en el dispositivo frente al host y cuánto tiempo del dispositivo se dedicó a esperar datos de entrada del host.
- Tiempo de paso trazado contra el número de paso : muestra un gráfico del tiempo de paso del dispositivo (en milisegundos) sobre todos los pasos muestreados. Cada paso se divide en múltiples categorías (con diferentes colores) de dónde se dedica el tiempo. El área roja corresponde a la parte del tiempo que los dispositivos estuvieron inactivos esperando datos de entrada del host. El área verde muestra cuánto tiempo estuvo funcionando realmente el dispositivo.
- Estadísticas de tiempo de paso : informa el promedio, la desviación estándar y el rango ([mínimo, máximo]) del tiempo de paso del dispositivo.
Análisis del lado del host
El análisis del lado del host informa un desglose del tiempo de procesamiento de entrada (el tiempo dedicado a las operaciones de la API tf.data ) en el host en varias categorías:
- Lectura de datos de archivos bajo demanda : tiempo dedicado a leer datos de archivos sin almacenamiento en caché, captación previa ni intercalado.
- Lectura anticipada de datos de archivos : tiempo dedicado a leer archivos, incluido el almacenamiento en caché, la captación previa y el entrelazado.
- Preprocesamiento de datos : tiempo dedicado a operaciones de preprocesamiento, como la descompresión de imágenes.
- Poner en cola los datos que se transferirán al dispositivo : tiempo dedicado a colocar los datos en una cola de alimentación antes de transferirlos al dispositivo.
Expanda Estadísticas de operaciones de entrada para inspeccionar las estadísticas de operaciones de entrada individuales y sus categorías desglosadas por tiempo de ejecución.
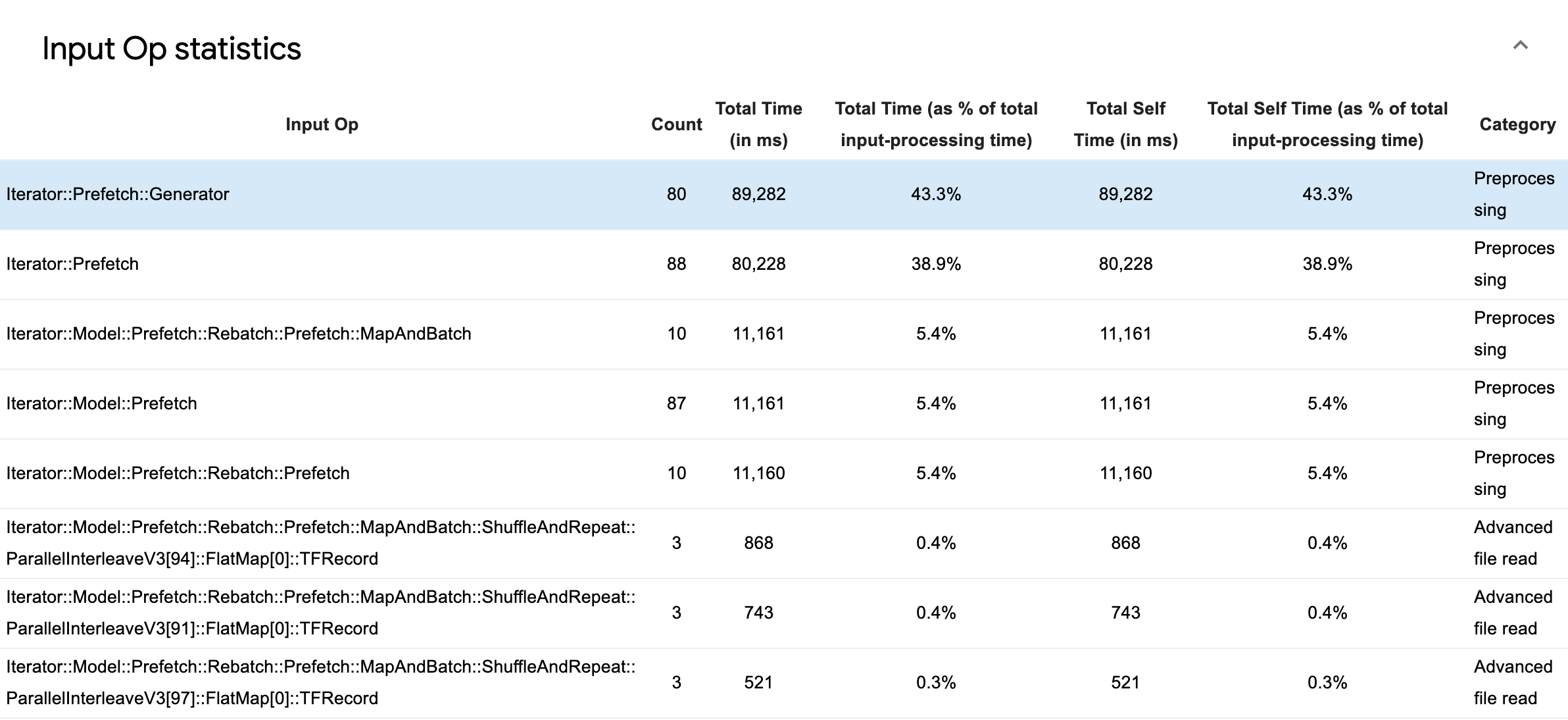
Aparecerá una tabla de datos de origen con cada entrada que contiene la siguiente información:
- Operación de entrada : muestra el nombre de la operación de TensorFlow de la operación de entrada.
- Recuento : muestra el número total de instancias de ejecución de operaciones durante el período de creación de perfiles.
- Tiempo total (en ms) : muestra la suma acumulada del tiempo dedicado a cada una de esas instancias.
- % de tiempo total : muestra el tiempo total dedicado a una operación como una fracción del tiempo total dedicado al procesamiento de entrada.
- Tiempo propio total (en ms) : muestra la suma acumulada del tiempo propio dedicado a cada una de esas instancias. El tiempo propio aquí mide el tiempo transcurrido dentro del cuerpo de la función, excluyendo el tiempo transcurrido en la función que llama.
- % de tiempo total para uno mismo . Muestra el tiempo total del usuario como una fracción del tiempo total dedicado al procesamiento de entrada.
- Categoría . Muestra la categoría de procesamiento de la operación de entrada.
Estadísticas de TensorFlow
La herramienta TensorFlow Stats muestra el rendimiento de cada operación (op) de TensorFlow que se ejecuta en el host o dispositivo durante una sesión de creación de perfiles.
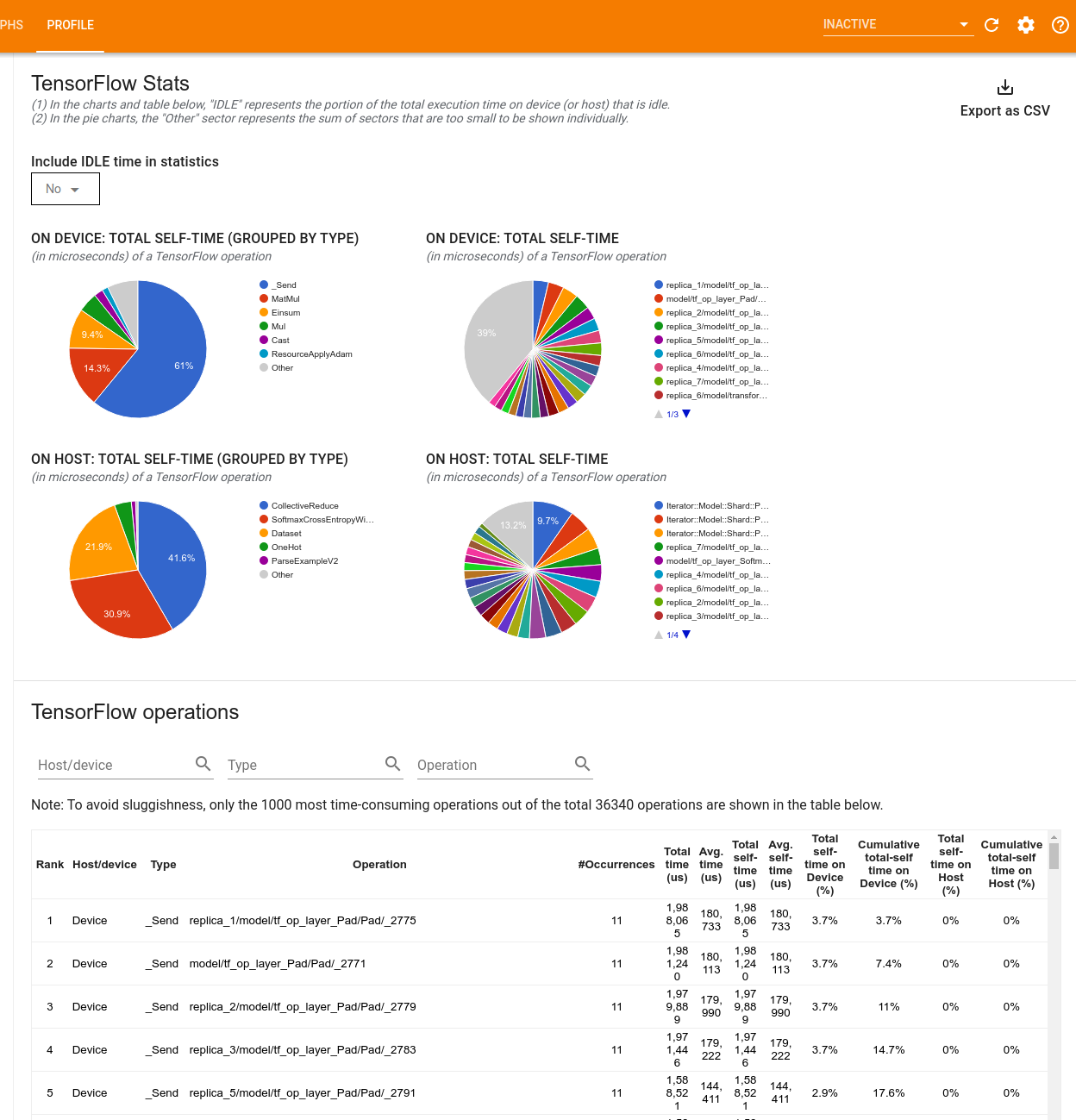
La herramienta muestra información de rendimiento en dos paneles:
El panel superior muestra hasta cuatro gráficos circulares:
- La distribución del tiempo de autoejecución de cada operación en el host.
