
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | | |
Panoramica
Questa recensioni classifica notebook di film come positivo o negativo che utilizzano il testo della revisione. Questo è un esempio di classificazione binaria, un tipo importante e ampiamente applicabile di problema machine learning.
Dimostreremo l'uso della regolarizzazione del grafico in questo notebook costruendo un grafico dall'input fornito. La ricetta generale per la creazione di un modello regolato dal grafico utilizzando il framework Neural Structured Learning (NSL) quando l'input non contiene un grafico esplicito è la seguente:
- Crea incorporamenti per ogni campione di testo nell'input. Questo può essere fatto utilizzando modelli pre-addestrati, come word2vec , girevole , BERT etc.
- Costruisci un grafico basato su questi incorporamenti utilizzando una metrica di somiglianza come la distanza 'L2', la distanza 'coseno', ecc. I nodi nel grafico corrispondono ai campioni e gli spigoli nel grafico corrispondono alla somiglianza tra coppie di campioni.
- Genera dati di addestramento dal grafico sopra sintetizzato e dalle funzionalità di esempio. I dati di training risultanti conterranno feature adiacenti oltre alle feature del nodo originale.
- Crea una rete neurale come modello di base utilizzando l'API sequenziale, funzionale o di sottoclasse di Keras.
- Avvolgere il modello base con la classe wrapper GraphRegularization, fornita dal framework NSL, per creare un nuovo modello Keras grafico. Questo nuovo modello includerà un grafico della perdita di regolarizzazione come termine di regolarizzazione nel suo obiettivo di formazione.
- Addestrare e valutare il modello Keras grafico.
Requisiti
- Installa il pacchetto Neural Structured Learning.
- Installare tensorflow-hub.
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
Dipendenze e importazioni
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Set di dati IMDB
Il set di dati IMDB contiene il testo di 50.000 recensioni di film dalla Internet Movie Database . Questi sono suddivisi in 25.000 recensioni per la formazione e 25.000 recensioni per i test. I set di allenamento e test sono equilibrati, nel senso che contengono un uguale numero di recensioni positive e negative.
In questo tutorial, utilizzeremo una versione preelaborata del set di dati IMDB.
Scarica il set di dati IMDB preelaborato
Il set di dati IMDB viene fornito con TensorFlow. È già stato preelaborato in modo tale che le revisioni (sequenze di parole) siano state convertite in sequenze di numeri interi, dove ogni numero intero rappresenta una parola specifica in un dizionario.
Il codice seguente scarica il set di dati IMDB (o utilizza una copia memorizzata nella cache se è già stata scaricata):
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
L'argomento num_words=10000 mantiene le prime 10.000 parole più frequenti nei dati di addestramento. Le parole rare vengono scartate per mantenere gestibili le dimensioni del vocabolario.
Esplora i dati
Prendiamoci un momento per capire il formato dei dati. Il set di dati viene preelaborato: ogni esempio è un array di numeri interi che rappresentano le parole della recensione del film. Ogni etichetta è un valore intero di 0 o 1, dove 0 è una recensione negativa e 1 è una recensione positiva.
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
Il testo delle recensioni è stato convertito in numeri interi, dove ogni numero intero rappresenta una parola specifica in un dizionario. Ecco come appare la prima recensione:
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
Le recensioni dei film possono avere lunghezze diverse. Il codice seguente mostra il numero di parole nella prima e nella seconda revisione. Poiché gli input a una rete neurale devono essere della stessa lunghezza, dovremo risolverlo in seguito.
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
Riconvertire i numeri interi in parole
Può essere utile sapere come riconvertire gli interi nel testo corrispondente. Qui creeremo una funzione di supporto per interrogare un oggetto dizionario che contiene la mappatura da intero a stringa:
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
Ora siamo in grado di utilizzare la decode_review funzione per visualizzare il testo per la prima valutazione:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
Costruzione del grafico
La costruzione del grafico implica la creazione di incorporamenti per campioni di testo e quindi l'utilizzo di una funzione di somiglianza per confrontare gli incorporamenti.
