
टीएल;डीआर : टेन्सरफ्लो रैंकिंग पाइपलाइनों के साथ टेन्सरफ्लो रैंकिंग मॉडल बनाने, प्रशिक्षित करने और परोसने के लिए बॉयलरप्लेट कोड को कम करें; उपयोग के मामले और संसाधनों को देखते हुए बड़े पैमाने पर रैंकिंग अनुप्रयोगों के लिए उचित वितरित रणनीतियों का उपयोग करें।
परिचय
TensorFlow रैंकिंग पाइपलाइन में डेटा प्रोसेसिंग, मॉडल निर्माण, प्रशिक्षण और सेवा प्रक्रियाओं की एक श्रृंखला शामिल है जो आपको न्यूनतम प्रयासों के साथ डेटा लॉग से स्केलेबल न्यूरल नेटवर्क-आधारित रैंकिंग मॉडल बनाने, प्रशिक्षित करने और सेवा करने की अनुमति देती है। जब सिस्टम बड़ा हो जाता है तो पाइपलाइन सबसे अधिक कुशल होती है। सामान्य तौर पर, यदि आपका मॉडल एक मशीन पर चलने में 10 मिनट या उससे अधिक समय लेता है, तो लोड को वितरित करने और प्रसंस्करण में तेजी लाने के लिए इस पाइपलाइन ढांचे का उपयोग करने पर विचार करें।
TensorFlow रैंकिंग पाइपलाइन वितरित सिस्टम (1K+ CPU और 100+ GPU और TPUs) पर बड़े डेटा (टेराबाइट्स+) और बड़े मॉडल (100M+ FLOPs) के साथ बड़े पैमाने पर प्रयोगों और उत्पादन में लगातार और स्थिर रूप से चलाई गई है। एक बार जब TensorFlow मॉडल डेटा के एक छोटे से हिस्से पर model.fit के साथ सिद्ध हो जाता है, तो पाइपलाइन को हाइपर-पैरामीटर स्कैनिंग, निरंतर प्रशिक्षण और अन्य बड़े पैमाने की स्थितियों के लिए अनुशंसित किया जाता है।
रैंकिंग पाइपलाइन
TensorFlow में, रैंकिंग मॉडल बनाने, प्रशिक्षित करने और सेवा प्रदान करने के लिए एक विशिष्ट पाइपलाइन में निम्नलिखित विशिष्ट चरण शामिल होते हैं।
- मॉडल संरचना परिभाषित करें:
- इनपुट बनाएं;
- पूर्व-प्रसंस्करण परतें बनाएं;
- तंत्रिका नेटवर्क आर्किटेक्चर बनाएं;
- ट्रेन मॉडल:
- डेटा लॉग से ट्रेन और सत्यापन डेटासेट उत्पन्न करें;
- उचित हाइपर-पैरामीटर के साथ मॉडल तैयार करें:
- अनुकूलक;
- रैंकिंग हानि;
- रैंकिंग मेट्रिक्स;
- अनेक डिवाइसों पर प्रशिक्षित करने के लिए वितरित रणनीतियों को कॉन्फ़िगर करें।
- विभिन्न बहीखाता पद्धति के लिए कॉलबैक कॉन्फ़िगर करें।
- परोसने के लिए निर्यात मॉडल;
- मॉडल परोसें:
- परोसते समय डेटा प्रारूप निर्धारित करें;
- प्रशिक्षित मॉडल चुनें और लोड करें;
- लोडेड मॉडल के साथ प्रक्रिया करें।
TensorFlow रैंकिंग पाइपलाइन का एक मुख्य उद्देश्य चरणों में बॉयलरप्लेट कोड को कम करना है, जैसे डेटासेट लोडिंग और प्रीप्रोसेसिंग, सूचीवार डेटा की अनुकूलता और बिंदुवार स्कोरिंग फ़ंक्शन और मॉडल निर्यात। अन्य महत्वपूर्ण उद्देश्य कई अंतर्निहित सहसंबद्ध प्रक्रियाओं के सुसंगत डिजाइन को लागू करना है, उदाहरण के लिए, मॉडल इनपुट को प्रशिक्षण डेटासेट और सेवारत डेटा प्रारूप दोनों के साथ संगत होना चाहिए।
गाइड का प्रयोग करें
उपरोक्त सभी डिज़ाइन के साथ, टीएफ-रैंकिंग मॉडल लॉन्च करना निम्नलिखित चरणों में आता है, जैसा चित्र 1 में दिखाया गया है।
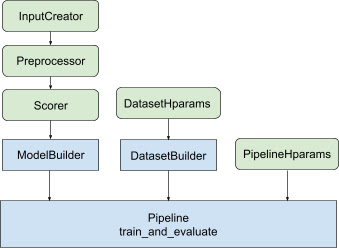
वितरित तंत्रिका नेटवर्क का उपयोग करने का उदाहरण
इस उदाहरण में, आप अंतर्निहित tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder , और tfr.keras.pipeline.SimplePipeline का लाभ उठाएंगे जो मॉडल इनपुट में इनपुट सुविधाओं को लगातार परिभाषित करने के लिए feature_spec एस लेते हैं और डेटासेट सर्वर. चरण-दर-चरण वॉकथ्रू वाला नोटबुक संस्करण वितरित रैंकिंग ट्यूटोरियल में पाया जा सकता है।