- La distribución del tiempo de autoejecución de cada tipo de operación en el host.
- La distribución del tiempo de autoejecución de cada operación en el dispositivo.
- La distribución del tiempo de autoejecución de cada tipo de operación en el dispositivo.
El panel inferior muestra una tabla que informa datos sobre las operaciones de TensorFlow con una fila para cada operación y una columna para cada tipo de datos (ordene las columnas haciendo clic en el encabezado de la columna). Haga clic en el botón Exportar como CSV en el lado derecho del panel superior para exportar los datos de esta tabla como un archivo CSV.
Tenga en cuenta que:
Si alguna operación tiene operaciones infantiles:
- El tiempo total "acumulado" de una operación incluye el tiempo pasado dentro de las operaciones secundarias.
- El tiempo total "propio" de una operación no incluye el tiempo pasado dentro de las operaciones secundarias.
Si se ejecuta una operación en el host:
- El porcentaje del tiempo total en el dispositivo incurrido por la opción será 0.
- El porcentaje acumulativo del tiempo total de uso propio en el dispositivo hasta esta operación incluida será 0.
Si se ejecuta una operación en el dispositivo:
- El porcentaje del tiempo total en el host incurrido por esta operación será 0.
- El porcentaje acumulativo del tiempo total de tiempo propio en el host hasta esta operación inclusive será 0.
Puede optar por incluir o excluir el tiempo de inactividad en los gráficos circulares y en la tabla.
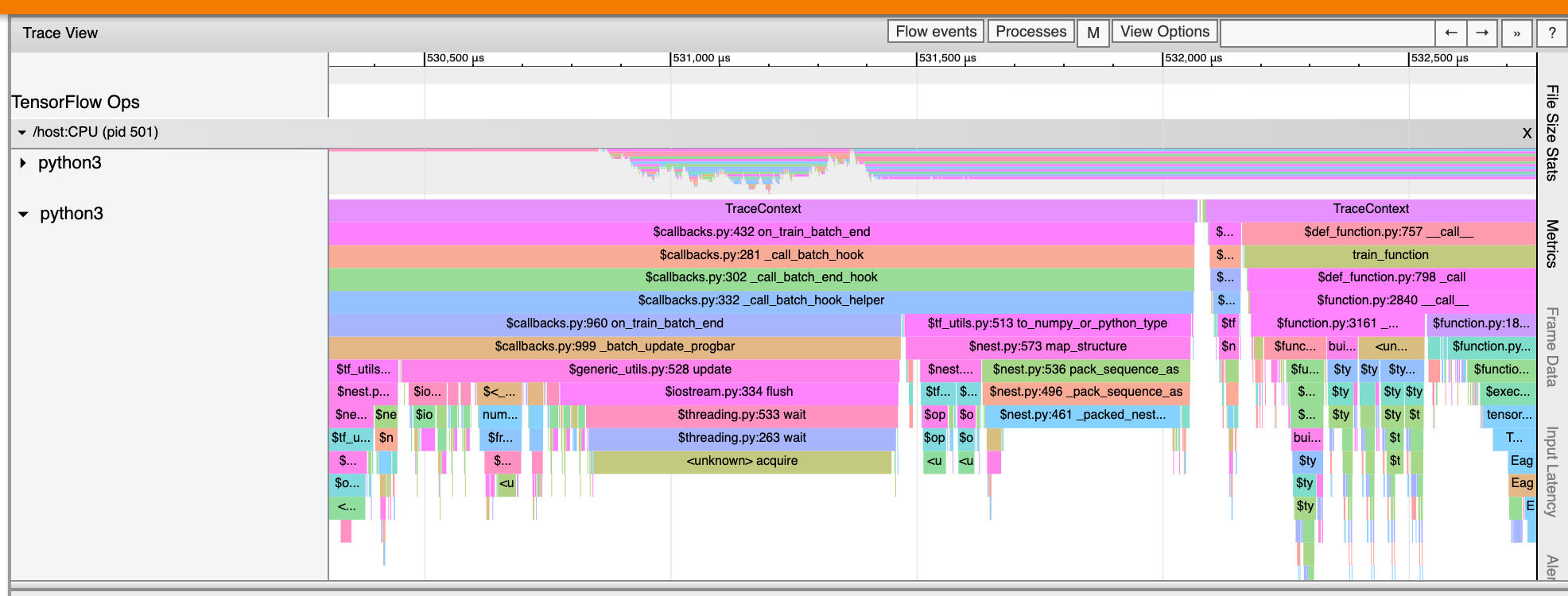
Visor de seguimiento
El visor de seguimiento muestra una línea de tiempo que muestra:
- Duraciones de las operaciones ejecutadas por su modelo de TensorFlow
- ¿Qué parte del sistema (host o dispositivo) ejecutó una operación? Normalmente, el host ejecuta operaciones de entrada, preprocesa los datos de entrenamiento y los transfiere al dispositivo, mientras que el dispositivo ejecuta el entrenamiento del modelo real.
El visor de seguimiento le permite identificar problemas de rendimiento en su modelo y luego tomar medidas para resolverlos. Por ejemplo, en un nivel alto, puede identificar si la capacitación de entrada o de modelo está tomando la mayor parte del tiempo. Profundizando, puede identificar qué operaciones tardan más en ejecutarse. Tenga en cuenta que el visor de seguimiento está limitado a 1 millón de eventos por dispositivo.
Interfaz del visor de seguimiento
Cuando abres el visor de seguimiento, aparece mostrando tu ejecución más reciente:
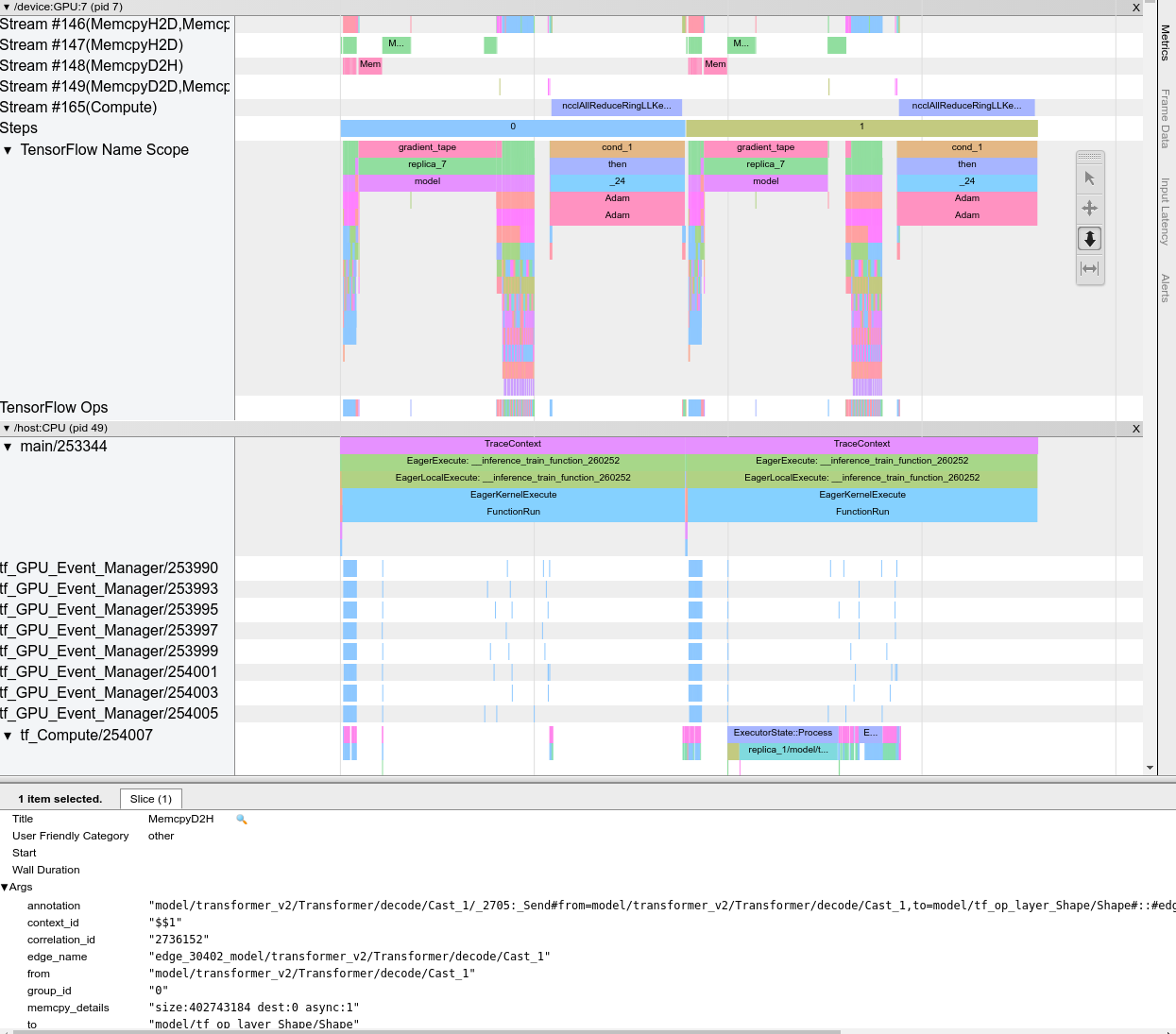
Esta pantalla contiene los siguientes elementos principales:
- Panel de línea de tiempo : muestra las operaciones que el dispositivo y el host ejecutaron a lo largo del tiempo.