Prima di procedere ulteriormente, creiamo prima una directory per memorizzare gli artefatti creati da questo tutorial.
mkdir -p /tmp/imdb
Crea incorporamenti di esempio
Useremo incastri girevoli preaddestrato per creare incastri nel tf.train.Example formato per ogni campione in ingresso. Vi memorizzare le immersioni risultanti nel TFRecord formato insieme ad una funzione aggiuntiva che rappresenta l'ID di ciascun campione. Questo è importante e ci consentirà di abbinare gli incorporamenti di esempio con i nodi corrispondenti nel grafico in un secondo momento.
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
Costruisci un grafico
Ora che abbiamo gli embedding di esempio, li useremo per costruire un grafico di similarità, cioè, i nodi in questo grafico corrisponderanno ai campioni e gli archi in questo grafico corrisponderanno alla similarità tra coppie di nodi.
Neural Structured Learning fornisce una libreria di creazione di grafici per costruire un grafico basato su incorporamenti di esempio. Esso utilizza somiglianza coseno come misura di similarità di confrontare incastri e bordi di generazione tra loro. Ci consente anche di specificare una soglia di somiglianza, che può essere utilizzata per scartare bordi dissimili dal grafico finale. In questo esempio, utilizzando 0,99 come soglia di somiglianza e 12345 come seme casuale, si ottiene un grafico con 429.415 bordi bidirezionali. Qui stiamo utilizzando il supporto del costruttore grafico per località sensibili hashing (LSH) per accelerare la creazione del grafico. Per informazioni dettagliate sull'uso di supporto LSH del costruttore grafico, vedere la build_graph_from_config documentazione API.
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
Ciascun bordo bidirezionale è rappresentato da due bordi diretti nel file TSV di output, in modo che il file contenga 429.415 * 2 = 858.830 linee totali:
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
Caratteristiche di esempio
Creiamo le caratteristiche del campione per il nostro problema utilizzando il tf.train.Example formato e li persistiamo nel TFRecord formato. Ogni campione includerà le seguenti tre caratteristiche:
- id: l'ID del nodo del campione.
- parole: Un elenco Int64 che contiene gli ID di parole.
- Etichetta: A Singleton Int64 che identifica la classe di destinazione del riesame.
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
Aumenta i dati di allenamento con i vicini del grafico
Poiché disponiamo delle funzionalità di esempio e del grafico sintetizzato, possiamo generare i dati di training aumentati per l'apprendimento strutturato neurale. Il framework NSL fornisce una libreria per combinare il grafico e le funzionalità di esempio per produrre i dati di training finali per la regolarizzazione del grafico. I dati di addestramento risultanti includeranno le caratteristiche del campione originale e le caratteristiche dei loro vicini corrispondenti.
In questo tutorial, consideriamo gli archi non orientati e utilizziamo un massimo di 3 vicini per campione per aumentare i dati di addestramento con i vicini del grafico.
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
Modello base
Ora siamo pronti per costruire un modello base senza regolarizzazione del grafico. Per costruire questo modello, possiamo utilizzare gli incorporamenti che sono stati utilizzati nella costruzione del grafico, oppure possiamo apprendere nuovi incorporamenti insieme al compito di classificazione. Ai fini di questo notebook, faremo quest'ultimo.
