
Questa guida illustra come utilizzare gli strumenti disponibili con TensorFlow Profiler per monitorare le prestazioni dei tuoi modelli TensorFlow. Imparerai come comprendere le prestazioni del tuo modello sull'host (CPU), sul dispositivo (GPU) o su una combinazione di host e dispositivi.
La profilazione aiuta a comprendere il consumo di risorse hardware (tempo e memoria) delle varie operazioni (ops) di TensorFlow nel modello e a risolvere i colli di bottiglia delle prestazioni e, in definitiva, a velocizzare l'esecuzione del modello.
Questa guida ti spiegherà come installare il Profiler, i vari strumenti disponibili, le diverse modalità con cui il Profiler raccoglie i dati sulle prestazioni e alcune best practice consigliate per ottimizzare le prestazioni del modello.
Se desideri profilare le prestazioni del tuo modello sui Cloud TPU, fai riferimento alla guida Cloud TPU .
Installa i prerequisiti Profiler e GPU
Installa il plugin Profiler per TensorBoard con pip. Tieni presente che Profiler richiede le versioni più recenti di TensorFlow e TensorBoard (>=2.2).
pip install -U tensorboard_plugin_profile
Per profilare sulla GPU è necessario:
- Soddisfa i driver GPU NVIDIA® e i requisiti CUDA® Toolkit elencati nei requisiti software di supporto GPU TensorFlow .
Assicurati che l' interfaccia degli strumenti di profilazione NVIDIA® CUDA® (CUPTI) esista nel percorso:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
Se non hai CUPTI nel percorso, anteponi la sua directory di installazione alla variabile di ambiente $LD_LIBRARY_PATH eseguendo:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
Quindi, esegui nuovamente il comando ldconfig sopra per verificare che la libreria CUPTI venga trovata.
Risolvere i problemi relativi ai privilegi
Quando esegui la profilazione con CUDA® Toolkit in un ambiente Docker o su Linux, potresti riscontrare problemi relativi a privilegi CUPTI insufficienti ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ). Vai alla documentazione per sviluppatori NVIDIA per ulteriori informazioni su come risolvere questi problemi su Linux.
Per risolvere i problemi relativi ai privilegi CUPTI in un ambiente Docker, esegui
docker run option '--privileged=true'
Strumenti del profilatore
Accedi al Profiler dalla scheda Profilo in TensorBoard, che appare solo dopo aver acquisito alcuni dati del modello.
Il Profiler dispone di una selezione di strumenti che aiutano nell'analisi delle prestazioni:
- Pagina Panoramica
- Analizzatore della pipeline di input
- Statistiche TensorFlow
- Visualizzatore di tracce
- Statistiche del kernel GPU
- Strumento di profilo della memoria
- Visualizzatore pod
Pagina Panoramica
La pagina di panoramica fornisce una visualizzazione di primo livello delle prestazioni del modello durante l'esecuzione del profilo. La pagina mostra una pagina di panoramica aggregata per il tuo host e tutti i dispositivi e alcuni consigli per migliorare le prestazioni di addestramento del modello. Puoi anche selezionare singoli host nel menu a discesa Host.
La pagina di panoramica visualizza i dati come segue:
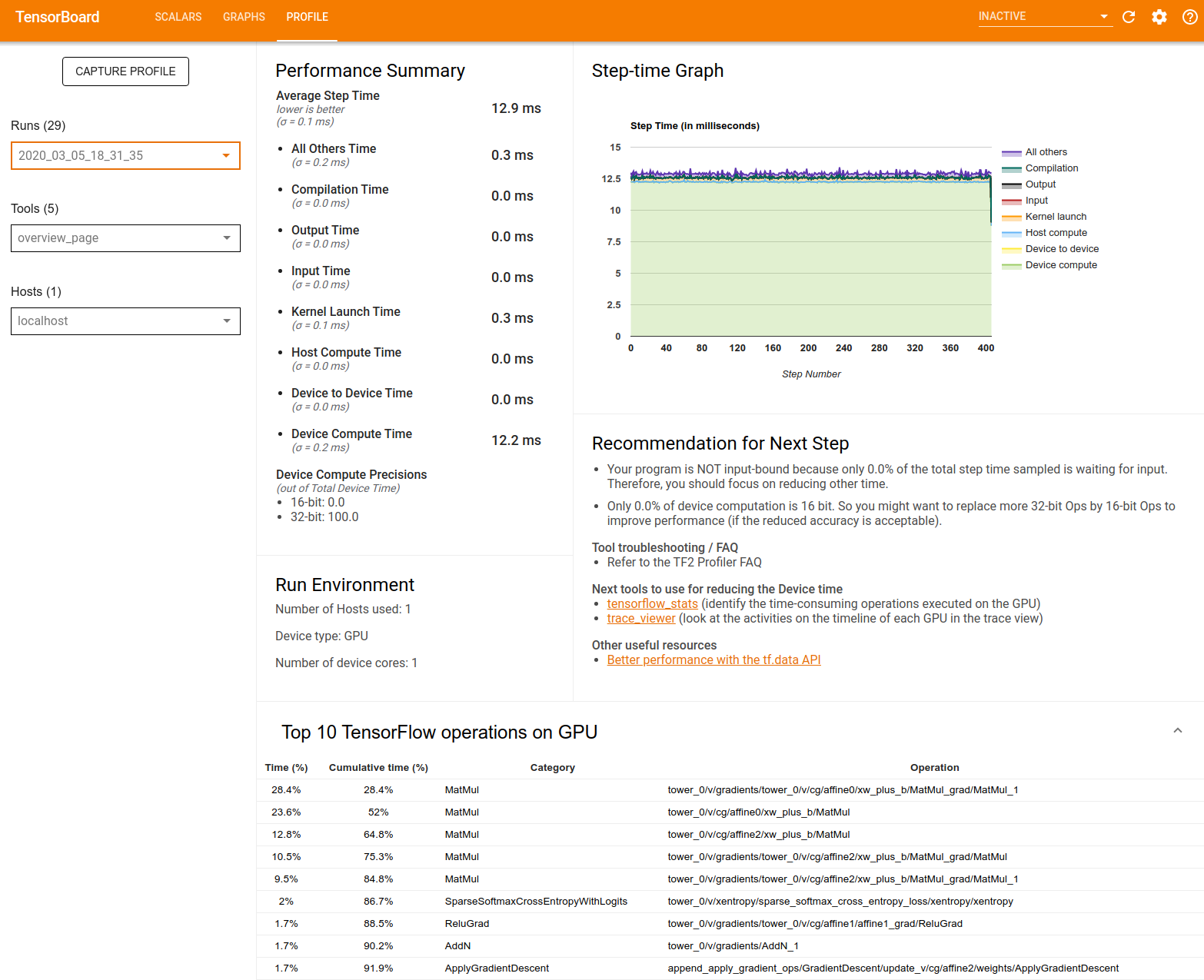
Riepilogo delle prestazioni : visualizza un riepilogo di alto livello delle prestazioni del modello. Il riepilogo delle prestazioni è composto da due parti:
Suddivisione del tempo del passo: suddivide il tempo medio del passo in più categorie in cui viene trascorso il tempo:
- Compilazione: tempo impiegato per compilare i kernel.
- Input: tempo impiegato nella lettura dei dati di input.
- Output: tempo impiegato nella lettura dei dati di output.
- Lancio del kernel: tempo impiegato dall'host per avviare i kernel
- Tempo di calcolo dell'host..
- Tempo di comunicazione da dispositivo a dispositivo.
- Tempo di calcolo sul dispositivo.
- Tutti gli altri, incluso il sovraccarico di Python.
Precisioni di calcolo del dispositivo: segnala la percentuale del tempo di calcolo del dispositivo che utilizza calcoli a 16 e 32 bit.
Grafico del tempo di passaggio : visualizza un grafico del tempo di passaggio del dispositivo (in millisecondi) su tutti i passaggi campionati. Ogni passaggio è suddiviso nelle molteplici categorie (con colori diversi) in cui viene trascorso il tempo. L'area rossa corrisponde alla porzione di tempo in cui i dispositivi sono rimasti inattivi in attesa dei dati di input dall'host. L'area verde mostra per quanto tempo il dispositivo ha effettivamente funzionato.
Le 10 principali operazioni TensorFlow sul dispositivo (ad esempio GPU) : mostra le operazioni sul dispositivo che sono state eseguite più a lungo.
Ogni riga visualizza il tempo personale di un'operazione (come percentuale di tempo impiegato da tutte le operazioni), il tempo cumulativo, la categoria e il nome.
Ambiente di esecuzione : visualizza un riepilogo di alto livello dell'ambiente di esecuzione del modello, incluso:
- Numero di host utilizzati.
- Tipo di dispositivo (GPU/TPU).
- Numero di core del dispositivo.
Raccomandazione per il passaggio successivo : segnala quando un modello viene associato all'input e consiglia gli strumenti che è possibile utilizzare per individuare e risolvere i colli di bottiglia delle prestazioni del modello.
Analizzatore di pipeline di ingresso
Quando un programma TensorFlow legge i dati da un file, inizia nella parte superiore del grafico TensorFlow in modo pipeline. Il processo di lettura è suddiviso in più fasi di elaborazione dati collegate in serie, dove l'output di una fase costituisce l'input per quella successiva. Questo sistema di lettura dei dati è chiamato pipeline di input .
Una tipica pipeline per la lettura di record da file prevede le seguenti fasi:
- Lettura del fascicolo.
- Preelaborazione dei file (facoltativa).
- Trasferimento di file dall'host al dispositivo.
Una pipeline di input inefficiente può rallentare gravemente la tua applicazione. Un'applicazione viene considerata vincolata all'input quando trascorre una parte significativa di tempo nella pipeline di input. Utilizza le informazioni ottenute dall'analizzatore della pipeline di input per comprendere i punti in cui la pipeline di input è inefficiente.
L'analizzatore della pipeline di input ti dice immediatamente se il tuo programma è vincolato all'input e ti guida attraverso l'analisi lato dispositivo e host per eseguire il debug dei colli di bottiglia delle prestazioni in qualsiasi fase della pipeline di input.
Controlla le indicazioni sulle prestazioni della pipeline di input per le best practice consigliate per ottimizzare le pipeline di input dei dati.
Dashboard della pipeline di input
Per aprire l'analizzatore della pipeline di input, seleziona Profile , quindi seleziona input_pipeline_analyzer dal menu a discesa Strumenti .
