
El rendimiento de TensorFlow Serving depende en gran medida de la aplicación que ejecuta, el entorno en el que se implementa y otro software con el que comparte el acceso a los recursos de hardware subyacentes. Como tal, ajustar su rendimiento depende en cierta medida de los casos y existen muy pocas reglas universales que garanticen un rendimiento óptimo en todos los entornos. Dicho esto, este documento tiene como objetivo capturar algunos principios generales y mejores prácticas para ejecutar TensorFlow Serving.
Utilice la guía Solicitudes de inferencia de perfiles con TensorBoard para comprender el comportamiento subyacente del cálculo de su modelo en las solicitudes de inferencia y use esta guía para mejorar su rendimiento de forma iterativa.
Consejos rápidos
- ¿La latencia de la primera solicitud es demasiado alta? Habilitar el calentamiento del modelo .
- ¿Está interesado en una mayor utilización de recursos o rendimiento? Configurar procesamiento por lotes
Ajuste del rendimiento: objetivos y parámetros
Al ajustar el rendimiento de TensorFlow Serving, generalmente hay 2 tipos de objetivos que puede tener y 3 grupos de parámetros para modificar para mejorar esos objetivos.
Objetivos
TensorFlow Serving es un sistema de servicio en línea para modelos de aprendizaje automático. Al igual que con muchos otros sistemas de servicios en línea, su principal objetivo de rendimiento es maximizar el rendimiento mientras se mantiene la latencia de cola por debajo de ciertos límites . Dependiendo de los detalles y la madurez de su aplicación, es posible que le importe más la latencia promedio que la latencia final , pero algunas nociones de latencia y rendimiento suelen ser las métricas con las que establece los objetivos de rendimiento. Tenga en cuenta que no tratamos la disponibilidad en esta guía, ya que es más una función del entorno de implementación.
Parámetros
Podemos pensar aproximadamente en 3 grupos de parámetros cuya configuración determina el rendimiento observado: 1) el modelo TensorFlow 2) las solicitudes de inferencia y 3) el servidor (hardware y binario).
1) El modelo TensorFlow
El modelo define el cálculo que realizará TensorFlow Serving al recibir cada solicitud entrante.
Debajo del capó, TensorFlow Serving usa el tiempo de ejecución de TensorFlow para hacer la inferencia real de sus solicitudes. Esto significa que la latencia promedio de atender una solicitud con TensorFlow Serving suele ser al menos la de hacer inferencias directamente con TensorFlow. Esto significa que si en una máquina determinada, la inferencia en un solo ejemplo toma 2 segundos y tiene un objetivo de latencia de menos de un segundo, debe perfilar las solicitudes de inferencia, comprender qué operaciones de TensorFlow y subgráficos de su modelo contribuyen más a esa latencia y rediseñe su modelo teniendo en cuenta la latencia de inferencia como una restricción de diseño.
Tenga en cuenta que, si bien la latencia promedio de realizar inferencias con TensorFlow Serving generalmente no es más baja que usar TensorFlow directamente, donde TensorFlow Serving brilla es mantener baja la latencia de cola para muchos clientes que consultan muchos modelos diferentes, todo mientras se utiliza de manera eficiente el hardware subyacente para maximizar el rendimiento. .
2) Las solicitudes de inferencia
Superficies API
TensorFlow Serving tiene dos superficies de API (HTTP y gRPC), las cuales implementan la API de PredictionService (con la excepción del servidor HTTP que no expone un punto final de MultiInference ). Ambas superficies API están muy ajustadas y agregan una latencia mínima, pero en la práctica, se observa que la superficie gRPC tiene un rendimiento ligeramente mayor.
Métodos API
En general, se recomienda utilizar los extremos Classify y Regress ya que aceptan tf.Example , que es una abstracción de nivel superior; sin embargo, en casos excepcionales de solicitudes estructuradas de gran tamaño (O(Mb)), los usuarios expertos pueden encontrar el uso de PredictRequest y la codificación directa de sus mensajes Protobuf en un TensorProto, y omitir la serialización y la deserialización de tf.Example como una fuente de leve aumento de rendimiento.