Variabili globali
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
Iperparametri
Useremo un'istanza di HParams per inclue vari iperparametri e costanti utilizzate per la formazione e la valutazione. Descriviamo brevemente ciascuno di essi di seguito:
num_classes: Ci sono 2 classi - positivo e negativo.
max_seq_length: Questo è il numero massimo di parole considerate da ogni revisione di film in questo esempio.
vocab_size: Questa è la dimensione del vocabolario considerato per questo esempio.
distance_type: Questa è la distanza metrica utilizzata per regolarizzare il campione con i suoi vicini.
graph_regularization_multiplier: Questo controlla il peso relativo del termine grafico regolarizzazione nella funzione generale di perdita.
num_neighbors: il numero di vicini utilizzati per la regolarizzazione del grafico. Tale valore deve essere minore o uguale al
max_nbrsargomento usato sopra quando si richiamansl.tools.pack_nbrs.num_fc_units: Il numero di unità nello strato completamente connessi della rete neurale.
train_epochs: il numero di epoche di formazione.
dimensione del lotto utilizzato per la formazione e la valutazione: batch_size.
eval_steps: il numero di lotti di processo prima ritenendo di valutazione è completo. Se è impostato su
None, tutte le istanze nel set di prova vengono valutati.
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
Preparare i dati
Le revisioni, le matrici di numeri interi, devono essere convertite in tensori prima di essere immesse nella rete neurale. Questa conversione può essere eseguita in un paio di modi:
Convertire gli array in vettori di
0s e1s indicano parola occorrenza, simile ad una codifica di un caldo. Ad esempio, la sequenza[3, 5]diventerebbe10000vettore dimensionale che è tutti zero eccetto per gli indici3e5, che sono quelli. Quindi, fare questo il primo strato in una rete, unDensestrato in grado di gestire dati floating point vettoriali. Questo approccio è intensivo di memoria, tuttavia, richiedono unnum_words * num_reviewsmatrice dimensioni.In alternativa, possiamo pad le matrici così tutti hanno la stessa lunghezza, crea un tensore intero di forma
max_length * num_reviews. Possiamo utilizzare un livello di incorporamento in grado di gestire questa forma come primo livello nella nostra rete.
In questo tutorial, utilizzeremo il secondo approccio.
Dal momento che le recensioni di film devono avere la stessa lunghezza, useremo il pad_sequence funzione definita di seguito per standardizzare le lunghezze.
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
Costruisci il modello
Una rete neurale viene creata impilando i livelli: ciò richiede due principali decisioni architetturali:
- Quanti strati usare nel modello?
- Quante unità nascosti da utilizzare per ogni strato?
In questo esempio, i dati di input sono costituiti da un array di indici di parole. Le etichette da prevedere sono 0 o 1.
Useremo un LSTM bidirezionale come modello base in questo tutorial.
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
I livelli sono effettivamente impilati in sequenza per costruire il classificatore:
- Il primo strato è un
Inputstrato che prende il vocabolario intero codificato. - Il livello successivo è un
Embeddingstrato, che prende il vocabolario intero codificato e cerca il vettore incorporamento per ogni parola-index. Questi vettori vengono appresi come treni modello. I vettori aggiungono una dimensione all'array di output. Le dimensioni risultanti sono:(batch, sequence, embedding). - Successivamente, un livello LSTM bidirezionale restituisce un vettore di output a lunghezza fissa per ogni esempio.
- Questa uscita vettore a lunghezza fissa viene convogliata attraverso un (completamente collegato
Dense) strato con 64 unità nascoste. - L'ultimo strato è densamente connesso con un singolo nodo di output. Utilizzando il
sigmoidfunzione di attivazione, questo valore è un float tra 0 e 1, che rappresenta una probabilità, o livello di confidenza.
Unità nascoste
Il modello di cui sopra ha due strati intermedi o "nascosti" tra ingresso ed uscita, ed escludendo Embedding strato. Il numero di output (unità, nodi o neuroni) è la dimensione dello spazio di rappresentazione per il livello. In altre parole, la quantità di libertà concessa alla rete nell'apprendere una rappresentazione interna.
Se un modello ha più unità nascoste (uno spazio di rappresentazione a più dimensioni) e/o più livelli, la rete può apprendere rappresentazioni più complesse. Tuttavia, rende la rete più costosa dal punto di vista computazionale e può portare all'apprendimento di modelli indesiderati, modelli che migliorano le prestazioni sui dati di addestramento ma non sui dati di test. Questo si chiama overfitting.