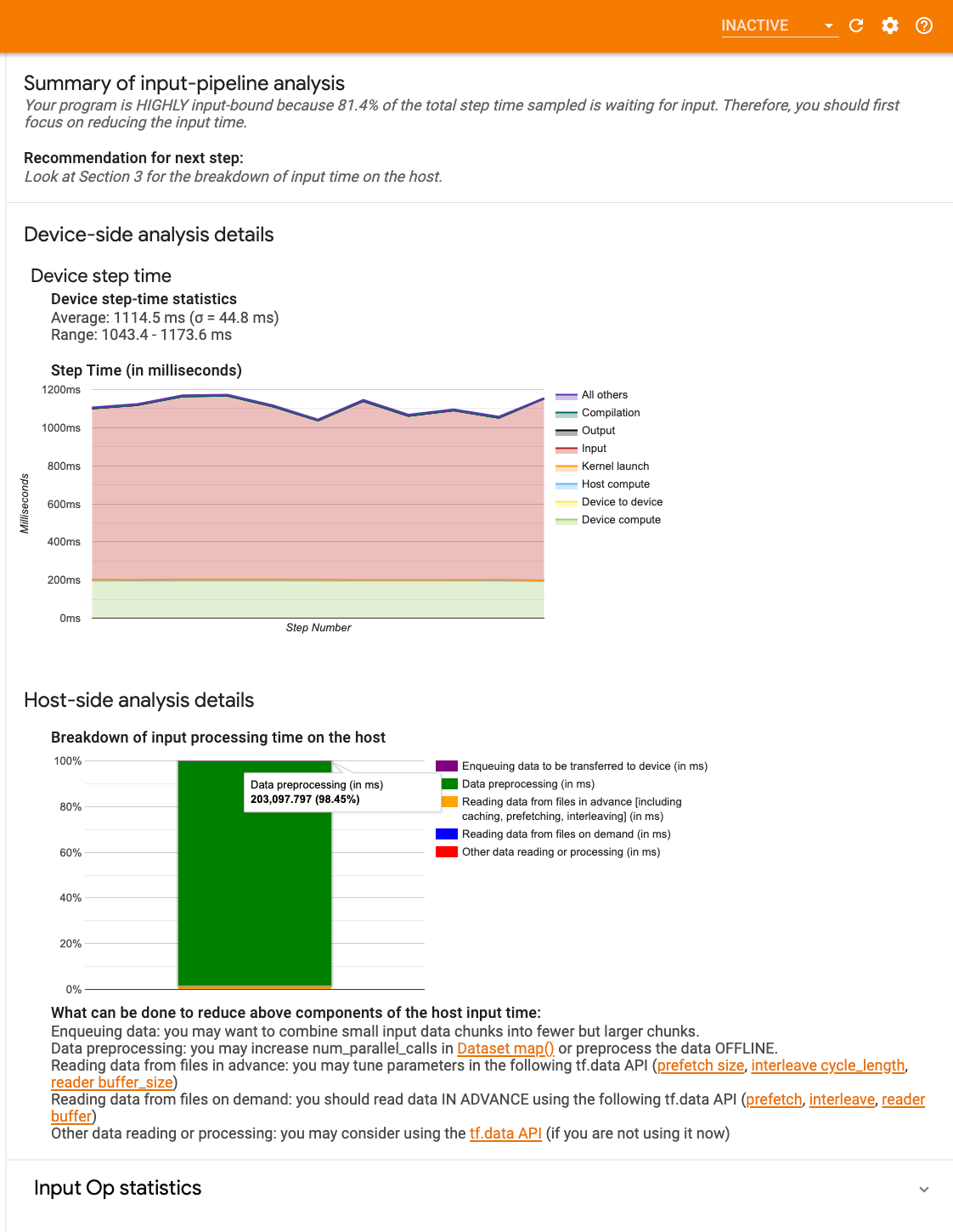
La dashboard contiene tre sezioni:
- Riepilogo : riepiloga la pipeline di input complessiva con informazioni sull'eventuale vincolo di input dell'applicazione e, in tal caso, in che misura.
- Analisi lato dispositivo : visualizza risultati dettagliati dell'analisi lato dispositivo, inclusi il tempo di passaggio del dispositivo e l'intervallo di tempo trascorso dal dispositivo in attesa dei dati di input tra i core in ogni passaggio.
- Analisi lato host : mostra un'analisi dettagliata sul lato host, inclusa una suddivisione del tempo di elaborazione dell'input sull'host.
Riepilogo della pipeline di input
Il Riepilogo segnala se il tuo programma è vincolato all'input presentando la percentuale di tempo del dispositivo impiegato nell'attesa dell'input dall'host. Se si utilizza una pipeline di input standard dotata di strumenti, lo strumento segnala dove viene impiegata la maggior parte del tempo di elaborazione dell'input.
Analisi lato dispositivo
L'analisi lato dispositivo fornisce informazioni dettagliate sul tempo trascorso sul dispositivo rispetto all'host e sulla quantità di tempo trascorso dal dispositivo in attesa dei dati di input dall'host.
- Tempo del passo tracciato rispetto al numero del passo : visualizza un grafico del tempo del passo del dispositivo (in millisecondi) su tutti i passi campionati. Ogni passaggio è suddiviso nelle molteplici categorie (con colori diversi) in cui viene trascorso il tempo. L'area rossa corrisponde alla porzione di tempo in cui i dispositivi sono rimasti inattivi in attesa dei dati di input dall'host. L'area verde mostra per quanto tempo il dispositivo ha effettivamente funzionato.
- Statistiche del tempo del passo : riporta la media, la deviazione standard e l'intervallo ([minimo, massimo]) del tempo del passo del dispositivo.
Analisi lato host
L'analisi lato host riporta una suddivisione del tempo di elaborazione dell'input (il tempo impiegato per le operazioni API tf.data ) sull'host in diverse categorie:
- Lettura dei dati dai file su richiesta : tempo impiegato nella lettura dei dati dai file senza memorizzazione nella cache, precaricamento e interleaving.
- Lettura anticipata dei dati dai file : tempo impiegato nella lettura dei file, inclusi memorizzazione nella cache, precaricamento e interleaving.
- Preelaborazione dei dati : tempo impiegato nelle operazioni di preelaborazione, come la decompressione delle immagini.
- Accodamento dei dati da trasferire al dispositivo : tempo impiegato per inserire i dati in una coda di alimentazione prima di trasferirli al dispositivo.
Espandi Statistiche operazioni di input per esaminare le statistiche per le singole operazioni di input e le relative categorie suddivise per tempo di esecuzione.
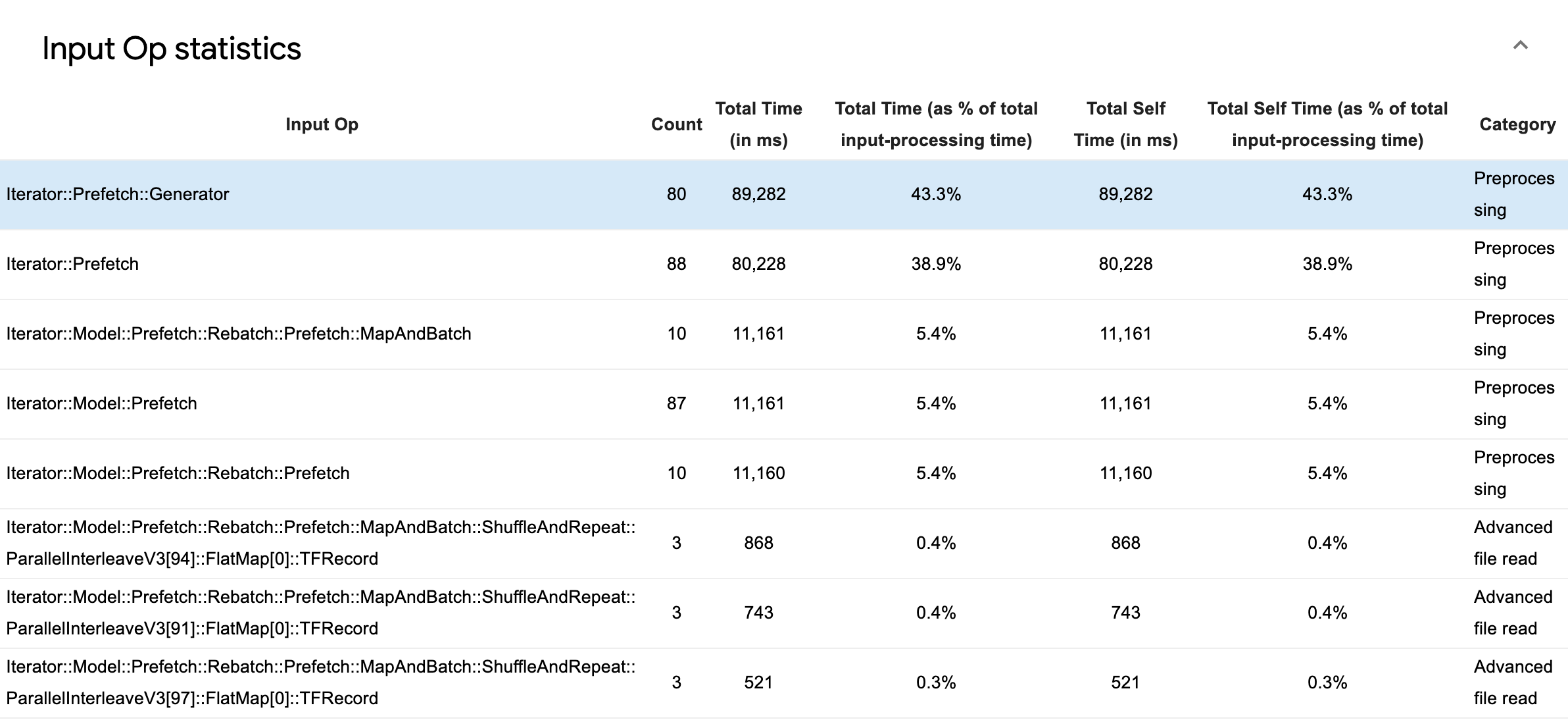
Verrà visualizzata una tabella di dati di origine con ciascuna voce contenente le seguenti informazioni:
- Input Op : mostra il nome dell'operazione TensorFlow dell'operazione di input.
- Conteggio : mostra il numero totale di istanze di esecuzione op durante il periodo di profilazione.
- Tempo totale (in ms) : mostra la somma cumulativa del tempo trascorso su ciascuna di queste istanze.
- % tempo totale : mostra il tempo totale impiegato in un'operazione come frazione del tempo totale impiegato nell'elaborazione dell'input.