पहले संदर्भ और उदाहरण सुविधाओं दोनों के लिए feature_spec को परिभाषित करें।
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
चित्र 1 में दर्शाए गए चरणों का पालन करें:
feature_spec एस से input_creator परिभाषित करें।
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
फिर इनपुट सुविधाओं के समान सेट के लिए प्रीप्रोसेसिंग सुविधा परिवर्तनों को परिभाषित करें।
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
बिल्ट-इन फीडफॉरवर्ड डीएनएन मॉडल के साथ स्कोरर को परिभाषित करें।
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
input_creator , preprocessor और scorer के साथ model_builder बनाएं।
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
अब dataset_builder के लिए हाइपरपैरामीटर सेट करें।
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
dataset_builder बनाएं।
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
पाइपलाइन के लिए हाइपरपैरामीटर भी सेट करें।
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
ranking_pipeline बनाएं और प्रशिक्षित करें।
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
टेन्सरफ्लो रैंकिंग पाइपलाइन का डिज़ाइन
टेन्सरफ्लो रैंकिंग पाइपलाइन बॉयलरप्लेट कोड के साथ इंजीनियरिंग का समय बचाने में मदद करती है, साथ ही, ओवरराइडिंग और सबक्लासिंग के माध्यम से अनुकूलन के लचीलेपन की अनुमति देती है। इसे प्राप्त करने के लिए, पाइपलाइन TensorFlow रैंकिंग पाइपलाइन स्थापित करने के लिए अनुकूलन योग्य कक्षाएं tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder और tfr.keras.pipeline.AbstractPipeline पेश करती है।

मॉडलबिल्डर
Keras मॉडल के निर्माण से संबंधित बॉयलरप्लेट कोड को AbstractModelBuilder में एकीकृत किया गया है, जिसे AbstractPipeline को पास किया जाता है और रणनीति के दायरे के तहत मॉडल बनाने के लिए पाइपलाइन के अंदर बुलाया जाता है। यह चित्र 1 में दिखाया गया है। वर्ग विधियों को अमूर्त आधार वर्ग में परिभाषित किया गया है।
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
आप AbstractModelBuilder को सीधे उपवर्गित कर सकते हैं और अनुकूलन के लिए ठोस तरीकों से अधिलेखित कर सकते हैं, जैसे
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
साथ ही, आपको इनपुट सुविधाओं, प्रीप्रोसेस ट्रांसफॉर्मेशन और सबक्लासिंग के बजाय क्लास इनिट में फ़ंक्शन इनपुट input_creator , preprocessor और scorer के रूप में निर्दिष्ट स्कोरिंग फ़ंक्शन के साथ ModelBuilder उपयोग करना चाहिए।
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
इन इनपुट को बनाने के बॉयलरप्लेट को कम करने के लिए, input_creator के लिए फ़ंक्शन क्लास tfr.keras.model.InputCreator , preprocessor के लिए tfr.keras.model.Preprocessor और scorer के लिए tfr.keras.model.Scorer , ठोस उपवर्ग tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer , और tfr.keras.model.GAMScorer . इनमें अधिकांश सामान्य उपयोग के मामले शामिल होने चाहिए।
ध्यान दें कि ये फ़ंक्शन क्लास केरस क्लास हैं, इसलिए क्रमबद्धता की कोई आवश्यकता नहीं है। उन्हें अनुकूलित करने के लिए उपवर्गीकरण अनुशंसित तरीका है।
