
O desempenho do TensorFlow Serving depende muito do aplicativo executado, do ambiente em que é implantado e de outros softwares com os quais compartilha o acesso aos recursos de hardware subjacentes. Como tal, ajustar seu desempenho depende um pouco do caso e há muito poucas regras universais que garantem um desempenho ideal em todas as configurações. Com isso dito, este documento visa capturar alguns princípios gerais e práticas recomendadas para executar o TensorFlow Serving.
Use o guia Solicitações de inferência de perfil com TensorBoard para entender o comportamento subjacente da computação do seu modelo em solicitações de inferência e use este guia para melhorar iterativamente seu desempenho.
Dicas rápidas
- A latência da primeira solicitação é muito alta? Ative o aquecimento do modelo .
- Interessado em maior utilização de recursos ou taxa de transferência? Configurar lotes
Ajuste de desempenho: objetivos e parâmetros
Ao ajustar o desempenho do TensorFlow Serving, geralmente há 2 tipos de objetivos que você pode ter e 3 grupos de parâmetros para ajustar para melhorar esses objetivos.
Objetivos
O TensorFlow Serving é um sistema de atendimento online para modelos aprendidos por máquina. Assim como em muitos outros sistemas de atendimento online, seu principal objetivo de desempenho é maximizar a taxa de transferência enquanto mantém a latência de cauda abaixo de certos limites . Dependendo dos detalhes e da maturidade do seu aplicativo, você pode se preocupar mais com a latência média do que com a latência final , mas algumas noções de latência e taxa de transferência geralmente são as métricas em relação às quais você define os objetivos de desempenho. Observe que não discutimos a disponibilidade neste guia, pois isso é mais uma função do ambiente de implantação.
Parâmetros
Podemos pensar aproximadamente em 3 grupos de parâmetros cuja configuração determina o desempenho observado: 1) o modelo TensorFlow 2) as solicitações de inferência e 3) o servidor (hardware e binário).
1) O Modelo TensorFlow
O modelo define a computação que o TensorFlow Serving realizará ao receber cada solicitação recebida.
Nos bastidores, o TensorFlow Serving usa o tempo de execução do TensorFlow para fazer a inferência real de suas solicitações. Isso significa que a latência média de atender uma solicitação com o TensorFlow Serving geralmente é pelo menos a de fazer inferência diretamente com o TensorFlow. Isso significa que, se em uma determinada máquina, a inferência em um único exemplo leva 2 segundos e você tem um destino de latência de menos de um segundo, você precisa criar o perfil de solicitações de inferência, entender quais operações e subgráficos do TensorFlow do seu modelo contribuem mais para essa latência e reprojete seu modelo com a latência de inferência como uma restrição de projeto em mente.
Observe que, embora a latência média da realização de inferência com o TensorFlow Serving geralmente não seja menor do que usar o TensorFlow diretamente, onde o TensorFlow Serving se destaca é manter a latência da cauda baixa para muitos clientes que consultam muitos modelos diferentes, ao mesmo tempo em que utiliza com eficiência o hardware subjacente para maximizar a taxa de transferência .
2) As Solicitações de Inferência
Superfícies de API
O TensorFlow Serving tem duas superfícies de API (HTTP e gRPC), ambas implementando a API PredictionService (com exceção do servidor HTTP que não expõe um endpoint MultiInference ). Ambas as superfícies de API são altamente ajustadas e adicionam latência mínima, mas, na prática, observa-se que a superfície gRPC tem um desempenho ligeiramente melhor.
Métodos de API
Em geral, é aconselhável usar os endpoints Classify e Regress, pois eles aceitam tf.Example , que é uma abstração de nível superior; no entanto, em casos raros de solicitações estruturadas grandes (O(Mb)), usuários experientes podem encontrar usando PredictRequest e codificando diretamente suas mensagens Protobuf em um TensorProto, e pulando a serialização e desserialização de tf.Example uma fonte de pequeno ganho de desempenho.