- Tempo personale totale (in ms) : mostra la somma cumulativa del tempo personale trascorso su ciascuna di queste istanze. Il tempo personale qui misura il tempo trascorso all'interno del corpo della funzione, escluso il tempo trascorso nella funzione che chiama.
- Tempo personale totale% . Mostra il tempo personale totale come frazione del tempo totale impiegato nell'elaborazione dell'input.
- Categoria . Mostra la categoria di elaborazione dell'input op.
Statistiche di TensorFlow
Lo strumento TensorFlow Stats mostra le prestazioni di ogni operazione (operazione) TensorFlow eseguita sull'host o sul dispositivo durante una sessione di profilazione.
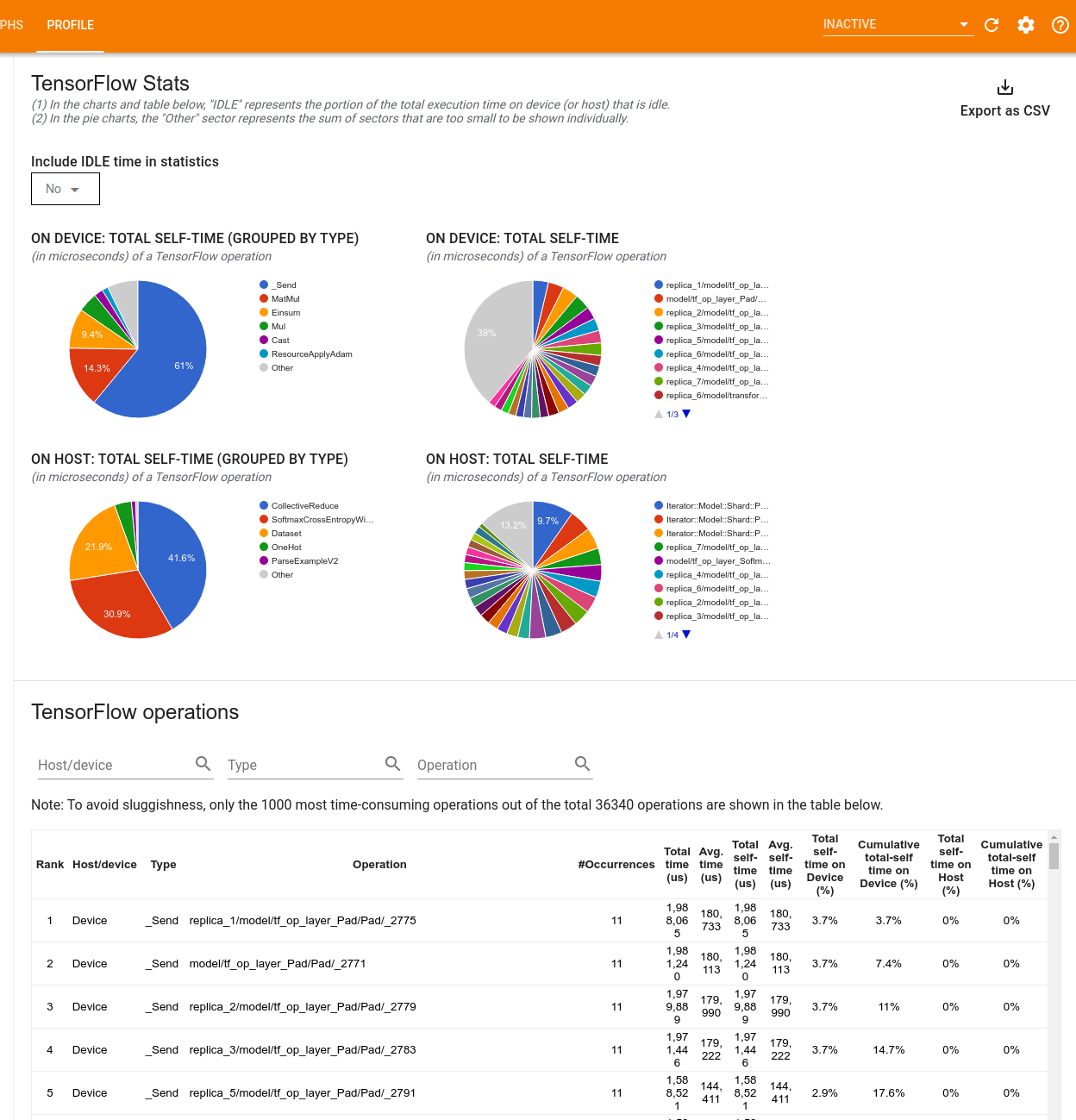
Lo strumento visualizza le informazioni sulle prestazioni in due riquadri:
Il riquadro superiore visualizza fino a quattro grafici a torta:
- La distribuzione del tempo di autoesecuzione di ciascuna operazione sull'host.
- La distribuzione del tempo di autoesecuzione di ciascun tipo di operazione sull'host.
- La distribuzione del tempo di autoesecuzione di ciascuna operazione sul dispositivo.
- La distribuzione del tempo di autoesecuzione di ciascun tipo di operazione sul dispositivo.
Il riquadro inferiore mostra una tabella che riporta i dati sulle operazioni TensorFlow con una riga per ciascuna operazione e una colonna per ciascun tipo di dati (ordina le colonne facendo clic sull'intestazione della colonna). Fare clic sul pulsante Esporta come CSV sul lato destro del riquadro superiore per esportare i dati da questa tabella come file CSV.
Notare che:
Se qualche operazione ha operazioni secondarie:
- Il tempo totale "accumulato" di un'operazione include il tempo trascorso all'interno delle operazioni secondarie.
- Il tempo "auto" totale di un'operazione non include il tempo trascorso all'interno delle operazioni secondarie.
Se un'operazione viene eseguita sull'host:
- La percentuale del tempo personale totale sul dispositivo derivante dall'operazione sarà 0.
- La percentuale cumulativa del tempo personale totale sul dispositivo fino a questa operazione inclusa sarà 0.
Se un'operazione viene eseguita sul dispositivo:
- La percentuale del tempo personale totale sull'host sostenuto da questa operazione sarà 0.
- La percentuale cumulativa del tempo personale totale sull'host fino a questa operazione inclusa sarà 0.
Puoi scegliere di includere o escludere il tempo di inattività nei grafici a torta e nella tabella.
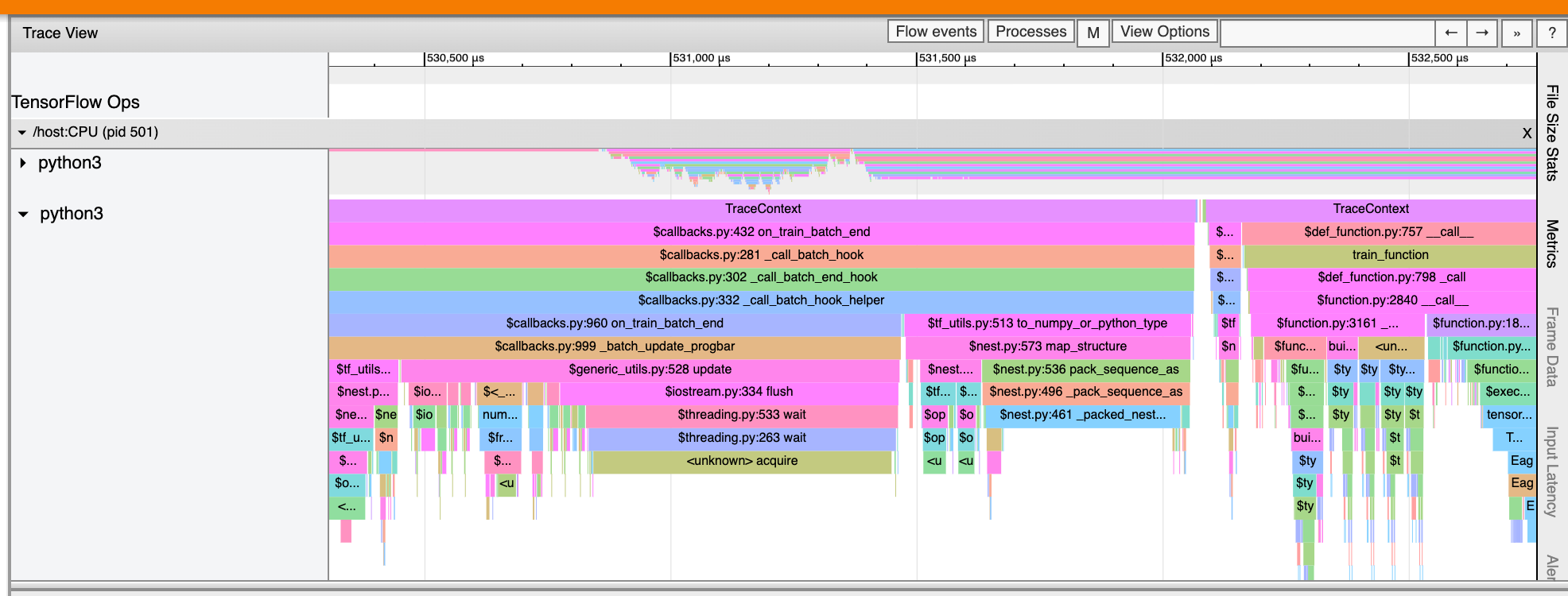
Visualizzatore di tracce
Il visualizzatore di tracce visualizza una sequenza temporale che mostra:
- Durate delle operazioni eseguite dal tuo modello TensorFlow
- Quale parte del sistema (host o dispositivo) ha eseguito un'operazione. In genere, l'host esegue operazioni di input, preelabora i dati di addestramento e li trasferisce al dispositivo, mentre il dispositivo esegue l'effettivo addestramento del modello
Il visualizzatore di tracce consente di identificare i problemi di prestazioni nel modello e quindi adottare misure per risolverli. Ad esempio, a un livello elevato, è possibile identificare se l'addestramento dell'input o del modello richiede la maggior parte del tempo. Eseguendo il drill-down, puoi identificare quali operazioni richiedono più tempo per essere eseguite. Tieni presente che il visualizzatore di tracce è limitato a 1 milione di eventi per dispositivo.