डेटासेटबिल्डर
DatasetBuilder वर्ग डेटासेट से संबंधित बॉयलरप्लेट एकत्र करता है। डेटा को Pipeline में भेज दिया जाता है और प्रशिक्षण और सत्यापन डेटासेट की सेवा करने और सहेजे गए मॉडल के लिए सेवा हस्ताक्षर को परिभाषित करने के लिए बुलाया जाता है। जैसा कि चित्र 1 में दिखाया गया है, DatasetBuilder विधियों को tfr.keras.pipeline.AbstractDatasetBuilder बेस क्लास में परिभाषित किया गया है,
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
एक ठोस DatasetBuilder क्लास में, आपको build_train_datasets , build_valid_datasets और build_signatures लागू करना होगा।
एक ठोस वर्ग जो feature_spec एस से डेटासेट बनाता है वह भी प्रदान किया गया है:
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
DatasetBuilder में उपयोग किए जाने वाले hparams tfr.keras.pipeline.DatasetHparams डेटाक्लास में निर्दिष्ट हैं।
पाइपलाइन
रैंकिंग पाइपलाइन tfr.keras.pipeline.AbstractPipeline वर्ग पर आधारित है:
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
एक ठोस पाइपलाइन वर्ग जो मॉडल को model.fit के साथ संगत विभिन्न tf.distribute.strategy के साथ प्रशिक्षित करता है, वह भी प्रदान किया गया है:
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
tfr.keras.pipeline.ModelFitPipeline में प्रयुक्त hparams tfr.keras.pipeline.PipelineHparams डेटाक्लास में निर्दिष्ट हैं। यह ModelFitPipeline क्लास अधिकांश टीएफ रैंकिंग उपयोग मामलों के लिए पर्याप्त है। ग्राहक विशिष्ट उद्देश्यों के लिए इसे आसानी से उपवर्गित कर सकते हैं।
वितरित रणनीति समर्थन
कृपया TensorFlow समर्थित वितरित रणनीतियों के विस्तृत परिचय के लिए वितरित प्रशिक्षण देखें। वर्तमान में, TensorFlow रैंकिंग पाइपलाइन tf.distribute.MirroredStrategy (डिफ़ॉल्ट), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy और tf.distribute.ParameterServerStrategy का समर्थन करती है। प्रतिबिंबित रणनीति अधिकांश एकल मशीन प्रणालियों के साथ संगत है। कृपया बिना वितरित रणनीति के लिए strategy को None पर सेट करें।
सामान्य तौर पर, MirroredStrategy सीपीयू और जीपीयू विकल्पों वाले अधिकांश उपकरणों पर अपेक्षाकृत छोटे मॉडल के लिए काम करती है। MultiWorkerMirroredStrategy बड़े मॉडलों के लिए काम करती है जो एक कार्यकर्ता में फिट नहीं होते हैं। ParameterServerStrategy अतुल्यकालिक प्रशिक्षण करती है और इसके लिए कई कर्मचारियों की उपलब्धता की आवश्यकता होती है। TPU उपलब्ध होने पर TPUStrategy बड़े मॉडलों और बड़े डेटा के लिए आदर्श है, हालाँकि, यह टेंसर आकृतियों के मामले में कम लचीला है जिसे यह संभाल सकता है।
पूछे जाने वाले प्रश्न
RankingPipelineउपयोग करने के लिए घटकों का न्यूनतम सेट
ऊपर उदाहरण कोड देखें.यदि मेरे पास अपना स्वयं का केरस
modelहो तो क्या होगा?
tf.distributeरणनीतियों के साथ प्रशिक्षित होने के लिए, रणनीति.स्कोप() के तहत परिभाषित सभी प्रशिक्षण योग्य चर के साथmodelका निर्माण करना आवश्यक है। तो अपने मॉडल कोModelBuilderमें इस प्रकार लपेटें,
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
फिर आगे के प्रशिक्षण के लिए इस मॉडल_बिल्डर को पाइपलाइन में फ़ीड करें।