Tamaño del lote
Hay dos formas principales en que el procesamiento por lotes puede ayudar a su rendimiento. Puede configurar sus clientes para enviar solicitudes por lotes a TensorFlow Serving, o puede enviar solicitudes individuales y configurar TensorFlow Serving para esperar hasta un período de tiempo predeterminado y realizar inferencias en todas las solicitudes que llegan en ese período en un lote. La configuración del último tipo de procesamiento por lotes le permite alcanzar TensorFlow Serving con QPS extremadamente altos, al tiempo que le permite escalar de forma sublineal los recursos informáticos necesarios para mantenerse al día. Esto se analiza con más detalle en la guía de configuración y en el LÉAME de procesamiento por lotes.
3) El servidor (hardware y binario)
El binario TensorFlow Serving realiza una contabilidad bastante precisa del hardware en el que se ejecuta. Como tal, debe evitar ejecutar otras aplicaciones de uso intensivo de cómputo o memoria en la misma máquina, especialmente aquellas con uso dinámico de recursos.
Al igual que con muchos otros tipos de cargas de trabajo, TensorFlow Serving es más eficiente cuando se implementa en menos máquinas más grandes (más CPU y RAM) (es decir, una Deployment con menos replicas en términos de Kubernetes). Esto se debe a un mejor potencial para la implementación de múltiples inquilinos para utilizar el hardware y reducir los costos fijos (servidor RPC, tiempo de ejecución de TensorFlow, etc.).
Aceleradores
Si su host tiene acceso a un acelerador, asegúrese de haber implementado su modelo para colocar cálculos densos en el acelerador; esto debería hacerse automáticamente si ha usado API de TensorFlow de alto nivel, pero si ha creado gráficos personalizados o desea anclar partes específicas de gráficos en aceleradores específicos, es posible que deba colocar manualmente ciertos subgráficos en aceleradores (es decir, usar with tf.device('/device:GPU:0'): ... ).
CPU modernas
Las CPU modernas han ampliado continuamente la arquitectura del conjunto de instrucciones x86 para mejorar la compatibilidad con SIMD (datos múltiples de instrucción única) y otras características críticas para cálculos densos (por ejemplo, una multiplicación y suma en un ciclo de reloj). Sin embargo, para ejecutarse en máquinas un poco más antiguas, TensorFlow y TensorFlow Serving se crean con la modesta suposición de que la CPU del host no admite las funciones más nuevas.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Si ve esta entrada de registro (posiblemente extensiones diferentes a las 2 enumeradas) en el inicio de TensorFlow Serving, significa que puede reconstruir TensorFlow Serving y apuntar a la plataforma de su host en particular y disfrutar de un mejor rendimiento. Construir TensorFlow Serving desde la fuente es relativamente fácil con Docker y se documenta aquí .
Configuración binaria
TensorFlow Serving ofrece una serie de botones de configuración que gobiernan su comportamiento en tiempo de ejecución, en su mayoría establecidos a través de indicadores de línea de comandos . Algunos de estos (en particular tensorflow_intra_op_parallelism y tensorflow_inter_op_parallelism ) se transmiten para configurar el tiempo de ejecución de TensorFlow y se configuran automáticamente, lo que los usuarios expertos pueden anular haciendo muchos experimentos y encontrando la configuración adecuada para su carga de trabajo y entorno específicos.
Vida útil de una solicitud de inferencia de servicio de TensorFlow
Repasemos brevemente la vida de un ejemplo prototípico de una solicitud de inferencia de TensorFlow Serving para ver el viaje por el que pasa una solicitud típica. Para nuestro ejemplo, nos sumergiremos en una solicitud de predicción que recibe la superficie de la API gRPC de servicio de TensorFlow 2.0.0.
Primero veamos un diagrama de secuencia a nivel de componente y luego saltemos al código que implementa esta serie de interacciones.