Funzione di perdita e ottimizzatore
Un modello necessita di una funzione di perdita e di un ottimizzatore per l'addestramento. Poiché questo è un problema di classificazione binaria e il modello uscite una probabilità (a strato singolo apparecchio con attivazione sigmoidale), useremo la binary_crossentropy funzione di perdita.
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Crea un set di convalida
Durante l'addestramento, vogliamo verificare l'accuratezza del modello su dati che non ha mai visto prima. Creare un set di validazione per la messa a parte una frazione dei dati di allenamento originali. (Perché non utilizzare il set di test ora? Il nostro obiettivo è sviluppare e ottimizzare il nostro modello utilizzando solo i dati di addestramento, quindi utilizzare i dati di test solo una volta per valutare la nostra precisione).
In questo tutorial, prendiamo circa il 10% dei campioni di addestramento iniziali (10% di 25000) come dati etichettati per l'addestramento e il resto come dati di convalida. Poiché la suddivisione treno/test iniziale era 50/50 (25000 campioni ciascuno), l'effettiva suddivisione treno/convalida/test che abbiamo ora è 5/45/50.
Nota che 'train_dataset' è già stato raggruppato e mescolato.
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
Allena il modello
Addestrare il modello in mini-batch. Durante l'addestramento, monitorare la perdita e l'accuratezza del modello sul set di convalida:
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
Valuta il modello
Ora vediamo come si comporta il modello. Verranno restituiti due valori. Perdita (un numero che rappresenta il nostro errore, valori più bassi sono migliori) e precisione.
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
Crea un grafico di accuratezza/perdita nel tempo
model.fit() restituisce uno History oggetto che contiene un dizionario con tutto ciò che è accaduto durante l'allenamento:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
Sono disponibili quattro voci: una per ciascuna metrica monitorata durante l'addestramento e la convalida. Possiamo usarli per tracciare la perdita di addestramento e convalida per il confronto, nonché l'accuratezza di addestramento e convalida:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
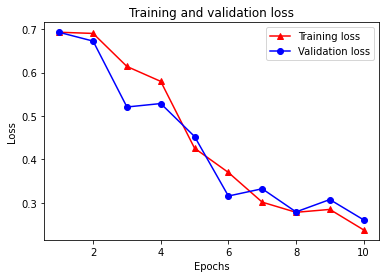
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
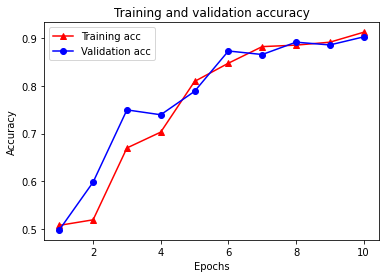
Si noti la perdita di formazione diminuisce con ogni epoca e la formazione di precisione aumenta con ogni epoca. Ciò è previsto quando si utilizza un'ottimizzazione della discesa del gradiente: dovrebbe ridurre al minimo la quantità desiderata ad ogni iterazione.
Regolarizzazione del grafico
Ora siamo pronti per provare la regolarizzazione del grafico utilizzando il modello base che abbiamo costruito sopra. Useremo il GraphRegularization classe wrapper fornito dal framework Learning Neural Strutturato per avvolgere il modello base (bi-LSTM) per includere grafico regolarizzazione. Il resto dei passaggi per l'addestramento e la valutazione del modello regolarizzato dal grafico è simile a quello del modello base.
Crea un modello grafico-regolato
Per valutare il vantaggio incrementale della regolarizzazione del grafico, creeremo una nuova istanza del modello di base. Questo perché model è già stato allenato per un paio di iterazioni, e il riutilizzo di questo modello addestrato per creare un modello grafico-regolarizzato non sarà un confronto equo per model .