Tamanho do batch
Existem duas maneiras principais de o agrupamento em lote ajudar seu desempenho. Você pode configurar seus clientes para enviar solicitações em lote para o TensorFlow Serving ou enviar solicitações individuais e configurar o TensorFlow Serving para aguardar até um período de tempo predeterminado e realizar inferências em todas as solicitações que chegam nesse período em um lote. A configuração do último tipo de lote permite que você atinja o TensorFlow Serving em QPS extremamente alto, ao mesmo tempo em que permite dimensionar de forma sublinear os recursos de computação necessários para acompanhar. Isso é discutido em mais detalhes no guia de configuração e no README de lotes .
3) O Servidor (Hardware e Binário)
O binário do TensorFlow Serving faz uma contabilidade bastante precisa do hardware no qual é executado. Dessa forma, você deve evitar executar outros aplicativos com uso intensivo de computação ou memória na mesma máquina, especialmente aqueles com uso de recursos dinâmicos.
Assim como em muitos outros tipos de cargas de trabalho, o TensorFlow Serving é mais eficiente quando implantado em menos máquinas maiores (mais CPU e RAM) (ou seja, uma Deployment com replicas mais baixas nos termos do Kubernetes). Isso se deve a um melhor potencial de implantação multilocatário para utilizar o hardware e reduzir os custos fixos (servidor RPC, tempo de execução do TensorFlow etc.).
Aceleradores
Se seu host tiver acesso a um acelerador, certifique-se de ter implementado seu modelo para colocar cálculos densos no acelerador - isso deve ser feito automaticamente se você tiver usado APIs TensorFlow de alto nível, mas se tiver construído gráficos personalizados ou quiser fixar partes específicas de gráficos em aceleradores específicos, você pode precisar colocar manualmente certos subgráficos em aceleradores (ou seja, usando with tf.device('/device:GPU:0'): ... ).
CPUs modernas
As CPUs modernas estenderam continuamente a arquitetura do conjunto de instruções x86 para melhorar o suporte para SIMD (Single Instruction Multiple Data) e outros recursos críticos para cálculos densos (por exemplo, uma multiplicação e adição em um ciclo de clock). No entanto, para ser executado em máquinas um pouco mais antigas, o TensorFlow e o TensorFlow Serving são criados com a suposição modesta de que o mais novo desses recursos não é compatível com a CPU do host.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Se você vir essa entrada de log (possivelmente extensões diferentes das 2 listadas) na inicialização do TensorFlow Serving, significa que você pode reconstruir o TensorFlow Serving e direcionar a plataforma do seu host específico e desfrutar de um melhor desempenho. Construir o TensorFlow Servindo a partir da fonte é relativamente fácil usando o Docker e está documentado aqui .
Configuração Binária
O TensorFlow Serving oferece vários botões de configuração que controlam seu comportamento de tempo de execução, principalmente definidos por meio de sinalizadores de linha de comando . Alguns deles (mais notavelmente tensorflow_intra_op_parallelism e tensorflow_inter_op_parallelism ) são transmitidos para configurar o tempo de execução do TensorFlow e são configurados automaticamente, que usuários experientes podem substituir fazendo muitos experimentos e encontrando a configuração certa para sua carga de trabalho e ambiente específicos.
Vida útil de uma solicitação de inferência de veiculação do TensorFlow
Vamos analisar brevemente a vida de um exemplo prototípico de uma solicitação de inferência do TensorFlow Serving para ver a jornada pela qual uma solicitação típica passa. Para nosso exemplo, vamos nos aprofundar em uma solicitação de previsão recebida pela superfície 2.0.0 TensorFlow Serving gRPC API.
Vamos primeiro examinar um diagrama de sequência em nível de componente e, em seguida, pular para o código que implementa essa série de interações.