- Panel de detalles : muestra información adicional para las operaciones seleccionadas en el panel Línea de tiempo.
El panel Línea de tiempo contiene los siguientes elementos:
- Barra superior : Contiene varios controles auxiliares.
- Eje de tiempo : Muestra el tiempo relativo al inicio del trazado.
- Etiquetas de secciones y pistas : cada sección contiene varias pistas y tiene un triángulo a la izquierda en el que puede hacer clic para expandir y contraer la sección. Hay una sección para cada elemento de procesamiento del sistema.
- Selector de herramientas : contiene varias herramientas para interactuar con el visor de seguimiento, como Zoom, Pan, Select y Timing. Utilice la herramienta de sincronización para marcar un intervalo de tiempo.
- Eventos : muestran el tiempo durante el cual se ejecutó una operación o la duración de los metaeventos, como los pasos de entrenamiento.
Secciones y pistas
El visor de seguimiento contiene las siguientes secciones:
- Una sección para cada nodo del dispositivo , etiquetada con el número del chip del dispositivo y el nodo del dispositivo dentro del chip (por ejemplo,
/device:GPU:0 (pid 0)). Cada sección de nodo de dispositivo contiene las siguientes pistas:- Paso : muestra la duración de los pasos de entrenamiento que se estaban ejecutando en el dispositivo.
- TensorFlow Ops : muestra las operaciones ejecutadas en el dispositivo.
- Operaciones XLA : muestra las operaciones XLA que se ejecutaron en el dispositivo si XLA es el compilador utilizado (cada operación TensorFlow se traduce en una o varias operaciones XLA. El compilador XLA traduce las operaciones XLA en código que se ejecuta en el dispositivo).
- Una sección para los subprocesos que se ejecutan en la CPU de la máquina host, denominada "Subprocesos del host" . La sección contiene una pista para cada subproceso de CPU. Tenga en cuenta que puede ignorar la información que se muestra junto a las etiquetas de las secciones.
Eventos
Los eventos dentro de la línea de tiempo se muestran en diferentes colores; los colores en sí no tienen un significado específico.
El visor de seguimiento también puede mostrar seguimientos de llamadas a funciones de Python en su programa TensorFlow. Si utiliza la API tf.profiler.experimental.start , puede habilitar el seguimiento de Python utilizando ProfilerOptions llamado tuple al iniciar la creación de perfiles. Alternativamente, si usa el modo de muestreo para crear perfiles, puede seleccionar el nivel de seguimiento usando las opciones desplegables en el cuadro de diálogo Capturar perfil .
Estadísticas del kernel de GPU
Esta herramienta muestra estadísticas de rendimiento y la operación de origen para cada núcleo acelerado por GPU.
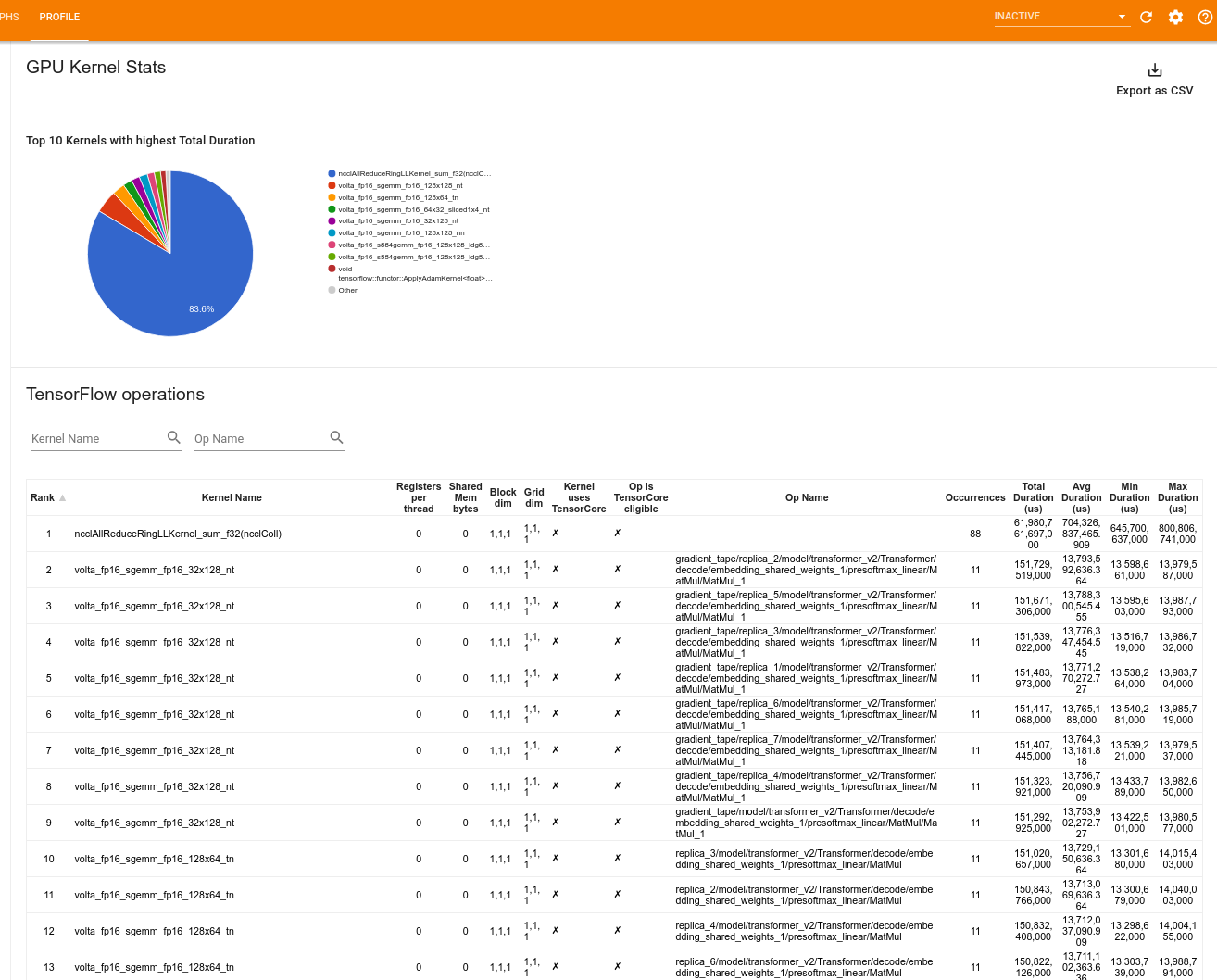
La herramienta muestra información en dos paneles:
El panel superior muestra un gráfico circular que muestra los núcleos CUDA que tienen el mayor tiempo total transcurrido.
El panel inferior muestra una tabla con los siguientes datos para cada par único de operaciones de kernel:
- Una clasificación en orden descendente de la duración total transcurrida de la GPU agrupada por par de operaciones de kernel.
- El nombre del kernel lanzado.
- La cantidad de registros de GPU utilizados por el kernel.
- El tamaño total de la memoria compartida (estática + dinámica compartida) utilizada en bytes.