Diagrama de secuencia
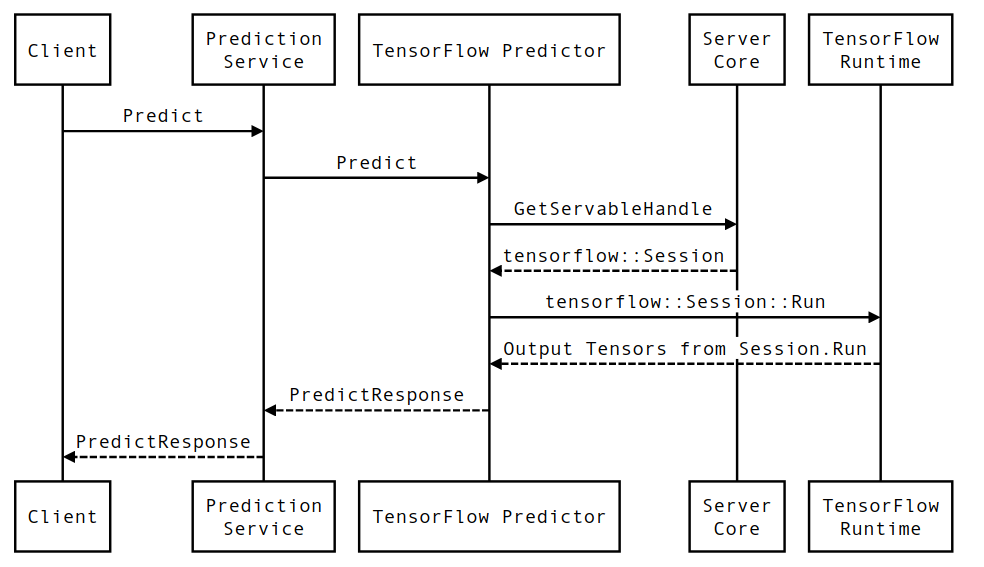
Tenga en cuenta que Client es un componente propiedad del usuario, Prediction Service, Servables y Server Core son propiedad de TensorFlow Serving y TensorFlow Runtime es propiedad de Core TensorFlow .
Detalles de la secuencia
-
PredictionServiceImpl::PredictrecibePredictRequest - Invocamos
TensorflowPredictor::Predict, propagando la fecha límite de solicitud desde la solicitud de gRPC (si se configuró una). - Dentro
TensorflowPredictor::Predict, buscamos el Servible (modelo) en el que la solicitud busca realizar una inferencia, de la cual recuperamos información sobre el Modelo guardado y, lo que es más importante, un identificador del objetoSessionen el que se encuentra el gráfico del modelo (posiblemente parcialmente) cargado. Este objeto Servible se creó y confirmó en la memoria cuando TensorFlow Serving cargó el modelo. Luego invocamos internal::RunPredict para llevar a cabo la predicción. - En
internal::RunPredict, después de validar y preprocesar la solicitud, usamos el objetoSessionpara realizar la inferencia mediante una llamada de bloqueo a Session::Run , momento en el que ingresamos al código base de TensorFlow. Después de queSession::Runregresa y nuestros tensores deoutputsse han llenado, convertimos las salidas enPredictionResponsey devolvemos el resultado a la pila de llamadas.
El rendimiento de TensorFlow Serving depende en gran medida de la aplicación que ejecuta, el entorno en el que se implementa y otro software con el que comparte el acceso a los recursos de hardware subyacentes. Como tal, ajustar su rendimiento depende en cierta medida de los casos y existen muy pocas reglas universales que garanticen un rendimiento óptimo en todos los entornos. Dicho esto, este documento tiene como objetivo capturar algunos principios generales y mejores prácticas para ejecutar TensorFlow Serving.
Utilice la guía Solicitudes de inferencia de perfiles con TensorBoard para comprender el comportamiento subyacente del cálculo de su modelo en las solicitudes de inferencia y use esta guía para mejorar su rendimiento de forma iterativa.
Consejos rápidos
- ¿La latencia de la primera solicitud es demasiado alta? Habilitar el calentamiento del modelo .
- ¿Está interesado en una mayor utilización de recursos o rendimiento? Configurar procesamiento por lotes
Ajuste del rendimiento: objetivos y parámetros
Al ajustar el rendimiento de TensorFlow Serving, generalmente hay 2 tipos de objetivos que puede tener y 3 grupos de parámetros para modificar para mejorar esos objetivos.