Diagrama de sequência
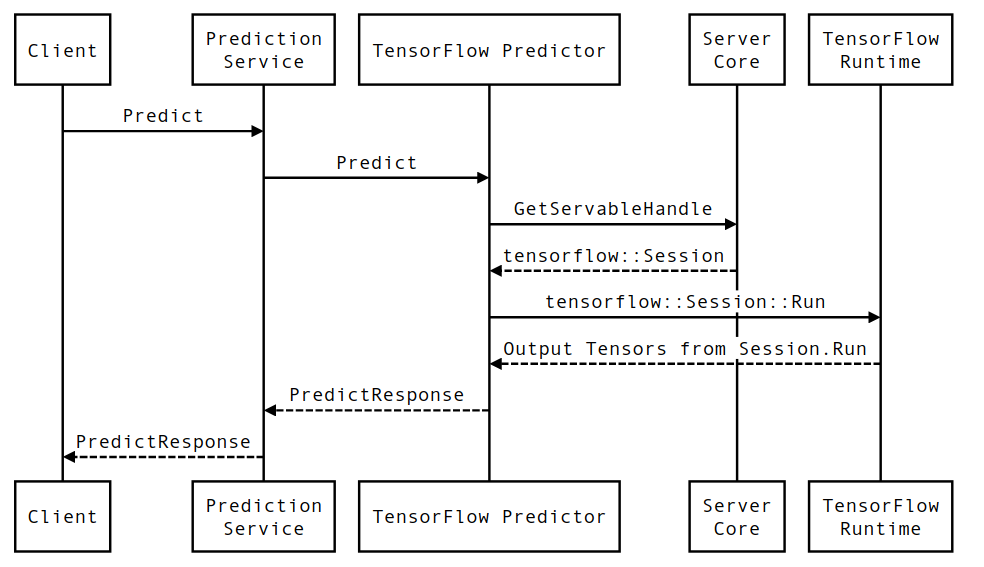
Observe que Client é um componente de propriedade do usuário, Prediction Service, Servables e Server Core são de propriedade do TensorFlow Serving e TensorFlow Runtime é de propriedade do Core TensorFlow .
Detalhes da sequência
-
PredictionServiceImpl::Predictrecebe oPredictRequest - Invocamos o
TensorflowPredictor::Predict, propagando o prazo da solicitação a partir da solicitação gRPC (se houver uma). - Dentro
TensorflowPredictor::Predict, pesquisamos o Servable (modelo) que a solicitação está procurando para realizar a inferência, a partir do qual recuperamos informações sobre o SavedModel e, mais importante, um identificador para o objetoSessionno qual o gráfico do modelo está (possivelmente parcialmente) carregado. Esse objeto Servable foi criado e confirmado na memória quando o modelo foi carregado pelo TensorFlow Serving. Em seguida, invocamos internal::RunPredict para realizar a previsão. - Em
internal::RunPredict, após validar e pré-processar a solicitação, usamos o objetoSessionpara realizar a inferência usando uma chamada de bloqueio para Session::Run , nesse ponto, entramos na base de código do núcleo TensorFlow. Depois queSession::Runretorna e nossos tensores deoutputssão preenchidos, convertemos as saídas em umPredictionResponsee retornamos o resultado na pilha de chamadas.
O desempenho do TensorFlow Serving depende muito do aplicativo executado, do ambiente em que é implantado e de outros softwares com os quais compartilha o acesso aos recursos de hardware subjacentes. Como tal, ajustar seu desempenho depende um pouco do caso e há muito poucas regras universais que garantem um desempenho ideal em todas as configurações. Com isso dito, este documento visa capturar alguns princípios gerais e práticas recomendadas para executar o TensorFlow Serving.
Use o guia Solicitações de inferência de perfil com TensorBoard para entender o comportamento subjacente da computação do seu modelo em solicitações de inferência e use este guia para melhorar iterativamente seu desempenho.
Dicas rápidas
- A latência da primeira solicitação é muito alta? Ative o aquecimento do modelo .
- Interessado em maior utilização de recursos ou taxa de transferência? Configurar lotes
Ajuste de desempenho: objetivos e parâmetros
Ao ajustar o desempenho do TensorFlow Serving, geralmente há 2 tipos de objetivos que você pode ter e 3 grupos de parâmetros para ajustar para melhorar esses objetivos.
