
Après avoir déployé TensorFlow Serving et émis des requêtes de votre client, vous remarquerez peut-être que les requêtes prennent plus de temps que prévu ou que vous n'atteignez pas le débit que vous auriez souhaité.
Dans ce guide, nous utiliserons le profileur de TensorBoard, que vous utilisez peut-être déjà pour profiler la formation de modèles , pour tracer les demandes d'inférence afin de nous aider à déboguer et à améliorer les performances d'inférence.
Vous devez utiliser ce guide conjointement avec les bonnes pratiques indiquées dans le Guide des performances pour optimiser votre modèle, vos requêtes et votre instance TensorFlow Serving.
Aperçu
À un niveau élevé, nous pointerons l'outil de profilage de TensorBoard vers le serveur gRPC de TensorFlow Serving. Lorsque nous enverrons une requête d'inférence à Tensorflow Serving, nous utiliserons également simultanément l'interface utilisateur de TensorBoard pour lui demander de capturer les traces de cette requête. En coulisses, TensorBoard communiquera avec TensorFlow Serving via gRPC et lui demandera de fournir une trace détaillée de la durée de vie de la demande d'inférence. TensorBoard visualisera ensuite l'activité de chaque thread sur chaque appareil de calcul (exécution du code intégré à profiler::TraceMe ) au cours de la durée de vie de la requête sur l'interface utilisateur de TensorBoard pour que nous puissions la consommer.
Conditions préalables
-
Tensorflow>=2.0.0 - TensorBoard (doit être installé si TF a été installé via
pip) - Docker (que nous utiliserons pour télécharger et exécuter l'image TF servant>=2.1.0)
Déployer un modèle avec TensorFlow Serving
Pour cet exemple, nous utiliserons Docker, la méthode recommandée pour déployer Tensorflow Serving, pour héberger un modèle de jouet qui calcule f(x) = x / 2 + 2 trouvé dans le référentiel Github Tensorflow Serving .
Téléchargez la source de TensorFlow Serving.
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
Lancez TensorFlow Serving via Docker et déployez le modèle half_plus_two.
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
Dans un autre terminal, interrogez le modèle pour vous assurer que le modèle est déployé correctement
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
Configurer le profileur de TensorBoard
Dans un autre terminal, lancez l'outil TensorBoard sur votre ordinateur, en fournissant un répertoire dans lequel enregistrer les événements de trace d'inférence :
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
Accédez à http://localhost:6006/ pour afficher l'interface utilisateur de TensorBoard. Utilisez le menu déroulant en haut pour accéder à l'onglet Profil. Cliquez sur Capturer le profil et fournissez l'adresse du serveur gRPC de Tensorflow Serving.
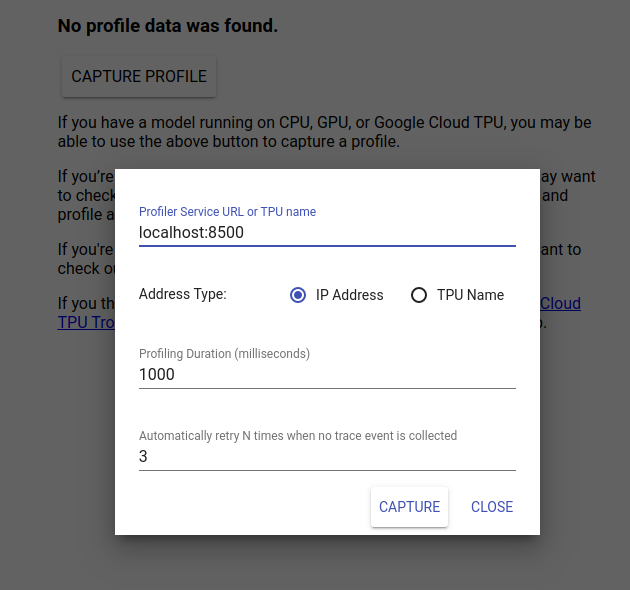
Dès que vous appuyez sur « Capturer », TensorBoard commencera à envoyer des demandes de profil au serveur de modèles. Dans la boîte de dialogue ci-dessus, vous pouvez définir à la fois la date limite pour chaque demande et le nombre total de fois que Tensorboard réessayera si aucun événement de trace n'est collecté. Si vous profilez un modèle coûteux, vous souhaiterez peut-être augmenter le délai pour vous assurer que la demande de profil n'expire pas avant la fin de la demande d'inférence.
Envoyer et profiler une demande d'inférence
Appuyez sur Capturer sur l'interface utilisateur de TensorBoard et envoyez rapidement une demande d'inférence à TF Serving.
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
Vous devriez voir le message « Capturer le profil avec succès. Veuillez actualiser ». des toasts apparaissent en bas de l’écran. Cela signifie que TensorBoard a pu récupérer les événements de trace de TensorFlow Serving et les enregistrer dans votre logdir . Actualisez la page pour visualiser la demande d'inférence avec le Trace Viewer du Profiler, comme indiqué dans la section suivante.
Analyser la trace de la demande d'inférence

Vous pouvez désormais voir facilement quel calcul est effectué à la suite de votre demande d'inférence. Vous pouvez zoomer et cliquer sur l'un des rectangles (tracer les événements) pour obtenir plus d'informations telles que l'heure de début exacte et la durée du mur.
À un niveau élevé, nous voyons deux threads appartenant au runtime TensorFlow et un troisième appartenant au serveur REST, gérant la réception de la requête HTTP et créant une session TensorFlow.
Nous pouvons zoomer pour voir ce qui se passe à l'intérieur du SessionRun.

Dans le deuxième thread, nous voyons un appel initial ExecutorState::Process dans lequel aucune opération TensorFlow n'est exécutée mais les étapes d'initialisation sont exécutées.
Dans le premier thread, nous voyons l'appel pour lire la première variable, et une fois que la deuxième variable est également disponible, exécute la multiplication et ajoute des noyaux en séquence. Enfin, l'Executor signale que son calcul est effectué en appelant le DoneCallback et que la Session peut être fermée.
Prochaines étapes
Bien qu'il s'agisse d'un exemple simple, vous pouvez utiliser le même processus pour profiler des modèles beaucoup plus complexes, ce qui vous permet d'identifier les opérations lentes ou les goulots d'étranglement dans l'architecture de votre modèle afin d'améliorer ses performances.
Veuillez vous référer au TensorBoard Profiler Guide pour un didacticiel plus complet sur les fonctionnalités du Profiler de TensorBoard et du TensorFlow Serving Performance Guide pour en savoir plus sur l'optimisation des performances d'inférence.