Objetivos
TensorFlow Serving es un sistema de servicio en línea para modelos de aprendizaje automático. Al igual que con muchos otros sistemas de servicios en línea, su principal objetivo de rendimiento es maximizar el rendimiento mientras se mantiene la latencia de cola por debajo de ciertos límites . Dependiendo de los detalles y la madurez de su aplicación, es posible que le importe más la latencia promedio que la latencia final , pero algunas nociones de latencia y rendimiento suelen ser las métricas con las que establece los objetivos de rendimiento. Tenga en cuenta que no tratamos la disponibilidad en esta guía, ya que es más una función del entorno de implementación.
Parámetros
Podemos pensar aproximadamente en 3 grupos de parámetros cuya configuración determina el rendimiento observado: 1) el modelo TensorFlow 2) las solicitudes de inferencia y 3) el servidor (hardware y binario).
1) El modelo TensorFlow
El modelo define el cálculo que realizará TensorFlow Serving al recibir cada solicitud entrante.
Debajo del capó, TensorFlow Serving usa el tiempo de ejecución de TensorFlow para hacer la inferencia real de sus solicitudes. Esto significa que la latencia promedio de atender una solicitud con TensorFlow Serving suele ser al menos la de hacer inferencias directamente con TensorFlow. Esto significa que si en una máquina determinada, la inferencia en un solo ejemplo toma 2 segundos y tiene un objetivo de latencia de menos de un segundo, debe perfilar las solicitudes de inferencia, comprender qué operaciones de TensorFlow y subgráficos de su modelo contribuyen más a esa latencia y rediseñe su modelo teniendo en cuenta la latencia de inferencia como una restricción de diseño.
Tenga en cuenta que, si bien la latencia promedio de realizar inferencias con TensorFlow Serving generalmente no es más baja que usar TensorFlow directamente, donde TensorFlow Serving brilla es mantener baja la latencia de cola para muchos clientes que consultan muchos modelos diferentes, todo mientras se utiliza de manera eficiente el hardware subyacente para maximizar el rendimiento. .
2) Las solicitudes de inferencia
Superficies API
TensorFlow Serving tiene dos superficies de API (HTTP y gRPC), las cuales implementan la API de PredictionService (con la excepción del servidor HTTP que no expone un punto final de MultiInference ). Ambas superficies API están muy ajustadas y agregan una latencia mínima, pero en la práctica, se observa que la superficie gRPC tiene un rendimiento ligeramente mayor.
Métodos API
En general, se recomienda utilizar los extremos Classify y Regress ya que aceptan tf.Example , que es una abstracción de nivel superior; sin embargo, en casos excepcionales de solicitudes estructuradas de gran tamaño (O(Mb)), los usuarios expertos pueden encontrar el uso de PredictRequest y la codificación directa de sus mensajes Protobuf en un TensorProto, y omitir la serialización y la deserialización de tf.Example como una fuente de leve aumento de rendimiento.
Tamaño del lote
Hay dos formas principales en que el procesamiento por lotes puede ayudar a su rendimiento. Puede configurar sus clientes para enviar solicitudes por lotes a TensorFlow Serving, o puede enviar solicitudes individuales y configurar TensorFlow Serving para esperar hasta un período de tiempo predeterminado y realizar inferencias en todas las solicitudes que llegan en ese período en un lote. La configuración del último tipo de procesamiento por lotes le permite alcanzar TensorFlow Serving con QPS extremadamente altos, al tiempo que le permite escalar de forma sublineal los recursos informáticos necesarios para mantenerse al día. Esto se analiza con más detalle en la guía de configuración y en el LÉAME de procesamiento por lotes.
3) El servidor (hardware y binario)
El binario TensorFlow Serving realiza una contabilidad bastante precisa del hardware en el que se ejecuta. Como tal, debe evitar ejecutar otras aplicaciones de uso intensivo de cómputo o memoria en la misma máquina, especialmente aquellas con uso dinámico de recursos.