Objetivos
O TensorFlow Serving é um sistema de atendimento online para modelos aprendidos por máquina. Assim como em muitos outros sistemas de atendimento online, seu principal objetivo de desempenho é maximizar a taxa de transferência enquanto mantém a latência de cauda abaixo de certos limites . Dependendo dos detalhes e da maturidade do seu aplicativo, você pode se preocupar mais com a latência média do que com a latência final , mas algumas noções de latência e taxa de transferência geralmente são as métricas em relação às quais você define os objetivos de desempenho. Observe que não discutimos a disponibilidade neste guia, pois isso é mais uma função do ambiente de implantação.
Parâmetros
Podemos pensar aproximadamente em 3 grupos de parâmetros cuja configuração determina o desempenho observado: 1) o modelo TensorFlow 2) as solicitações de inferência e 3) o servidor (hardware e binário).
1) O Modelo TensorFlow
O modelo define a computação que o TensorFlow Serving realizará ao receber cada solicitação recebida.
Nos bastidores, o TensorFlow Serving usa o tempo de execução do TensorFlow para fazer a inferência real de suas solicitações. Isso significa que a latência média de atender uma solicitação com o TensorFlow Serving geralmente é pelo menos a de fazer inferência diretamente com o TensorFlow. Isso significa que, se em uma determinada máquina, a inferência em um único exemplo leva 2 segundos e você tem um destino de latência de menos de um segundo, você precisa criar o perfil de solicitações de inferência, entender quais operações e subgráficos do TensorFlow do seu modelo contribuem mais para essa latência e reprojete seu modelo com a latência de inferência como uma restrição de projeto em mente.
Observe que, embora a latência média da realização de inferência com o TensorFlow Serving geralmente não seja menor do que usar o TensorFlow diretamente, onde o TensorFlow Serving se destaca é manter a latência da cauda baixa para muitos clientes que consultam muitos modelos diferentes, ao mesmo tempo em que utiliza com eficiência o hardware subjacente para maximizar a taxa de transferência .
2) As Solicitações de Inferência
Superfícies de API
O TensorFlow Serving tem duas superfícies de API (HTTP e gRPC), ambas implementando a API PredictionService (com exceção do servidor HTTP que não expõe um endpoint MultiInference ). Ambas as superfícies de API são altamente ajustadas e adicionam latência mínima, mas, na prática, observa-se que a superfície gRPC tem um desempenho ligeiramente melhor.
Métodos de API
Em geral, é aconselhável usar os endpoints Classify e Regress, pois eles aceitam tf.Example , que é uma abstração de nível superior; no entanto, em casos raros de solicitações estruturadas grandes (O(Mb)), usuários experientes podem encontrar usando PredictRequest e codificando diretamente suas mensagens Protobuf em um TensorProto, e pulando a serialização e desserialização de tf.Example uma fonte de pequeno ganho de desempenho.
Tamanho do batch
Existem duas maneiras principais de o agrupamento em lote ajudar seu desempenho. Você pode configurar seus clientes para enviar solicitações em lote para o TensorFlow Serving ou enviar solicitações individuais e configurar o TensorFlow Serving para aguardar até um período de tempo predeterminado e realizar inferências em todas as solicitações que chegam nesse período em um lote. A configuração do último tipo de lote permite que você atinja o TensorFlow Serving em QPS extremamente alto, ao mesmo tempo em que permite dimensionar de forma sublinear os recursos de computação necessários para acompanhar. Isso é discutido em mais detalhes no guia de configuração e no README de lotes .
3) O Servidor (Hardware e Binário)
O binário do TensorFlow Serving faz uma contabilidade bastante precisa do hardware no qual é executado. Dessa forma, você deve evitar executar outros aplicativos com uso intensivo de computação ou memória na mesma máquina, especialmente aqueles com uso de recursos dinâmicos.
