
Les performances de TensorFlow Serving dépendent fortement de l'application qu'il exécute, de l'environnement dans lequel il est déployé et des autres logiciels avec lesquels il partage l'accès aux ressources matérielles sous-jacentes. En tant que tel, le réglage de ses performances dépend quelque peu du cas et il existe très peu de règles universelles garantissant des performances optimales dans tous les contextes. Cela dit, ce document vise à capturer quelques principes généraux et bonnes pratiques pour exécuter TensorFlow Serving.
Veuillez utiliser le guide Demandes d'inférence de profil avec TensorBoard pour comprendre le comportement sous-jacent du calcul de votre modèle sur les demandes d'inférence, et utilisez ce guide pour améliorer ses performances de manière itérative.
Astuces rapides
- La latence de la première requête est trop élevée ? Activer le préchauffage du modèle .
- Intéressé par une utilisation des ressources ou un débit plus élevé ? Configurer le traitement par lots
Optimisation des performances : objectifs et paramètres
Lorsque vous ajustez les performances de TensorFlow Serving, vous pouvez généralement avoir deux types d'objectifs et trois groupes de paramètres à modifier pour améliorer ces objectifs.
Objectifs
TensorFlow Serving est un système de diffusion en ligne pour les modèles appris automatiquement. Comme pour de nombreux autres systèmes de service en ligne, son principal objectif de performances est de maximiser le débit tout en maintenant la latence finale en dessous de certaines limites . En fonction des détails et de la maturité de votre application, vous vous souciez peut-être davantage de la latence moyenne que de la latence finale , mais certaines notions de latence et de débit sont généralement les mesures par rapport auxquelles vous définissez des objectifs de performances. Notez que nous ne discutons pas de la disponibilité dans ce guide car cela dépend davantage de l'environnement de déploiement.
Paramètres
On peut grossièrement penser à 3 groupes de paramètres dont la configuration détermine les performances observées : 1) le modèle TensorFlow 2) les requêtes d'inférence et 3) le serveur (matériel & binaire).
1) Le modèle TensorFlow
Le modèle définit le calcul que TensorFlow Serving effectuera à la réception de chaque requête entrante.
Sous le capot, TensorFlow Serving utilise le runtime TensorFlow pour effectuer l'inférence réelle sur vos demandes. Cela signifie que la latence moyenne de traitement d'une requête avec TensorFlow Serving est généralement au moins celle d'une inférence directement avec TensorFlow. Cela signifie que si sur une machine donnée, l'inférence sur un seul exemple prend 2 secondes et que vous avez un objectif de latence inférieur à la seconde, vous devez profiler les demandes d'inférence, comprendre quelles opérations TensorFlow et sous-graphiques de votre modèle contribuent le plus à cette latence. et repensez votre modèle en gardant à l'esprit la latence d'inférence comme contrainte de conception.
Veuillez noter que même si la latence moyenne de l'inférence avec TensorFlow Serving n'est généralement pas inférieure à celle de l'utilisation directe de TensorFlow, TensorFlow Serving brille en réduisant la latence de queue pour de nombreux clients interrogeant de nombreux modèles différents, tout en utilisant efficacement le matériel sous-jacent pour maximiser le débit. .
2) Les demandes d'inférence
Surfaces API
TensorFlow Serving dispose de deux surfaces d'API (HTTP et gRPC), qui implémentent toutes deux l' API PredictionService (à l'exception du serveur HTTP qui n'expose pas de point de terminaison MultiInference ). Les deux surfaces API sont hautement optimisées et ajoutent une latence minimale, mais en pratique, la surface gRPC s'avère légèrement plus performante.
Méthodes API
En général, il est conseillé d'utiliser les points de terminaison Classify et Regress car ils acceptent tf.Example , qui est une abstraction de niveau supérieur ; cependant, dans de rares cas de requêtes structurées volumineuses (O(Mb)), les utilisateurs avertis peuvent utiliser PredictRequest et coder directement leurs messages Protobuf dans un TensorProto, et ignorer la sérialisation et la désérialisation depuis tf.Exemple, une source de léger gain de performances.
Taille du lot
Le traitement par lots peut améliorer vos performances de deux manières principales. Vous pouvez configurer vos clients pour envoyer des requêtes par lots à TensorFlow Serving, ou vous pouvez envoyer des requêtes individuelles et configurer TensorFlow Serving pour attendre jusqu'à une période de temps prédéterminée et effectuer une inférence sur toutes les requêtes qui arrivent au cours de cette période en un seul lot. La configuration de ce dernier type de traitement par lots vous permet d'atteindre TensorFlow Serving à un QPS extrêmement élevé, tout en lui permettant de mettre à l'échelle de manière sublinéaire les ressources de calcul nécessaires pour suivre le rythme. Ceci est discuté plus en détail dans le guide de configuration et le README par lots .
3) Le serveur (matériel et binaire)
Le binaire TensorFlow Serving effectue une comptabilité assez précise du matériel sur lequel il s'exécute. En tant que tel, vous devez éviter d’exécuter d’autres applications gourmandes en calcul ou en mémoire sur la même machine, en particulier celles avec une utilisation dynamique des ressources.
Comme pour de nombreux autres types de charges de travail, TensorFlow Serving est plus efficace lorsqu'il est déployé sur des machines moins nombreuses et plus grandes (plus de CPU et de RAM) (c'est-à-dire un Deployment avec moins replicas en termes de Kubernetes). Cela est dû à un meilleur potentiel de déploiement multi-tenant pour utiliser le matériel et à des coûts fixes inférieurs (serveur RPC, runtime TensorFlow, etc.).