- La dimensión del bloque expresada como
blockDim.x, blockDim.y, blockDim.z. - Las dimensiones de la cuadrícula expresadas como
gridDim.x, gridDim.y, gridDim.z. - Si la operación es elegible para usar Tensor Cores .
- Si el kernel contiene instrucciones de Tensor Core.
- El nombre de la operación que lanzó este kernel.
- El número de apariciones de este par kernel-op.
- El tiempo total de GPU transcurrido en microsegundos.
- El tiempo promedio de GPU transcurrido en microsegundos.
- El tiempo mínimo de GPU transcurrido en microsegundos.
- El tiempo máximo de GPU transcurrido en microsegundos.
Herramienta de perfil de memoria
La herramienta Perfil de memoria monitorea el uso de la memoria de su dispositivo durante el intervalo de creación de perfiles. Puede utilizar esta herramienta para:
- Depure problemas de falta de memoria (OOM) identificando el uso máximo de memoria y la asignación de memoria correspondiente a las operaciones de TensorFlow. También puede depurar problemas de OOM que puedan surgir al ejecutar la inferencia multiinquilino .
- Depurar problemas de fragmentación de la memoria.
La herramienta de perfil de memoria muestra datos en tres secciones:
- Resumen del perfil de memoria
- Gráfico de línea de tiempo de memoria
- Tabla de desglose de la memoria
Resumen del perfil de memoria
Esta sección muestra un resumen de alto nivel del perfil de memoria de su programa TensorFlow como se muestra a continuación:
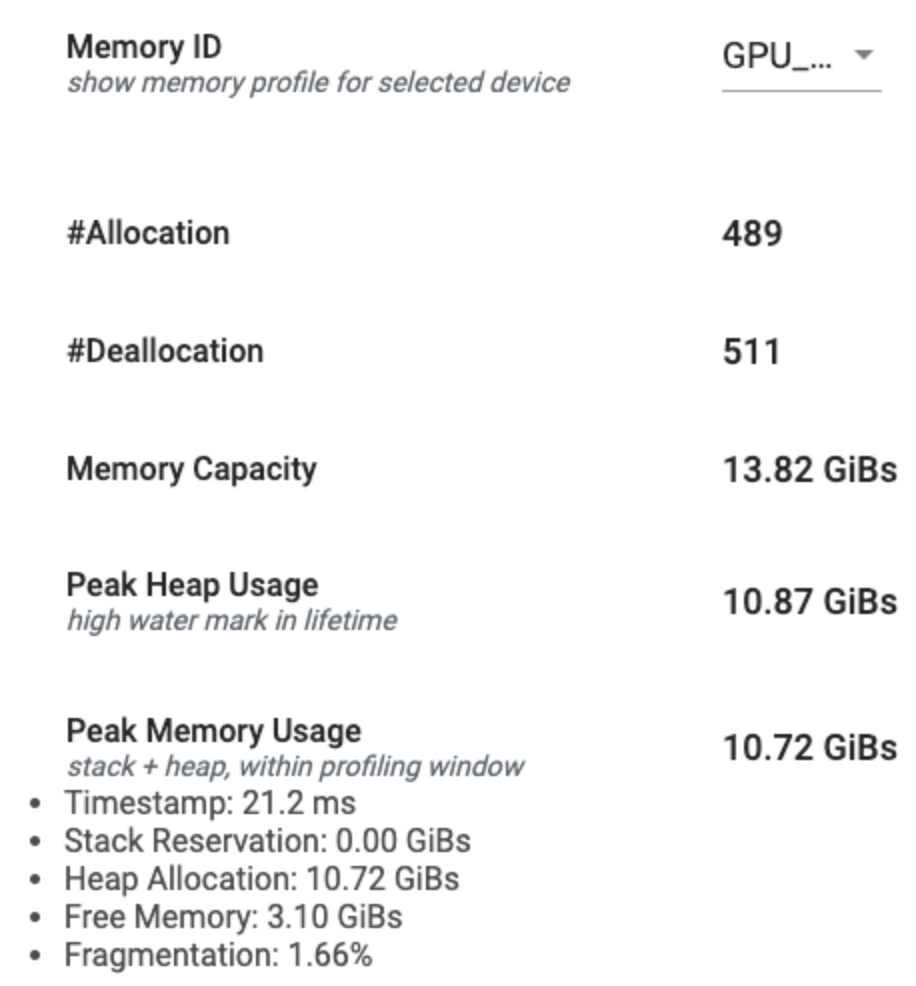
El resumen del perfil de memoria tiene seis campos:
- ID de memoria : menú desplegable que enumera todos los sistemas de memoria del dispositivo disponibles. Seleccione el sistema de memoria que desea ver en el menú desplegable.
- #Allocation : el número de asignaciones de memoria realizadas durante el intervalo de creación de perfiles.
- #Deallocation : el número de desasignaciones de memoria en el intervalo de generación de perfiles.
- Capacidad de memoria : la capacidad total (en GiB) del sistema de memoria que seleccione.
- Uso máximo del montón : el uso máximo de memoria (en GiB) desde que el modelo comenzó a ejecutarse.
- Uso máximo de memoria : el uso máximo de memoria (en GiB) en el intervalo de creación de perfiles. Este campo contiene los siguientes subcampos:
- Marca de tiempo : la marca de tiempo de cuando ocurrió el uso máximo de memoria en el gráfico de línea de tiempo.
- Reserva de pila : cantidad de memoria reservada en la pila (en GiB).
- Asignación de montón : cantidad de memoria asignada en el montón (en GiB).
- Memoria libre : cantidad de memoria libre (en GiB). La capacidad de memoria es la suma total de la reserva de pila, la asignación de montón y la memoria libre.
- Fragmentación : El porcentaje de fragmentación (cuanto menor, mejor). Se calcula como un porcentaje de
(1 - Size of the largest chunk of free memory / Total free memory).