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Allena il modello
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
Valuta il modello
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
Crea un grafico di accuratezza/perdita nel tempo
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
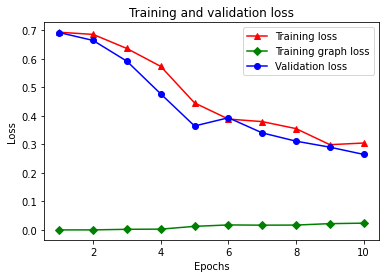
Ci sono cinque voci in totale nel dizionario: perdita di addestramento, accuratezza di addestramento, perdita del grafico di addestramento, perdita di convalida e accuratezza di convalida. Possiamo tracciarli tutti insieme per il confronto. Si noti che la perdita del grafico viene calcolata solo durante l'allenamento.
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
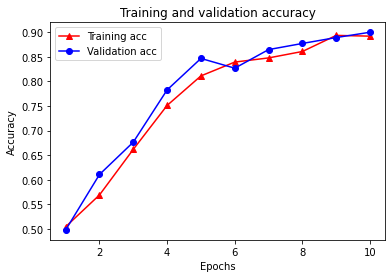
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
Il potere dell'apprendimento semi-supervisionato
L'apprendimento semi-supervisionato e, più specificamente, la regolarizzazione del grafico nel contesto di questo tutorial, può essere davvero potente quando la quantità di dati di addestramento è piccola. La mancanza di dati di formazione è compensata sfruttando la somiglianza tra i campioni di formazione, cosa non possibile nell'apprendimento supervisionato tradizionale.
Definiamo il rapporto di supervisione come il rapporto tra formazione campioni al numero totale di campioni, che comprende la formazione, la convalida, e campioni di prova. In questo taccuino, abbiamo utilizzato un rapporto di supervisione di 0,05 (ovvero il 5% dei dati etichettati) per addestrare sia il modello base che il modello regolarizzato dal grafico. Illustriamo l'impatto del rapporto di supervisione sull'accuratezza del modello nella cella sottostante.
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
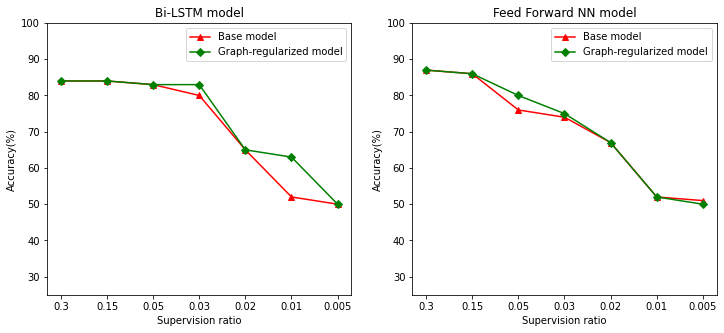
Si può osservare che al diminuire del rapporto di supervisione, diminuisce anche l'accuratezza del modello. Questo è vero sia per il modello base che per il modello regolarizzato a grafo, indipendentemente dall'architettura del modello utilizzata. Tuttavia, si noti che il modello regolato dal grafico ha prestazioni migliori rispetto al modello base per entrambe le architetture. In particolare, per il modello Bi-LSTM, quando il rapporto di supervisione è 0,01, la precisione del modello grafico-regolarizzata è ~ 20% superiore a quella del modello di base. Ciò è dovuto principalmente all'apprendimento semi-supervisionato per il modello regolato dal grafico, in cui viene utilizzata la somiglianza strutturale tra i campioni di addestramento oltre ai campioni di addestramento stessi.
Conclusione
Abbiamo dimostrato l'uso della regolarizzazione del grafico utilizzando il framework Neural Structured Learning (NSL) anche quando l'input non contiene un grafico esplicito. Abbiamo considerato il compito di classificare il sentiment delle recensioni di film IMDB per il quale abbiamo sintetizzato un grafico di somiglianza basato sugli incorporamenti di recensioni. Incoraggiamo gli utenti a sperimentare ulteriormente variando gli iperparametri, la quantità di supervisione e utilizzando diverse architetture di modelli.