Interfaccia del visualizzatore di tracce
Quando apri il visualizzatore di tracce, viene visualizzato l'esecuzione più recente:
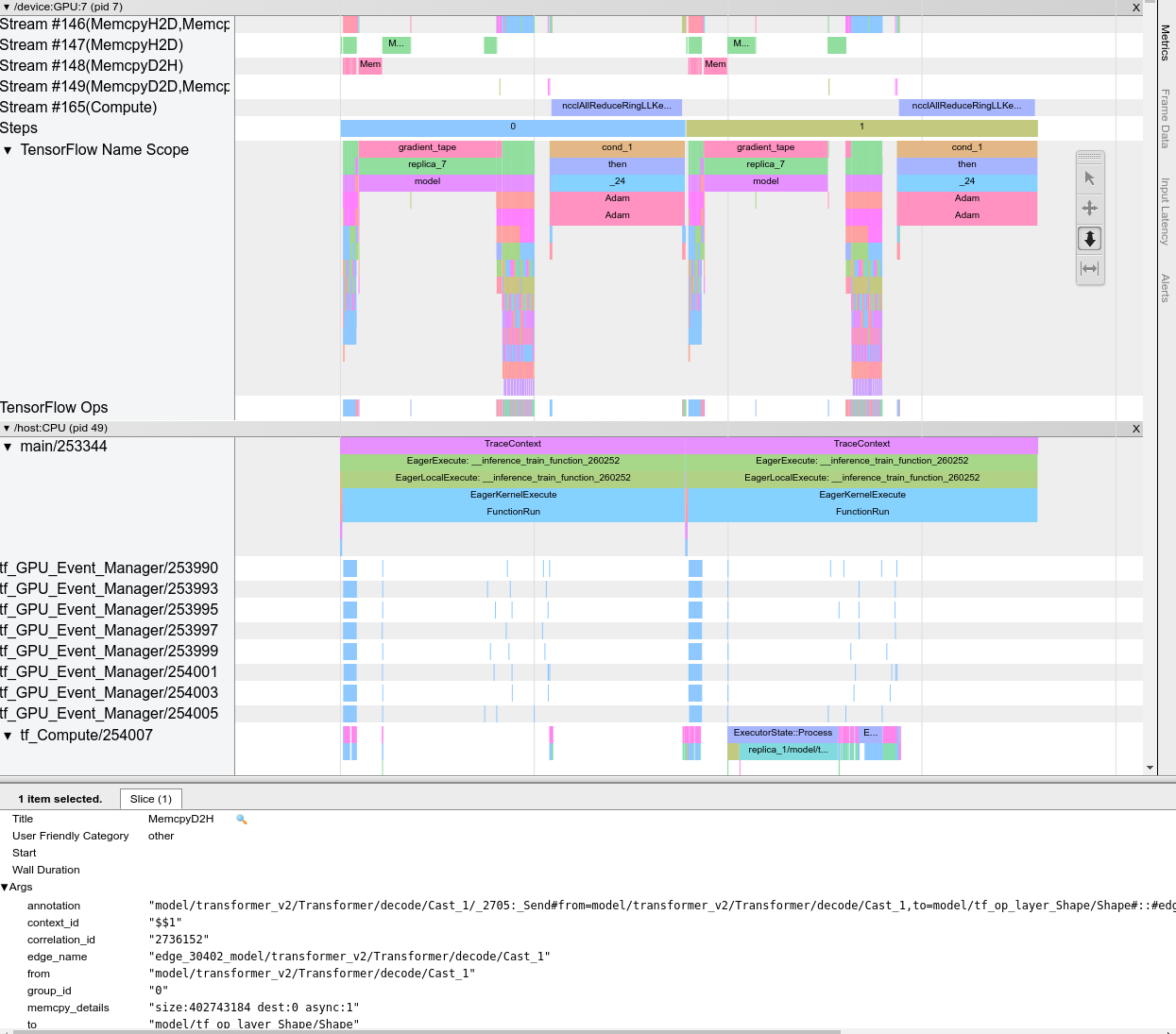
Questa schermata contiene i seguenti elementi principali:
- Riquadro sequenza temporale : mostra le operazioni eseguite dal dispositivo e dall'host nel tempo.
- Riquadro dei dettagli : mostra informazioni aggiuntive per le operazioni selezionate nel riquadro Timeline.
Il riquadro Timeline contiene i seguenti elementi:
- Barra superiore : contiene vari controlli ausiliari.
- Asse temporale : mostra il tempo relativo all'inizio della traccia.
- Etichette di sezioni e tracce : ogni sezione contiene più tracce e ha un triangolo sulla sinistra su cui puoi fare clic per espandere e comprimere la sezione. Esiste una sezione per ogni elemento di elaborazione nel sistema.
- Selettore strumenti : contiene vari strumenti per interagire con il visualizzatore di tracce come Zoom, Panoramica, Seleziona e Temporizzazione. Utilizzare lo strumento Timing per contrassegnare un intervallo di tempo.
- Eventi : mostrano il tempo durante il quale è stata eseguita un'operazione o la durata dei meta-eventi, come le fasi di addestramento.
Sezioni e tracce
Il visualizzatore di tracce contiene le seguenti sezioni:
- Una sezione per ciascun nodo del dispositivo , etichettata con il numero del chip del dispositivo e il nodo del dispositivo all'interno del chip (ad esempio,
/device:GPU:0 (pid 0)). Ciascuna sezione del nodo del dispositivo contiene le seguenti tracce:- Fase : mostra la durata delle fasi di allenamento in esecuzione sul dispositivo
- TensorFlow Ops : mostra le operazioni eseguite sul dispositivo
- Operazioni XLA : mostra le operazioni (op) XLA eseguite sul dispositivo se XLA è il compilatore utilizzato (ogni operazione TensorFlow viene tradotta in una o più operazioni XLA. Il compilatore XLA traduce le operazioni XLA in codice eseguito sul dispositivo).
- Una sezione per i thread in esecuzione sulla CPU del computer host, denominata "Host Threads" . La sezione contiene una traccia per ciascun thread della CPU. Tieni presente che puoi ignorare le informazioni visualizzate accanto alle etichette delle sezioni.
Eventi
Gli eventi all'interno della sequenza temporale vengono visualizzati in diversi colori; i colori stessi non hanno un significato specifico.
Il visualizzatore di tracce può anche visualizzare tracce di chiamate di funzioni Python nel tuo programma TensorFlow. Se utilizzi l'API tf.profiler.experimental.start , puoi abilitare la traccia Python utilizzando ProfilerOptions namedtuple all'avvio della profilazione. In alternativa, se si utilizza la modalità di campionamento per la profilazione, è possibile selezionare il livello di tracciamento utilizzando le opzioni a discesa nella finestra di dialogo Acquisisci profilo .
Statistiche del kernel GPU
Questo strumento mostra le statistiche sulle prestazioni e l'operazione di origine per ogni kernel accelerato dalla GPU.
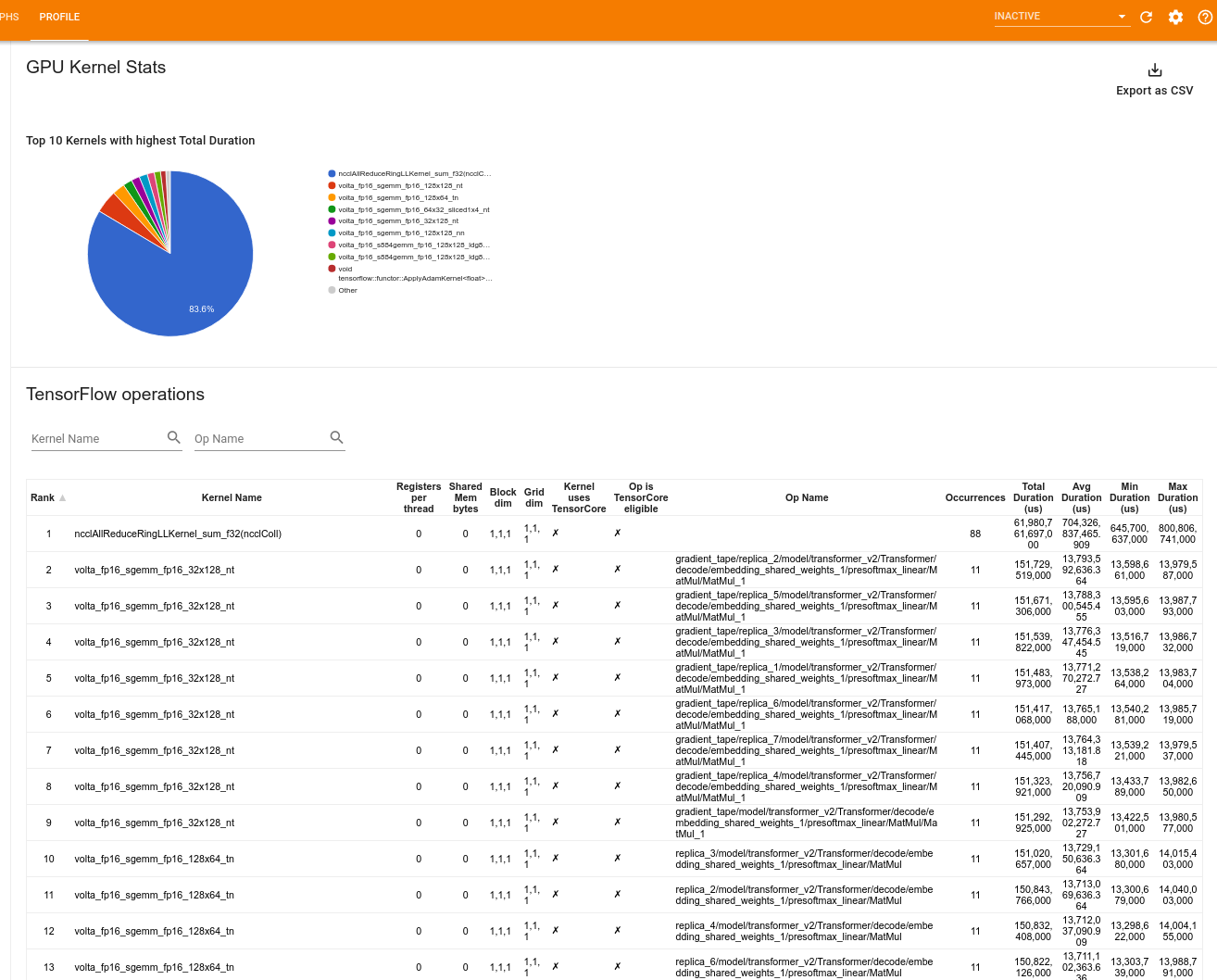
Lo strumento visualizza le informazioni in due riquadri:
Il riquadro superiore visualizza un grafico a torta che mostra i kernel CUDA con il tempo totale trascorso più elevato.
Il riquadro inferiore visualizza una tabella con i seguenti dati per ciascuna coppia univoca kernel-op:
- Una classifica in ordine decrescente della durata totale trascorsa della GPU raggruppata per coppia kernel-op.