Gráfico de línea de tiempo de memoria
Esta sección muestra un gráfico del uso de la memoria (en GiB) y el porcentaje de fragmentación frente al tiempo (en ms).
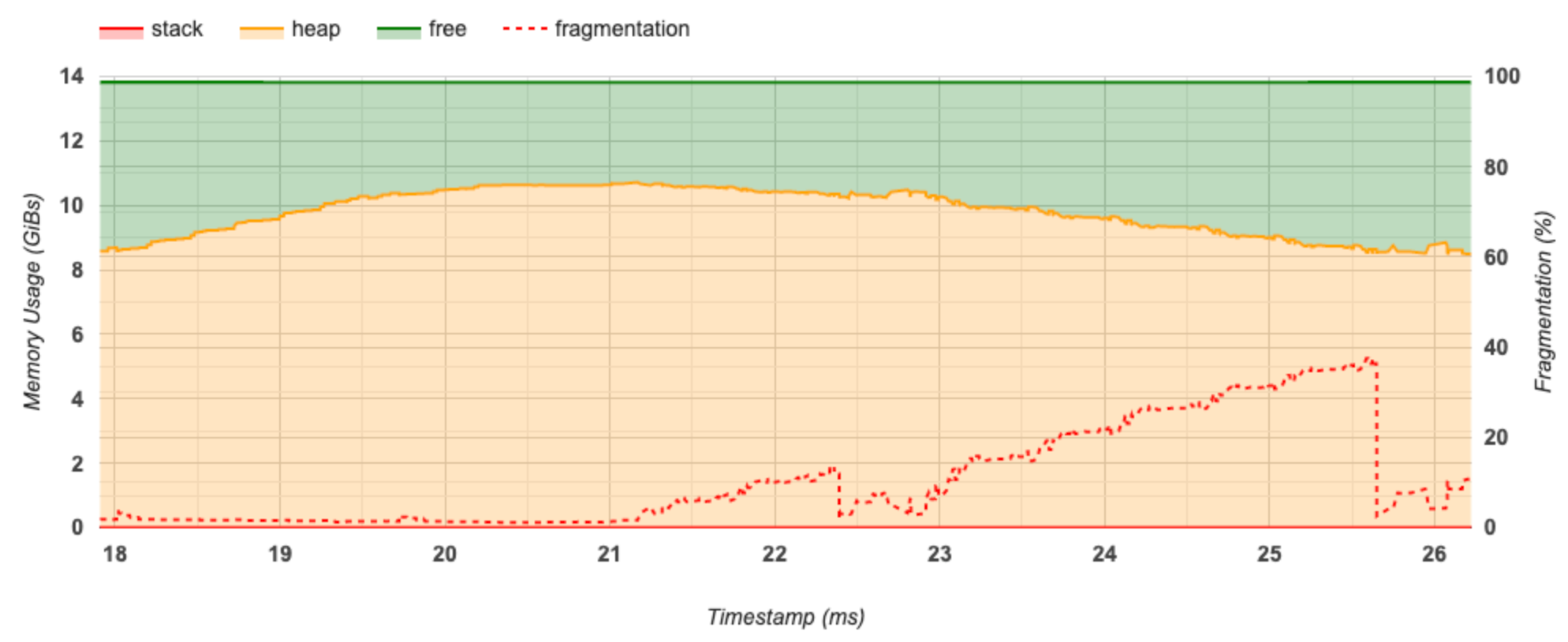
El eje X representa la línea de tiempo (en ms) del intervalo de generación de perfiles. El eje Y de la izquierda representa el uso de memoria (en GiB) y el eje Y de la derecha representa el porcentaje de fragmentación. En cada punto del tiempo en el eje X, la memoria total se divide en tres categorías: pila (en rojo), montón (en naranja) y libre (en verde). Pase el cursor sobre una marca de tiempo específica para ver los detalles sobre los eventos de asignación/desasignación de memoria en ese punto, como se muestra a continuación:
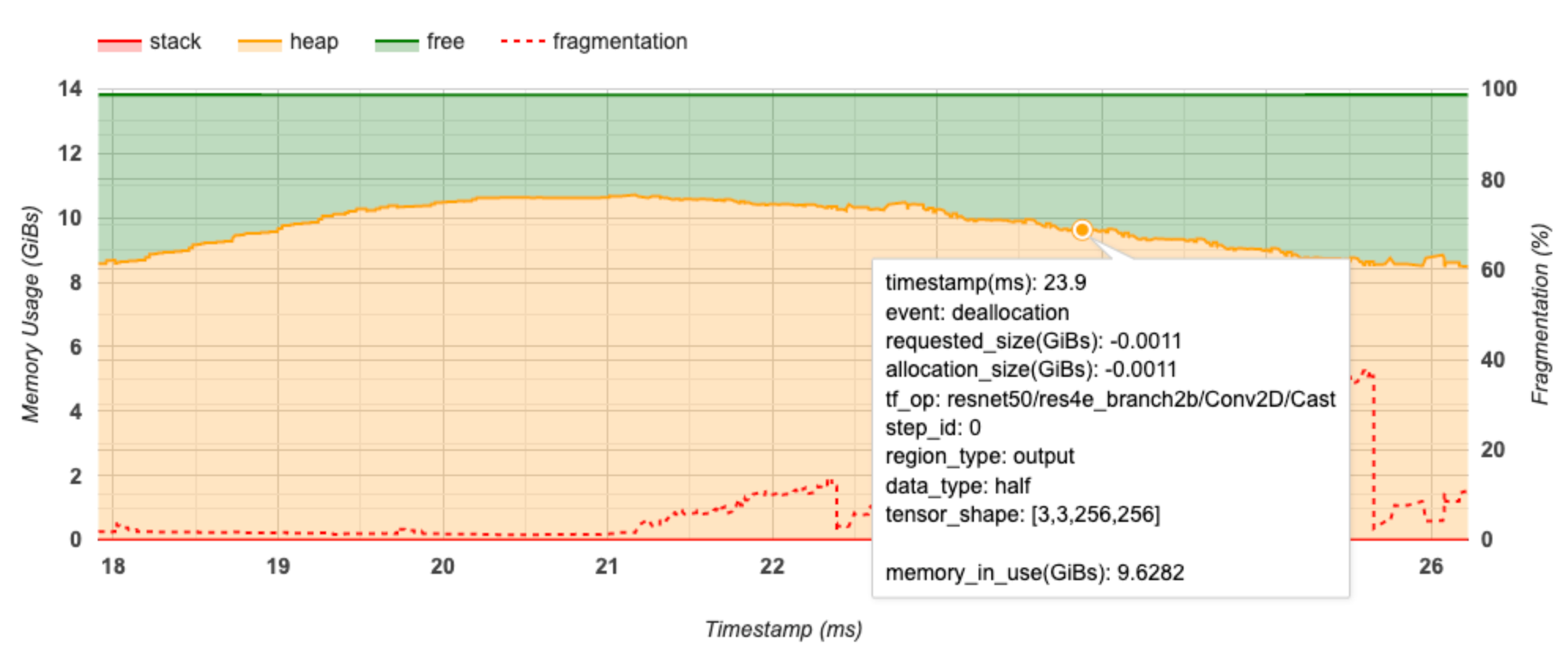
La ventana emergente muestra la siguiente información:
- marca de tiempo (ms) : la ubicación del evento seleccionado en la línea de tiempo.
- evento : El tipo de evento (asignación o desasignación).
- request_size(GiBs) : la cantidad de memoria solicitada. Este será un número negativo para eventos de desasignación.
- asignación_tamaño (GiB) : la cantidad real de memoria asignada. Este será un número negativo para eventos de desasignación.
- tf_op : la operación de TensorFlow que solicita la asignación/desasignación.
- step_id : el paso de entrenamiento en el que ocurrió este evento.
- region_type : el tipo de entidad de datos para el que es esta memoria asignada. Los valores posibles son
temppara temporales,outputpara activaciones y gradientes, ypersist/dynamicpara pesos y constantes. - data_type : el tipo de elemento tensor (por ejemplo, uint8 para un entero sin signo de 8 bits).
- tensor_shape : la forma del tensor que se asigna/desasigna.
- Memory_in_use(GiBs) : la memoria total que está en uso en este momento.
Tabla de desglose de la memoria
Esta tabla muestra las asignaciones de memoria activa en el punto de uso máximo de memoria en el intervalo de generación de perfiles.
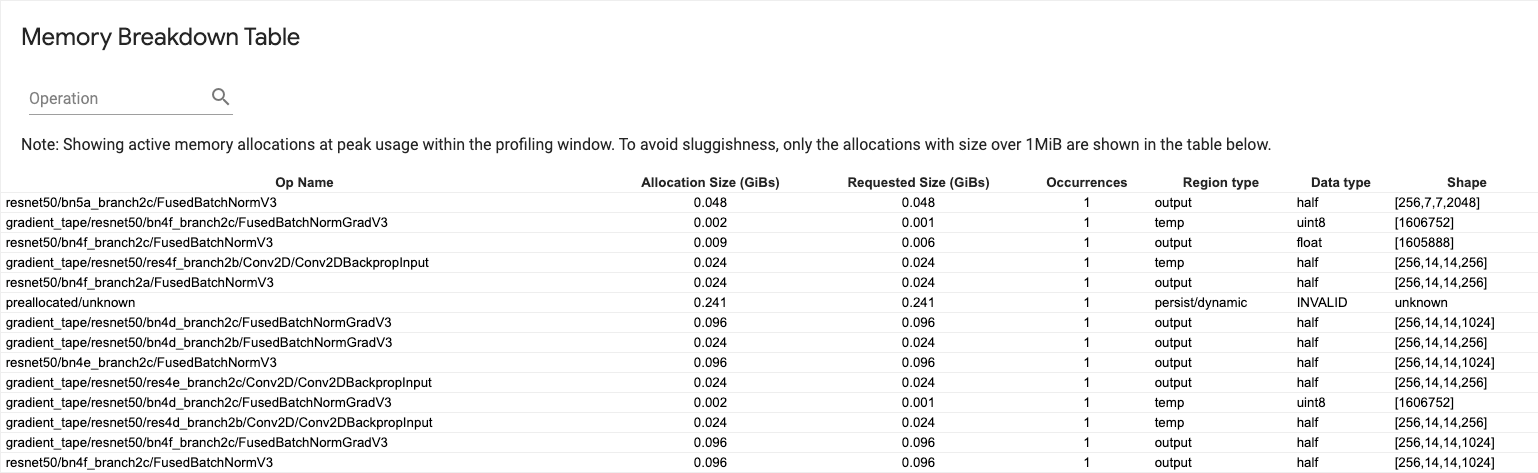
Hay una fila para cada operación de TensorFlow y cada fila tiene las siguientes columnas:
- Nombre de operación : el nombre de la operación de TensorFlow.
- Tamaño de asignación (GiB) : la cantidad total de memoria asignada a esta operación.
- Tamaño solicitado (GiB) : la cantidad total de memoria solicitada para esta operación.
- Ocurrencias : el número de asignaciones para esta operación.
- Tipo de región : el tipo de entidad de datos para el que es esta memoria asignada. Los valores posibles son
temppara temporales,outputpara activaciones y gradientes, ypersist/dynamicpara pesos y constantes. - Tipo de datos : el tipo de elemento tensor.
- Forma : la forma de los tensores asignados.
Visor de pods
La herramienta Pod Viewer muestra el desglose de un paso de capacitación entre todos los trabajadores.