Assim como em muitos outros tipos de cargas de trabalho, o TensorFlow Serving é mais eficiente quando implantado em menos máquinas maiores (mais CPU e RAM) (ou seja, uma Deployment com replicas mais baixas nos termos do Kubernetes). Isso se deve a um melhor potencial de implantação multilocatário para utilizar o hardware e reduzir os custos fixos (servidor RPC, tempo de execução do TensorFlow etc.).
Aceleradores
Se seu host tiver acesso a um acelerador, certifique-se de ter implementado seu modelo para colocar cálculos densos no acelerador - isso deve ser feito automaticamente se você tiver usado APIs TensorFlow de alto nível, mas se tiver construído gráficos personalizados ou quiser fixar partes específicas de gráficos em aceleradores específicos, você pode precisar colocar manualmente certos subgráficos em aceleradores (ou seja, usando with tf.device('/device:GPU:0'): ... ).
CPUs modernas
As CPUs modernas estenderam continuamente a arquitetura do conjunto de instruções x86 para melhorar o suporte para SIMD (Single Instruction Multiple Data) e outros recursos críticos para cálculos densos (por exemplo, uma multiplicação e adição em um ciclo de clock). No entanto, para ser executado em máquinas um pouco mais antigas, o TensorFlow e o TensorFlow Serving são criados com a suposição modesta de que o mais novo desses recursos não é compatível com a CPU do host.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Se você vir essa entrada de log (possivelmente extensões diferentes das 2 listadas) na inicialização do TensorFlow Serving, significa que você pode reconstruir o TensorFlow Serving e direcionar a plataforma do seu host específico e desfrutar de um melhor desempenho. Construir o TensorFlow Servindo a partir da fonte é relativamente fácil usando o Docker e está documentado aqui .
Configuração Binária
O TensorFlow Serving oferece vários botões de configuração que controlam seu comportamento de tempo de execução, principalmente definidos por meio de sinalizadores de linha de comando . Alguns deles (mais notavelmente tensorflow_intra_op_parallelism e tensorflow_inter_op_parallelism ) são transmitidos para configurar o tempo de execução do TensorFlow e são configurados automaticamente, que usuários experientes podem substituir fazendo muitos experimentos e encontrando a configuração certa para sua carga de trabalho e ambiente específicos.
Vida útil de uma solicitação de inferência de veiculação do TensorFlow
Vamos analisar brevemente a vida de um exemplo prototípico de uma solicitação de inferência do TensorFlow Serving para ver a jornada pela qual uma solicitação típica passa. Para nosso exemplo, vamos nos aprofundar em uma solicitação de previsão recebida pela superfície 2.0.0 TensorFlow Serving gRPC API.
Vamos primeiro examinar um diagrama de sequência em nível de componente e, em seguida, pular para o código que implementa essa série de interações.
Diagrama de sequência
Observe que Client é um componente de propriedade do usuário, Prediction Service, Servables e Server Core são de propriedade do TensorFlow Serving e TensorFlow Runtime é de propriedade do Core TensorFlow .
Detalhes da sequência
-
PredictionServiceImpl::Predictrecebe oPredictRequest - Invocamos o
TensorflowPredictor::Predict, propagando o prazo da solicitação a partir da solicitação gRPC (se houver uma). - Dentro
TensorflowPredictor::Predict, pesquisamos o Servable (modelo) que a solicitação está procurando para realizar a inferência, a partir do qual recuperamos informações sobre o SavedModel e, mais importante, um identificador para o objetoSessionno qual o gráfico do modelo está (possivelmente parcialmente) carregado. Esse objeto Servable foi criado e confirmado na memória quando o modelo foi carregado pelo TensorFlow Serving. Em seguida, invocamos internal::RunPredict para realizar a previsão. - Em
internal::RunPredict, após validar e pré-processar a solicitação, usamos o objetoSessionpara realizar a inferência usando uma chamada de bloqueio para Session::Run , nesse ponto, entramos na base de código do núcleo TensorFlow. Depois queSession::Runretorna e nossos tensores deoutputssão preenchidos, convertemos as saídas em umPredictionResponsee retornamos o resultado na pilha de chamadas.