- Il nome del kernel avviato.
- Il numero di registri GPU utilizzati dal kernel.
- La dimensione totale della memoria condivisa (statica + condivisa dinamica) utilizzata in byte.
- La dimensione del blocco espressa come
blockDim.x, blockDim.y, blockDim.z. - Le dimensioni della griglia espresse come
gridDim.x, gridDim.y, gridDim.z. - Se l'operazione è idonea a utilizzare Tensor Core .
- Se il kernel contiene istruzioni Tensor Core.
- Il nome dell'operazione che ha lanciato questo kernel.
- Il numero di occorrenze di questa coppia kernel-op.
- Il tempo totale trascorso della GPU in microsecondi.
- Il tempo medio trascorso della GPU in microsecondi.
- Il tempo minimo trascorso della GPU in microsecondi.
- Il tempo massimo trascorso dalla GPU in microsecondi.
Strumento per il profilo della memoria
Lo strumento Profilo memoria monitora l'utilizzo della memoria del dispositivo durante l'intervallo di profilazione. Puoi utilizzare questo strumento per:
- Eseguire il debug dei problemi di memoria insufficiente (OOM) individuando i picchi di utilizzo della memoria e l'allocazione di memoria corrispondente alle operazioni TensorFlow. È inoltre possibile eseguire il debug dei problemi di OOM che potrebbero verificarsi quando si esegue l'inferenza multi-tenancy .
- Eseguire il debug dei problemi di frammentazione della memoria.
Lo strumento profilo memoria visualizza i dati in tre sezioni:
- Riepilogo del profilo di memoria
- Grafico della sequenza temporale della memoria
- Tabella di ripartizione della memoria
Riepilogo del profilo di memoria
Questa sezione visualizza un riepilogo di alto livello del profilo di memoria del tuo programma TensorFlow come mostrato di seguito:

Il riepilogo del profilo di memoria ha sei campi:
- ID memoria : menu a discesa che elenca tutti i sistemi di memoria del dispositivo disponibili. Seleziona il sistema di memoria che desideri visualizzare dal menu a discesa.
- #Allocation : il numero di allocazioni di memoria effettuate durante l'intervallo di profilazione.
- #Deallocation : il numero di deallocazioni di memoria nell'intervallo di profilazione
- Capacità di memoria : la capacità totale (in GiB) del sistema di memoria selezionato.
- Utilizzo massimo dell'heap : utilizzo massimo della memoria (in GiB) dall'avvio dell'esecuzione del modello.
- Utilizzo massimo della memoria : utilizzo massimo della memoria (in GiB) nell'intervallo di profilazione. Questo campo contiene i seguenti sottocampi:
- Timestamp : il timestamp di quando si è verificato il picco di utilizzo della memoria nel grafico della sequenza temporale.
- Prenotazione dello stack : quantità di memoria riservata nello stack (in GiB).
- Allocazione heap : quantità di memoria allocata sull'heap (in GiB).
- Memoria libera : quantità di memoria libera (in GiB). La capacità di memoria è la somma totale della prenotazione dello stack, dell'allocazione dell'heap e della memoria libera.
- Frammentazione : la percentuale di frammentazione (più bassa è meglio). Viene calcolato come percentuale di
(1 - Size of the largest chunk of free memory / Total free memory).
Grafico della sequenza temporale della memoria
Questa sezione visualizza un grafico dell'utilizzo della memoria (in GiB) e la percentuale di frammentazione rispetto al tempo (in ms).
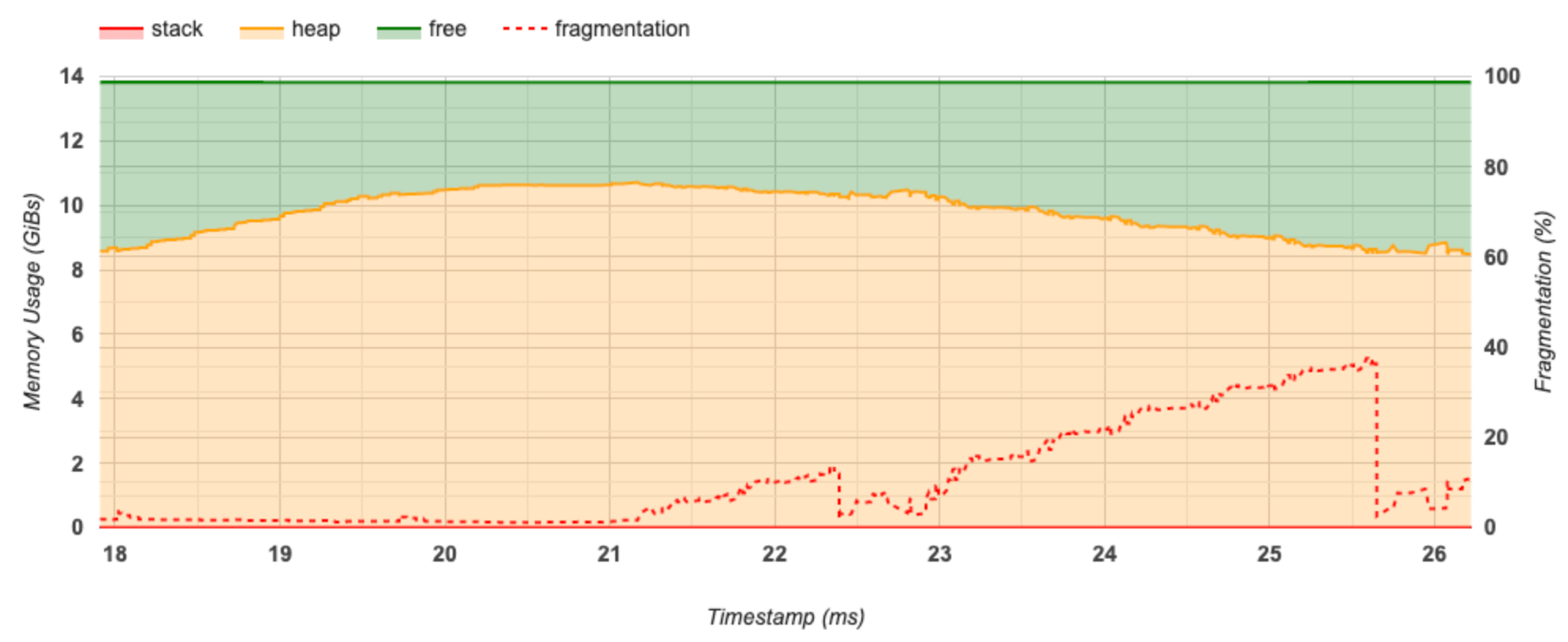
L'asse X rappresenta la sequenza temporale (in ms) dell'intervallo di profilazione. L'asse Y a sinistra rappresenta l'utilizzo della memoria (in GiB) e l'asse Y a destra rappresenta la percentuale di frammentazione. In ogni momento sull'asse X, la memoria totale è suddivisa in tre categorie: stack (in rosso), heap (in arancione) e libera (in verde). Passa il mouse sopra un timestamp specifico per visualizzare i dettagli sugli eventi di allocazione/deallocazione della memoria in quel punto, come di seguito:
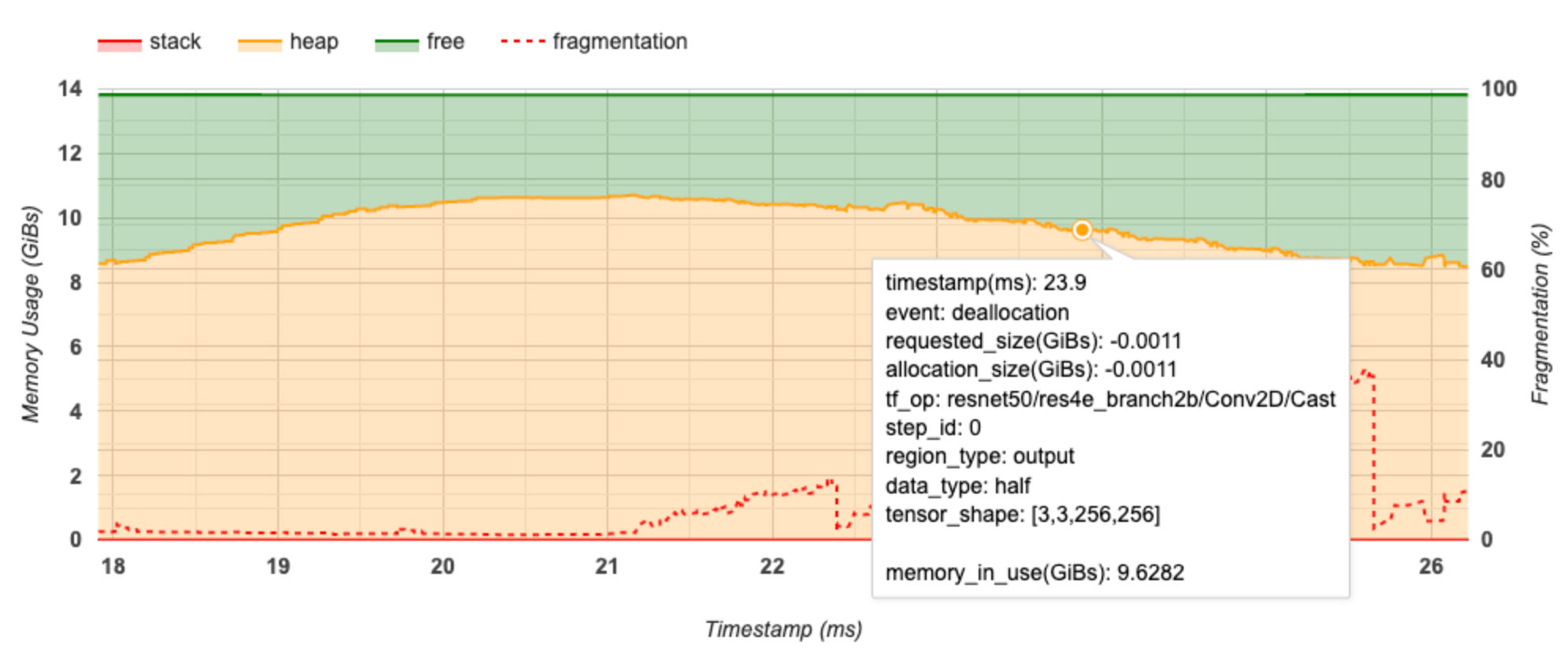
La finestra pop-up visualizza le seguenti informazioni:
- timestamp(ms) : la posizione dell'evento selezionato sulla timeline.