Al igual que con muchos otros tipos de cargas de trabajo, TensorFlow Serving es más eficiente cuando se implementa en menos máquinas más grandes (más CPU y RAM) (es decir, una Deployment con menos replicas en términos de Kubernetes). Esto se debe a un mejor potencial para la implementación de múltiples inquilinos para utilizar el hardware y reducir los costos fijos (servidor RPC, tiempo de ejecución de TensorFlow, etc.).
Aceleradores
Si su host tiene acceso a un acelerador, asegúrese de haber implementado su modelo para colocar cálculos densos en el acelerador; esto debería hacerse automáticamente si ha usado API de TensorFlow de alto nivel, pero si ha creado gráficos personalizados o desea anclar partes específicas de gráficos en aceleradores específicos, es posible que deba colocar manualmente ciertos subgráficos en aceleradores (es decir, usar with tf.device('/device:GPU:0'): ... ).
CPU modernas
Las CPU modernas han ampliado continuamente la arquitectura del conjunto de instrucciones x86 para mejorar la compatibilidad con SIMD (datos múltiples de instrucción única) y otras características críticas para cálculos densos (por ejemplo, una multiplicación y suma en un ciclo de reloj). Sin embargo, para ejecutarse en máquinas un poco más antiguas, TensorFlow y TensorFlow Serving se crean con la modesta suposición de que la CPU del host no admite las funciones más nuevas.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Si ve esta entrada de registro (posiblemente extensiones diferentes a las 2 enumeradas) en el inicio de TensorFlow Serving, significa que puede reconstruir TensorFlow Serving y apuntar a la plataforma de su host en particular y disfrutar de un mejor rendimiento. Construir TensorFlow Serving desde la fuente es relativamente fácil con Docker y se documenta aquí .
Configuración binaria
TensorFlow Serving ofrece una serie de botones de configuración que gobiernan su comportamiento en tiempo de ejecución, en su mayoría establecidos a través de indicadores de línea de comandos . Algunos de estos (en particular tensorflow_intra_op_parallelism y tensorflow_inter_op_parallelism ) se transmiten para configurar el tiempo de ejecución de TensorFlow y se configuran automáticamente, lo que los usuarios expertos pueden anular haciendo muchos experimentos y encontrando la configuración adecuada para su carga de trabajo y entorno específicos.
Vida útil de una solicitud de inferencia de servicio de TensorFlow
Repasemos brevemente la vida de un ejemplo prototípico de una solicitud de inferencia de TensorFlow Serving para ver el viaje por el que pasa una solicitud típica. Para nuestro ejemplo, nos sumergiremos en una solicitud de predicción que recibe la superficie de la API gRPC de servicio de TensorFlow 2.0.0.
Primero veamos un diagrama de secuencia a nivel de componente y luego saltemos al código que implementa esta serie de interacciones.
Diagrama de secuencia
Tenga en cuenta que Client es un componente propiedad del usuario, Prediction Service, Servables y Server Core son propiedad de TensorFlow Serving y TensorFlow Runtime es propiedad de Core TensorFlow .
Detalles de la secuencia
-
PredictionServiceImpl::PredictrecibePredictRequest - Invocamos
TensorflowPredictor::Predict, propagando la fecha límite de solicitud desde la solicitud de gRPC (si se configuró una). - Dentro
TensorflowPredictor::Predict, buscamos el Servible (modelo) en el que la solicitud busca realizar una inferencia, de la cual recuperamos información sobre el Modelo guardado y, lo que es más importante, un identificador del objetoSessionen el que se encuentra el gráfico del modelo (posiblemente parcialmente) cargado. Este objeto Servible se creó y confirmó en la memoria cuando TensorFlow Serving cargó el modelo. Luego invocamos internal::RunPredict para llevar a cabo la predicción. - En
internal::RunPredict, después de validar y preprocesar la solicitud, usamos el objetoSessionpara realizar la inferencia mediante una llamada de bloqueo a Session::Run , momento en el que ingresamos al código base de TensorFlow. Después de queSession::Runregresa y nuestros tensores deoutputsse han llenado, convertimos las salidas enPredictionResponsey devolvemos el resultado a la pila de llamadas.