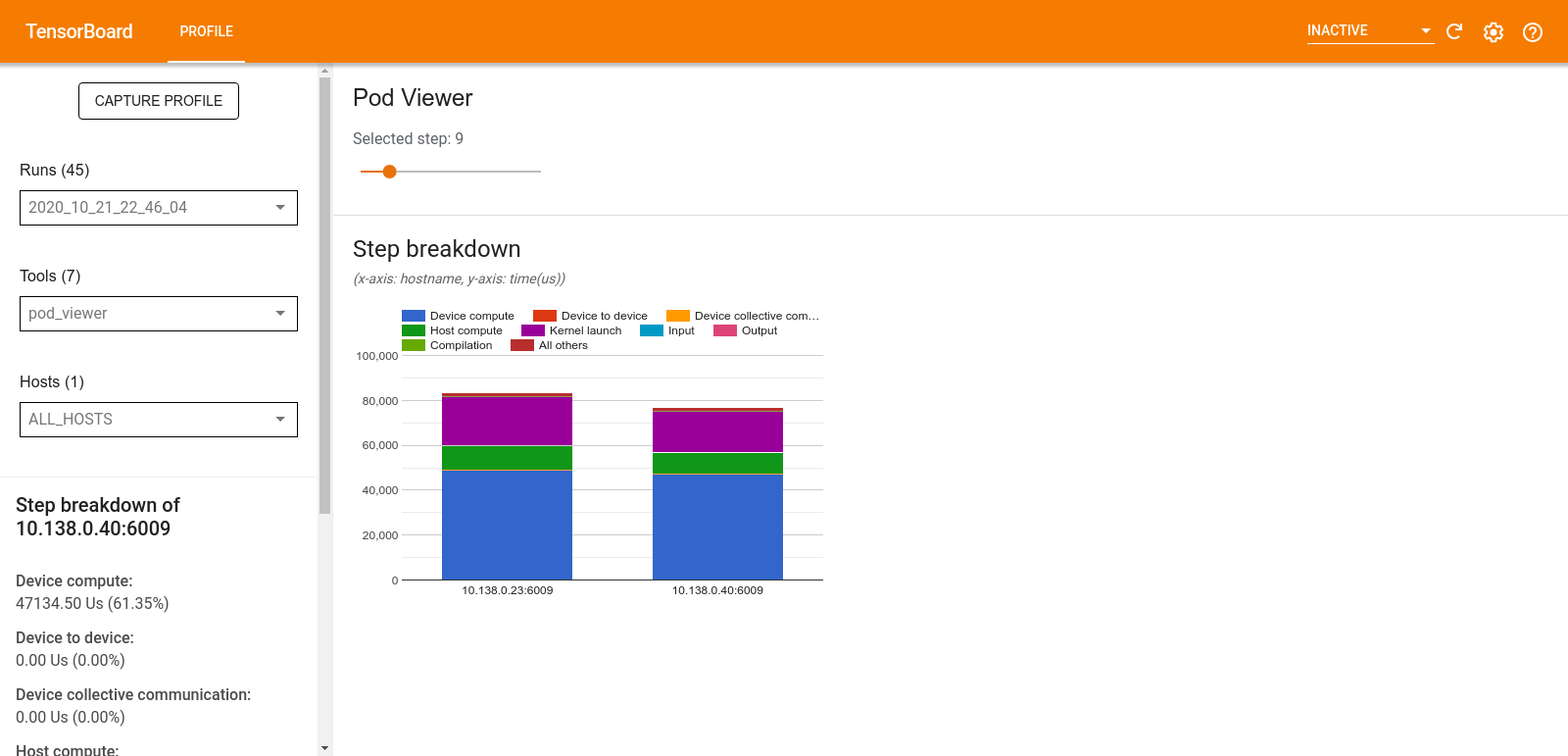
- El panel superior tiene un control deslizante para seleccionar el número de paso.
- El panel inferior muestra un gráfico de columnas apiladas. Esta es una vista de alto nivel de categorías de tiempos de pasos desglosadas colocadas una encima de otra. Cada columna apilada representa un trabajador único.
- Cuando pasa el cursor sobre una columna apilada, la tarjeta del lado izquierdo muestra más detalles sobre el desglose de los pasos.
análisis de cuello de botella de tf.data
La herramienta de análisis de cuellos de botella tf.data detecta automáticamente cuellos de botella en las canalizaciones de entrada tf.data en su programa y proporciona recomendaciones sobre cómo solucionarlos. Funciona con cualquier programa que utilice tf.data independientemente de la plataforma (CPU/GPU/TPU). Su análisis y recomendaciones se basan en esta guía .
Detecta un cuello de botella siguiendo estos pasos:
- Encuentre el host vinculado con mayor cantidad de entradas.
- Encuentre la ejecución más lenta de una canalización de entrada
tf.data. - Reconstruya el gráfico de canalización de entrada a partir del seguimiento del generador de perfiles.
- Encuentre la ruta crítica en el gráfico de canalización de entrada.
- Identificar la transformación más lenta en el camino crítico como cuello de botella.
La interfaz de usuario se divide en tres secciones: Resumen del análisis de rendimiento , Resumen de todas las canalizaciones de entrada y Gráfico de canalización de entrada .
Resumen del análisis de rendimiento

Esta sección proporciona el resumen del análisis. Informa sobre canalizaciones de entrada tf.data lentas detectadas en el perfil. Esta sección también muestra el host más vinculado a la entrada y su canal de entrada más lento con la latencia máxima. Lo más importante es que identifica qué parte del proceso de entrada es el cuello de botella y cómo solucionarlo. La información del cuello de botella se proporciona con el tipo de iterador y su nombre largo.
Cómo leer el nombre largo del iterador tf.data
Un nombre largo tiene el formato Iterator::<Dataset_1>::...::<Dataset_n> . En el nombre largo, <Dataset_n> coincide con el tipo de iterador y los otros conjuntos de datos en el nombre largo representan transformaciones posteriores.
Por ejemplo, considere el siguiente conjunto de datos de canalización de entrada:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
Los nombres largos de los iteradores del conjunto de datos anterior serán:
| Tipo de iterador | Nombre largo |
|---|---|
| Rango | Iterador::Lote::Repetir::Mapa::Rango |
| Mapa | Iterador::Lote::Repetir::Mapa |
| Repetir | Iterador::Lote::Repetir |
| Lote | Iterador::Lote |
Resumen de todos los canales de entrada
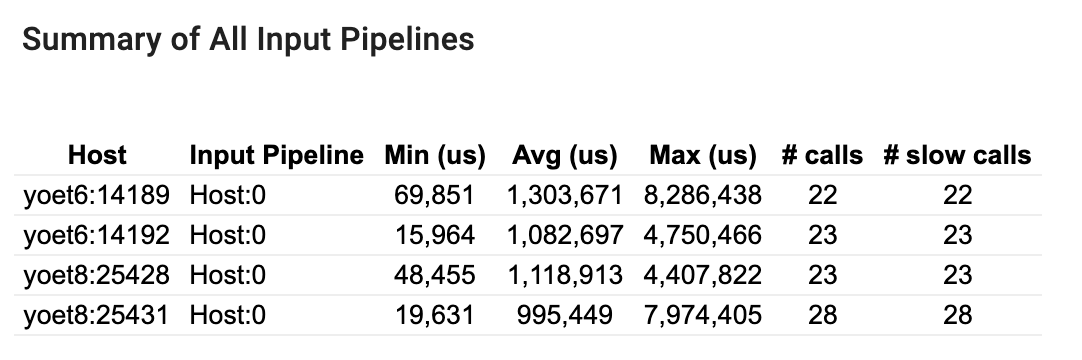
Esta sección proporciona el resumen de todas las canalizaciones de entrada en todos los hosts. Normalmente hay una canalización de entrada. Cuando se utiliza la estrategia de distribución, hay una canalización de entrada del host que ejecuta el código tf.data del programa y varias canalizaciones de entrada del dispositivo que recuperan datos de la canalización de entrada del host y los transfieren a los dispositivos.
Para cada canal de entrada, muestra las estadísticas de su tiempo de ejecución. Una llamada se considera lenta si dura más de 50 μs.
Gráfico de canalización de entrada

Esta sección muestra el gráfico de canalización de entrada con la información del tiempo de ejecución. Puede utilizar "Host" y "Input Pipeline" para elegir qué host y canal de entrada ver. Las ejecuciones de la canalización de entrada se clasifican según el tiempo de ejecución en orden descendente, que puede elegir mediante el menú desplegable Clasificación .