- evento : il tipo di evento (allocazione o deallocazione).
- request_size(GiBs) : la quantità di memoria richiesta. Questo sarà un numero negativo per gli eventi di deallocazione.
- allocation_size(GiBs) : la quantità effettiva di memoria allocata. Questo sarà un numero negativo per gli eventi di deallocazione.
- tf_op : l'operazione TensorFlow che richiede l'allocazione/deallocazione.
- step_id : la fase di training in cui si è verificato questo evento.
- regional_type : il tipo di entità dati a cui è destinata la memoria allocata. I valori possibili sono
tempper temporanei,outputper attivazioni e gradienti epersist/dynamicper pesi e costanti. - data_type : il tipo di elemento tensore (ad esempio, uint8 per un intero senza segno a 8 bit).
- tensor_shape : la forma del tensore da allocare/deallocare.
- memory_in_use(GiBs) : la memoria totale in uso in questo momento.
Tabella di suddivisione della memoria
Questa tabella mostra le allocazioni di memoria attive nel punto di picco di utilizzo della memoria nell'intervallo di profilazione.
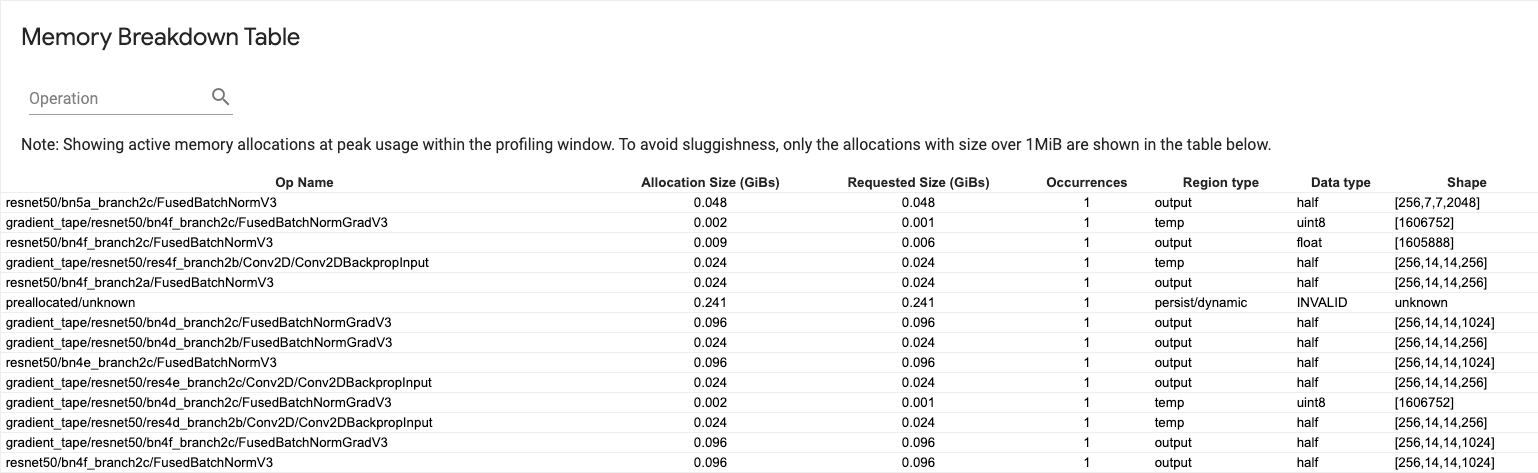
Esiste una riga per ciascuna operazione TensorFlow e ogni riga ha le seguenti colonne:
- Op Name : il nome dell'operazione TensorFlow.
- Dimensione allocazione (GiB) : la quantità totale di memoria allocata a questa operazione.
- Dimensione richiesta (GiB) : la quantità totale di memoria richiesta per questa operazione.
- Occorrenze : il numero di assegnazioni per questa op.
- Tipo di regione : il tipo di entità dati a cui è destinata la memoria allocata. I valori possibili sono
tempper temporanei,outputper attivazioni e gradienti epersist/dynamicper pesi e costanti. - Tipo di dati : il tipo di elemento tensore.
- Forma : la forma dei tensori allocati.
Visualizzatore pod
Lo strumento Pod Viewer mostra la suddivisione di una fase di formazione tra tutti i lavoratori.
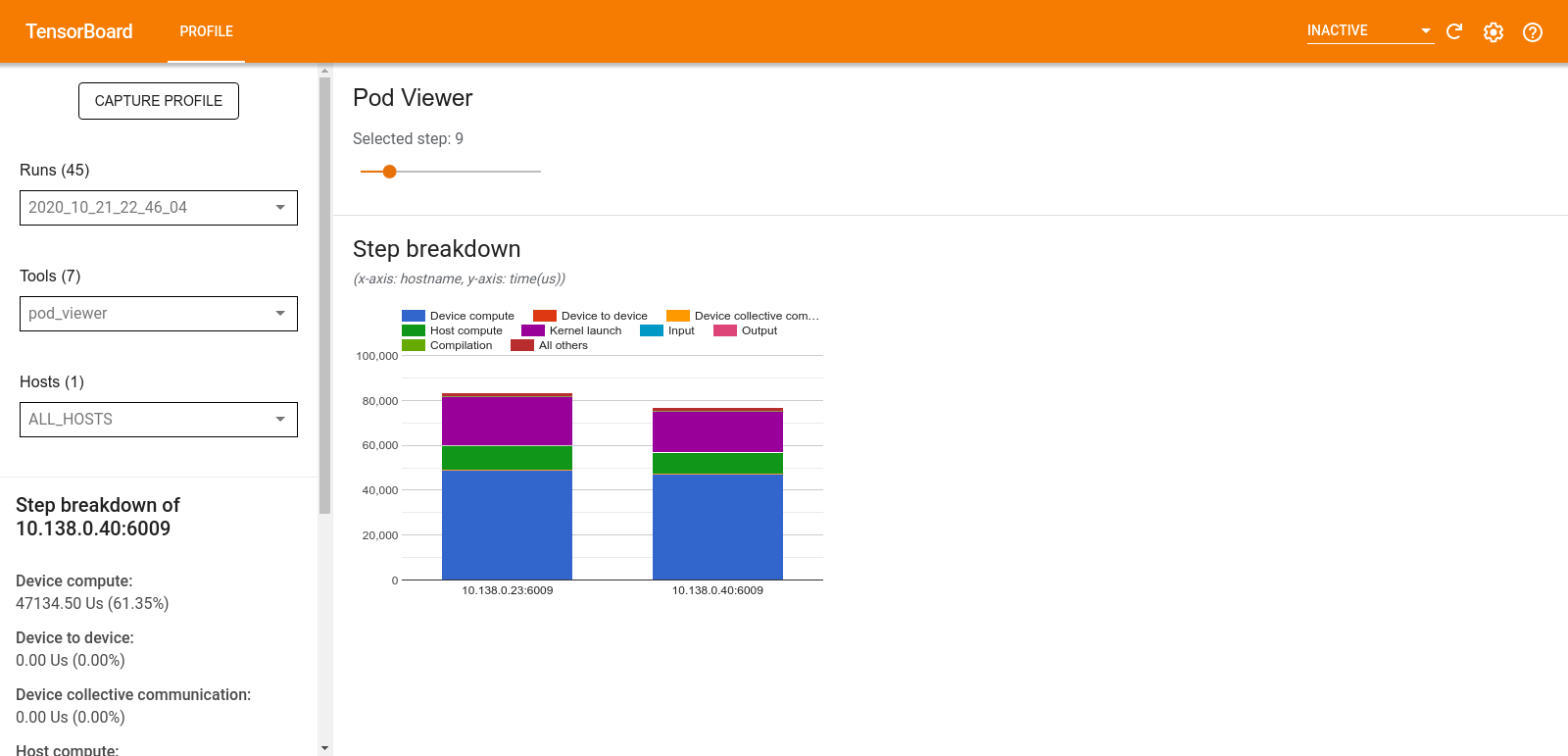
- Il riquadro superiore dispone di un dispositivo di scorrimento per la selezione del numero del passaggio.
- Il riquadro inferiore visualizza un istogramma in pila. Questa è una visualizzazione di alto livello delle categorie passo-tempo suddivise e posizionate una sopra l'altra. Ogni colonna in pila rappresenta un lavoratore unico.
- Quando passi il mouse su una colonna in pila, la scheda sul lato sinistro mostra maggiori dettagli sulla suddivisione dei passaggi.
analisi del collo di bottiglia tf.data
Lo strumento di analisi dei colli di bottiglia tf.data rileva automaticamente i colli di bottiglia nelle pipeline di input tf.data nel tuo programma e fornisce consigli su come risolverli. Funziona con qualsiasi programma che utilizza tf.data indipendentemente dalla piattaforma (CPU/GPU/TPU). Le sue analisi e raccomandazioni si basano su questa guida .
Rileva un collo di bottiglia seguendo questi passaggi:
- Trova l'host associato al maggior numero di input.
- Trova l'esecuzione più lenta di una pipeline di input
tf.data. - Ricostruire il grafico della pipeline di input dalla traccia del profiler.
- Trova il percorso critico nel grafico della pipeline di input.
- Identificare la trasformazione più lenta sul percorso critico come collo di bottiglia.
L'interfaccia utente è divisa in tre sezioni: Riepilogo dell'analisi delle prestazioni , Riepilogo di tutte le pipeline di input e Grafico della pipeline di input .
Riepilogo dell'analisi delle prestazioni

In questa sezione viene fornita la sintesi dell'analisi. Segnala le pipeline di input tf.data lente rilevate nel profilo. Questa sezione mostra anche l'host con il maggior numero di input e la relativa pipeline di input più lenta con la latenza massima. Ancora più importante, identifica quale parte della pipeline di input costituisce il collo di bottiglia e come risolverlo. Le informazioni sul collo di bottiglia vengono fornite con il tipo di iteratore e il relativo nome lungo.
Come leggere il nome lungo dell'iteratore tf.data
Un nome lungo è formattato come Iterator::<Dataset_1>::...::<Dataset_n> . Nel nome lungo, <Dataset_n> corrisponde al tipo di iteratore e gli altri set di dati nel nome lungo rappresentano trasformazioni downstream.