Accélérateurs
Si votre hôte a accès à un accélérateur, assurez-vous d'avoir implémenté votre modèle pour placer des calculs denses sur l'accélérateur. Cela devrait être fait automatiquement si vous avez utilisé des API TensorFlow de haut niveau, mais si vous avez créé des graphiques personnalisés ou si vous souhaitez épingler. parties spécifiques de graphiques sur des accélérateurs spécifiques, vous devrez peut-être placer manuellement certains sous-graphiques sur des accélérateurs (c'est-à-dire en utilisant with tf.device('/device:GPU:0'): ... ).
Processeurs modernes
Les processeurs modernes ont continuellement étendu l'architecture du jeu d'instructions x86 pour améliorer la prise en charge de SIMD (Single Instruction Multiple Data) et d'autres fonctionnalités essentielles aux calculs denses (par exemple, une multiplication et une addition en un cycle d'horloge). Cependant, afin de fonctionner sur des machines légèrement plus anciennes, TensorFlow et TensorFlow Serving sont conçus avec l'hypothèse modeste que les fonctionnalités les plus récentes ne sont pas prises en charge par le processeur hôte.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Si vous voyez cette entrée de journal (éventuellement des extensions différentes des 2 répertoriées) au démarrage de TensorFlow Serving, cela signifie que vous pouvez reconstruire TensorFlow Serving et cibler la plate-forme de votre hôte particulier et bénéficier de meilleures performances. Construire TensorFlow Servir à partir des sources est relativement simple avec Docker et est documenté ici .
Configuration binaire
TensorFlow Serving propose un certain nombre de boutons de configuration qui régissent son comportement d'exécution, principalement définis via des indicateurs de ligne de commande . Certains d'entre eux (notamment tensorflow_intra_op_parallelism et tensorflow_inter_op_parallelism ) sont transmis pour configurer le runtime TensorFlow et sont automatiquement configurés, que les utilisateurs avertis peuvent remplacer en effectuant de nombreuses expériences et en trouvant la bonne configuration pour leur charge de travail et leur environnement spécifiques.
Durée de vie d'une requête d'inférence TensorFlow Serving
Passons brièvement en revue la vie d'un exemple prototypique de requête d'inférence TensorFlow Serving pour voir le parcours parcouru par une requête typique. Pour notre exemple, nous allons plonger dans une demande de prédiction reçue par la surface de l'API gRPC TensorFlow Serving 2.0.0.
Examinons d'abord un diagramme de séquence au niveau des composants, puis passons au code qui implémente cette série d'interactions.
Diagramme de séquençage
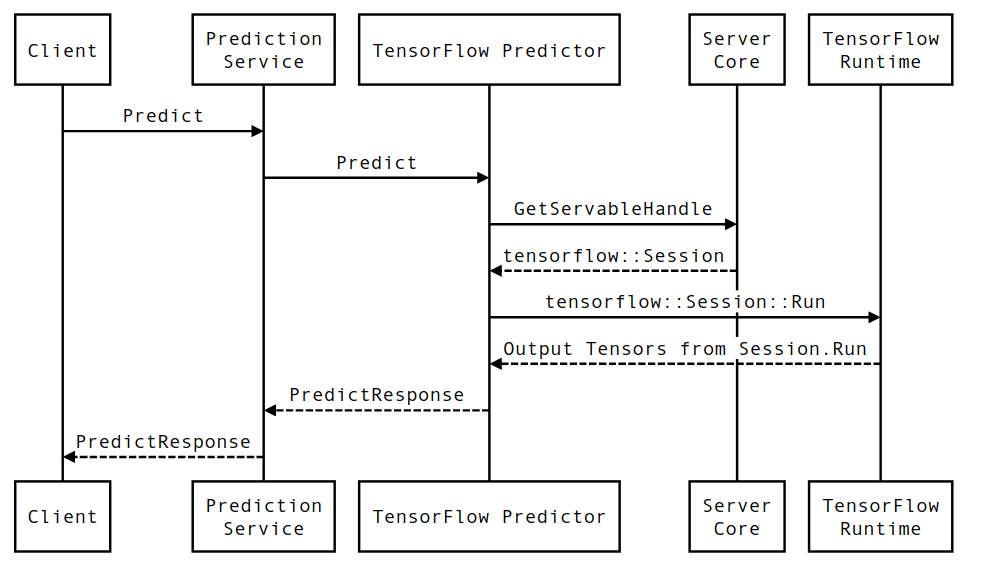
Notez que le client est un composant appartenant à l'utilisateur, Prediction Service, Servables et Server Core appartiennent à TensorFlow Serving et TensorFlow Runtime appartient à Core TensorFlow .
Détails de la séquence
-
PredictionServiceImpl::Predictreçoit laPredictRequest - Nous invoquons le
TensorflowPredictor::Predict, propageant la date limite de la requête à partir de la requête gRPC (si elle a été définie). - Dans
TensorflowPredictor::Predict, nous recherchons le Servable (modèle) sur lequel la requête cherche à effectuer une inférence, à partir duquel nous récupérons des informations sur le SavedModel et, plus important encore, un handle vers l'objetSessiondans lequel se trouve le graphique du modèle (éventuellement partiellement). chargé. Cet objet Servable a été créé et validé en mémoire lorsque le modèle a été chargé par TensorFlow Serving. Nous invoquons ensuite internal::RunPredict pour effectuer la prédiction. - Dans
internal::RunPredict, après avoir validé et prétraité la demande, nous utilisons l'objetSessionpour effectuer l'inférence à l'aide d'un appel bloquant à Session::Run , auquel cas nous entrons dans la base de code principale de TensorFlow. Une fois le retourSession::Runet nos tenseursoutputsremplis, nous convertissons les sorties enPredictionResponseet renvoyons le résultat dans la pile d'appels.