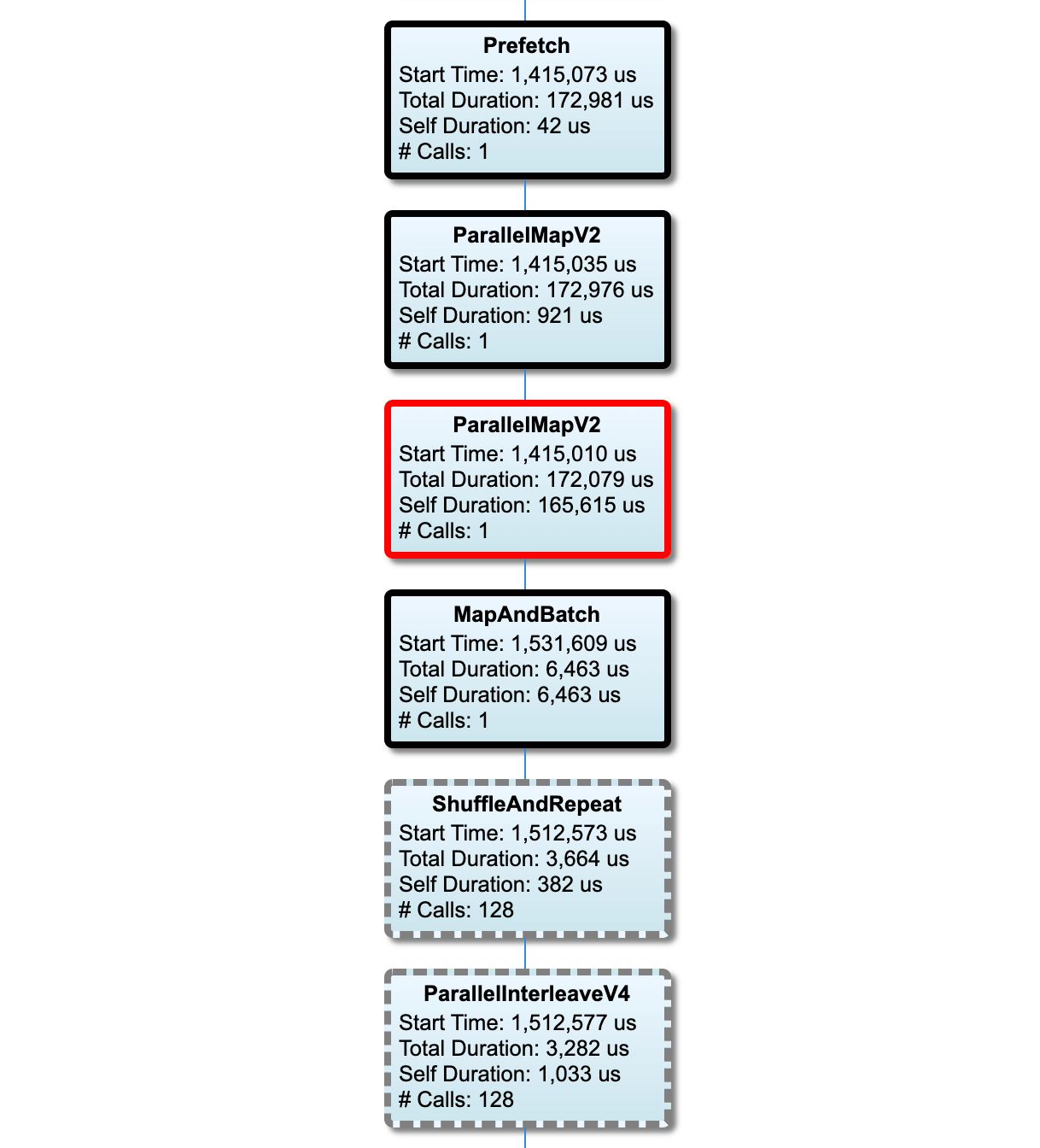
Los nodos de la ruta crítica tienen contornos en negrita. El nodo de cuello de botella, que es el nodo con el tiempo propio más largo en la ruta crítica, tiene un contorno rojo. Los otros nodos no críticos tienen contornos discontinuos grises.
En cada nodo, Start Time indica la hora de inicio de la ejecución. El mismo nodo se puede ejecutar varias veces, por ejemplo, si hay una operación Batch en la canalización de entrada. Si se ejecuta varias veces, es la hora de inicio de la primera ejecución.
La duración total es el tiempo de ejecución de la pared. Si se ejecuta varias veces, es la suma de los tiempos de pared de todas las ejecuciones.
El tiempo propio es el tiempo total sin el tiempo superpuesto con sus nodos secundarios inmediatos.
"# Llamadas" es la cantidad de veces que se ejecuta la canalización de entrada.
Recopilar datos de rendimiento
TensorFlow Profiler recopila actividades del host y seguimientos de GPU de su modelo de TensorFlow. Puede configurar Profiler para recopilar datos de rendimiento a través del modo programático o del modo de muestreo.
API de creación de perfiles
Puede utilizar las siguientes API para realizar la creación de perfiles.
Modo programático utilizando TensorBoard Keras Callback (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Modo programático utilizando la API de función
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Modo programático utilizando el administrador de contexto.
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Modo de muestreo: realice perfiles bajo demanda utilizando
tf.profiler.experimental.server.startpara iniciar un servidor gRPC con la ejecución del modelo de TensorFlow. Después de iniciar el servidor gRPC y ejecutar su modelo, puede capturar un perfil a través del botón Capturar perfil en el complemento de perfil de TensorBoard. Utilice el script en la sección Instalar perfilador anterior para iniciar una instancia de TensorBoard si aún no se está ejecutando.Como ejemplo,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Un ejemplo para perfilar a varios trabajadores:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
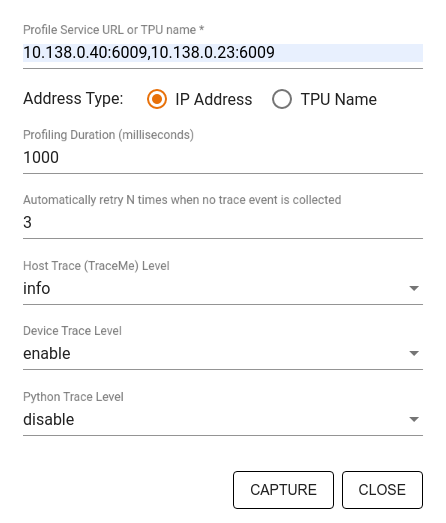
Utilice el cuadro de diálogo Capturar perfil para especificar:
- Una lista delimitada por comas de URL de servicios de perfil o nombres de TPU.
- Una duración de generación de perfiles.
- El nivel de seguimiento de llamadas a dispositivos, hosts y funciones de Python.
- Cuántas veces desea que Profiler vuelva a intentar capturar perfiles si no tuvo éxito al principio.
Creación de perfiles de bucles de entrenamiento personalizados
Para crear un perfil de bucles de entrenamiento personalizados en su código de TensorFlow, instrumente el bucle de entrenamiento con la API tf.profiler.experimental.Trace para marcar los límites de los pasos para Profiler.
El argumento name se utiliza como prefijo para los nombres de los pasos, el argumento de la palabra clave step_num se agrega a los nombres de los pasos y el argumento de la palabra clave _r hace que Profiler procese este evento de seguimiento como un evento de paso.
Como ejemplo,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Esto permitirá el análisis de rendimiento basado en pasos del Profiler y hará que los eventos de los pasos aparezcan en el visor de seguimiento.
Asegúrese de incluir el iterador del conjunto de datos dentro del contexto tf.profiler.experimental.Trace para un análisis preciso de la canalización de entrada.
El siguiente fragmento de código es un antipatrón:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Casos de uso de creación de perfiles
El generador de perfiles cubre una serie de casos de uso en cuatro ejes diferentes. Algunas de las combinaciones son actualmente compatibles y otras se agregarán en el futuro. Algunos de los casos de uso son:
- Creación de perfiles local frente a remota : estas son dos formas comunes de configurar su entorno de creación de perfiles. En la creación de perfiles local, la API de creación de perfiles se llama en la misma máquina que ejecuta su modelo, por ejemplo, una estación de trabajo local con GPU. En la creación de perfiles remota, la API de creación de perfiles se llama en una máquina diferente desde donde se ejecuta su modelo, por ejemplo, en una Cloud TPU.
- Creación de perfiles de varios trabajadores : puede crear perfiles de varias máquinas cuando utilice las capacidades de capacitación distribuida de TensorFlow.
- Plataforma de hardware : perfil de CPU, GPU y TPU.
La siguiente tabla proporciona una descripción general rápida de los casos de uso compatibles con TensorFlow mencionados anteriormente:
| API de creación de perfiles | Local | Remoto | Varios trabajadores | Plataformas de hardware |
|---|---|---|---|---|
| Devolución de llamada de TensorBoard Keras | Apoyado | No compatible | No compatible | CPU, GPU |
API de inicio/parada tf.profiler.experimental | Apoyado | No compatible | No compatible | CPU, GPU |
tf.profiler.experimental client.trace API | Apoyado | Apoyado | Apoyado | CPU, GPU, TPU |
| API de administrador de contexto | Apoyado | No compatible | No compatible | CPU, GPU |
Mejores prácticas para un rendimiento óptimo del modelo
Utilice las siguientes recomendaciones según corresponda para sus modelos de TensorFlow para lograr un rendimiento óptimo.
En general, realice todas las transformaciones en el dispositivo y asegúrese de utilizar la última versión compatible de bibliotecas como cuDNN e Intel MKL para su plataforma.
Optimice la canalización de datos de entrada
Utilice los datos del [#input_pipeline_analyzer] para optimizar su proceso de entrada de datos. Una canalización de entrada de datos eficiente puede mejorar drásticamente la velocidad de ejecución de su modelo al reducir el tiempo de inactividad del dispositivo. Intente incorporar las mejores prácticas detalladas en la guía Mejor rendimiento con la API tf.data y a continuación para hacer que su proceso de entrada de datos sea más eficiente.