Ad esempio, considera il seguente set di dati della pipeline di input:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
I nomi lunghi per gli iteratori del set di dati sopra saranno:
| Tipo di iteratore | Nome lungo |
|---|---|
| Allineare | Iteratore::Batch::Ripeti::Mappa::Intervallo |
| Mappa | Iteratore::Batch::Ripeti::Mappa |
| Ripetere | Iteratore::Batch::Ripeti |
| Lotto | Iteratore::Batch |
Riepilogo di tutte le pipeline di input
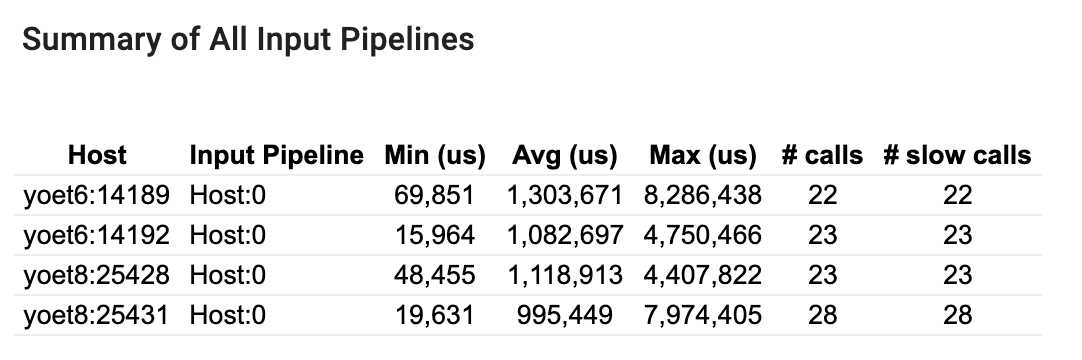
Questa sezione fornisce il riepilogo di tutte le pipeline di input su tutti gli host. In genere è presente una pipeline di input. Quando si utilizza la strategia di distribuzione, è presente una pipeline di input dell'host che esegue il codice tf.data del programma e più pipeline di input del dispositivo che recuperano i dati dalla pipeline di input dell'host e li trasferiscono ai dispositivi.
Per ogni pipeline di input, mostra le statistiche del suo tempo di esecuzione. Una chiamata viene considerata lenta se dura più di 50 μs.
Grafico della pipeline di input

Questa sezione mostra il grafico della pipeline di input con le informazioni sul tempo di esecuzione. Puoi utilizzare "Host" e "Pipeline di input" per scegliere quale host e pipeline di input visualizzare. Le esecuzioni della pipeline di input vengono ordinate in base al tempo di esecuzione in ordine decrescente che puoi scegliere utilizzando il menu a discesa Classifica .
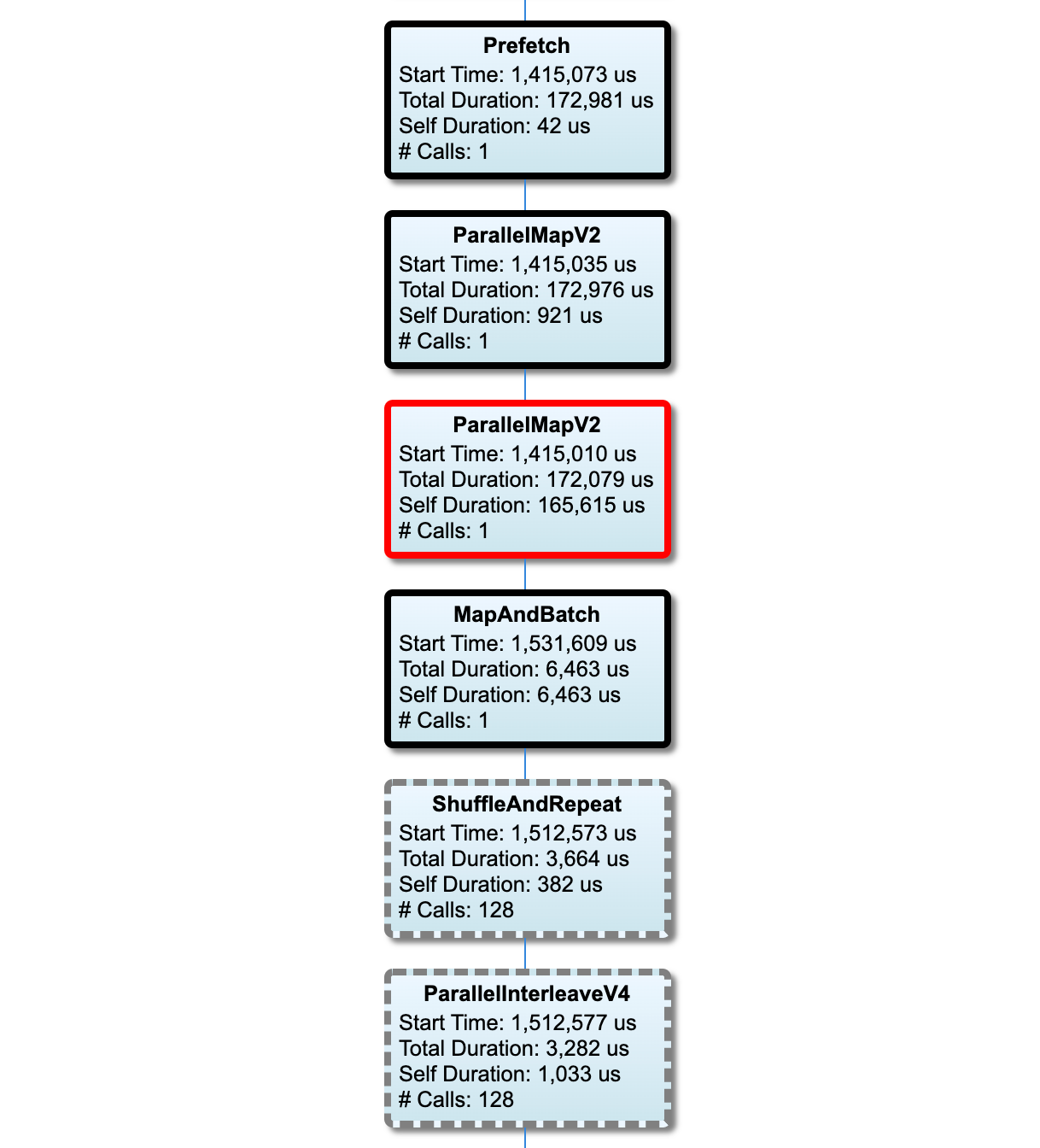
I nodi del percorso critico hanno contorni netti. Il nodo del collo di bottiglia, che è il nodo con il tempo autonomo più lungo sul percorso critico, ha un contorno rosso. Gli altri nodi non critici hanno contorni tratteggiati grigi.
In ciascun nodo, Start Time indica l'ora di inizio dell'esecuzione. Lo stesso nodo può essere eseguito più volte, ad esempio, se è presente un'operazione Batch nella pipeline di input. Se viene eseguito più volte, è l'ora di inizio della prima esecuzione.
La Durata Totale è il tempo limite dell'esecuzione. Se viene eseguito più volte, è la somma dei tempi di tutte le esecuzioni.
Il tempo personale è il tempo totale senza il tempo sovrapposto con i suoi nodi figlio immediati.
"# Calls" è il numero di volte in cui viene eseguita la pipeline di input.
Raccogliere dati sulle prestazioni
TensorFlow Profiler raccoglie le attività dell'host e le tracce GPU del tuo modello TensorFlow. È possibile configurare il Profiler per raccogliere dati sulle prestazioni tramite la modalità programmatica o la modalità di campionamento.
API di profilazione
È possibile utilizzare le seguenti API per eseguire la profilazione.
Modalità programmatica utilizzando TensorBoard Keras Callback (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Modalità programmatica utilizzando l'API della funzione
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Modalità programmatica utilizzando il gestore del contesto
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Modalità di campionamento: esegui la profilazione su richiesta utilizzando
tf.profiler.experimental.server.startper avviare un server gRPC con l'esecuzione del modello TensorFlow. Dopo aver avviato il server gRPC ed eseguito il modello, puoi acquisire un profilo tramite il pulsante Acquisisci profilo nel plug-in del profilo TensorBoard. Utilizza lo script nella sezione Installa profiler qui sopra per avviare un'istanza TensorBoard se non è già in esecuzione.Ad esempio,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Un esempio per la profilazione di più lavoratori:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)

Utilizzare la finestra di dialogo Profilo di acquisizione per specificare:
- Un elenco delimitato da virgole di URL del servizio profilo o nomi TPU.
- Una durata della profilazione.
- Il livello di tracciamento delle chiamate al dispositivo, all'host e alla funzione Python.
- Quante volte vuoi che Profiler riprovi ad acquisire i profili se inizialmente non ha avuto successo.
Profilazione di cicli di formazione personalizzati
Per profilare i cicli di addestramento personalizzati nel tuo codice TensorFlow, strumenti il ciclo di addestramento con l'API tf.profiler.experimental.Trace per contrassegnare i limiti dei passaggi per il Profiler.
L'argomento name viene utilizzato come prefisso per i nomi dei passaggi, l'argomento della parola chiave step_num viene aggiunto ai nomi dei passaggi e l'argomento della parola chiave _r fa sì che questo evento di traccia venga elaborato come evento del passaggio dal Profiler.
Ad esempio,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Ciò consentirà l'analisi delle prestazioni basata sui passaggi del Profiler e farà sì che gli eventi dei passaggi vengano visualizzati nel visualizzatore di tracce.
Assicurati di includere l'iteratore del set di dati nel contesto tf.profiler.experimental.Trace per un'analisi accurata della pipeline di input.
Lo snippet di codice seguente è un anti-pattern:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Profilazione dei casi d'uso
Il profiler copre una serie di casi d'uso lungo quattro assi diversi. Alcune combinazioni sono attualmente supportate e altre verranno aggiunte in futuro. Alcuni dei casi d'uso sono:
- Profilazione locale e remota : questi sono due modi comuni per impostare l'ambiente di profilazione. Nella profilazione locale, l'API di profilazione viene richiamata sulla stessa macchina eseguita dal modello, ad esempio una workstation locale con GPU. Nella profilazione remota, l'API di profilazione viene richiamata su un computer diverso da quello su cui è in esecuzione il modello, ad esempio su un Cloud TPU.
- Profilazione di più lavoratori : puoi profilare più macchine quando utilizzi le funzionalità di formazione distribuita di TensorFlow.
- Piattaforma hardware : CPU, GPU e TPU del profilo.
La tabella seguente fornisce una rapida panoramica dei casi d'uso supportati da TensorFlow menzionati sopra:
| API di profilazione | Locale | Remoto | Più lavoratori | Piattaforme hardware |
|---|---|---|---|---|
| Richiamata TensorBoard Keras | Supportato | Non supportato | Non supportato | Processore, GPU |
API di avvio/arresto tf.profiler.experimental | Supportato | Non supportato | Non supportato | Processore, GPU |
API tf.profiler.experimental client.trace | Supportato | Supportato | Supportato | Processore, GPU, TPU |
| API del gestore contesto | Supportato | Non supportato | Non supportato | Processore, GPU |
Best practice per prestazioni ottimali del modello
Utilizza i seguenti consigli applicabili ai tuoi modelli TensorFlow per ottenere prestazioni ottimali.
In generale, esegui tutte le trasformazioni sul dispositivo e assicurati di utilizzare la versione compatibile più recente di librerie come cuDNN e Intel MKL per la tua piattaforma.
Ottimizza la pipeline dei dati di input
Utilizza i dati di [#input_pipeline_analyzer] per ottimizzare la pipeline di input dei dati. Una pipeline di input dati efficiente può migliorare drasticamente la velocità di esecuzione del modello riducendo i tempi di inattività del dispositivo. Prova a incorporare le best practice dettagliate nella guida Migliorare le prestazioni con l'API tf.data e di seguito per rendere più efficiente la pipeline di input dei dati.
In generale, parallelizzare qualsiasi operazione che non necessita di essere eseguita in sequenza può ottimizzare in modo significativo la pipeline di input dei dati.
In molti casi, è utile modificare l'ordine di alcune chiamate o ottimizzare gli argomenti in modo che funzionino meglio per il proprio modello. Durante l'ottimizzazione della pipeline dei dati di input, esegui il benchmark solo del caricatore di dati senza le fasi di training e backpropagation per quantificare l'effetto delle ottimizzazioni in modo indipendente.
Prova a eseguire il tuo modello con dati sintetici per verificare se la pipeline di input rappresenta un collo di bottiglia delle prestazioni.
Utilizza
tf.data.Dataset.shardper l'addestramento multi-GPU. Assicurati di effettuare lo sharding molto presto nel ciclo di input per evitare riduzioni del throughput. Quando lavori con TFRecords, assicurati di partizionare l'elenco di TFRecords e non il contenuto di TFRecords.Parallelizza diverse operazioni impostando dinamicamente il valore di
num_parallel_callsutilizzandotf.data.AUTOTUNE.Valuta la possibilità di limitare l'utilizzo di
tf.data.Dataset.from_generatorpoiché è più lento rispetto alle operazioni TensorFlow pure.Considera la possibilità di limitare l'utilizzo di
tf.py_functionpoiché non può essere serializzato e non è supportato per l'esecuzione in TensorFlow distribuito.Utilizza
tf.data.Optionsper controllare le ottimizzazioni statiche nella pipeline di input.
Leggi anche la guida all'analisi delle prestazioni tf.data per ulteriori indicazioni sull'ottimizzazione della pipeline di input.
Ottimizza l'aumento dei dati
Quando lavori con dati di immagine, rendi più efficiente l'aumento dei dati eseguendo il casting su diversi tipi di dati dopo aver applicato trasformazioni spaziali, come capovolgimento, ritaglio, rotazione, ecc.
Utilizza NVIDIA® DALI
In alcuni casi, ad esempio quando si dispone di un sistema con un elevato rapporto GPU/CPU, tutte le ottimizzazioni di cui sopra potrebbero non essere sufficienti per eliminare i colli di bottiglia nel caricatore dati causati dalle limitazioni dei cicli della CPU.
Se utilizzi GPU NVIDIA® per applicazioni di visione artificiale e deep learning audio, prendi in considerazione l'utilizzo della libreria di caricamento dati ( DALI ) per accelerare la pipeline dei dati.
Consulta la documentazione NVIDIA® DALI: Operations per un elenco delle operazioni DALI supportate.
Utilizzare il threading e l'esecuzione parallela
Esegui operazioni su più thread della CPU con l'API tf.config.threading per eseguirle più velocemente.
TensorFlow imposta automaticamente il numero di thread di parallelismo per impostazione predefinita. Il pool di thread disponibile per l'esecuzione delle operazioni TensorFlow dipende dal numero di thread della CPU disponibili.
Controlla la velocità parallela massima per una singola operazione utilizzando tf.config.threading.set_intra_op_parallelism_threads . Tieni presente che se esegui più operazioni in parallelo, tutte condivideranno il pool di thread disponibile.
Se disponi di operazioni indipendenti non bloccanti (operazioni senza percorso diretto tra loro sul grafico), utilizza tf.config.threading.set_inter_op_parallelism_threads per eseguirle contemporaneamente utilizzando il pool di thread disponibile.
Varie
Quando lavori con modelli più piccoli su GPU NVIDIA®, puoi impostare tf.compat.v1.ConfigProto.force_gpu_compatible=True per forzare l'allocazione di tutti i tensori della CPU con la memoria bloccata CUDA per dare un incremento significativo alle prestazioni del modello. Tuttavia, prestare attenzione quando si utilizza questa opzione per modelli sconosciuti/molto grandi poiché ciò potrebbe avere un impatto negativo sulle prestazioni dell'host (CPU).
Migliora le prestazioni del dispositivo
Segui le best practice dettagliate qui e nella guida all'ottimizzazione delle prestazioni della GPU per ottimizzare le prestazioni del modello TensorFlow sul dispositivo.
Se utilizzi GPU NVIDIA, registra l'utilizzo della GPU e della memoria in un file CSV eseguendo:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
Configurare il layout dei dati
Quando si lavora con dati che contengono informazioni sul canale (come immagini), ottimizzare il formato del layout dei dati per preferire i canali per ultimi (NHWC rispetto a NCHW).
I formati di dati Channel-last migliorano l'utilizzo di Tensor Core e forniscono miglioramenti significativi delle prestazioni soprattutto nei modelli convoluzionali se abbinati ad AMP. I layout dei dati NCHW possono ancora essere gestiti dai Tensor Core, ma introducono un sovraccarico aggiuntivo a causa delle operazioni di trasposizione automatica.
È possibile ottimizzare il layout dei dati per preferire i layout NHWC impostando data_format="channels_last" per layer come tf.keras.layers.Conv2D , tf.keras.layers.Conv3D e tf.keras.layers.RandomRotation .
Utilizza tf.keras.backend.set_image_data_format per impostare il formato di layout dei dati predefinito per l'API backend Keras.
Massimizza la cache L2
Quando lavori con le GPU NVIDIA®, esegui lo snippet di codice riportato di seguito prima del ciclo di training per massimizzare la granularità di recupero L2 a 128 byte.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
Configura l'utilizzo del thread GPU
La modalità thread GPU decide come vengono utilizzati i thread GPU.
Impostare la modalità thread su gpu_private per assicurarsi che la preelaborazione non rubhi tutti i thread GPU. Ciò ridurrà il ritardo di lancio del kernel durante la formazione. Puoi anche impostare il numero di thread per GPU. Imposta questi valori usando le variabili di ambiente.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
Configurare le opzioni di memoria GPU
In generale, aumentare le dimensioni del lotto e ridimensionare il modello per utilizzare meglio le GPU e ottenere un throughput più elevato. Si noti che l'aumento della dimensione del lotto cambierà l'accuratezza del modello, quindi il modello deve essere ridimensionato sintonizzando iperparametri come il tasso di apprendimento per soddisfare l'accuratezza target.
Inoltre, utilizzare tf.config.experimental.set_memory_growth per consentire alla memoria GPU di crescere per impedire a tutta la memoria disponibile di essere completamente allocata a OPS che richiedono solo una frazione della memoria. Ciò consente di eseguire altri processi che consumano la memoria GPU sullo stesso dispositivo.
Per saperne di più, dai un'occhiata alla limitazione della guida alla crescita della memoria GPU nella Guida GPU per saperne di più.
Varie
Aumenta la dimensione del mini-batch di allenamento (numero di campioni di allenamento utilizzati per dispositivo in una iterazione del ciclo di allenamento) alla quantità massima che si adatta senza un errore fuori memoria (OOM) sulla GPU. L'aumento della dimensione del lotto influisce sulla precisione del modello, quindi assicurati di ridimensionare il modello sintonizzando iperparametri per soddisfare l'accuratezza del target.
Disabilitare gli errori di OOM durante l'allocazione del tensore nel codice di produzione. Imposta
report_tensor_allocations_upon_oom=Falseintf.compat.v1.RunOptions.Per i modelli con strati di convoluzione, rimuovere l'aggiunta di bias se si utilizza la normalizzazione batch. La normalizzazione batch sposta i valori in base alla loro media e questo rimuove la necessità di avere un termine di pregiudizio costante.
Usa le statistiche TF per scoprire come funzionano OPS in modo efficiente sul dispositivo.
Utilizzare
tf.functionper eseguire calcoli e facoltativamente, abilitajit_compile=Trueflag (tf.function(jit_compile=True). Per saperne di più, vai a utilizzare xla tf.function .Ridurre al minimo le operazioni di Python host tra passaggi e riduci i callback. Calcola le metriche ogni pochi passaggi anziché ad ogni passaggio.
Mantieni occupate le unità di calcolo del dispositivo.
Invia dati a più dispositivi in parallelo.
Prendi in considerazione l'uso di rappresentazioni numeriche a 16 bit , come
fp16: il formato punto galleggiante a mezza precisione specificata da IEEE, o il formato BFLOAT16 a punto galleggiante cerebrale.
Risorse aggiuntive
- Tensorflow Profiler: Profile Model Performance Tutorial con Keras e Tensorboard in cui è possibile applicare i consigli in questa guida.
- La profilazione delle prestazioni in Tensorflow 2 parla del Tensorflow Dev Summit 2020.
- La demo del profiler Tensorflow dal Tensorflow Dev Summit 2020.
Limiti noti
Profilaggio di GPU multipli su Tensorflow 2.2 e Tensorflow 2.3
Tensorflow 2.2 e 2.3 supportano la profilazione della GPU multipla solo per sistemi host singoli; La profilazione multipla GPU per i sistemi multidoscei non è supportata. Per profilare le configurazioni GPU multi-lavoratore, ogni lavoratore deve essere profilato in modo indipendente. Da Tensorflow 2.4 più lavoratori possono essere profilati utilizzando l'API tf.profiler.experimental.client.trace .
CUDA® Toolkit 10.2 o successivo è necessario per profilare più GPU. Poiché Tensorflow 2.2 e 2.3 supportano le versioni CUDA® Toolkit solo fino a 10.1, è necessario creare collegamenti simbolici a libcudart.so.10.1 e libcupti.so.10.1 :
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1