En general, paralelizar cualquier operación que no necesite ejecutarse secuencialmente puede optimizar significativamente la canalización de entrada de datos.
En muchos casos, resulta útil cambiar el orden de algunas llamadas o ajustar los argumentos para que funcionen mejor para su modelo. Mientras optimiza la canalización de datos de entrada, compare solo el cargador de datos sin los pasos de entrenamiento y retropropagación para cuantificar el efecto de las optimizaciones de forma independiente.
Intente ejecutar su modelo con datos sintéticos para verificar si la canalización de entrada es un cuello de botella en el rendimiento.
Utilice
tf.data.Dataset.shardpara el entrenamiento con múltiples GPU. Asegúrese de fragmentar desde el principio del ciclo de entrada para evitar reducciones en el rendimiento. Cuando trabaje con TFRecords, asegúrese de fragmentar la lista de TFRecords y no el contenido de TFRecords.Paralelice varias operaciones estableciendo dinámicamente el valor de
num_parallel_callsusandotf.data.AUTOTUNE.Considere limitar el uso de
tf.data.Dataset.from_generator, ya que es más lento en comparación con las operaciones puras de TensorFlow.Considere limitar el uso de
tf.py_functionya que no se puede serializar y no se admite su ejecución en TensorFlow distribuido.Utilice
tf.data.Optionspara controlar las optimizaciones estáticas en la canalización de entrada.
Lea también la guía de análisis de rendimiento tf.data para obtener más orientación sobre cómo optimizar su canal de entrada.
Optimizar el aumento de datos
Cuando trabaje con datos de imágenes, haga que el aumento de datos sea más eficiente al convertirlos en diferentes tipos de datos después de aplicar transformaciones espaciales, como voltear, recortar, rotar, etc.
Utilice NVIDIA® DALI
En algunos casos, como cuando tiene un sistema con una alta proporción de GPU a CPU, es posible que todas las optimizaciones anteriores no sean suficientes para eliminar los cuellos de botella en el cargador de datos causados por las limitaciones de los ciclos de la CPU.
Si está utilizando GPU NVIDIA® para aplicaciones de aprendizaje profundo de audio y visión por computadora, considere usar la biblioteca de carga de datos ( DALI ) para acelerar la canalización de datos.
Consulte NVIDIA® DALI: documentación de operaciones para obtener una lista de operaciones DALI compatibles.
Utilice subprocesos y ejecución paralela
Ejecute operaciones en múltiples subprocesos de CPU con la API tf.config.threading para ejecutarlas más rápido.
TensorFlow establece automáticamente la cantidad de subprocesos de paralelismo de forma predeterminada. El grupo de subprocesos disponible para ejecutar operaciones de TensorFlow depende de la cantidad de subprocesos de CPU disponibles.
Controle la aceleración paralela máxima para una sola operación usando tf.config.threading.set_intra_op_parallelism_threads . Tenga en cuenta que si ejecuta varias operaciones en paralelo, todas compartirán el grupo de subprocesos disponible.
Si tiene operaciones independientes sin bloqueo (operaciones sin una ruta dirigida entre ellas en el gráfico), use tf.config.threading.set_inter_op_parallelism_threads para ejecutarlas simultáneamente usando el grupo de subprocesos disponible.
Misceláneas
Cuando trabaje con modelos más pequeños en GPU NVIDIA®, puede configurar tf.compat.v1.ConfigProto.force_gpu_compatible=True para forzar que todos los tensores de la CPU se asignen con memoria fija CUDA para brindar un impulso significativo al rendimiento del modelo. Sin embargo, tenga cuidado al utilizar esta opción para modelos desconocidos o muy grandes, ya que esto podría afectar negativamente al rendimiento del host (CPU).
Mejorar el rendimiento del dispositivo
Siga las mejores prácticas que se detallan aquí y en la guía de optimización del rendimiento de GPU para optimizar el rendimiento del modelo TensorFlow en el dispositivo.
Si está utilizando GPU NVIDIA, registre la GPU y la utilización de la memoria en un archivo CSV ejecutando:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
Configurar el diseño de datos
Cuando trabaje con datos que contengan información del canal (como imágenes), optimice el formato de diseño de datos para preferir los canales al final (NHWC sobre NCHW).
Los formatos de datos del último canal mejoran la utilización de Tensor Core y proporcionan mejoras de rendimiento significativas, especialmente en modelos convolucionales cuando se combinan con AMP. Tensor Cores aún puede operar los diseños de datos NCHW, pero introduce una sobrecarga adicional debido a las operaciones de transposición automática.
Puede optimizar el diseño de los datos para preferir los diseños NHWC configurando data_format="channels_last" para capas como tf.keras.layers.Conv2D , tf.keras.layers.Conv3D y tf.keras.layers.RandomRotation .
Utilice tf.keras.backend.set_image_data_format para configurar el formato de diseño de datos predeterminado para la API de backend de Keras.
Maximiza la caché L2
Cuando trabaje con GPU NVIDIA®, ejecute el siguiente fragmento de código antes del ciclo de entrenamiento para maximizar la granularidad de recuperación L2 a 128 bytes.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
Configurar el uso de subprocesos de GPU
El modo de subproceso de GPU decide cómo se utilizan los subprocesos de GPU.
Establezca el modo de subproceso en gpu_private para asegurarse de que el preprocesamiento no robe todos los hilos de GPU. Esto reducirá el retraso de lanzamiento del núcleo durante el entrenamiento. También puede establecer el número de hilos por GPU. Establezca estos valores utilizando variables de entorno.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
Configurar opciones de memoria de GPU
En general, aumente el tamaño del lote y escala el modelo para utilizar mejor las GPU y obtener un mayor rendimiento. Tenga en cuenta que aumentar el tamaño del lote cambiará la precisión del modelo, por lo que el modelo debe escalarse ajustando hiperparámetros como la tasa de aprendizaje para cumplir con la precisión del objetivo.
Además, use tf.config.experimental.set_memory_growth para permitir que la memoria GPU crezca para evitar que toda la memoria disponible se asigne completamente a OPS que requieren solo una fracción de la memoria. Esto permite que otros procesos que consumen memoria GPU se ejecuten en el mismo dispositivo.
Para obtener más información, consulte la guía limitante de crecimiento de la memoria de la GPU en la Guía de GPU para obtener más información.
Misceláneas
Aumente el tamaño de mini lote de entrenamiento (número de muestras de entrenamiento utilizadas por dispositivo en una iteración del bucle de entrenamiento) a la cantidad máxima que se ajusta sin un error fuera de memoria (OOM) en la GPU. El aumento del tamaño del lote impacta la precisión del modelo, así que asegúrese de escalar el modelo ajustando los hiperparámetros para cumplir con la precisión del objetivo.
Desactivar informes de errores OOM durante la asignación de tensor en el código de producción. Establecer
report_tensor_allocations_upon_oom=Falseentf.compat.v1.RunOptions.Para modelos con capas de convolución, elimine la adición de sesgo si usa la normalización por lotes. La normalización por lotes cambia los valores por su media y esto elimina la necesidad de tener un término de sesgo constante.
Use estadísticas de TF para averiguar qué tan eficientemente se ejecutan OPS en el dispositivo.
Use
tf.functionpara realizar cálculos y opcionalmente, habilite el flagadorjit_compile=True(tf.function(jit_compile=True). Para obtener más información, vaya a usar xla tf.function .Minimice las operaciones del host Python entre los pasos y reduzca las devoluciones de llamada. Calcule las métricas cada pocos pasos en lugar de en cada paso.
Mantenga las unidades de cómputo del dispositivo ocupadas.
Envíe datos a múltiples dispositivos en paralelo.
Considere el uso de representaciones numéricas de 16 bits , como
fp16, el formato de punto flotante de media precisión especificado por IEEE, o el formato BFLOAT16 de punto flotante del cerebro.
Recursos adicionales
- El tutorial de rendimiento de TensorFlow Profiler: Perfil Model con Keras y Tensorboard, donde puede aplicar los consejos en esta guía.
- El perfil de rendimiento en TensorFlow 2 habla de la cumbre de tensorflow Dev 2020.
- La demostración de TensorFlow Profiler de Tensorflow Dev Summit 2020.
Limitaciones conocidas
Perfilando múltiples GPU en TensorFlow 2.2 y TensorFlow 2.3
TensorFlow 2.2 y 2.3 admiten múltiples perfiles de GPU solo para sistemas de host único; No es compatible con múltiples perfiles de GPU para sistemas de múltiples huéspedes. Para perfilar configuraciones de GPU múltiples, cada trabajador debe ser perfilado de forma independiente. De TensorFlow 2.4 Se pueden perfilar varios trabajadores utilizando tf.profiler.experimental.client.trace API.
Se requiere CUDA® Toolkit 10.2 o posterior para perfilar múltiples GPU. Como TensorFlow 2.2 y 2.3 admiten versiones de kit de herramientas CUDA® solo hasta 10.1, debe crear enlaces simbólicos a libcudart.so.10.1 y libcupti.so.10.1 :
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1